Most teams building “talk to data” experiences follow the same path. They connect a large language model to the warehouse, point it at the schema, pipe in some catalog descriptions and glossary terms, and the first demo feels like magic. Simple questions work, stakeholders get excited, and it looks like you’re a prompt away from self-serve analytics.
Then production happens. The joins get messier, domain language creeps in, people ask questions the model hasn’t seen before, and accuracy falls off a cliff. The instinct to place blame is predictable: wrong model, wrong provider, wrong prompt, not enough fine-tuning…
But after running a controlled experiment with over 500 query evaluations, we’re convinced that one of the biggest gaps between AI demos and AI in production isn’t intelligence. It’s context.
And by context, we mean something specific. Most organizations have metadata : business glossaries, column descriptions, catalog entries. But metadata on its own is raw material.
Context is what you get when you shape that metadata into machine-usable signals, things like concise domain rules, SQL patterns, guardrails, and contrasts that a model can actually act on. In our experiments, that distinction turned out to matter a lot.
LLMs are brilliant generalists with zero institutional knowledge
Permalink to “LLMs are brilliant generalists with zero institutional knowledge”A large language model is powerful in the abstract, but it has no idea how your business works. It can see every table, column, and relationship in your warehouse, yet it doesn’t know what any of it means inside your organization.
LLMs don’t know what “eliminated” means, that “churned” means something different in marketing than in finance, that three different columns named “date” exist for three completely different reasons, or that some joins are technically valid and semantically disastrous.
Without context, the model fills in the gaps the only way it can: with plausible guesses. And in analytics, plausible guesses are dangerous, because AI doesn’t just fail quietly - it fails with confident, convincing wrong answers.
We tested one variable: context
Permalink to “We tested one variable: context”We wanted to put numbers behind this intuition, so we ran a controlled NL→SQL experiment in a realistic analytics environment. The setup used a Formula One dataset with 13 tables, 94 columns, and 174 unique natural language questions, each evaluated three times for 522 total runs. The only thing we changed across conditions was the context layer provided to the model.
We compared three versions.
-
The first was a bare schema with just table names, column names, and data types, about 29 lines of minimal technical context.
-
The second was high-signal context , which added concise business definitions, SQL usage patterns, and domain rules on top of the schema, coming to about 64 lines.
-
The third was human documentation context , the same information expanded into verbose, catalog-style narrative descriptions, roughly 176 lines.
Same dataset. Same model. Same questions. Only the context layer changed.
The bare schema produced 16.1% correct answers, roughly one in six. The high-signal context brought that up to 22.2%, a 38% relative improvement that was statistically significant at p < 0.0001. The verbose documentation context actually performed worse than the concise version, dropping 13.8% while costing 52% more due to larger prompts.
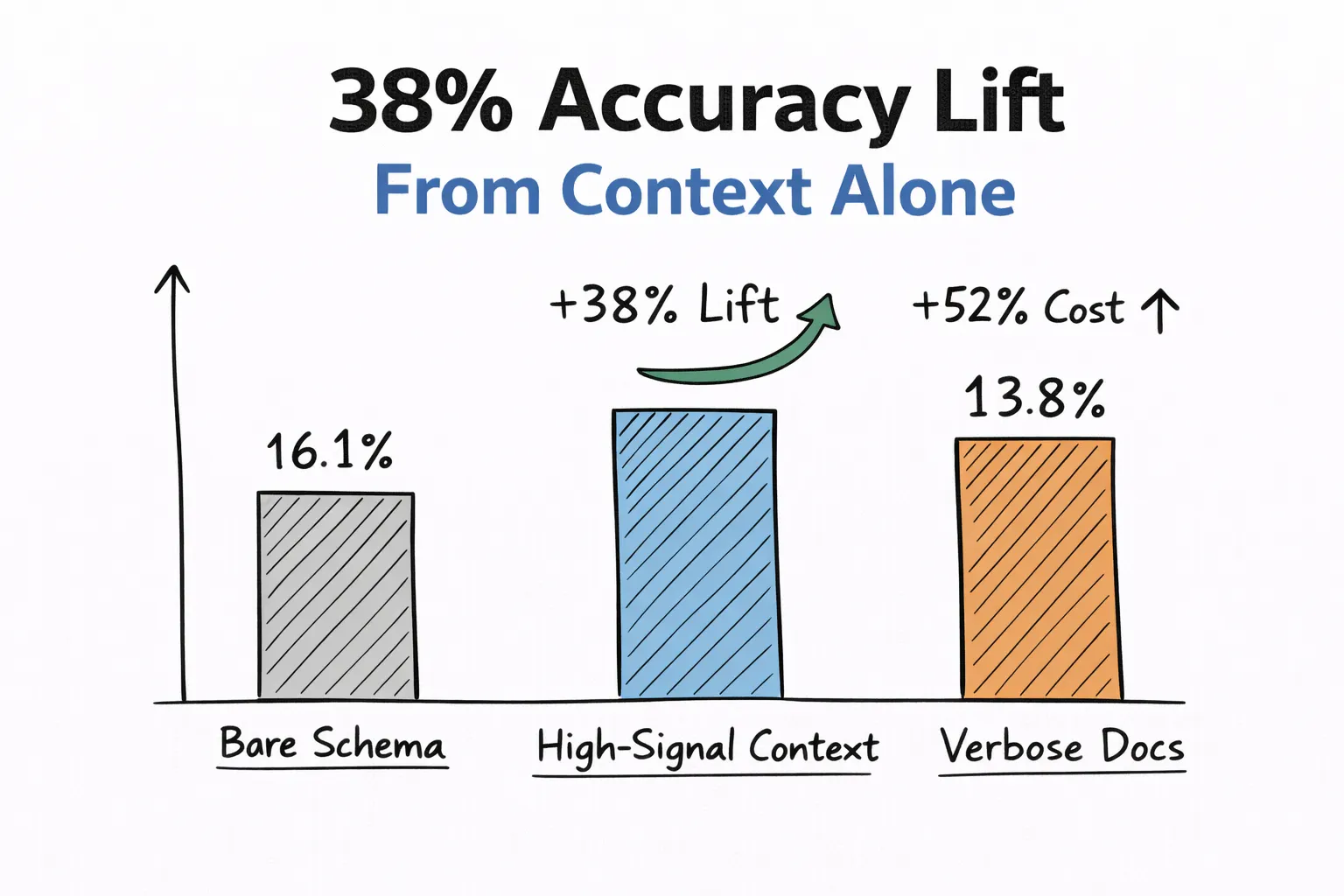 High Signal Context Test | Source: Author
High Signal Context Test | Source: Author
To be clear, 22% absolute accuracy is not production-ready. But the direction and the magnitude of change from context alone tell you where the leverage is. And the surprising takeaway wasn’t just that better context helped. It was that more documentation actually made things worse.
Why “more context” can become noise
Permalink to “Why “more context” can become noise”Humans can skim paragraphs and extract the one sentence that matters. Models can’t.
When you flood a prompt with narrative prose, the important signals get diluted: which tables should be joined, what terms mean in this business, which columns are easy to confuse, what rules define “active” or “eliminated.” To the model, verbose documentation isn’t helpful. It’s noise.
What works is not more text, but higher signal density. That’s the core difference between metadata (the raw descriptions sitting in your catalog) and context (those descriptions distilled into the precise signals a model needs to reason correctly).
A simple example: the “eliminated” problem
Permalink to “A simple example: the “eliminated” problem”One question from our benchmark illustrates this perfectly. A user asks: “Which F1 drivers were eliminated in the first round?” The schema includes qualifying results, lap times, and positions, but nothing explicitly labeled “eliminated.”
Without domain context, the model generated something like:
[code]
SELECT driver_name
FROM results
WHERE position IS NULL;
[/code]
Syntactically valid, but semantically wrong. In racing, “eliminated in the first round” refers to the slowest drivers in Q1, not rows with missing data. Once we encoded that rule in the context layer, the model produced something much closer to correct:
[code]
SELECT driver_name
FROM qualifying
ORDER BY q1_time DESC
LIMIT 5;
[/code]
That single piece of institutional knowledge was the difference between a plausible lie and a useful answer. It’s not simply more words. It’s the right words, in the right format, at the right moment.
Where context matters most
Permalink to “Where context matters most”Not every question benefits equally. We grouped queries into three complexity buckets and the pattern was clear.
Simple questions made up about 70% of the set, things like “average age of drivers?” These saw minimal lift from added context, about 1.15x, because schema alone is usually enough.
Very complex questions were about 4% of the set, involving nested logic and multi-step reasoning. Context barely helped here, about 1.00x. These need tool planning, chain-of-thought prompting, or human review.
The interesting category was medium-complexity questions, about 27% of the set. These are joins, aggregations, and domain-specific definitions: the workhorse analytics questions that businesses ask every day. This category saw a 2.15x improvement with high-signal context.
 Context Impact by Question Type | Source: Author
Context Impact by Question Type | Source: Author
That’s the practical sweet spot. The biggest return on context investment isn’t in toy queries, and it isn’t in the hardest edge cases. It’s in the middle band, the questions your analysts and stakeholders actually care about. If you’re deciding where to invest in making metadata machine-usable, start there.
Four principles of context engineering
Permalink to “Four principles of context engineering”So what does machine-usable context actually look like? Four patterns repeatedly mattered in our experiment, and they’re consistent with what practitioners across the NL→SQL space are converging on more broadly.
1. Show usage, not just meaning
Permalink to “1. Show usage, not just meaning”A typical catalog description says something like “the millisecond column contains lap time measurements.” Clear enough for a person, but not particularly useful for a model. A machine-usable version makes the intended usage explicit through a runnable example:
-- Fastest lap time
[code]
SELECT milliseconds
FROM lap_times
ORDER BY milliseconds ASC
LIMIT 1;
[/code]
Models learn more from one correct query pattern than from paragraphs of prose. For each high-value field, the question to ask is: what one or two query fragments would show a model how this is actually used in practice?
2. Encode guardrails
Permalink to “2. Encode guardrails”It’s not enough to describe what a field represents. You also need to capture how not to use it. This includes directions like “never join events directly to users_raw,” or “status = ‘active’ is unreliable before 2021,” or “country here is billing, not shipping.”
In our experiment, making rules like these explicit directly flipped wrong answers into correct ones. Good context is not just definition. It is a constraint.
3. Disambiguate lookalikes side by side
Permalink to “3. Disambiguate lookalikes side by side”Many of the hardest errors came from subtle differences between fields that look similar. Instead of scattering column descriptions across the catalog independently, put confusable fields next to each other with explicit contrast: drivers.nationality is the driver’s home country, while circuits.country is the race location. That small change makes it much easier for a model to pick the right field when it sees a phrase like “drivers by country” versus “races by location.” Contrast is context.
4. Speak production language
Permalink to “4. Speak production language”The context needs to use the same language as your warehouse. That means fully qualified names like analytics.f1.drivers instead of just drivers, real column names rather than pseudocode, and snippets taken from actual production queries wherever possible. If the context uses one naming convention and the schema uses another, you’re teaching the model two dialects and asking it to guess which one is real.
The economics
Permalink to “The economics”We estimated the incremental cost of richer context at roughly $4.02 per 1,000 queries. Even modest reductions in wrong answers easily outweigh that cost, because the real expense isn’t token spend. It’s one confidently wrong number in a high-stakes decision.
We modeled a conservative ROI scenario where each correctly answered self-service query avoids roughly $0.50 in support or rework, and the returns were significant. But we’d encourage you to run your own numbers with your own assumptions. The underlying logic matters more than any specific figure: the economic impact of fewer bad answers almost always dwarfs the marginal cost of better context.
What we didn’t test
Permalink to “What we didn’t test”We want to be clear about boundaries. We tested one model, one domain, and one dataset scale. We did not compare against RAG with curated query examples, few-shot libraries, or semantic layer integration. And even our best condition still failed roughly 80% of queries.
Context is necessary, not sufficient. Production NL→SQL will still require validation layers, execution safeguards, and human oversight for high-stakes work. We think of context as one of the most underinvested levers available right now, but certainly not the only lever.
How to start without boiling the ocean
Permalink to “How to start without boiling the ocean”Treat this like an experiment. Pick one domain where errors matter, whether that’s revenue, risk, growth, or operations. Collect real medium-complexity questions from query logs, tickets, notebooks, and meetings. Focus on the joins and aggregations with domain nuance.
Then rewrite the context for the tables those questions touch. Add example queries, guardrails, and contrast notes. Keep it concise and aim for signal density, not coverage. Measure accuracy before and after, tracking not just the win rate but which types of errors disappear. Scale what works.
The mindset shift
Permalink to “The mindset shift”For years, metadata was about helping humans browse data. Now it has a second job: helping machines reason safely.
The implication isn’t that models don’t matter. They do. But for many teams, the highest-leverage investment right now may not be a bigger model or a better prompt. It may be turning the metadata you already have into context that machines can actually use.
The teams that get the most from AI in analytics won’t necessarily be the ones with the biggest models. They will be the ones who build the strongest layer of institutional context between AI and the warehouse, one domain at a time, one set of questions at a time, one high-signal chunk of context at a time.
Reference: The findings and numbers discussed here draw ona published study of NL→SQL performance under different metadata conditions, Research Shows How Enhanced Metadata Delivers 38% Better AI Accuracy for Certain Queries.
Thanks for reading Metadata Weekly!
The Insight Index: Your Weekly Data & AI Digest
Permalink to “The Insight Index: Your Weekly Data & AI Digest”Top resources, social posts, and recommended reads, carefully curated for you.
-
**Why keeping Data& Analytics and AI in IT keeps killing ROI — **Patrick Eriksson
-
**The Principles of Data Modeling (Facts& Dimensions) — **Yassine Mahboub
-
**The Data Job isn’t Dying Because the Trust Problem is Exploding — **Julie Zhuo
-
The struggle for good AI governance is real — Grant Gross
-
**How to Build Your First Team of AI Agents — **Dr. Phillipa Hardman
-
**The Human Elements of the AI Foundations — **Gaurav Ramesh
That’s all for this edition. Stay curious, keep exploring, and see you all in the next one!
About Context & Chaos
Permalink to “About Context & Chaos”Context & Chaos isn’t just a newsletter. It’s shared community space where practitioners, builders, and thinkers come together to share stories, lessons, and ideas about what truly matters in the world of data and AI: context engineering, governance, architecture, discovery, and the human side of doing meaningful work.
Our goal is simple, to create a space that cuts through the noise and celebrates the people behind the amazing things that are happening in the data & AI domain.
Whether you’re solving messy problems, experimenting with AI, or figuring out how to make data more human, Context & Chaos is your place to learn, reflect, and connect.
Got something on your mind? We’d love to hear from you. Hit Reply!
Originally published in the Context & Chaos newsletter on Substack.
Share this article