



















I have had some version of the same conversation with a CIO almost every day this year. It usually starts the same way. Their team has read about context layers, or seen the term in a Gartner note. They know it matters. They know it sits somewhere underneath the agents they are trying to put into production.
And then comes the real question: What is it, actually? Is it a data catalog with new branding? A semantic layer? A knowledge graph? A RAG over unstructured data? Is it the same as memory, decision traces, or context graphs?
All of those things matter, but none of them are the same as the context layer.
In this article, I want to break down the buzzwords to make it clear what a context layer actually is, what it isn’t, and where it fits into the AI platform architecture.
If you’re new to this space, Context Layer 101 is the right starting point — it explains why context infrastructure is the missing layer between data and trustworthy enterprise AI.
Context = Knowledge + Expertise + Norms
Permalink to “Context = Knowledge + Expertise + Norms”Before we can talk about what makes up the context layer, it’s important to be precise about what context actually means here.
An AI agent operating inside a real business needs three kinds of context:
Knowledge is the map of the business. This includes entities, definitions, metrics, relationships, taxonomies, and glossary terms. In short, it’s the ontology of how the company interacts and talks. This lets a human and an AI system agree on what a customer, product, policy, and revenue actually mean.
Expertise is how work actually gets done. This includes procedures, workflows, tool choices, task decomposition, playbooks, and the practical know-how of regular projects like running the monthly close, qualifying an inbound lead, or triaging a support escalation. Today, this lives across SOPs, tickets, Slack threads, and the heads of the three people who have been on the team long enough to remember why we do it that way.
Norms are the rules of acceptable action. This includes policies, permissions, obligations, approval paths, exception handling, and compliance constraints. Norms tell the agent not just what is true and how to do it, but what is allowed. For example, they govern which customer can be offered which discount, which actions need a human approver, and which data cannot leave which jurisdiction.
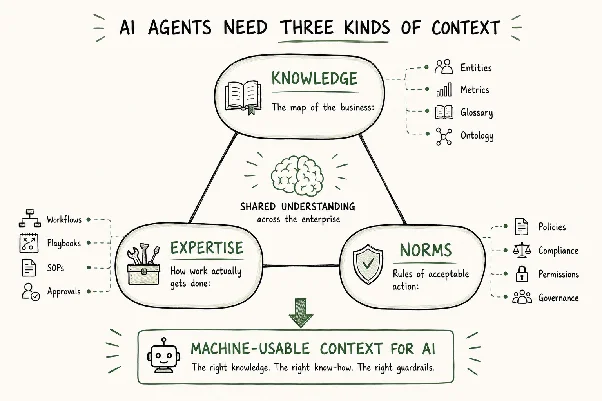
Three Kinds of Context: Knowledge, Expertise, and Norms. Source: Author.
What an Enterprise Context Layer Actually Is
Permalink to “What an Enterprise Context Layer Actually Is”Let’s get right to it.
An enterprise context layer is the system that turns knowledge, expertise, and norms into machine-usable context for AI — across the heterogeneous landscape of data, business systems, and AI. It exists so agents can operate with shared meaning, with the right information at the right moment, and with the governance needed to act safely and consistently.
Think of the context layer as a shared enterprise brain. It’s the foundation that every agent in your company reaches into, learns from, and contributes back to. That’s what makes the tenth agent dramatically better than the first, because each one inherits what the previous ones already learned.
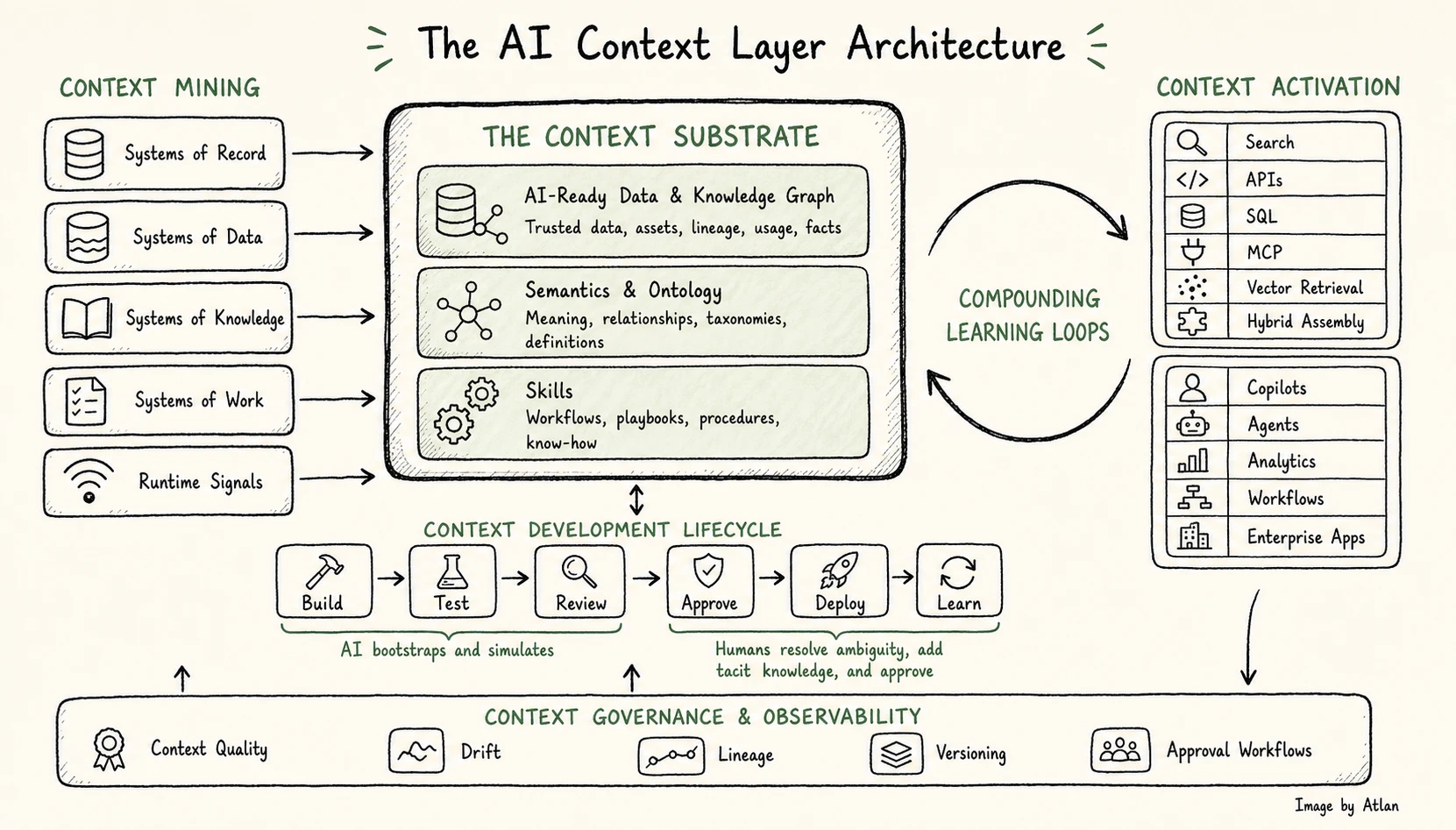
The AI Context Layer Architecture. Source: Author.
The context layer has two halves working together:
- A core context substrate: The machine-usable substance of context itself, made of three integrated parts.
- Five capabilities: The operating system that produces, governs, delivers, and continuously improves that substrate over time.
Part 1: The core context substrate
Permalink to “Part 1: The core context substrate”The substrate is the machine-usable representation of enterprise context. It’s made of three tightly integrated parts: AI-ready data, semantics & ontology, and skills. Together they answer three different questions an agent needs to act:
- What data and assets can I trust? → AI-Ready Data & Knowledge Graph
- What do things in this business mean, and how are they connected? → Semantics & Ontology
- How does work actually get done here, and what’s allowed? → Skills
You can’t have one without the others. Data without semantics is uninterpretable. Semantics without data is theater. And both without skills can describe the business but not operate it.
1. AI-ready data and the knowledge graph
Permalink to “1. AI-ready data and the knowledge graph”This is the foundation: the integrated, trusted, and AI-ready representation of an enterprise’s data and knowledge assets. It solves two distinct problems.
First, it makes structured data machine-readable for AI. That means enriching tables and datasets with the context agents actually need: descriptions, primary keys, join paths, required filters, SQL patterns, usage history, and the ways humans typically ask questions of that data.
Second, it makes unstructured knowledge accessible in a governed way. That means identifying canonical facts, indexing files and folders, applying classification logic, and deciding what is allowed to become part of the enterprise knowledge graph.
Canonical knowledge is the narrative that defines how the company thinks, sells, builds, and speaks. Strategy documents, mission and values, brand voice guides, product positioning, principles, frameworks, and org charts. These are the ideas experienced employees carry in their heads and every new hire absorbs in their first 90 days.
There’s also an important shift happening here. As MCP emerges as a key protocol, and as more core systems expose high-quality MCP servers, there’s a real possibility that agents may not need every asset to be physically centralized. If they understand how to use the MCPs, the tools, and the rules of the systems where knowledge already lives, they may be able to traverse the enterprise knowledge graph directly and retrieve verified context from the source.
2. Semantics and ontology — the map of the business
Permalink to “2. Semantics and ontology — the map of the business”If AI-ready data tells you what exists, semantics and ontology tell you what it means and how it connects. This is the map of the business.
It encodes two different things:
- Semantics: Shared definitions of business concepts. Glossary entries, metric definitions, and the vocabulary every team uses and often disagrees on — what counts as an active customer, gross margin, or escalated incident.
- Ontology: The structure of how those concepts relate. The relationship between Customers, Accounts, and Transactions, or between Products, SKUs, and Inventory. Entities, relationships, knowledge graphs — what allows agents to reason across the business instead of treating each system as an island.
Ontologies and knowledge management are not new disciplines. What is new is that AI can now build, maintain, and curate encoded knowledge at the pace the business actually moves — reading query logs, reconciling conflicting documents, detecting drift between what a brand voice guide says and what marketing actually publishes. A living knowledge model is finally tractable at enterprise scale.
3. Skills — reusable procedures, processes, and norms
Permalink to “3. Skills — reusable procedures, processes, and norms”Knowing what something means is not the same as knowing what to do next. A semantic layer can tell an agent what gross margin is. It cannot tell the agent how to close the month, when to escalate an exception, or which approval path matters in practice. That’s a different layer of enterprise intelligence entirely.
This is where Skills come in. Skills make procedural knowledge — the way work gets done, and the norms that constrain it — durable and machine-usable.
A skill is the new primitive that does for procedural knowledge what code did for logic in software. Each skill is a reusable, versionable, testable unit of how-to. The context layer is the system that manages skills through version control, lifecycle management, and unit testing.
Two problems make skills hard, and they map cleanly onto the capabilities in Part 2.
The first is building the library — how do you reverse-engineer a skills library inside a company that already exists? You can’t write 10,000 skills in a quarter, and the most important procedural knowledge isn’t documented anywhere. This is a Context Mining problem.
The second is maintaining and governing the library — how do skills stay current as the business changes, how do changes propagate when an upstream skill is updated, and where does accountability sit when something goes wrong? This is a Context Development Lifecycle problem, and it’s where the organizational design questions live.
For the substrate itself, the takeaway is simpler: Skills give the context layer a way to encode how work gets done and what’s allowed in a form that’s reusable, versioned, and testable — the same way code did for software logic. That’s the new primitive. Everything else is operating system around it.
Part 2: The five capabilities
Permalink to “Part 2: The five capabilities”The substrate is what the context layer is. The five capabilities are what it does — the operating system that produces context from enterprise reality, governs it through a lifecycle, compounds it through learning, delivers it where agents work, and keeps it trustworthy over time.
Capability 1: Context mining
Permalink to “Capability 1: Context mining”If you want to understand how a business thinks it runs, read its documentation. If you want to understand how it actually runs, observe its systems.
A surprising amount of business context is hidden across business systems, knowledge systems, Slack, email, tickets — and the trail of how people actually use all of them. The first job of the context layer is to connect to that fragmented reality and reverse-engineer business operations from it.
Context mining draws from two kinds of sources:
- Existing business and knowledge systems: Systems of record (Salesforce, ServiceNow), systems of data (Snowflake, Databricks, BI dashboards), systems of knowledge (Notion, Confluence, ticketing systems, email), and systems of work (Slack, project tools, the trail of where decisions happen).
- Runtime signals: Query history, usage patterns, agent traces, evals, human overrides, and freshness signals.
Mining semantics and ontology
The semantic layer of a real business doesn’t live in one place. It’s scattered across SQL query patterns, undated decks, Notion pages, Slack threads, and people’s heads. A few examples of what this actually looks like in production:
- AI reads your SQL query history, notices that Sales and Finance use different definitions of Annual Recurring Revenue, and surfaces the conflict for a human to decide which should be used company-wide.
- Someone asks AI about the escalation threshold, but four documents disagree. AI reads them all, weighs their last-updated dates and author seniority, drafts two candidate versions, and brings them to a human.
In each case, AI does the heavy lifting and humans decide.
Mining skills
Mining procedural knowledge is even harder than mining semantics, because most of it was never written down. The durable methods are system-led:
- Skill-building as part of agent-building: Do the work manually with the agent once, then use AI to examine the session, extract the repeatable pattern, write the skill file with triggers and edge cases, and register it.
- Mining existing systems: Creating process maps from event logs, or decision flows from email and Slack patterns.
- Failure-driven skill capture: Run the agent, watch where it fails, and capture the missing context at the point of failure. Each failure is a signal where a skill is needed.
- Desktop shadowing: Shadow what top operators actually do on their machines and reverse-construct their workflows.
- Structured AI interviews: AI runs structured conversations with employees to surface the exceptions, workarounds, and decision rules that observation can’t reach.
None of these methods produce a finished skill on their own — they produce candidates that the Context Development Lifecycle then tests, reviews, approves, and deploys.
Capability 2: Context development lifecycle
Permalink to “Capability 2: Context development lifecycle”Just as software engineering created the software development lifecycle to manage how code is built, reviewed, versioned, and deployed, companies that want a shot at truly becoming AI-native will need a context development lifecycle to manage how context is created, tested, approved, deployed, and retired.
Context can no longer live as scattered prompts, hidden instructions, and isolated team-level decisions. It has to become a first-class asset: reusable, reproducible, versioned, and governable.
The lifecycle has six stages — and the line between AI and humans moves through it:
- Build → Test → Review: AI bootstraps and simulates. AI drafts the candidate context, tests it against historical traces and known cases, and surfaces it for review.
- Approve → Deploy → Learn: Humans resolve ambiguity, add tacit knowledge, and approve. A human owner decides whether the candidate becomes canonical, where it propagates, and what it replaces.
Change propagation is crucial. If a company changes its core ICP or redefines a key persona, that’s not a small edit — it’s a structural change to enterprise understanding. The system should trace the lineage of that change across every downstream context artifact, every evaluation, and every agent that depends on it. The real governance challenge isn’t just storing context, but understanding the blast radius of change.
Consider a real cascade. A company’s positioning document might be a CMO-approved skill. That positioning feeds the social media skill, the SDR pitch skill, and the analyst call skill. When the CMO updates positioning, what happens? Does the change propagate automatically? Does it queue for review by each downstream skill owner? These are not theoretical questions — they’re the difference between a context layer that compounds and one that contradicts itself.
AI will do most of the work, and humans will increasingly step in only for judgment, certification, and exception handling. But for that to work, every context agent in the lifecycle needs a specialized role, a clear scope of authority, and a human accountability path.
Capability 3: Compounding learning loops
Permalink to “Capability 3: Compounding learning loops”Memory is one of the muddiest words in the entire agent stack. A useful way to think about it is across four types:
- Working memory: The agent’s immediate execution surface.
- Episodic memory: The structured record of what happened over time.
- Semantic memory: The durable knowledge the system has learned to preserve.
- Procedural memory: The rulebook for how work gets done.
Working memory and episodic memory belong close to the agent harness — they’re part of execution state. Semantic memory and procedural memory belong inside the context layer, because they represent knowledge and skills the organization wants to preserve, govern, and make portable across agents, tools, and workflows.
This is where compounding learning loops become essential. Episodic memory and traces shouldn’t just sit as logs. Through traces, evals, corrections, human review, and certification, temporary experience gets converted into durable context. A clarification becomes a saved preference. A repeated exception becomes an explicit policy. A workflow that consistently works becomes part of the organization’s procedural memory.
Take a simple example. A contact center agent is helping a customer, and during that interaction the customer mentions that their son has a dairy allergy. In the moment, that detail lives in working memory. The interaction becomes part of episodic memory. But if the system determines this detail is important, verifies it, and promotes it, it becomes semantic memory: the customer profile is updated, and future agents never rediscover it.
It’s not just about helping one model remember one conversation. It’s about deciding what should remain local to execution, what should be archived as history, and what should be promoted into shared enterprise knowledge. Every interaction makes the layer smarter — and the smarter the layer gets, the better every future agent performs.
Capability 4: Context activation and retrieval
Permalink to “Capability 4: Context activation and retrieval”Context is only valuable if it reaches the right human or agent, in the right interface, at the right moment of work.
This capability activates context so it shows up where decisions get made: copilots, search, analytics tools, workflows, code editors, agent frameworks, and the applications where work already happens.
As context becomes an enterprise asset, it has to survive a heterogeneous world of interfaces, protocols, and retrieval patterns. There will not be one winner. Some systems will consume context through MCP. Others will use APIs, SQL, search, vector retrieval, graph traversal, or hybrid runtime assembly.
The data lakehouse became the open architecture that kept data portable across engines, tools, and clouds. The context lakehouse could follow a similar pattern — not just a place to store context, but the persistent architecture that makes context reusable in production.
In the short term, this means solving a practical problem: translation. Even inside the Google ecosystem, Looker wants context as a LookML model while Gemini Enterprise wants it as a skill file. Snowflake wants Semantic Views. The winning architecture will not force every ecosystem to speak one language. It will translate canonical context into many local dialects.
Capability 5: Context governance and observability
Permalink to “Capability 5: Context governance and observability”The other four capabilities make the context layer functional. Governance and observability are what make it trustworthy.
Without governance, context decays into a fog of unverified prompts, drifted definitions, and competing instructions. With governance, it becomes infrastructure: certified, observable, and continuously improving.
Governance and observability span five concerns that have to be live across every other capability:
- Context Quality: Is this metric definition, skill, or policy verified by an owner and tested against real cases?
- Drift: Has the world changed underneath this piece of context? Is the brand voice guide still aligned with what marketing actually publishes?
- Lineage: Where did this context come from? Which downstream agents, evals, and workflows depend on it?
- Versioning: Can we roll back? Can two agents disagree because they’re on different versions of the same skill, and can we tell?
- Approval workflows: Who’s allowed to merge a change that affects multiple teams? Who certifies that a newly discovered playbook is real, safe, and broadly reusable?
These aren’t prompt-engineering questions. They’re organizational design questions, and they’ll define whether enterprise AI becomes trustworthy at scale.
Compounding only works if there are clear accountability loops. Without them, the context layer becomes another data lake — a graveyard of artifacts no one trusts. With them, it becomes the shared brain the rest of the AI stack reaches into with confidence.
The shape of the market today
Permalink to “The shape of the market today”If you draw the market map of context-layer companies right now, you’ll find dozens of logos crammed into a single category. Three patterns are worth pulling apart.
Agent builders building context for their own vertical. Sierra is an agent company. The context layer they’re building is real, but it’s specific to customer experience agents. Almost every vertical agent company shipping today is doing some version of this.
Platforms building context for their own product. Snowflake is building Snowflake Intelligence, and the context layer underneath it is specific to data analysis on Snowflake-resident data. That’s a valuable context layer. It’s also not the enterprise context layer.
Specialists building one component of the substrate. This is most of the market map. Memory companies (mem0, Letta, Zep, Cognee) work on a piece of the compounding learning loop. Process mining companies (WIQ, Klarity, Worktrace, Skan) work on capturing procedural knowledge. Vector retrieval companies (Pinecone, Chroma, Milvus) work on activation. Semantic specialists (honeydew, RelationalAI) work on parts of the ontology. Each is excellent at one piece. Most will end up integrated into a context layer rather than being one.
The context layer will consolidate the same way the modern data stack did, but harder and faster — because the whole point of the context layer is that it’s shared. A Fortune 500 with one layer for its CS agents, another for data analysis, a third for memory, and a fourth for process mining doesn’t have a context layer. It has four context islands. The compounding loop breaks the moment context can’t move between agents, products, and ecosystems.
The companies that will define this category are the ones that integrate across all three substrates and run all five capabilities as one coherent loop.
What it isn’t
Permalink to “What it isn’t”How is a semantic layer different from an enterprise context layer?
There are three flavors of semantic layer in the market today: embedded (Looker, Snowflake Semantic Views), universal (Cube, AtScale, dbt’s semantic layer), and universal context layers (Atlan). Universal semantic layers are engine-agnostic but still scoped to metrics and dimensions for analytics. A universal context layer goes further: it covers the full substrate and runs all five capabilities across the heterogeneous landscape of enterprise AI.
Is an enterprise data catalog the enterprise context layer?
No. Data catalogs were built for humans, to help analysts find tables and understand columns. The primary producer and consumer of a context layer is AI. That changes everything: the substrate has to include skills and procedural knowledge, the lifecycle has to assume AI bootstraps most of the work, and the activation layer has to speak MCP, vectors, graphs, and APIs — not just a search box.
Is long-term memory the same as the enterprise context layer?
No. Long-term memory is one piece of one capability — the compounding learning loop. The context layer is the broader system that decides what gets promoted from memory into shared, governed enterprise knowledge.
