Most AI failures don’t announce themselves.
They don’t trigger outages, customer escalations, or emergency reviews. Instead, they quietly stall. Promising demos fail to become products. Products fail to bring revenue. Excitement gets a reality check.
By the time organizations realize something is wrong, the narrative has already shifted: AI is overhyped, the ROI isn’t there, the models aren’t ready.
But that explanation is convenient and incomplete.
AI Foundations | Source: Author
The pattern behind the silence
Permalink to “The pattern behind the silence”As companies experimented aggressively with GenAI over the past 2 years, a pattern emerged. The failures weren’t caused by model limitations or a lack of talent. They were caused by organizations looking at AI through the wrong lens.
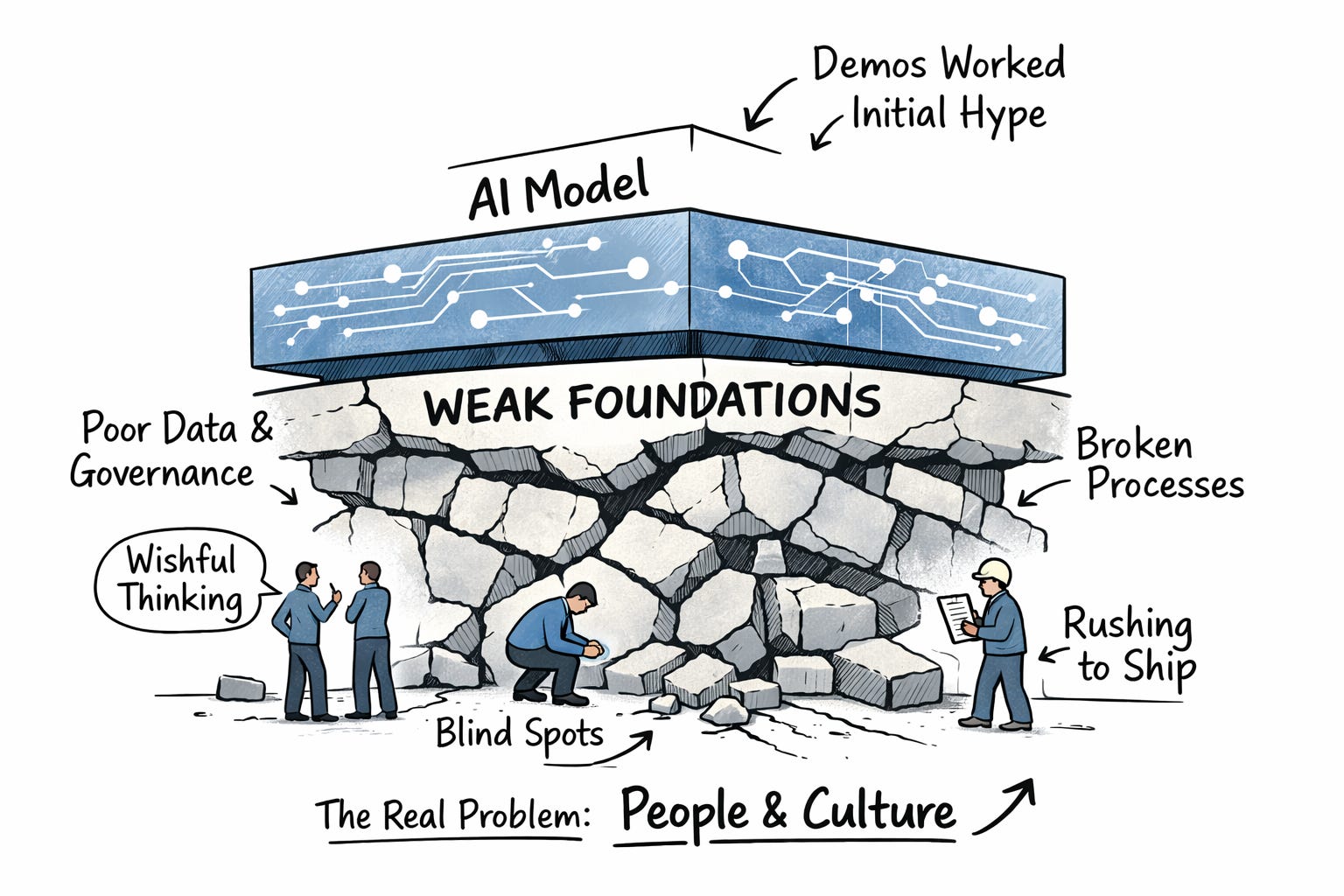
Most AI investments didn’t stall because the models weren’t capable, but because of everything underneath. Organizations tried to scale AI without the foundational infrastructure required for it: reliable data, clear governance, shared business context, and operational systems that could support learning over time.
That analysis is right. But I’m more interested in a deeper question:
Why did so many capable organizations choose to ignore those foundations in the first place?
My thesis is simple, but uncomfortable: weak foundations are rarely the root problem. They’re usually a symptom. The real constraint is organizational: how companies make decisions, reward work, assess their own capabilities, and learn under uncertainty.
In other words, most AI failures are people problems long before they become technical ones.
Foundations vs. model capabilities: a false bet, for understandable reasons
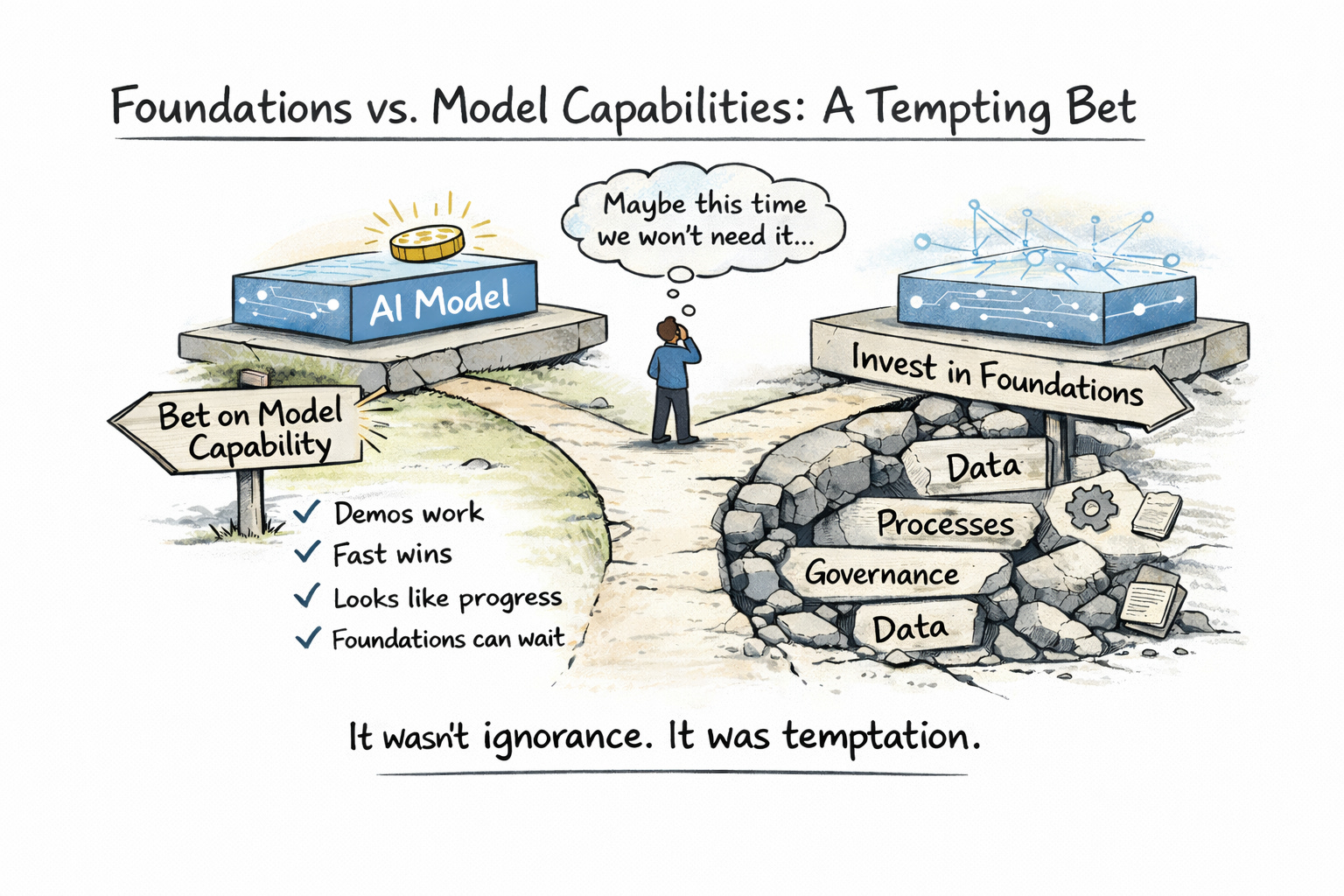
Permalink to “Foundations vs. model capabilities: a false bet, for understandable reasons”The diagnosis that failures in AI are a foundation problem and not a model problem is incomplete without understanding why organizations made that bet.
It wasn’t ignorance. It was the temptation to believe that everything would work as intended out of the box.
Frontier models were marketed as general-purpose intelligence. The promise — explicit or implicit — was that sufficiently capable models could compensate for messy data, brittle systems, and unclear processes. If that were true, the slow, unglamorous work of fixing foundations could be postponed indefinitely.
Many leaders knew foundations mattered. They just hoped this time would be different.
That hope exposed two deeper organizational gaps:
Capability blind spots: Companies overestimated their ability to operationalize AI quickly, or underestimated the complexity of their existing systems.
Self-awareness gaps: Without a clear understanding of their own constraints — technical, cultural, organizational — many organizations defaulted to copying what others were doing.
Neither problem is primarily technical. Both are reflections of people, incentives, and leadership.
Foundations vs Models | Source: Author
Incentives, fear, and the optics of progress
Permalink to “Incentives, fear, and the optics of progress”If this feels familiar, that’s because it mirrors the long-standing tension between shipping features and paying down technical debt.
Foundations don’t ship. Products do.
Most organizations reward visible progress: launches, announcements, adoption metrics. They rarely reward the work required to make those outcomes sustainable. Fixing data quality, untangling ownership, or formalizing context doesn’t look like innovation, even when it’s the prerequisite for it.
Layer on top of that:
- Fear of missing out
- Competitive pressure
- The need to signal momentum externally
And the choice becomes predictable. Shipping something — anything — feels safer than slowing down to confront foundational gaps that are hard to explain and harder to quantify.
Rethinking “failure” in the AI era
Permalink to “Rethinking “failure” in the AI era”The framing of 2025 as a year of quiet AI failures is fair from a short-term ROI perspective. But I’m not convinced those failures were avoidable — or even undesirable.
AI foundations aren’t one thing. Nor are they a checklist. They are a web of interdependencies: data quality, observability, governance, reliability, context, ownership. For organizations without prior foundational maturity, it’s not obvious what to fix first or whether fixing anything in isolation would help.
Experimentation clarified reality.
Building and breaking systems revealed where the true constraints were. According to the MIT NANDA report, of the 60% of organizations that evaluated enterprise-grade AI tools, only 20% reached pilot stage and just 5% made it to production. Failures were attributed to “brittle workflows, lack of contextual learning, and misalignment with day-to-day operations.” This isn’t a model capability problem — it’s an organizational one.
Failed pilots produced the evidence required to justify foundational investment. Many recent model capabilities reflect enterprise pain points surfaced through these experiments — OpenAI’s function calling announcement mentions customer feedback multiple times; Claude 3’s capabilities announcement cites several features driven by enterprise customer needs.
In that sense, some failures weren’t dead ends. They were the cost of education.
Budget is not the root cause of success
Permalink to “Budget is not the root cause of success”Successful organizations often allocated 50 to 70% of AI budgets to foundations. That’s directionally correct, but dangerous if misinterpreted.
Money doesn’t create clarity. In fact, it’s often a result of clarity.
High foundation investment is usually the result of organizational confidence, not the cause. Confidence that comes from people who understand:
- What “good” looks like in their environment
- Where the real bottlenecks are
- Which tradeoffs are worth making
Without that clarity, increasing budget often amplifies dysfunction rather than resolving it.
Where AI actually delivered value
Permalink to “Where AI actually delivered value”Internal tooling and back-office automation outperformed customer-facing AI. Internal use cases work better because:
- They compose deterministic systems rather than replacing them
- They tolerate rough edges
- They bypass legacy complexity
- They optimize for individual leverage rather than product guarantees
More broadly, LLMs delivered disproportionate value as tools for personal augmentation: research, synthesis, writing, prototyping, and coding. Productizing that value proved far harder — not because models were weak, but because organizations weren’t ready.
Competing explanations, same destination
Permalink to “Competing explanations, same destination”The MIT NANDA report argues that learning — not infrastructure or regulation — is the core barrier to scaling GenAI. At first glance, this seems to contradict the emphasis on foundations.
I see them as sequential, not conflicting.
As models improve their ability to learn and adapt, they surface organizational constraints faster. Better intelligence doesn’t reduce the need for context — it amplifies it. And context, both technical and human, comes from organizations understanding themselves.
Which brings us to the real missing foundation.
The missing foundation: organizational self-awareness
Permalink to “The missing foundation: organizational self-awareness”AI performance depends on context. But context doesn’t exist in systems. It originates in people.
Organizational self-awareness is the ability to accurately perceive:
- What the organization is good at
- Where it struggles
- How decisions are made
- What work is rewarded
- Where knowledge lives
- Who owns which outcomes
Without this clarity, technical investments — no matter how well-funded — fail to compound.
A practical self-awareness diagnostic
Permalink to “A practical self-awareness diagnostic”This isn’t a maturity model or a scorecard. It’s a set of questions teams can revisit as AI efforts evolve.
1. The Campsite Test: Are our AI initiatives leaving systems healthier than we found them, or merely adding new layers of complexity to already fragile foundations?
2. The Incentives Test: Who gets rewarded for foundational work? Not rhetorically, but in recognition, promotions, visibility, and career progression.
3. The Context Test: Do teams share a common definition of business context? Do they know where it lives, how it’s maintained, and who owns it?
4. The Reality Test: Are we making decisions based on our actual capabilities or aspirational ones borrowed from other organizations?
5. The Learning Test: When experiments fail, do we extract signals and adjust course, or add them to the “innovation portfolio” slide and quietly move on to the next initiative?
Organizations that score poorly here don’t fail because they lack technology. They fail because they don’t see themselves clearly enough to use it well.
Closing
Permalink to “Closing”Most conversations about AI foundations focus on data, infrastructure, and governance. Those matter, but they are downstream.
Foundations are built by people before they’re built in systems. Until organizations develop the self-awareness to understand how they work, AI will continue to expose the same cracks, just faster.
The future of AI adoption won’t be decided by models alone. It will be decided by whether organizations are willing to look in the mirror.
Thanks for reading Context & Chaos!
About Context & Chaos
Permalink to “About Context & Chaos”Context & Chaos isn’t just a newsletter. It’s shared community space where practitioners, builders, and thinkers come together to share stories, lessons, and ideas about what truly matters in the world of data and AI: context engineering, governance, architecture, discovery, and the human side of doing meaningful work.
Our goal is simple, to create a space that cuts through the noise and celebrates the people behind the amazing things that are happening in the data & AI domain.
Whether you’re solving messy problems, experimenting with AI, or figuring out how to make data more human, Context & Chaos is your place to learn, reflect, and connect.
Got something on your mind? We’d love to hear from you.
Originally published on the Context & Chaos Substack newsletter.
Share this article