I have had some version of the same conversation with a CIO almost every day this year. Their team has read about context layers, or seen the term in a Gartner note. They know it matters and that it sits somewhere underneath the agents they are putting into production. Then comes the real question.
- What is it, actually?
- A data catalog with new branding?
- A semantic layer?
- A knowledge graph?
- Memory, decision traces, context graphs?
All of those things matter, but none of them is the context layer. So let me break down the buzzwords and make clear what a context layer actually is, what it is not, and where it fits into the AI platform architecture.
First, what “context” means
Permalink to “First, what “context” means”An AI agent operating inside a real business needs three kinds of context, and they map directly onto what the layer has to encode.
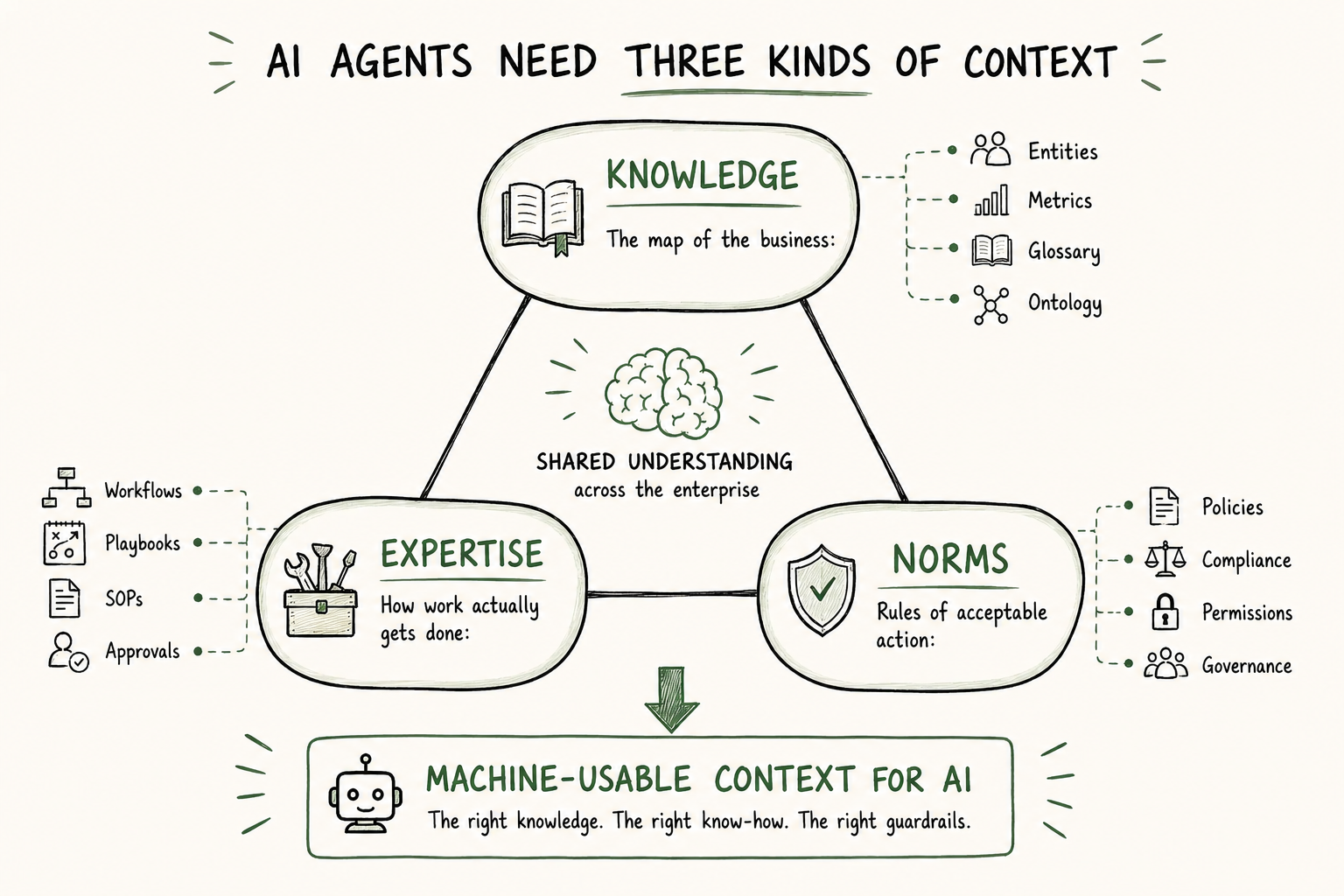
Three Kinds of Context: Knowledge, Expertise, and Norms | Source: Author
- Knowledge is the map of the business: entities, definitions, metrics, relationships, glossary terms, what lets a human and an AI agree on what a customer or revenue actually mean.
- Expertise is how work actually gets done: procedures, workflows, playbooks, the know-how behind running the monthly close or triaging a support escalation, today scattered across SOPs, tickets, Slack threads, and the heads of the three people on the team who remember why we do it this way.
- Norms are the rules of acceptable action: policies, permissions, approval paths, compliance constraints. They tell the agent not just what is true and how to do it, but what is allowed: which customer gets which discount, which actions need a human approver, which data cannot leave which jurisdiction.
Hold onto those three words. In the substrate, they reappear wearing different clothes: knowledge becomes data and semantics, expertise and norms together become skills.
What an enterprise context layer actually is
Permalink to “What an enterprise context layer actually is”An enterprise context layer is the system that turns knowledge, expertise, and norms into machine-usable context for AI, across the heterogeneous landscape of data, business systems, and AI tools. It exists so agents can operate with shared meaning, the right information at the right moment, and the governance to act safely and consistently. Think of it as a shared enterprise brain: the foundation every agent reaches into, learns from, and contributes back to. That is what makes the tenth agent dramatically better than the first, because each one inherits what the previous ones learned.
The layer has two halves: a core context substrate, the machine-usable substance of context itself in three integrated parts, and five capabilities, the operating system that produces, governs, delivers, and improves that substrate over time.
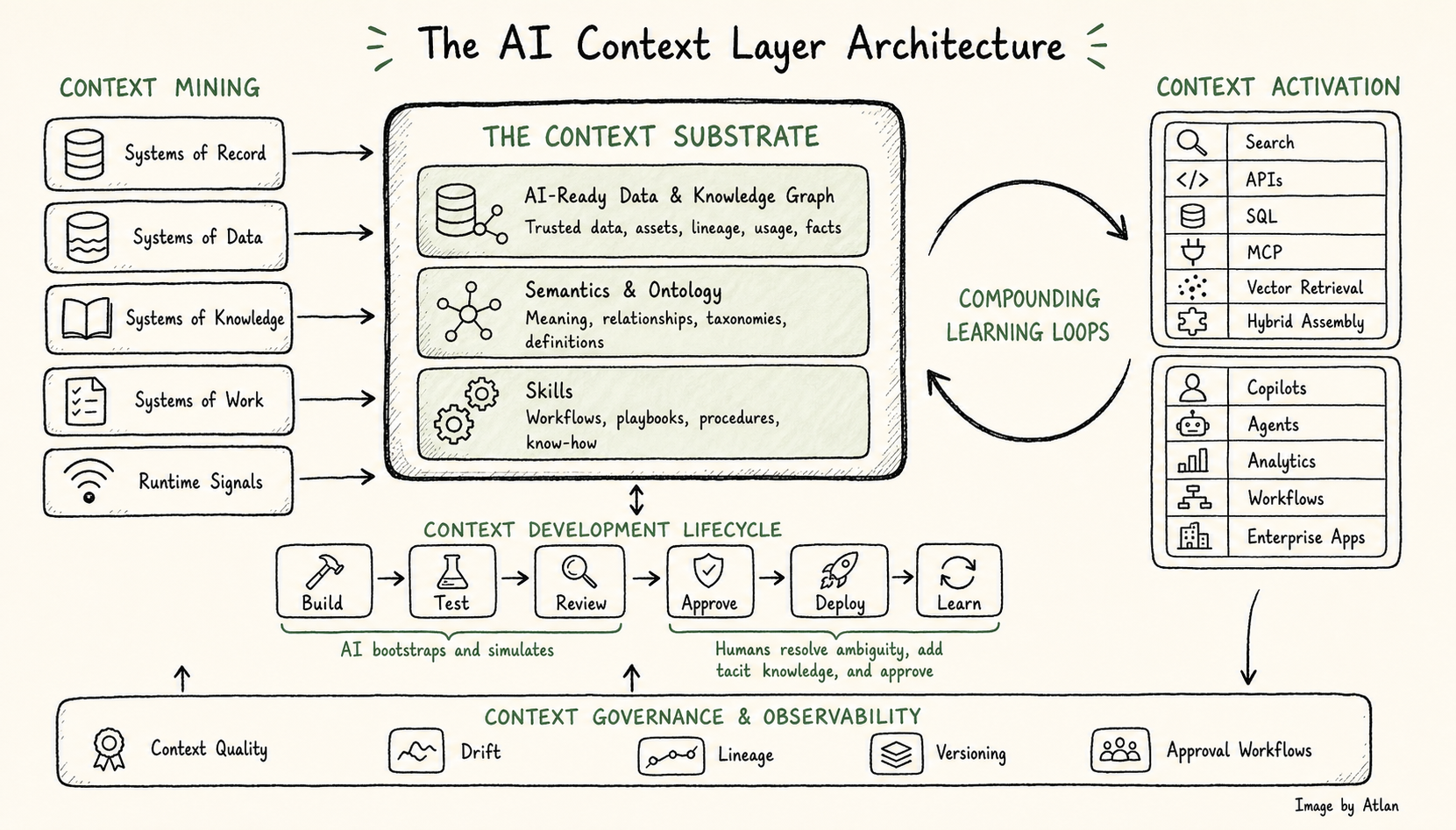
The AI Context Layer Architecture
Part 1: The core context substrate
Permalink to “Part 1: The core context substrate”The substrate has three tightly integrated parts, each answering a question an agent needs answered before it can act. What data can I trust? That is AI-ready data and the knowledge graph. What do things mean, and how are they connected? That is semantics and ontology. How does work get done here, and what is allowed? That is skills. You cannot have one without the others: data without semantics is uninterpretable, semantics without data describes a business nobody can query, and both without skills describe how the company works without being able to operate it.
AI-ready data and the knowledge graph
Permalink to “AI-ready data and the knowledge graph”This is the integrated, trusted, AI-ready representation of an enterprise’s data and knowledge assets. It makes structured data machine-readable, enriching tables with the context agents need such as descriptions, join paths, and the ways humans typically query that data, and it makes unstructured knowledge accessible in a governed way. An underrated piece of this is canonical knowledge: the narrative that defines how the company thinks, sells, builds, and speaks. Strategy documents, brand voice guides, product positioning, org charts, the ideas experienced employees carry in their heads and every new hire absorbs in their first 90 days. A layer that ignores canonical knowledge produces agents that answer questions but have no idea what the company is actually trying to do.
Semantics and ontology, the map of the business
Permalink to “Semantics and ontology, the map of the business”If AI-ready data tells you what exists, semantics and ontology tell you what it means and how it connects. Semantics are the shared definitions of business concepts: glossary entries, metric definitions, the vocabulary every team uses and disagrees on, like what counts as an active customer. Ontology is the structure of how those concepts relate: Customers to Accounts to Transactions, Products to SKUs to Inventory. This is what lets agents reason across the business instead of treating each system as an island; without it, retrieval is brittle and the agent fetches strings it cannot interpret. Ontologies are not new. What is new is that AI can now build and curate this knowledge at the pace the business moves, reading query logs and reconciling conflicting documents, so a living knowledge model is finally tractable at enterprise scale.
Skills, the reusable procedures and norms
Permalink to “Skills, the reusable procedures and norms”Knowing what something means is not the same as knowing what to do next. A semantic layer can tell an agent what gross margin is; it cannot tell the agent how to close the month or which approval path matters in practice. This is where skills come in. Skills make procedural knowledge, the way work gets done and the norms that constrain it, durable and machine-usable.
A skill is the new primitive that does for procedural knowledge what code did for logic in software. That comparison is worth slowing down on, because it is the whole argument. Before software had functions, logic lived as instructions you re-derived every time you needed them: copied between programs, half-remembered, subtly different in each place they ran. The function turned that into something you could name, version, test, and call from anywhere, and the moment logic became a reusable unit, software started compounding instead of being rewritten.
Procedural knowledge in the enterprise is stuck where logic was before functions. The way you actually run the monthly close, qualify a lead, or handle a refund exception lives as prompts in someone’s Notion doc, tribal memory, and steps people improvise differently each time. A skill is that knowledge made durable: a reusable, versionable, testable unit of how-to, with its own triggers, edge cases, and owner. When an organization treats skills as first-class assets rather than scattered prompts, the same thing happens that happened to software. Procedural knowledge stops being re-derived by every agent and every employee, and starts compounding. Two problems make this hard, and both are capabilities in Part 2: building the library, which is a mining problem, and maintaining and governing it as the business changes, which is a lifecycle problem. Everything else is an operating system around this primitive.
Part 2: The five capabilities
Permalink to “Part 2: The five capabilities”The substrate is what the context layer is. The five capabilities are what it does.
Context Mining: most business context was never written down
Permalink to “Context Mining: most business context was never written down”If you want to understand how a business thinks it runs, read its documentation. If you want to understand how it actually runs, observe its systems. Most business context is hidden across systems of record, data, knowledge, and work, and across runtime signals like query history, agent traces, and human overrides. The first job of the layer is to connect to that fragmented reality and reverse-engineer business operations from it. Mining semantics looks like this: AI reads your SQL query history, notices Sales and Finance define Annual Recurring Revenue differently, and surfaces the conflict for a human to resolve company-wide. AI does the heavy lifting; humans decide.
Mining skills is harder, because most procedural knowledge was never written down. The durable methods are system-led: extracting a skill from an agent session after the work is done manually, building process maps from event logs, capturing context at the point where an agent fails, and running structured AI interviews to surface judgment that observation cannot reach. None produces a finished skill alone. They produce candidates the next capability tests, approves, and deploys.
The development lifecycle: context needs an SDLC of its own
Permalink to “The development lifecycle: context needs an SDLC of its own”Software engineering created the software development lifecycle to manage how code is built, reviewed, versioned, and deployed. Companies that want a real shot at becoming AI-native need a context development lifecycle to do the same for context: created, tested, approved, deployed, retired. It can no longer live as scattered prompts and isolated team decisions; it has to become a first-class asset that is reusable, reproducible, versioned, and governable. AI handles the building, testing, and reviewing; humans own approval and deployment, deciding whether a candidate becomes canonical, where it propagates, and what it replaces.
Change propagation is the crucial part. If a company redefines its core ICP, that is a structural change to enterprise understanding, not a small edit. A positioning document might be a CMO-approved skill that feeds the social media skill, the SDR pitch skill, and the analyst call skill, so when the CMO updates it, does the change propagate automatically, queue for review by each downstream owner, or leave the old version running until someone certifies it? These are not theoretical questions. They are the difference between a layer that compounds and one that contradicts itself, and the next era of innovation will look much more like organizational design than prompt engineering.
Compounding learning loops: where the tenth agent gets smarter than the first
Permalink to “Compounding learning loops: where the tenth agent gets smarter than the first”Memory is one of the muddiest words in the agent stack. The split that matters is architectural. Working memory, the agent’s immediate execution surface, and episodic memory, the structured record of what happened, belong close to the agent harness as an execution state. Semantic memory, the durable knowledge the system preserves, and procedural memory, the rulebook for how work gets done, belong inside the context layer, because they are knowledge and skills the organization wants to preserve, govern, and make portable.
This is where learning loops matter. Traces should not just sit as logs. Through evals, corrections, human review, and certification, temporary experience becomes a durable context: a clarification becomes a saved preference, a repeated exception becomes an explicit policy. Take a contact center agent whose customer mentions a son with a dairy allergy. In the moment it lives in working memory and becomes an episodic trace, but once the system verifies and promotes it, it becomes semantic memory in the customer profile, and future agents never rediscover it. Every interaction makes the layer smarter, and the smarter it gets, the better every future agent performs.
Activation and retrieval: one layer, many dialects
Permalink to “Activation and retrieval: one layer, many dialects”Context is only valuable if it reaches the right human or agent, in the right interface, at the right moment: copilots, search, analytics, workflows, code editors, agent frameworks. There will not be one winner. Some systems consume context through MCP, others through APIs, SQL, vector retrieval, or graph traversal, so the layer cannot be tied to one interface or assume any single standard is always the answer. In the short term that means translation: even inside the Google ecosystem, Looker wants a LookML model while Gemini Enterprise wants a skill file. The winning architecture will not force every ecosystem to speak one language. It will translate canonical context into many local dialects.
Context governance and observability: the difference between infrastructure and a data lake with ambitions
Permalink to “Context governance and observability: the difference between infrastructure and a data lake with ambitions”The other four capabilities make the layer functional. Governance makes it trustworthy: without it, context decays into a fog of unverified prompts, drifted definitions, and competing instructions; with it, context becomes infrastructure. Five concerns have to be live across every capability. Quality: is this definition or skill verified by an owner and tested against real cases? Drift: has the world changed underneath it? Lineage: where did it come from, and what depends on it? Versioning: can we roll back, and can we tell when two agents disagree because they are on different versions? Approval: who can merge a change that affects multiple teams, and who certifies a new playbook is safe and reusable? These are organizational design questions, and they decide whether enterprise AI becomes trustworthy at scale. Without clear accountability loops, the layer becomes another data lake, a graveyard of artifacts no one trusts. With them, it becomes the shared brain the rest of the stack reaches into with confidence.
The shape of the market today
Permalink to “The shape of the market today”Draw the market map of context-layer companies right now and you will find dozens of logos crammed into one category. Some belong there. Most are building something else that happens to have a context layer inside it: agent builders whose layer is scoped to their own vertical, platforms whose layer is scoped to data resident in their product, and specialists who own one component of the substrate, whether memory, process mining, vector retrieval, or semantics. Each is excellent at one piece, and most will be integrated into a context layer rather than become one.
None of this is unhealthy; every early ecosystem looks like this before it consolidates. The context layer will consolidate harder and faster than most, because the whole point of the layer is that it is shared. A Fortune 500 with one layer for its CS agents, another for analytics, a third for memory, and a fourth for process mining does not have a context layer. It has four context islands, and the compounding loop breaks the moment context cannot move between agents. The companies that define this category will integrate across all three substrates and run all five capabilities as one coherent loop.
What it is not
Permalink to “What it is not”It helps to define the layer by contrast, because the confusion almost always comes from a neighbor concept.
How is a semantic layer different from an enterprise context layer? A semantic layer is a part of the picture, not the whole picture: it is scoped to metrics and dimensions for analytics, while the context layer covers data, semantics, and skills and runs all five capabilities.
Is an enterprise data catalog the enterprise context layer? A data catalog was built for humans, to help analysts find tables; the primary producer and consumer of a context layer is AI, which is why the substrate has to include skills and the activation layer has to speak MCP, vectors, graphs, and APIs, not just power a search box.
Is long-term memory the same as the enterprise context layer? No. Long-term memory is one piece of one capability. The context layer is the broader system that decides what gets promoted from memory into shared, governed enterprise knowledge.
Where this goes next
Permalink to “Where this goes next”Here is what I keep coming back to. The companies that win the next decade will not be the ones with the best models, because everyone will have access to the same models. They will be the ones whose context compounds, where the tenth agent is dramatically smarter than the first because the layer underneath it learned something every time.
That is the whole game. The substrate and the five capabilities are how you build for it, and getting the architecture right is the difference between a layer that compounds and four context islands that quietly contradict each other.
The context layer is not a feature you ship. It is the foundation everything else stands on. Let’s build it carefully.
This is the map. Over the coming weeks, this series walks each territory in depth: building the substrate inside a company that already exists, governing the lifecycle when one change ripples across hundreds of downstream agents, and measuring whether any of it is working. The hard part was never the definition. It is the build.
The full canonical piece, with the complete architecture diagram and deeper treatment of each capability is here. This is the Context and Chaos edition
The Cats of Context & Chaos
Permalink to “The Cats of Context & Chaos”
About Context & Chaos
Permalink to “About Context & Chaos”Context & Chaos isn’t just a newsletter. It’s shared community space where practitioners, builders, and thinkers come together to share stories, lessons, and ideas about what truly matters in the world of data and AI: context engineering, governance, architecture, discovery, and the human side of doing meaningful work.
Our goal is simple, to create a space that cuts through the noise and celebrates the people behind the amazing things that are happening in the data & AI domain.
Whether you’re solving messy problems, experimenting with AI, or figuring out how to make data more human, Context & Chaos is your place to learn, reflect, and connect.
Got something on your mind? We’d love to hear from you. Hit Reply!
Share this article