Here’s a pattern we keep seeing in 2026: a data team with mature BI, solid governance, respectable quality scores, and AI pilots that go nowhere.
The dashboards work. The semantic layer is defined. Lineage exists. The catalog is populated. By every traditional measure, the data is in good shape. And yet, the AI agent deployed last quarter can’t reliably answer “what were our top-performing products in EMEA last month?” without hallucinating a metric, misapplying a regional filter, or surfacing a number nobody in the room can trace back to a source.
The instinct is to blame the model. Or the prompt. Or the team that built the agent. But across dozens of these conversations, a different explanation keeps surfacing: the data was built for humans to interpret, not for machines to reason with. And those are fundamentally different requirements.
They’re not alone. According to a Gartner survey of data management leaders, 63% of organizations either lack or are unsure whether they have the right data management practices for AI. Only 4% of organizations report that their data is actually prepared for AI. Gartner predicts that through 2026, organizations will abandon sixty percent of AI projects unsupported by AI-ready data. And in their 2025 Hype Cycle for Artificial Intelligence, Gartner identified AI-ready data as one of the two fastest-advancing technologies, alongside AI agents, both sitting at the Peak of Inflated Expectations.
The numbers confirm what practitioners already feel: being BI-ready is not the same as being AI-ready.
 BI Ready vs AI Ready Data | Source: Author
BI Ready vs AI Ready Data | Source: Author
BI-ready is not AI-ready
Permalink to “BI-ready is not AI-ready”This distinction sounds academic until you see it break in production.
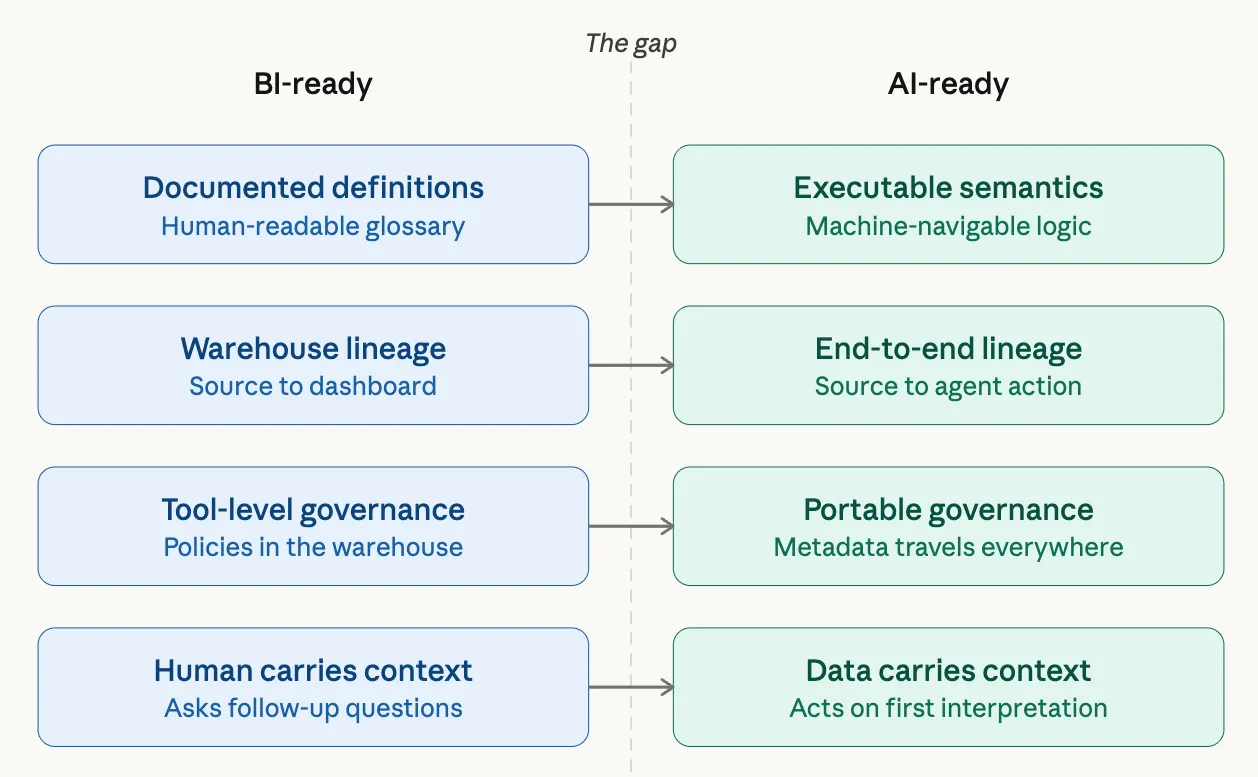
BI-ready data is modeled, cleaned, and documented so that a human analyst can find it, understand it, and build a report. The analyst brings their own judgment. They know to ask clarifying questions. They know that “revenue” means something different in finance than in product. They know that last quarter’s APAC numbers use a different methodology than EMEA’s. The data doesn’t need to encode all of that because the human carries the context.
AI-ready data has to encode everything the human carries in their head. Every definition needs to be unambiguous and machine-navigable. Every business rule needs to be executable, not just documented. Every policy, restriction, and edge case needs to travel with the data into whatever system consumes it, whether that’s a prompt, a vector store, a fine-tuning pipeline, or an agent’s reasoning chain.
The simplest way to think about it: BI-ready data is designed for someone who can ask a follow-up question. AI-ready data is designed for something that will act on its first interpretation with total confidence.
 BI Ready data is not AI ready | Source: Author
BI Ready data is not AI ready | Source: Author
Three gaps that break AI in BI-mature organizations
Permalink to “Three gaps that break AI in BI-mature organizations”If your BI stack is solid, you’re not starting from zero. But three specific gaps tend to surface the moment AI enters the picture.
Gap 1: Your AI can’t see what your BI users see
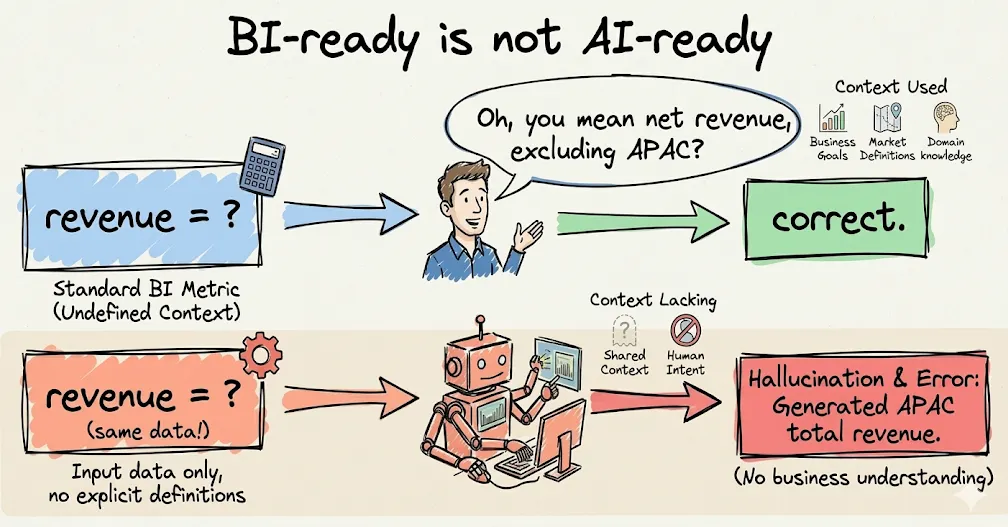
Permalink to “Gap 1: Your AI can’t see what your BI users see”A BI user opens a dashboard and sees a metric called “active customers.” Behind the scenes, they know (or can find out) that “active” means “at least one login in the past 90 days,” that it excludes trial accounts, and that the APAC definition uses 60 days because of a regional policy decision made in 2023.
An AI agent sees a column called active_customers and a catalog description that says “count of active customers.” That’s it. The 90-day window, the trial exclusion, the APAC exception: none of that is in a form the machine can consume. So the agent does what any confident system does with partial information. It guesses. And it’s wrong in ways that are difficult to catch because the answer looks plausible.
 What a BI user sees versus what an AI agent sees | Source: Author
What a BI user sees versus what an AI agent sees | Source: Author
This gap exists because BI documentation was written for humans who can infer context. AI systems can’t infer. They need context stated explicitly, in a structured form they can navigate programmatically.
Gap 2: You can’t explain an AI answer the way you explain a KPI
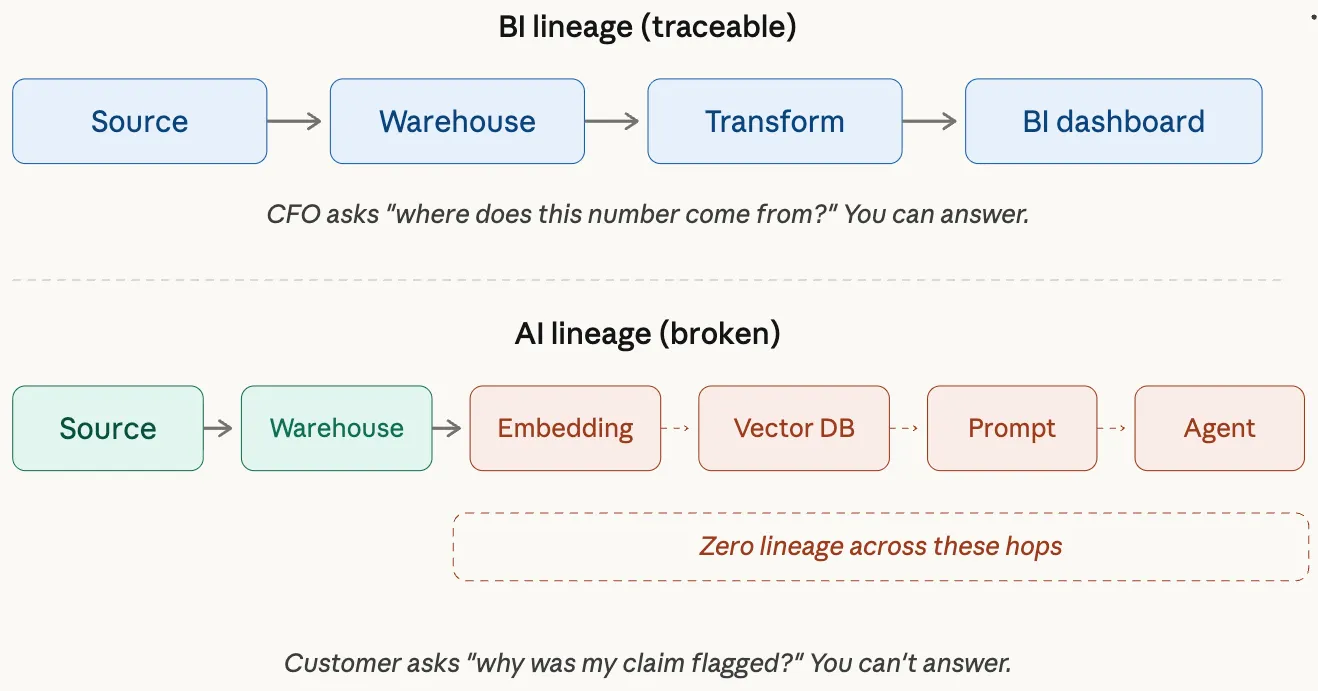
Permalink to “Gap 2: You can’t explain an AI answer the way you explain a KPI”BI has lineage. You can trace a number from a dashboard back through the transformation layer, into the warehouse, and out to a source system. When the CFO asks “where does this number come from?” you have an answer.
AI workflows break that chain. The data goes from your warehouse into a feature store, gets embedded in a vector database, gets retrieved by a RAG pipeline, gets assembled into a prompt, and gets interpreted by a model that produces an output the agent acts on. Each of those hops is a transformation, and most organizations have zero lineage across them.
 BI lineage chain vs. AI lineage chain | Source: Author
BI lineage chain vs. AI lineage chain | Source: Author
When an AI agent tells a customer their claim was flagged for review, and the customer asks why, the answer is “we don’t know which data informed that decision, through which path, under which policies.” That’s not a technical debt problem. That’s a trust problem. And it’s the kind of trust gap that ends AI programs.
Gap 3: Your governance stops at the warehouse door
Permalink to “Gap 3: Your governance stops at the warehouse door”In a BI world, governance means row-level security, column-level permissions, and access controls in the warehouse and the BI tool. Sensitive data is masked or restricted. Policies are enforced at query time.
In an AI world, data doesn’t stay in the warehouse. It flows into training datasets, vector stores, prompt templates, agent memory, and fine-tuning pipelines. A PII field that’s properly masked in Snowflake might appear unmasked in a vector embedding that was created before the masking policy was applied. A regional data residency rule that’s enforced in the warehouse might be violated the moment data crosses into an LLM hosted in a different jurisdiction.
Governance that stops at the warehouse door is governance that stops before AI starts. Sensitivity labels, usage constraints, regional restrictions, and retention policies need to be first-class metadata that travels with the data everywhere it goes.
What transfers and what doesn’t
Permalink to “What transfers and what doesn’t”The good news: BI-mature organizations have real advantages. The work isn’t wasted. It’s just incomplete.
What transfers directly: high-quality, reliable data. Catalog and glossary practices. Stewardship as a discipline. Column-level lineage across the warehouse layer. Access control frameworks. Data product thinking. The organizational muscle of caring about data quality. These are hard-won assets.
What doesn’t transfer: documentation that’s human-readable but not machine-navigable. Lineage that stops at the BI layer. Governance policies that are enforced in specific tools but not as portable metadata. Definitions that exist in Confluence pages and glossary entries but aren’t executable. The implicit knowledge that senior analysts carry in their heads and that nobody has ever had to formalize because a human was always at the end of the chain.
The bar moved. Not because the old bar was wrong, but because the consumer changed. The consumer used to be a person who could compensate for ambiguity. Now it’s a machine that amplifies it.
Five moves from BI-ready to AI-ready
Permalink to “Five moves from BI-ready to AI-ready”For teams that already have solid BI foundations, the path isn’t a rebuild. It’s an extension. Five specific moves close most of the gap.
1. Make your semantics executable, not just documented
Permalink to “1. Make your semantics executable, not just documented”If your business terms live in a glossary as text descriptions, they’re BI-ready. If they’re expressed as logic that a machine can call, apply, and validate, they’re AI-ready. “Revenue” defined in a Confluence page helps an analyst. “Revenue” defined as a calculation with scope, exceptions, and ownership in a form an agent can query helps an AI system. The format matters less than the principle: definitions need to be something a machine can use, not just something a human can read.
The hard part: most organizations have hundreds of business terms, and fewer than twenty percent are defined precisely enough to be executable. Start with your top twenty. That alone can take four to six weeks of work with subject matter experts, because the moment you try to make a definition executable, you discover that different teams have been using it differently for years.
2. Extend lineage into AI workflows
Permalink to “2. Extend lineage into AI workflows”Your lineage probably covers source systems through the warehouse to BI dashboards. That’s the BI lineage chain. The AI lineage chain adds feature stores, embedding pipelines, vector databases, prompt assemblies, model inputs, and agent actions. Every one of those is a transformation. If you can’t trace an AI output back through all of them, you can’t explain the output. Start with one AI use case and map the full chain. The gaps will be obvious.
The hard part: most lineage tools were built for SQL transformations, not for embedding pipelines or prompt assembly. The tooling gap is real. You will likely need to instrument some of these hops manually before automated solutions catch up. Expect to spend time stitching together metadata across systems that were never designed to talk to each other.
3. Turn your BI artifacts into training data for your context layer
Permalink to “3. Turn your BI artifacts into training data for your context layer”Your existing dashboards, queries, metric definitions, and filter logic are a goldmine. They encode how the business actually asks and answers questions. An AI system trained on “here’s how we calculate churn for the board deck” is dramatically more reliable than one that has to infer it from raw schema. Use your BI layer as ground truth for what the business means, and feed that into whatever context infrastructure your AI systems consume.
The hard part: BI artifacts are messy. Dashboards accumulate over years, with conflicting logic, abandoned metrics, and undocumented filters. Before you can use them as training data, you need to curate them. That means deciding which dashboards represent current business logic versus which are legacy. Not glamorous work, but skipping it means training your AI on contradictions.
4. Attach policies and sensitivity labels to every hop, not just the warehouse
Permalink to “4. Attach policies and sensitivity labels to every hop, not just the warehouse”PII tags, regional restrictions, allowed use cases, retention rules: these need to be metadata that travels with the data, not policies enforced at a specific tool layer. When data moves from Snowflake into a vector store, the sensitivity label should move with it. When it gets assembled into a prompt, the usage constraint should be queryable. If your governance is tool-specific, it’s BI governance. If it’s portable metadata, it’s AI governance.
The hard part: most governance today is enforced at the tool level, not the metadata level. Moving to portable governance means rethinking where policies live. It also means getting legal, compliance, and security teams involved in decisions about AI data flows, which adds coordination overhead. The teams that underestimate this step are usually the ones that end up with PII in a vector store they can’t audit.
5. Build data products for AI consumers, not just human ones
Permalink to “5. Build data products for AI consumers, not just human ones”A BI data product needs a name, a description, an owner, and a schema. An AI data product needs all of that plus: purpose (what this data is for), freshness guarantees (how current it is), quality thresholds (what “good enough” means for this use case), appropriate use (what you should and shouldn’t do with it), and context dependencies (what other data or knowledge you need to interpret it correctly). AI-ready data products look more like contracts than tables.
The hard part: building data products with this level of specification takes significantly more time than traditional documentation. Many teams find that defining “appropriate use” and “context dependencies” forces conversations that have never happened before, conversations about what data is actually for and what it should never be used for. Those conversations are valuable, but they are not fast.
Anti-patterns to watch for
Permalink to “Anti-patterns to watch for”A few patterns we see teams fall into repeatedly:
Treating “AI-ready” as another round of data quality work.
Permalink to “Treating “AI-ready” as another round of data quality work.”Quality is necessary but it’s the floor, not the ceiling. You can have perfect quality scores and still fail at AI because quality measures completeness and format, not meaning. As Gartner notes, “high-quality” data by traditional standards does not equate to AI-ready data. When training an algorithm, the model needs representative data, including the outliers you normally remove.
Assuming the BI semantic layer is enough context for AI.
Permalink to “Assuming the BI semantic layer is enough context for AI.”It’s a start, but BI semantic layers were designed for query generation, not for reasoning. An AI agent needs to understand not just how to calculate a metric but when to use it, what its limitations are, and what exceptions apply.
Building a giant knowledge graph before shipping a single AI use case.
Permalink to “Building a giant knowledge graph before shipping a single AI use case.”The teams that move fastest start with one use case, map the context it needs, build that context, test it, and expand. The teams that stall start with “let’s model the entire enterprise ontology” and are still modeling six months later.
Letting AI pilots bypass governance because they’re experiments.
Permalink to “Letting AI pilots bypass governance because they’re experiments.”Every experiment that ships without governance is a precedent. When it works and someone wants to scale it, the governance gap scales too. Build governance into the first pilot, not the tenth.
How to go about making data AI-ready
Permalink to “How to go about making data AI-ready”The five moves above tell you what to change. This section addresses the how: the underlying framework for thinking about AI-readiness as a practice, not a project.
Gartner’s research on AI-ready data offers a useful framing. You can prove your data is ready for AI by answering three questions: Is the data aligned to the use case? Can you qualify it for AI consumption? And can you govern it across every system it touches? These map to three pillars. But for BI-mature teams, each pillar has a specific meaning that goes beyond the generic advice.
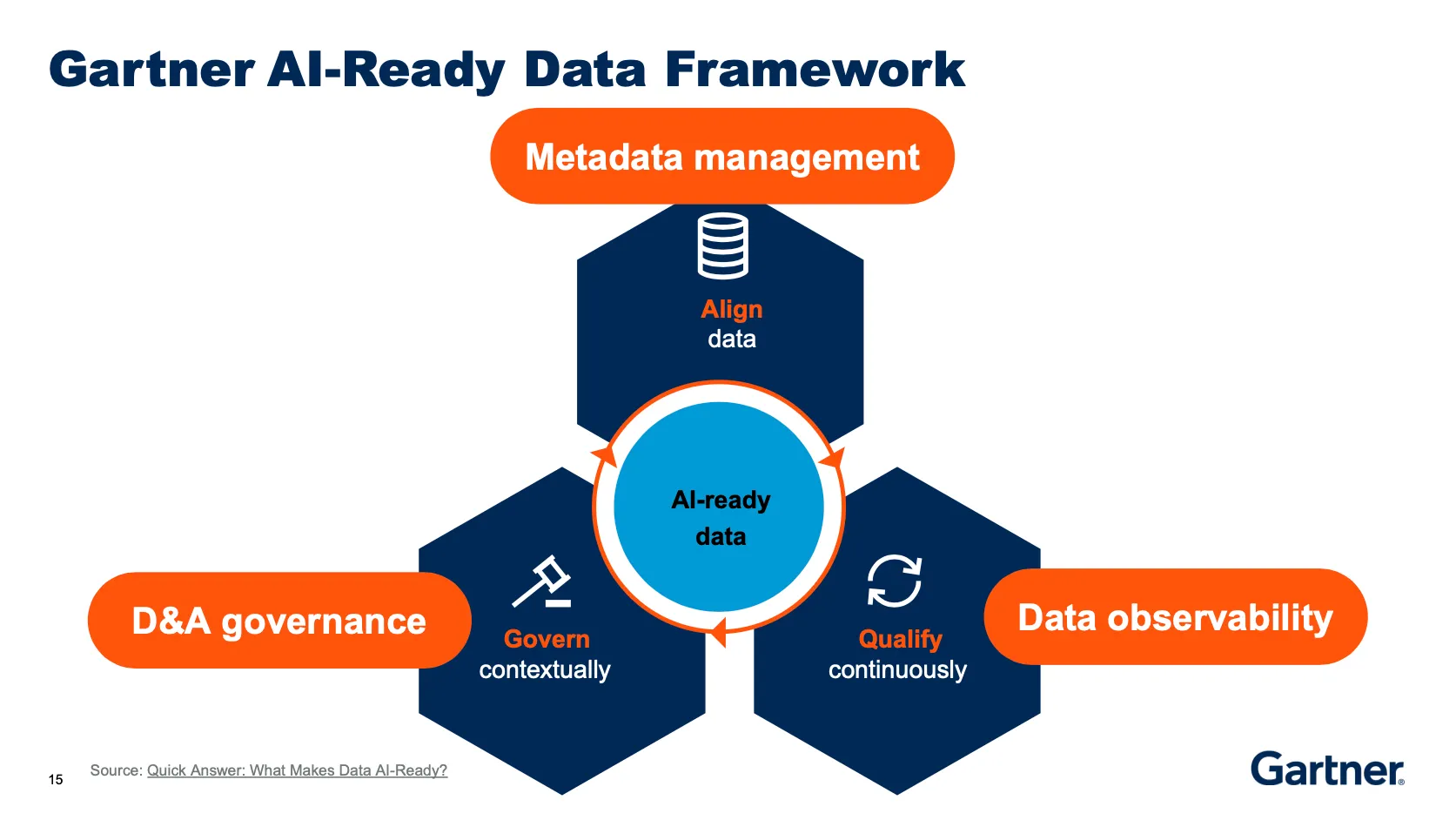
Pillar 1: Align data to AI use cases
You cannot make all your data AI-ready in advance. Readiness depends on how the data will be used. A predictive maintenance algorithm needs entirely different data than a GenAI application applied to enterprise documents. This is one of the sharpest differences from BI, where a well-modeled warehouse can serve dozens of use cases. AI use cases are specific, and the data requirements are specific to each one.
For BI-mature teams, this means resisting the instinct to boil the ocean. Pick your highest-value AI use case. Define exactly what data it needs. Identify where that data lives today, what’s missing, and what needs to change. The use case is the forcing function. It tells you exactly which data to focus on first, and it prevents the common trap of trying to make everything AI-ready simultaneously, which is how teams spend six months and ship nothing.
Pillar 2: Qualify the data for AI, not just for BI
Qualification goes beyond traditional data quality, and this is where many BI-mature teams get caught. In a BI context, you clean data by removing outliers and standardizing formats. In an AI context, you often need those outliers because the model has to learn from them. A dataset that scores perfectly on traditional quality metrics can still be useless for AI if it’s not representative of the patterns the model will encounter in production.
Qualification also means ensuring semantic richness. Can a machine understand what each field means, what units it uses, what business rules apply, and what exceptions exist? This is where metadata evolves from passive documentation to active intelligence: the kind that an AI system can consume programmatically rather than requiring a human to interpret. Gartner’s Melody Chien identifies three core components for building this readiness: metadata management, data quality, and data observability. The real leverage, she argues, comes at the intersection of all three.
Pillar 3: Govern for AI, not just for BI
Governance in the AI context means ensuring that data policies, sensitivity labels, usage constraints, and compliance rules travel with the data into every AI workflow. It means detecting sensitive data automatically, protecting it when it’s fed into models, and maintaining a clear chain of accountability from source data through model output.
Gartner is blunt on this point: organizations with basic or manual metadata management practices will face serious challenges making their data AI-ready. Traditional data management operations are too slow, too structured, and too rigid for AI teams. The governance journey starts at the executive level but depends on maturing metadata management as a foundational step, evolving metadata from passive records into active, automated intelligence that drives continuous improvement.
This is not a one-time project
Permalink to “This is not a one-time project”Perhaps the most important insight from Gartner’s framework, and the one that aligns with what every data management practitioner already knows: AI-ready data is not a destination. It’s a continuous practice. As AI use cases evolve, so must your data management infrastructure. The organizations that treat AI-readiness as a “done” state will find their models degrading as business logic changes, new data sources emerge, and regulatory requirements shift.
The difference is that AI raises the stakes. When the consumer was a human analyst, an outdated definition caused confusion. When the consumer is an AI agent acting autonomously, an outdated definition causes wrong decisions at scale.
A readiness check you can run on Monday
Permalink to “A readiness check you can run on Monday”Five questions to take into your next team meeting. If the honest answer to most of these is “no,” you know where the gaps are.
-
Can we express our top 20 business terms as executable logic, not just text definitions?
-
Can we trace any AI output back through every transformation to the source data and the policies that governed it?
-
Do sensitivity labels and usage constraints follow data into prompts, vector stores, and training pipelines?
-
Do our data products include purpose, freshness, quality thresholds, and appropriate use, or just schema and descriptions?
-
Is institutional knowledge (exceptions, workarounds, business rules that live in people’s heads) captured somewhere a machine can query?
If you got through that list without discomfort, either you’re ahead of almost everyone, or the questions need to be harder.
The reframe
Permalink to “The reframe”The question “is our data AI-ready?” is a dead end because it implies a single bar to clear. The more useful question is: “can the machines that consume our data understand it the way our best humans do?”
For most organizations, the answer is no. Not because the data is bad, but because the context that makes the data useful was never built for a machine to consume. The missing piece is a shared context layer: the metadata, semantics, and policies that let humans and AI interpret data the same way.
Your BI foundations are real. The definitions, the lineage, the governance, the quality: all of it matters. But the bar moved when the consumer changed from a human who asks follow-up questions to a machine that acts on its first interpretation.
The gap between BI-ready and AI-ready isn’t a data problem. It’s a context problem. And the path from one to the other is shorter than most teams think, if they know which five moves to make.
This article is written for organizations with mature BI programs looking to extend toward AI. If your organization is earlier in the journey, without established BI foundations, the path to AI-readiness looks different and deserves its own treatment. The principles here still apply, but the starting point and sequencing change significantly.
References
Permalink to “References”Gartner, “Lack of AI-Ready Data Puts AI Projects at Risk,” February 26, 2025.
Gartner, “AI-Ready Data Essentials to Capture AI Value,” December 2025.
Gartner, “Follow These Five Steps to Make Sure Your Data Is AI-Ready,” Melody Chien, Ehtisham Zaidi, Mark Beyer, October 18, 2024.
Gartner, “Top Predictions for Data and Analytics in 2026,” March 11, 2026.
Gartner Hype Cycle for Artificial Intelligence, 2025. AI-ready data identified as one of the two fastest-advancing technologies.
Gartner, “Quick Answer: What Makes Data AI-Ready?” Roxane Edjlali.
Thanks for reading Metadata Weekly!
The Insight Index: Your Weekly Data & AI Digest
Permalink to “The Insight Index: Your Weekly Data & AI Digest”Top resources, social posts, and recommended reads, carefully curated for you.
-
The 8 Levels of Agentic Engineering — Bassim Eledath
-
**Understanding Context — **Bill Inmon & Jessica Talisman
-
**More Context Is Not Better Context — **Eric Simon
-
**Relevance of Business Models for Data — **Dylan Anderson
-
**The Structure of Engineering Revolutions — **John Allsop
-
**Gartner D&A 2026: Where the Context Layer Became a Budget Line Item — **TD Sarma
That’s all for this edition. Stay curious, keep exploring, and see you all in the next one!
About Context & Chaos
Permalink to “About Context & Chaos”Context & Chaos isn’t just a newsletter. It’s shared community space where practitioners, builders, and thinkers come together to share stories, lessons, and ideas about what truly matters in the world of data and AI: context engineering, governance, architecture, discovery, and the human side of doing meaningful work.
Our goal is simple, to create a space that cuts through the noise and celebrates the people behind the amazing things that are happening in the data & AI domain.
Whether you’re solving messy problems, experimenting with AI, or figuring out how to make data more human, Context & Chaos is your place to learn, reflect, and connect.
Got something on your mind? We’d love to hear from you. Hit Reply!
Originally published in the Context & Chaos newsletter on Substack.
Share this article