You’ve probably seen OpenAI’s recent launch of Frontier, their platform to help enterprises build, deploy, and manage AI agents. This is a big deal. Not because of what Frontier does, but because of what OpenAI just admitted: getting AI right isn’t really about the models.
Frontier likened spinning up an AI agent to onboarding a new hire. Agents need the same primitives humans need to succeed at work: understanding of how work happens, a place to work, feedback, and clear identity, permissions, and boundaries. That’s a more mature vision of enterprise AI than “just give agents access to your data and let them figure it out”.
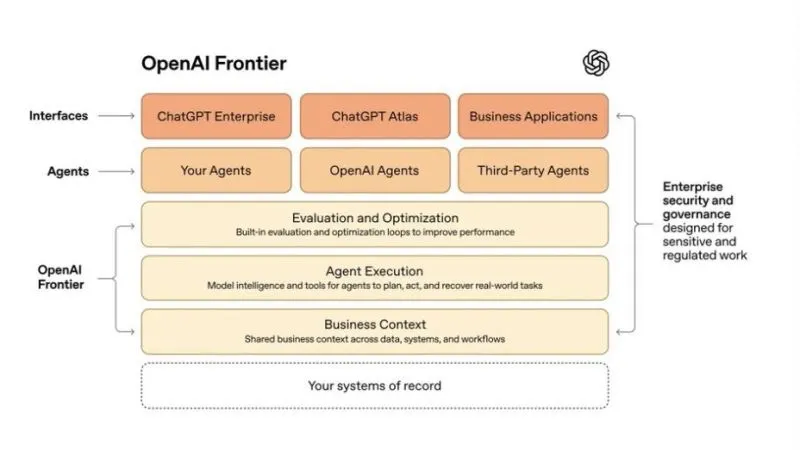 OpenAI Frontier Architecture | Source: OpenAI
OpenAI Frontier Architecture | Source: OpenAI
OpenAI’s own internal data agent story already proved this thesis. Performance only improved once they engineered six layers of context around their data: table usage patterns, human annotations, code analysis, institutional knowledge, memory, and runtime validation.
The base of Frontier isn’t the latest models — it’s business context, helping agents “understand how information flows, where decisions happen, and what outcomes matter”. In short, the company building the most powerful models in the world just told us that AI without context will fail.
Former Snowflake CEO Bob Muglia put this even more bluntly: “Models are not magic. To make the right decision, they need to understand your business. Context is the modern word for understanding your business – the business logic, the exceptions, all of the elements of your business. That is the foundation for making the agents work.”
That’s not a new insight for anyone who’s been building AI in production. I’ve been writing about the context gap and the enterprise context layer for the past 18 months. But hearing it here validates what data leaders have been fruitlessly arguing long before the recent hype around context graphs.
So let’s talk about context, beyond the hype and fluff. In this article, I’ll take on a few counterarguments against context that I’ve heard recently, explain why I think Frontier won’t truly solve the context problem, and share some principles for data leaders on how to make context truly work in their organization.
Won’t models just get smarter?
Permalink to “Won’t models just get smarter?”Since I published about context graphs, I’ve heard a lot of counterarguments on context. This is the strongest one, so I want to start here and engage with it properly.
Here’s the argument: Models are improving fast with longer context windows and better multimodal reasoning, instruction-following, and handling of ambiguity. For example, reasoning models led to a “sudden and significant improvement in LLM capabilities” just a year ago, where new models like OpenAI o1, GPT-4o, and DeepSeek-R1 blew away previous benchmarks and scored above 90% accuracy in key tests. Won’t models eventually be smart enough to figure out your business context on their own, without all this infrastructure?
On the one hand, yes. Models now have giant context windows, up to 1 million tokens, which allow them to take in and process more context than ever before. This means that they’re better now at tracking complex processes, resolving ambiguity, and reasoning over messy problems and information.
However, models can only use the information they’re given. If that underlying information is scattered, incomplete, or contradictory, a model can’t magically fix it.
It’s the classic governance problem. If the Sales team defines “customer” one way in its dashboard and the Finance team defines it another way in its documentation, no model, no matter how intelligent or how big its context window, can decide which definition is authoritative. That’s a coordination problem, not an intelligence problem that can just be reasoned away.
Now take that a step further. Once the model figures out what definition is authoritative, it can’t enforce it across systems, version it as the business evolves, audit it for compliance, and ensure every agent from every vendor uses the same definition. That’s organizational infrastructure, not model capability.
At a Fortune 500 media company, grounding agents in governed context improved accuracy 9x after nine months of stalled progress. Our metadata research showed a 38% improvement in AI-generated SQL accuracy with enhanced semantic metadata, and a 2.15x improvement for medium-complexity queries, the workhorse questions analysts ask every day.
These improvements came from context governance, not better models. The model was the same, but the surrounding context changed.
Haven’t we tried to ‘unify everything’ before?
Permalink to “Haven’t we tried to ‘unify everything’ before?”Data software has a long history of promising to bring everything together. Data lakehouses aimed to unify the data lake and warehouse, data intelligence platforms pitched themselves as one data app to rule them all, and the semantic layer promised one source of truth.
Is the context layer just another in a long line of hyped integrators?
I already wrote about why I believe context is more than a rebranded semantic layer. But more broadly, I think that the context layer is fundamentally different because of its place in the data stack.
Christensen’s “Law of Conservation of Attractive Profits” says that when one layer commoditizes, value shifts to an adjacent, more differentiated layer. That’s what is happening now. Whether it’s OpenAI, Claude, or Gemini, most AI model providers are offering competitive capability at similar prices.
This means that differentiation no longer lives in how strong a model is. It’s about how well that model understands your business.
Every enterprise system already produces context as part of its daily work: lineage from pipelines, ownership from catalogs, client interactions from CRM systems, incident history from support platforms, C-suite feedback from Slack, and more. That context is inherently distributed.
The role of a context layer isn’t to bring together disparate systems or centralize metadata data. It’s about connecting these systems and turning their scattered signals into a coherent, trusted record of how your business actually works.
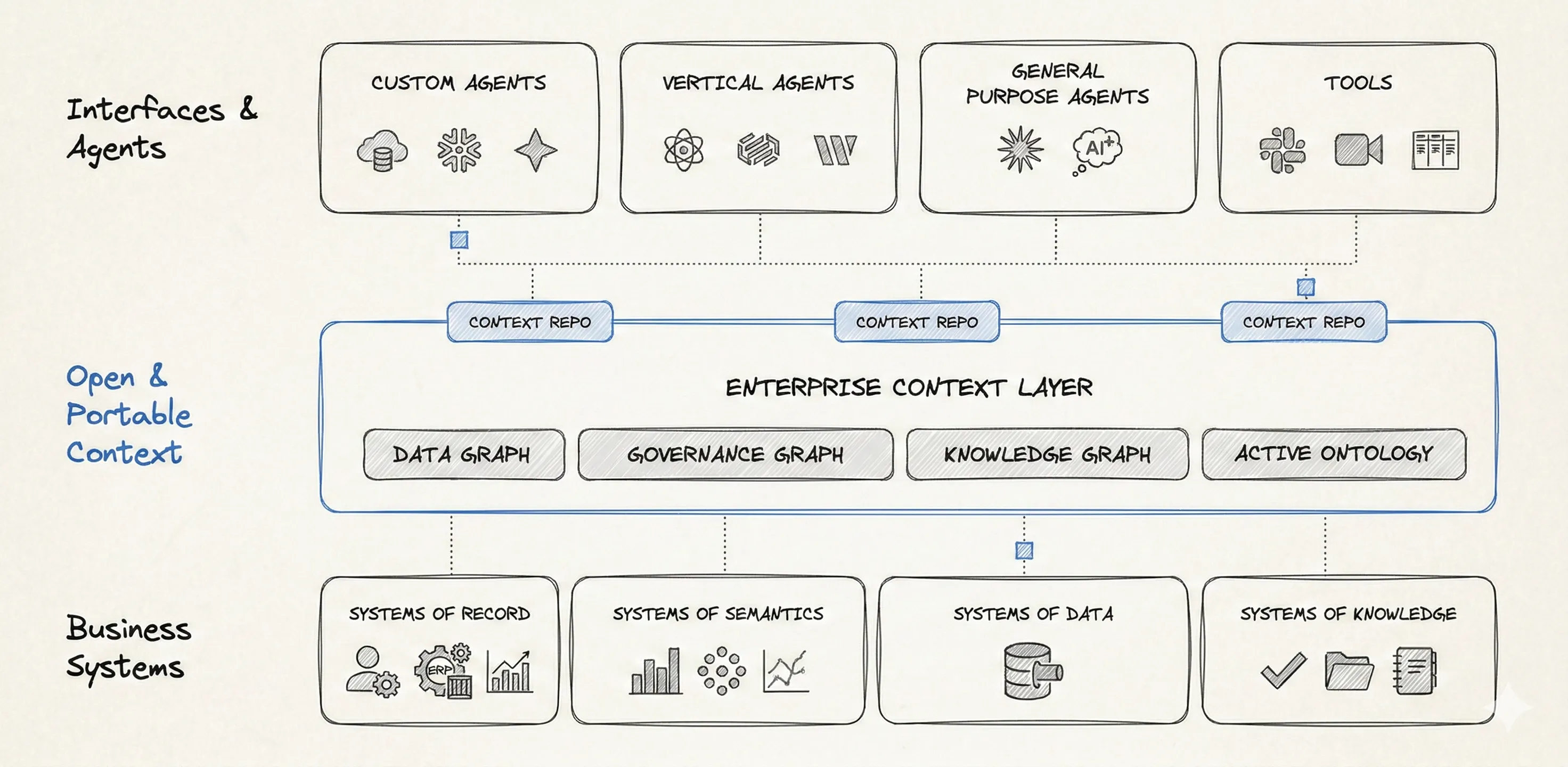 Enterprise Context Layer | Source: Author
Enterprise Context Layer | Source: Author
Why can’t context just live in the warehouse?
Permalink to “Why can’t context just live in the warehouse?”Since context entered the discourse, we’ve heard a common argument from data platform vendors. “We already have the data, the AI agents, and the context. Why add another layer?” That’s what Databricks is pitching with its AI/BI or Snowflake with Cortex.
It’s a reasonable argument for organizations that run on a single data platform. But most enterprises don’t.
I come back to the same example from my earlier article on context graphs. A single customer renewal decision might pull context from Salesforce, Snowflake, Zendesk, Slack, Confluence, and a semantic layer, each owned by a different team, each defining “customer” differently. A context layer inside Snowflake helps Snowflake’s agents. It doesn’t help agents on Salesforce, ServiceNow, OpenAI Frontier, or anywhere else.
So Frontier got the problem right: context matters, agents need business understanding, and models alone aren’t enough. But its solution has a blind spot.
Why Frontier won’t solve the context problem
Permalink to “Why Frontier won’t solve the context problem”This leads to why I think that, despite its meaningful emphasis on context, Frontier won’t be able to solve the context problem. This comes down to the heterogeneity problem.
In the past, heterogeneity referred to data sprawl across multiple systems — e.g. across different types of storage (lakes, warehouses, lakehouses), some centralized and some vertical-specific storage systems (e.g. CRMs). Now, however, we’re adding AI sprawl into the mix. As each data software tool launches its own “add your AI” feature, we’re seeing agents multiply across the data platform, each using their own blend of context from different places with different definitions.
If every platform builds its own business context layer — as is happening now with Frontier’s semantic store, Snowflake’s Cortex, Databricks’ Genie, proprietary ontologies in BI tools, and embedded context in vertical SaaS — you don’t get a context layer. You get dozens of conflicting context silos.
One customer told me, “We have 1,000+ Databricks Genie rooms and no way to govern them all. It’s like BI sprawl all over again.” __ Another discovered that “market” had three different definitions for their company, depending on which team and which agent they asked, each confidently returning conflicting numbers.
Frontier will make this worse, not better, unless the context architecture is right. Adding another platform-specific context layer on top of the existing Snowflake, Databricks, and Salesforce context silos accelerates, rather than solves, heterogeneity.
Beyond that, creating a mess of vendor- or platform-specific context just creates lock-in.
Previous generations of vendor lock-in were about data storage. For example, when you give a vendor your CRM data, switching costs are measured in data migration. But context is about your organization’s institutional memory. When you give a vendor your business context, switching costs are measured in retraining every agent’s understanding of your business . Every workflow, every automation, every AI decision that depends on “what does customer mean here?” breaks if you move. That’s a categorically different kind of lock-in.
Four principles to make context architecture work
Permalink to “Four principles to make context architecture work”If you’re a CIO, CDO, or CDAO making architecture decisions right now, here’s what I’d recommend keeping in mind:
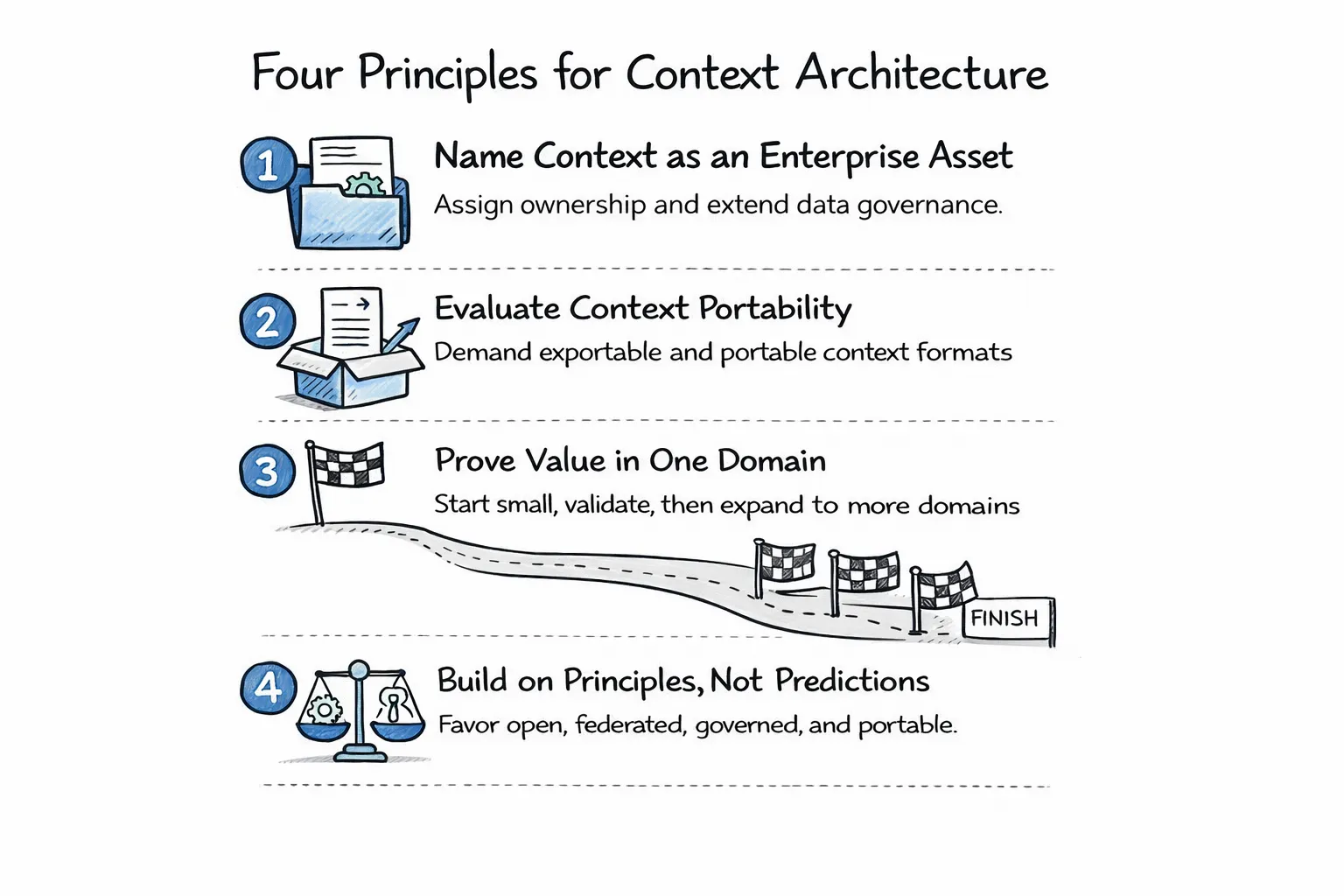 Four principles to make context architecture work | Source: Author
Four principles to make context architecture work | Source: Author
1. Name context as an enterprise asset and assign ownership. Most enterprises have nobody accountable for business context as a cross-functional resource. Data teams own metadata, BI teams own semantic layers, and AI teams own prompt engineering, but no one owns the intersection. Extend your data governance charter to include semantic models, decision traces, and context products, and then put a name next to it. If nobody owns it, every vendor will fill the vacuum.
2. Evaluate every AI platform on context portability. When you look at Frontier, Cortex, Genie, or any vertical agent, ask, can I export my business context in open formats? Does this platform consume context from my other systems, or only from its own? If I stop using this platform, does my context come with me? Your agents should depend on your context layer, not the other way around.
3. Start with one domain, prove it, and then expand. Pick one high-value use case, and build minimum viable context for that domain (semantics, key decision traces, permissions, etc). Once you wire it into one or two agents, use evals and feedback loops to push accuracy past 80% to prove value. We’ve seen this work with enterprises like Workday and Fox in our AI Labs program. Once you get the foundation right, the payoff will quickly compound, and each domain you add will benefit from the context you’ve already built.
4. Build on principles, not predictions. It’s tempting to speculate about the final form of context architecture, but the honest answer is that nobody knows. Will it be centralized stores, federated protocols, smarter models, or some combination? It’s too early to be certain and commit to one. But it’s never too early to follow the principles that govern the modern data stack: open over proprietary, federated over centralized, governed over ungoverned, enterprise-owned over vendor-owned. Keep those principles in mind and you’ll be positioned correctly regardless of how the architecture evolves.
The real fork in the road
Permalink to “The real fork in the road”A year ago, no one would have believed that the world’s most advanced AI lab would build a platform centered on business context rather than just model capability. Now it feels inevitable.
Frontier proved that models are becoming more and more commoditized and context is becoming infrastructure. But this infrastructure is just growing, and whoever ends up controlling it will quietly shape how your enterprise reasons, decides, and automates.
I feel like that’s the real fork in the road for data leaders.
If context lives inside every vendor platform, fragmented and duplicated, we’ll spend the next five years rebuilding the same governance mess we just spent a decade trying to untangle. But this time we’ll have autonomous agents trying to make decisions on top of the mess. Imagine if instead context could become a shared, governed understanding of how the business actually works. One built on an enterprise-owned, portable layer that any agent from any vendor can draw from.
Frontier is just the latest sign that context is inevitable. The strategic question now is not whether you will have a context layer, but whether you will own and control it.
Thanks for reading Metadata Weekly!
That’s all for this edition. Stay curious, keep exploring, and see you all in the next one!
About Context & Chaos
Permalink to “About Context & Chaos”Context & Chaos isn’t just a newsletter. It’s shared community space where practitioners, builders, and thinkers come together to share stories, lessons, and ideas about what truly matters in the world of data and AI: context engineering, governance, architecture, discovery, and the human side of doing meaningful work.
Our goal is simple, to create a space that cuts through the noise and celebrates the people behind the amazing things that are happening in the data & AI domain.
Whether you’re solving messy problems, experimenting with AI, or figuring out how to make data more human, Context & Chaos is your place to learn, reflect, and connect.
Got something on your mind? We’d love to hear from you. Hit Reply!
Originally published in the Context & Chaos newsletter on Substack.
Share this article