Ontology is having its moment in the sun right now, after being largely sidelined for the past decade, and the timing is not coincidental. Demand for ontologists is rising. There is growing recognition that a strong semantic foundation is necessary for keeping LLMs grounded in reality. The persistence of memory, along with structured and well-described metadata, are clearly making a major difference in how we build AI systems.
Yet this hasn’t come easily. The semantic community has been debating these issues for a quarter century, and even now there is significant contention about what an ontology is, how it should be formed, and how it fits into the broader context of AI. This article looks at four areas where ontologists were not so much flat-out wrong as persistently unfinished, and where AI teams are now rediscovering the same fault lines, usually without knowing they are standing on them.
Open vs. Closed World Assumption
Permalink to “Open vs. Closed World Assumption”This is the foundational assumption underlying the biggest distinction between the semantic community and the rest of the data modelling world. It ultimately comes down to governance: if you and I both create a model of some aspect of the world, which model is correct?
In the open world model, the assumption is egalitarian: both. In the closed world model, the assumption is authoritarian: mine is.
RDF was built on the open world assumption. If you and I talk about the same entity but describe different aspects of it, neither model is exclusive. I describe a cat in terms of its phenotypal characteristics: fur, obligate carnivore, meow, tail, forward-facing eyes. You describe it in terms of its genetic characteristics, its licensing status, or its representation in contemporary media. All of these are valid models. If you have a shared identifier for a given entity, you can apply each model about a particular cat, and in the aggregate they yield a much broader picture. Different authorities can have different opinions about which model is correct while still referring to the same entity.
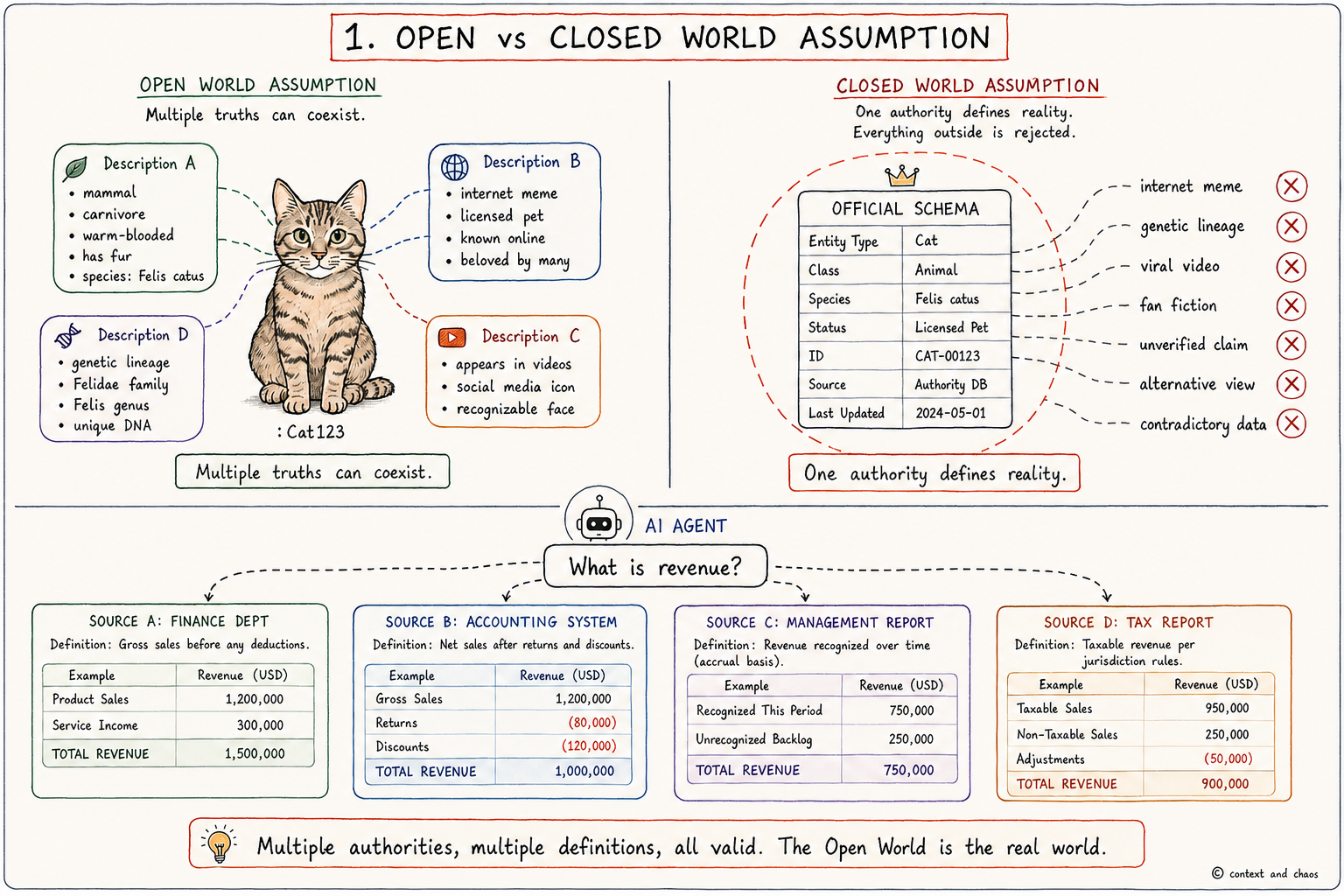
Where this breaks down is that different opinions often produce representations that differ at a structural level, making it difficult to consistently query across them. Upper ontologies such as GIST, BFO, Schema.org, and gUFO each structure their data differently: how something is labelled, which directions links go, how properties are defined. If our definitions do not agree, how can we be sure we are referencing the same concepts?
What you are seeing with RDF 1.2 is a partial retrenchment of the open world assumption, specifically through SHACL, a quasi-closed world model that introduces a meaningful distinction between a property and a predicate chain. SHACL has not been universally adopted, and there are still many in the semantic community who feel it is not the right approach. Yet they are also struggling with the downstream consequences of a pure open world model.
AI is grappling with this right now, and will have the same argument. When an enterprise AI agent queries “revenue,” it may find four tables with four different definitions, each valid under a different authority: Finance counts net of refunds, Sales counts bookings at signature, a legacy table persists from a migration no one completed, and a fifth definition lives in a dbt model no one has touched in eighteen months. The agent has no mechanism to adjudicate between them. It picks one and answers with confidence. This is the open world assumption failing in production, not as an abstract problem, but as the reason a board deck is wrong.
Generative LLMs are the ultimate expression of the open world assumption: anything can be asserted about anything, because linguistic conceptualisations are not bounded. The problem, which the connectionist community is still largely in denial about, is that you cannot trust such assertions without provenance to support their legitimacy. This will ultimately lead toward neurosymbolic AI: systems that combine the free-associating pattern-seeking that LLMs do well with the constraints of a formal language that prevent generative systems from drifting into confident irrelevancy.
The Importance of Reification
Permalink to “The Importance of Reification”Language is highly referential. When you use a subordinate clause, what you are qualifying is often not the subject but the whole assertion, an annotation on an assertion. Reifications are references to assertions themselves.
The earliest versions of RDF had reification, but it was costly given the speed of the technology at the time. For about the first fifteen years of the semantic web, reification was largely ignored, and it shows: most ontologies in use today still lack good mechanisms for handling it. This prompted an effort in the mid-2010s to add such support into the core of the language, which started as RDF-Star, and finally arrived as the polished implementation in RDF 1.2, a reification terminology woven directly into Turtle.
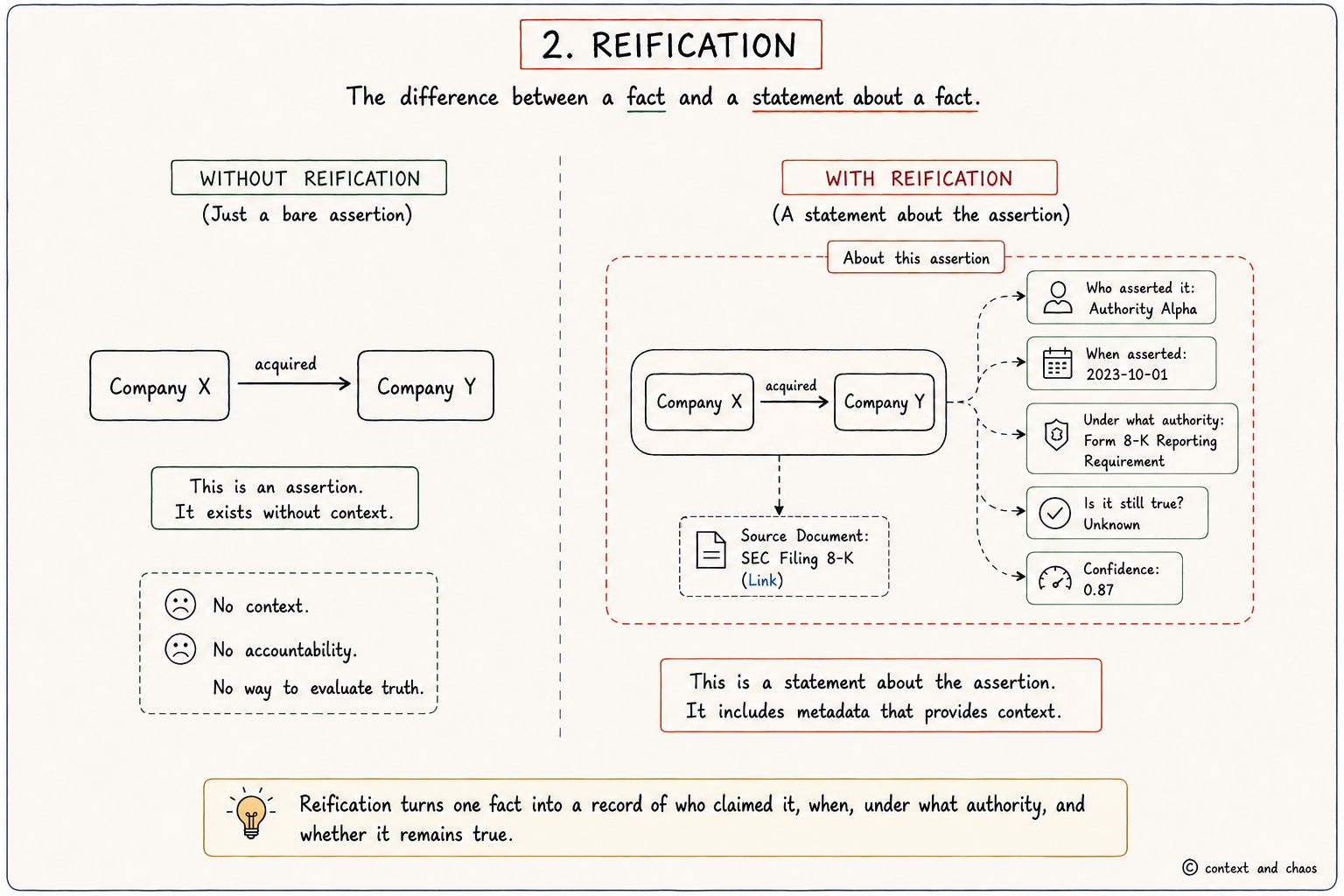
Property graph technologies got something right here early on. A property graph is a reified model: it recognises a meaningful distinction between a property on an entity and a property on a relationship. Where most property graph implementations stop short is at the limits of what can be reified. They provide only literal attributes, strings with associated semantic meaning. RDF 1.2 takes the model further: you can build a reifier that points to other objects in the graph, not just literals.
Reification by its very nature invites what Augustus de Morgan called “fleas upon fleas”: annotations on annotations, qualifications on qualifications. Narrative arcs are built from recursive calls to reifications. The connection between reification and recursion is only beginning to be explored at the edges of the LLM space.
The AI community will fight this same battle. Consider what happens when an agent reasons that “Company X acquired Company Y.” Without reification, that assertion is eternal and unqualified. The agent cannot reason about who asserted it, when it was true, or whether the entity still exists in the same form. Enterprise systems already surface this failure daily: agents that confidently describe an organisational structure that was reorganised eight months ago, a product line that was sunset, a contract that was renegotiated. Reification is not a baroque complication. It is the mechanism by which a system knows the difference between what is true and what was true. You cannot build a system that reasons well about language without eventually confronting this.
Context Graphs and the Primacy of Time
Permalink to “Context Graphs and the Primacy of Time”Knowledge graphs first emerged in the mid-2010s as a way of describing things in a system and how they relate to other things. In this model, there is no particular distinction about time. Most knowledge graphs treat time as an uncomfortable afterthought. This has come back to bite ontologists repeatedly, because time is another way of saying change.
OWL, still the poster child for the semantic movement, works upon a fundamental assumption: everything within its scope is a valid assertion. The problem is that validity is fluid. It changes. A person is born, lives, eventually dies. They change addresses, names, places of employment. The challenge with any knowledge graph is that it is either a now graph describing relationships at a specific moment, or an eternal graph in which mutations occur not on the entity but on the relationship.
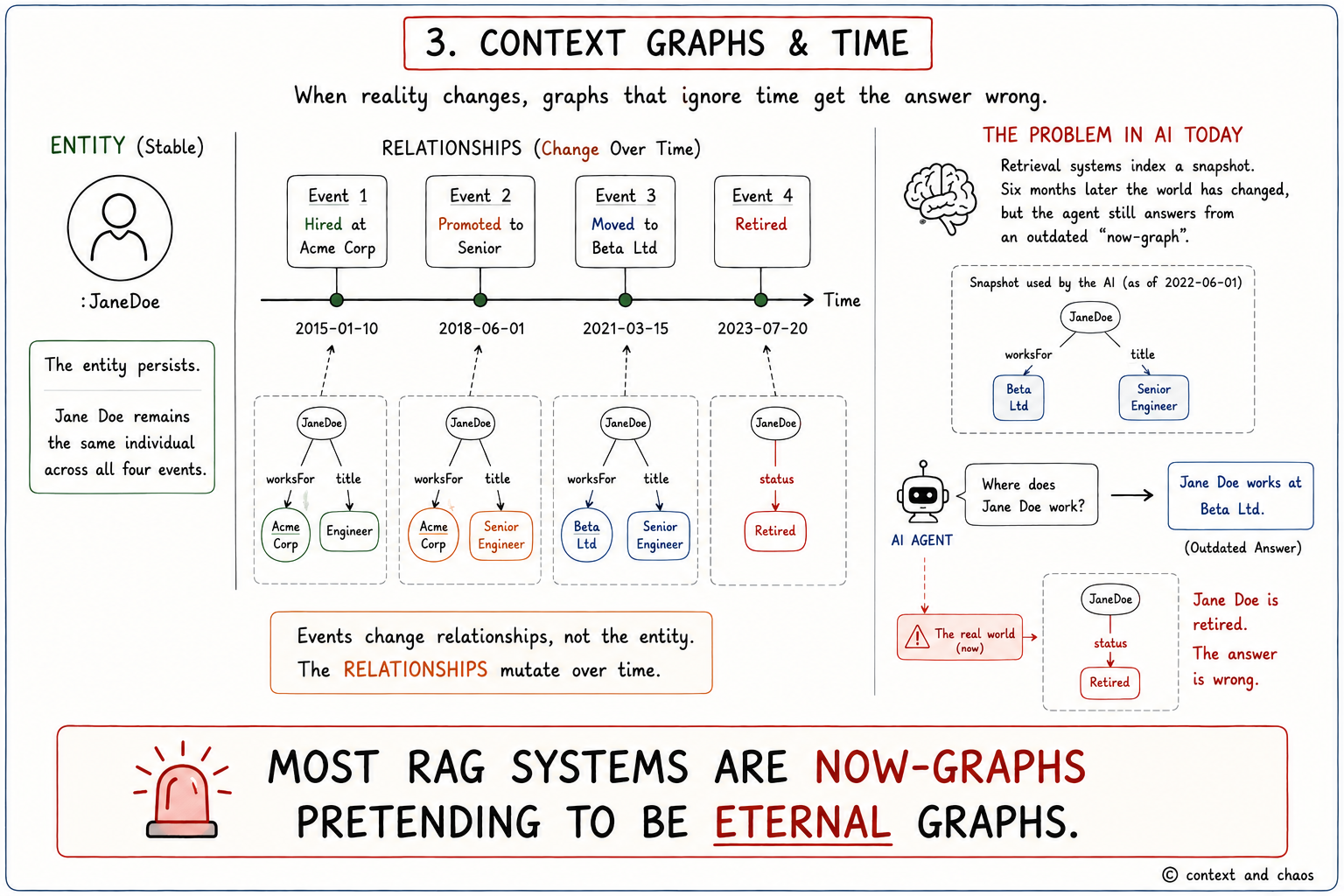
Reifications are essential here. If you can reify a relationship between two entities, you can capture events on that relationship over time. A person moving from one address to another changes neither the person nor the address. It identifies when that person moves in or out. An event can be thought of as something that changes a relationship. We call the result a context graph or event graph.
Context graphs change the nature of graphs because they create a clear division between relationships and mutations, and they introduce the idea that an assertion is contextually true. When an entity is first asserted, :JaneDoe :isA :Person, this spawns an event indicating the entity was instantiated at a particular point. At some stage Jane dies, and a third event records this, and a fourth records the date that this became knowledge in the graph. A SPARQL query can identify the full arc. A SHACL validation can report inconsistencies when a dead person does unexpected things.
This is the exact failure mode appearing in enterprise AI right now. A retrieval system indexes the current state of a document corpus. Six months later the corpus has changed, roles have shifted, products have been updated, but the agent’s context has not. It answers confidently from a world that no longer exists. RAG architectures, in their current form, are overwhelmingly now graphs masquerading as eternal ones. The teams discovering this are reinventing the context graph without the name for it, often in ad hoc ways that will need to be rebuilt when the scope grows. Context graphs are not a specialised application. They are what knowledge graphs become when you take time seriously.
Named Graphs, Namespaces, and the Edges of Authority
Permalink to “Named Graphs, Namespaces, and the Edges of Authority”What is a graph? This is one of the thorniest questions in ontology, though it has not been fully acknowledged as such. The default notion under the open world assumption was a collection of assertions, open-ended by nature. On its face, not unreasonable. If you have a global identifier for a resource, you do not really need to partition the graph.
Where things get uncomfortable is when multiple authorities assign assertions about the same entity under different identifiers, where even the nature of those entities may differ from one authority to the next. Consider a corporate acquisition: depending on which authority you ask, “Twitter” was acquired by X Corp in October 2022, or X Corp acquired the assets of a dissolved Twitter Inc., or Twitter ceased to exist and X is a new entity entirely. Three authorities, three different graphs, three different sets of assertions about employment contracts, intellectual property, regulatory filings, and legal continuity. None of them are wrong. They are operating under different framings of what the entity is. There is no neutral graph.
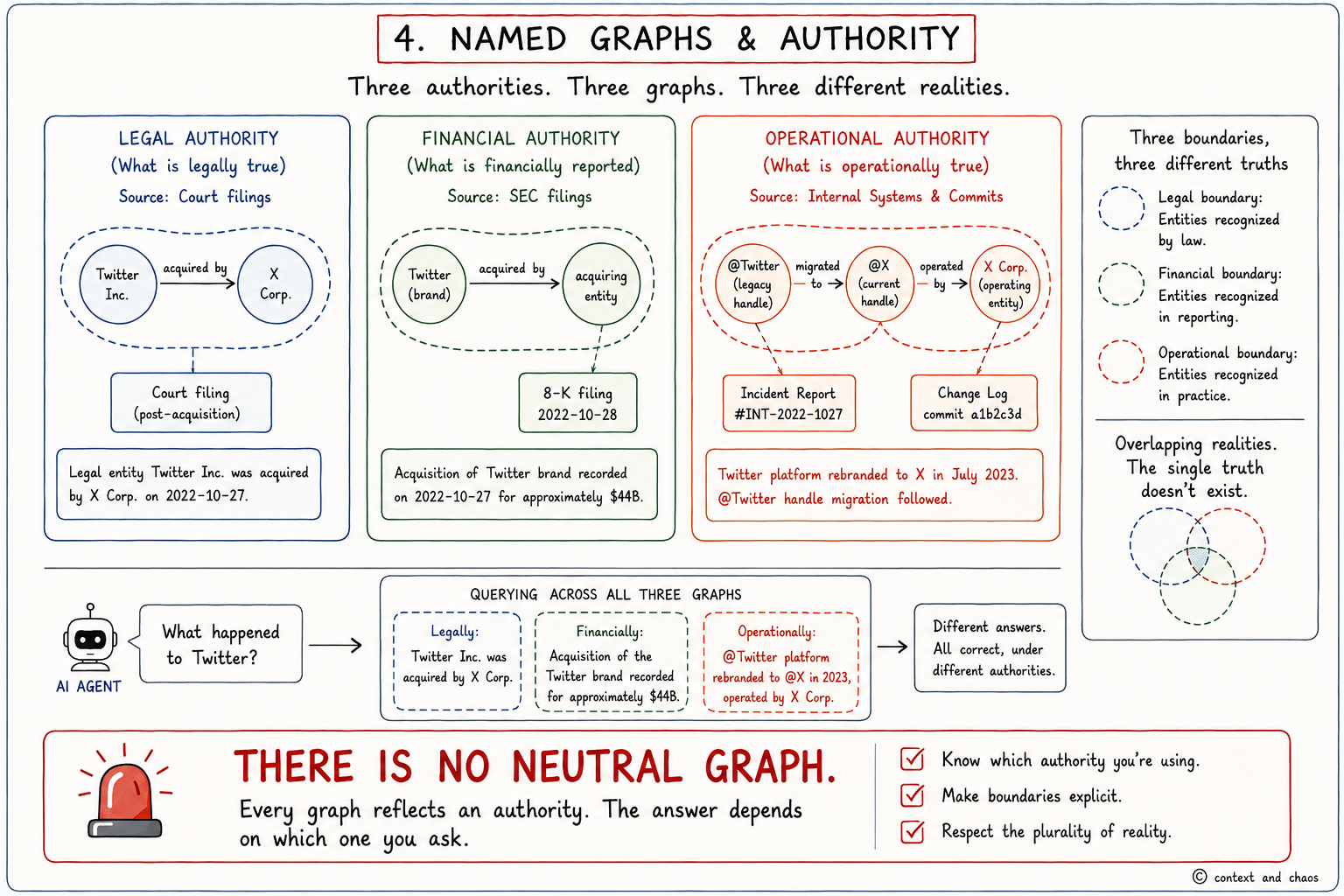
Named graphs, originally proposed in 2005 and formalised in RDF 1.1 in 2014, provide the ability to control the visibility of a set of assertions. This is more than a folder structure. It is a way of controlling which assertions, which facts, are relevant within a given query. Named graphs also carry IRIs, meaning they can be described, referenced, and manipulated, and locked. In conjunction with SHACL, such graph references can be displayed or hidden based on soft context rather than as a triple-store configuration.
The deeper discomfort named graphs introduce is that they strike at the core of the open world assumption. In practice, the boundary of any graph is remarkably firm. Access is controlled. You do not have unlimited power to write or read into the “global” graph without appropriate access. The triple store is, in effect, a named graph, even if it is not declared as such.
AI teams are hitting this right now, whether they recognise the shape of it or not. Multi-tenancy is a named graph problem. Security is a named graph problem. Provenance, knowing which version of the truth an agent is drawing from, under whose authority, at what point in time, is a named graph problem. An LLM can be thought of as a collection of overlapping narrative sheaths, where each path through the model corresponds to a single conversational trajectory. These paths overlap in many places and diverge at points where underlying assumptions differ. The pressures already forcing partitioning, multi-tenancy, security, privacy, provenance, are structurally the same arguments that led to named graphs. The teams discovering this in 2026 are unlikely to know that the argument was already had in 2005.
The Question the Map Doesn’t Answer
Permalink to “The Question the Map Doesn’t Answer”These are not places where ontologists got it wrong. Ontology is still an emerging discipline, and scale forces re-evaluation of beliefs as evidence arises showing that initial assumptions do not hold in larger contexts. The open world assumption is not wrong. It is simply incomplete. Reification is not baroque complication. It is how meaning actually works. Context graphs are not a specialised application. They are what knowledge graphs become when you take time seriously. Named graphs are not administrative convenience. They are the infrastructure of epistemic authority.
AI teams are arriving at these questions now, often without a map. The map exists. It is incomplete, contested, and in some places still under construction. But it is there, built at considerable cost, over twenty-five years, by people whose work was largely dismissed as too theoretical to matter.
The question worth sitting with is not whether AI teams will have these arguments. They will. The question is whether they will have them with the accumulated knowledge of the semantic community behind them, or whether they will spend the next decade paying for lessons that have already been learned.
The semantic web failed to scale. The arguments it generated did not.

Kurt Cagle is a consulting ontologist, knowledge graph architect, and technical author with more than 25 books to his credit. He serves as an IEEE Standards Editor and publishes The Cagle Report and The Ontologist on Substack, as well as the AI+Semantics NewsBytes LinkedIn newsletter. He is based in Olympia, Washington. Contact: [email protected]
This piece was developed in collaboration with Chloe Shannon, an AI collaborator and co-author working with Kurt Cagle on knowledge architecture, semantic systems, and the emerging intersection of formal ontology with LLMs. Contact: [email protected]
The Cats of Context & Chaos
Permalink to “The Cats of Context & Chaos”
About Context & Chaos
Permalink to “About Context & Chaos”Context & Chaos isn’t just a newsletter. It’s shared community space where practitioners, builders, and thinkers come together to share stories, lessons, and ideas about what truly matters in the world of data and AI: context engineering, governance, architecture, discovery, and the human side of doing meaningful work.
Our goal is simple, to create a space that cuts through the noise and celebrates the people behind the amazing things that are happening in the data & AI domain.
Whether you’re solving messy problems, experimenting with AI, or figuring out how to make data more human, Context & Chaos is your place to learn, reflect, and connect.
Got something on your mind? We’d love to hear from you. Hit Reply!
Share this article