Something shifted at Gartner D&A 2026. Not in a “here’s a new buzzword” way. In a “the analysts and the enterprises arrived at the same conclusion at the same time” way.
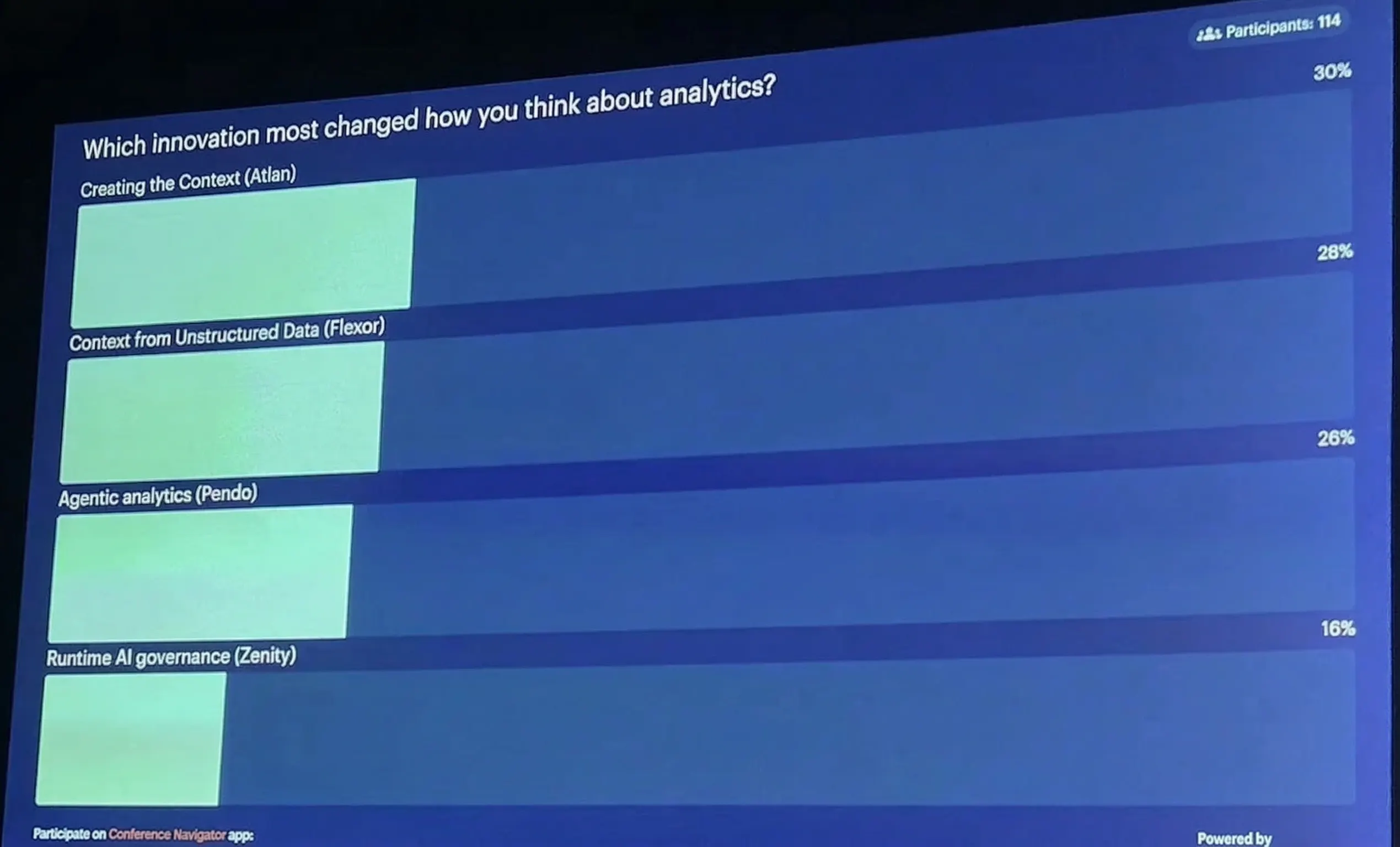
“Context layer” showed up back-to-back on the two biggest stages at the summit: the Opening Keynote and Rita Sallam’s Signature Series. Analysts used the phrase with conviction. Attendees photographed the slides. And when Gartner put four data innovations in front of 114 attendees and asked which one most changed how they think about analytics, a context graph won. Not an analyst picking a winner. Practitioners voting with their hands.
Over three days of sessions, floor conversations, and booth meetings, a pattern emerged.
 Source: Gartner
Source: Gartner
The analysts made their case. The spending data backed it up.
Permalink to “The analysts made their case. The spending data backed it up.”The opening keynote by Georgia O’Callaghan and Adam Ronthal framed the week around a single number: four out of five organizations are now increasing their AI investments. In 2024, just two out of five had actually deployed AI. The growth is real. The question the keynote posed was whether the foundations underneath are keeping up.
Their answer was direct:
“We need to build an integrated contextualization layer across our architecture, connecting every piece of information so everyone and everything, people and agents alike, can see the bigger picture and make better decisions.”
The keynote positioned context not as a feature but as the architecture layer that makes AI investments pay off: “Context is king. ”

Rita Sallam, Distinguished VP Analyst, raised the stakes in her Signature Series session. Only one in five AI investments currently show measurable ROI. Her prescription: treat context as critical infrastructure, the same way organizations treat cybersecurity. That comparison is deliberate. When something gets the cybersecurity treatment, it moves from a technical conversation to a board conversation. It gets executive attention, dedicated budget, and organizational accountability. Rita called context “the brain for AI ,” arguing that agents cannot function autonomously without high-quality context and trust. She declared universal semantic layers a “non-negotiable foundation” and predicted they will be treated as critical infrastructure by 2030, alongside data platforms and cybersecurity.

The spending data reinforced the argument. In a related impact brief, Gartner showed that organizations with the highest satisfaction from AI initiatives invest nearly twice as much in foundations (data quality, governance, talent) as in AI tools, a foundations-to-tools spending ratio of roughly 1.78x, about 30% higher than low-satisfaction peers. In these high-performing organizations, foundations consume around 60% of total AI spend. For any data leader making the case to their board that AI ROI requires foundation investment before tool investment, this is the slide to lead with.

That stat reframes the entire ROI conversation. The organizations getting the most from AI are not the ones buying the most advanced models. They are the ones investing in the context those models need to be useful.
The adoption numbers told the same story from the other direction: 44% of data and analytics leaders have already implemented semantic layers. An additional 48% plan to by 2027. Which means roughly three quarters of organizations are still catching up on a foundation Gartner is now calling critical infrastructure.
The prediction that stopped the room
Permalink to “The prediction that stopped the room”By Day 3, the connection between context and agentic AI had its own dedicated session. Andres Garcia-Rodeja presented “How to Build the Context Layer for Reliable AI Agents” and surfaced a prediction that reframed the agentic conversation: by 2028, 60% of agentic analytics projects relying solely on the Model Context Protocol will fail due to the absence of a consistent semantic layer.
That number matters because MCP is central to how most teams are thinking about agent architecture right now. Andres’ argument was not that MCP is wrong. It is that MCP alone is insufficient. Success requires complementing it with knowledge graphs, ontologies, and governed semantic layers that give agents coherent, reliable context for multi-step analytics.
He described the context layer as functioning like a digital twin for the business, integrating memory (both short-term and long-term data), governance (policies, instructions, and tools), and curated data (specific context provided to AI models).
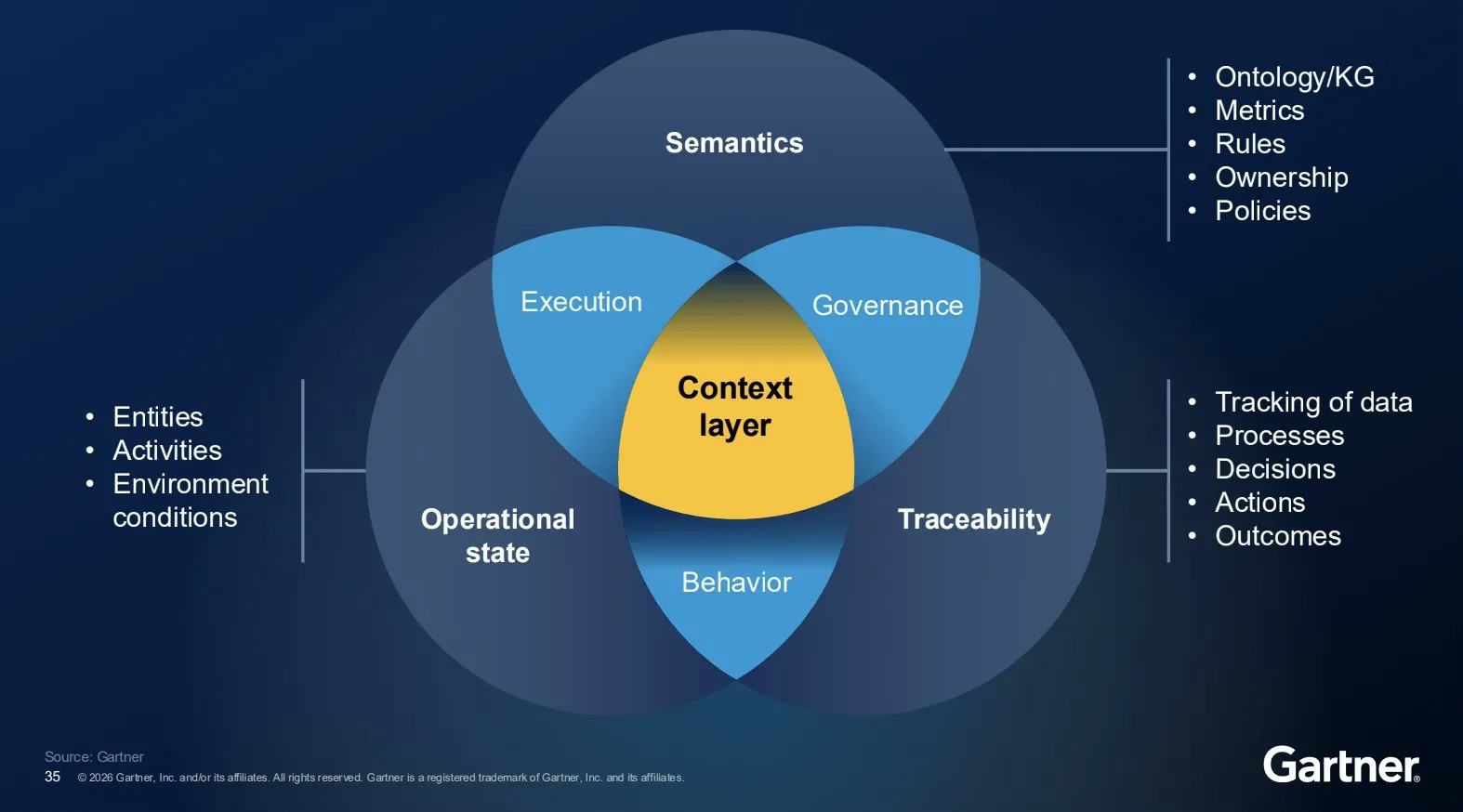
If your team is building agentic systems on MCP alone, this prediction is worth pinning to the wall.
What the floor said
Permalink to “What the floor said”The sessions told one story. The floor told a sharper one.
The expectation was that agentic AI sessions would dominate hallway conversations. They didn’t. The context layer did. And the people asking about it were not exploring. They were buying.
Multiple data and analytics leaders shared that Gartner analysts had specifically directed them to learn about context layer capabilities during one-on-one briefings. These were not exploratory conversations. They were analyst-referred, peer-validated, problem-specific, and budget-backed. Several had existing governance platforms deployed and were not seeing ROI. The pattern was consistent: leaders arriving with specific frustrations about what their current tools could not do and direct questions about what comes next.
Across 200+ conversations over three days, the same questions kept surfacing. They clustered around a few themes:
“We built talk-to-data. It doesn’t work reliably.” A Chief Analytics Officer at a global manufacturer described trying multiple approaches to conversational analytics and not being able to get repeatable accuracy. The issue was not the model. It was the absence of semantic context connecting business language to data language, exactly the gap the keynote diagnosed.
“Our governance platform has low adoption. Now we’re deploying agents without context.” A VP of Enterprise Architecture at a healthcare payer described watching governance adoption flatline while AI agents were already running in production without guardrails. This was the most common frustration on the floor: the governance tool exists, the team bought it, and nobody uses it. Now agents are making decisions without the context that governance was supposed to provide.
“How do we even begin building a context layer?” Many attendees were on the earliest part of the journey. They understood the need but did not have a clear starting point. The questions were practical: Where does a context layer sit in the architecture? Does it replace the catalog? How does it connect to the semantic layer? What gets built first?
“Context layer vs. semantic layer vs. knowledge graph: what’s the difference?” This came up repeatedly. Leaders were actively building a mental model of where context fits relative to adjacent concepts. They were not confused about whether they needed it. They were trying to understand how the pieces relate and where to draw the boundaries.
“Who owns this?” The organizational question surfaced in almost every serious conversation. Data engineering? The CDO? The AI team? A cross-functional council? Today’s org structures still treat catalog, governance, quality, and AI as separate problems. AI agents do not. The ownership question is unresolved at most organizations and everyone knows it.
“We need something that works across our stack, not inside one vendor.” CIOs were asking for a neutral, cross-stack context layer that sits above individual platforms. The forward-thinking ones, as one analyst put it, are “looking to put in place solid architecture for the future” and want defensibility through heterogeneity, not lock-in.
In breakout sessions, phones went up at architecture diagrams showing lineage, semantics, policies, and usage patterns connected across systems. Not at product announcements. At architecture slides. Attendees were photographing how context layers connect end-to-end because seeing it actually wired together is still rare enough to prompt recognition.
Mark Beyer’s session on active metadata reinforced the scale challenge from a different angle: “Every time you reuse data, you will create 100 times more metadata.” His point was that human intelligence lives in a bigger world than data assets. Humans have context. Agents are stuck with partial context unless you engineer the full picture into the system. That engineering is exactly what the context layer is for.
Arun Chandrasekaran, Distinguished VP Analyst, made the downstream risk concrete in his session on the blind spots CDAOs are not watching. His projections: by 2030, 50% of enterprises will face delayed AI upgrades or rising maintenance costs due to unmanaged technical debt. 30% will face degraded decision-making quality from over-reliance on AI. Shadow AI proliferating without governance. AI-generated artifacts accumulating without registries. Deployment metrics masking actual adoption failures. All symptoms of the same root cause: organizations scaling AI without the context infrastructure to govern what they are building.
The confidence gap models cannot fix alone
Permalink to “The confidence gap models cannot fix alone”Reporting from AnalyticsWeek, citing a joint Alteryx and Gartner report released during the summit, captured the split in sharp terms: 89% of US firms increased AI spending this quarter. 28% admit to having zero confidence in the data quality feeding their AI systems. A lead data architect quoted in the coverage put it plainly: “In 2024, we worried about AI making things up. In 2026, the problem is AI being too confident about bad data.”
That distinction matters more now than it did a year ago. Experimental chatbots made hallucinations visible. Agentic systems make them actionable. A hallucination on a dashboard is a reporting problem. A hallucination from an agent that updates supply chains, adjusts pricing, or triggers workflows is a decision problem.
The context layer is the answer to that confidence gap. It is how organizations turn the foundations Gartner is calling non-negotiable (data quality, governance, semantics) into machine-readable context that stops “too confident about bad data” before it reaches production.
What this means for teams scoping now
Permalink to “What this means for teams scoping now”Gartner D&A 2026 settled the question of whether a context layer matters. It does. The spending data proves the ROI case. The analyst predictions name it critical infrastructure. The floor conversations confirmed that enterprises are already scoping it with budget.
What the summit opened is the next set of questions:
Ownership. When an AI agent makes a bad decision because it lacks context, which team gets the call? Today’s org structures still treat catalog, governance, quality, and AI as separate problems. AI agents do not.
Operationalization. How do you build trust when your semantics are fragmented across teams, your governance tools have low adoption, and your AI runs without traceable guardrails?
Timing. Many enterprises have already shipped agents without governance or context. The question now is how fast they can close the gap.
A year ago, “context layer” was a conference slide. At Gartner D&A 2026, it was in procurement conversations, analyst referral calls, and budget allocation discussions.
The organizations investing in context foundations now will not just get more from their AI. They will set the terms for how everyone else catches up.
References
Permalink to “References”Gartner Data & Analytics Summit 2026 Orlando: Day 1 Highlights
Gartner Data & Analytics Summit 2026 Orlando: Day 2 Highlights
Gartner Data & Analytics Summit 2026 Orlando: Day 3 Highlights
Gartner Announces Top Predictions for Data and Analytics in 2026
AnalyticsWeek: “The Truth Layer Crisis: Why 28% US Firms Don’t Trust Own AI”
Thanks for reading Metadata Weekly!
That’s all for this edition. Stay curious, keep exploring, and see you all in the next one!
About Context & Chaos
Permalink to “About Context & Chaos”Context & Chaos isn’t just a newsletter. It’s shared community space where practitioners, builders, and thinkers come together to share stories, lessons, and ideas about what truly matters in the world of data and AI: context engineering, governance, architecture, discovery, and the human side of doing meaningful work.
Our goal is simple, to create a space that cuts through the noise and celebrates the people behind the amazing things that are happening in the data & AI domain.
Whether you’re solving messy problems, experimenting with AI, or figuring out how to make data more human, Context & Chaos is your place to learn, reflect, and connect.
Got something on your mind? We’d love to hear from you. Hit Reply!
Originally published in the Context & Chaos newsletter on Substack.
Share this article