Everyone owns context now.
Every platform at last week’s Snowflake Summit in San Francisco announced a version of it. The keynotes named it. The booths demonstrated it. The standards bodies wrote specifications for it. By the end of four days, the practitioners on the floor were more confused than when they arrived.
That confusion is worth paying attention to. It is a signal about where the real problem has moved.
Context is not two problems an enterprise gets to solve separately. What your data is, and what it means and who decides, are one layer. The industry now has a credible plan for the part of it that ships as a product. The part that does not fit in a product announcement, the agreement, the ownership, the institutional memory, is the part the floor kept asking about during the summit week. It is not a separate problem to solve later. It is the same problem, still open.
The announcement the field has been waiting for
Permalink to “The announcement the field has been waiting for”Something significant happened at this summit. For the first time, context infrastructure was the main story, not a footnote.
Sridhar Ramaswamy, Snowflake’s CEO, used his opening keynote to say it plainly: a model is not a unique advantage, because your competitor has the same model. The moat is your data. The company with the best governed, contextualized, machine-readable data wins the AI era, not the one with the best model subscription. In Snowflake’s framing, data is the most defensible moat a company has, and if it is fragmented, competitive advantage is buried with it.

Christian Kleinerman, Snowflake’s EVP of Product, made the same point from the product side: models keep changing and capabilities keep advancing, but the data is constant.
Two years ago, the mainstream position was that frontier models would solve the data quality problem downstream. The industry’s largest data platform is now saying the opposite. Governance, context, and meaning are the irreducible requirements. The category has arrived.
Platform vendors launched native semantic tooling. An open standard for semantic model interoperability gained ground, with a broad coalition of vendors behind it. Agent governance got a proper architecture: constrained agent identities, audit trails, policy enforcement at the meaning layer. A new acquisition in enterprise agent connectivity promised to plug AI agents into the full enterprise application stack, not just the warehouse.
Context is on every stage, in every booth, in every product roadmap. Which is exactly what makes the floor conversation so interesting.
What the room was actually asking
Permalink to “What the room was actually asking”Every vendor at this summit defined context with respect to what their software produces.
Semantic models for BI vendors. Metadata, schemas, and semantics for data platforms. Embeddings for vector stores. Lineage graphs for pipeline tools. Agent memory for AI frameworks. Knowledge graphs for ontology vendors. All of them context. None of them the whole of it. A semantic model is context, but not all context is semantics. Each tool is naming a true subset and treating it as the set. None of them wrong, exactly, which is what makes the conversation so hard.
When every tool claims context, the word stops meaning anything precise.
And the imprecision is not a new mistake, it is the latest version of an old one. Data and analytics has spent 20+ years treating the artifact as the goal, the dashboard, the model, now the semantic view, when the goal was always to answer the business question. That confusion is what triggered the whole data product movement. It is showing up again as “my job is to build the agent” instead of “my job is to solve the business problem.” The agent is the newest artifact to mistake for the outcome.
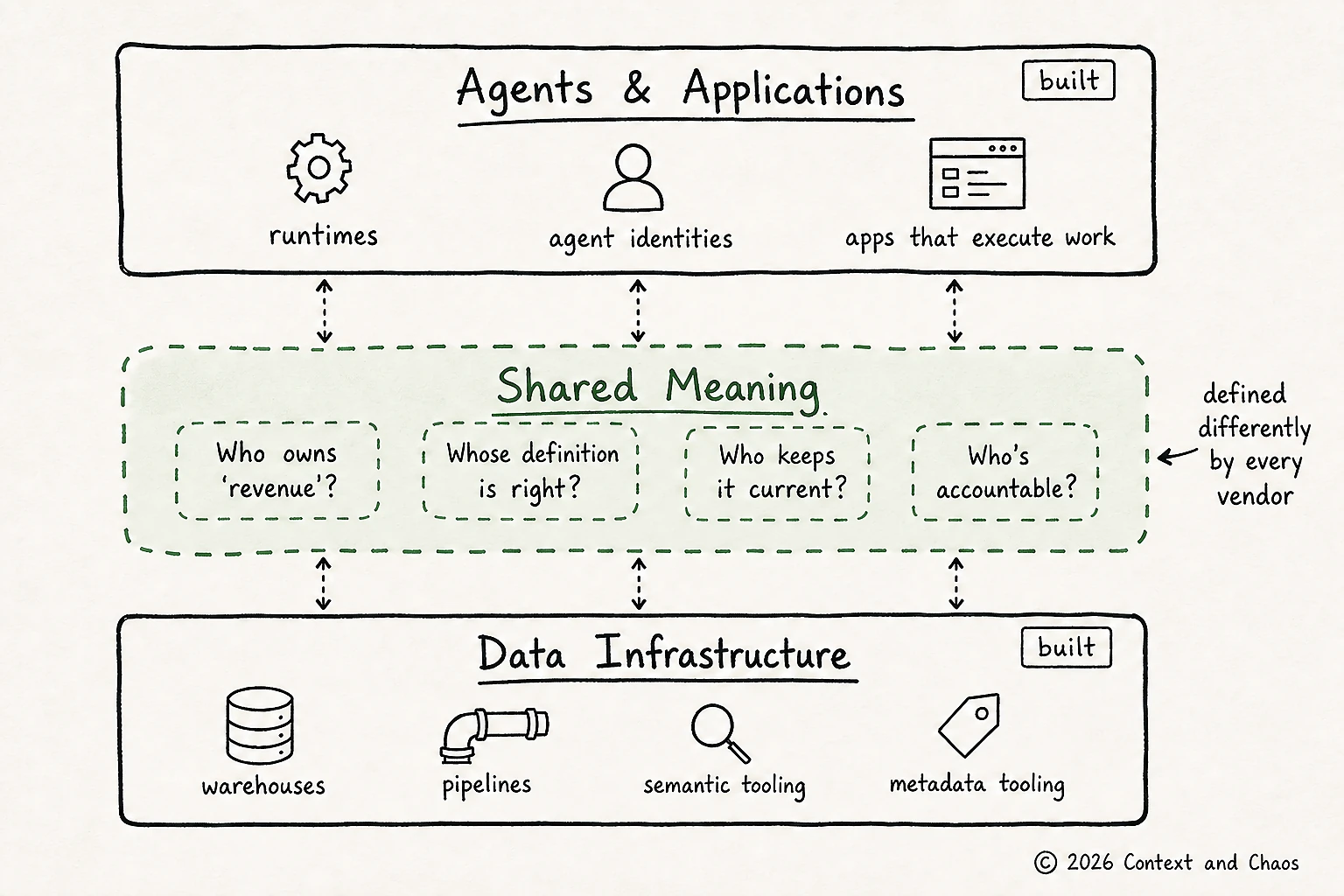
Most of what was announced last week at the summit sits at two ends of the stack. At one end, the data infrastructure: warehouses, lakehouses, pipelines, and the semantic and metadata tooling that makes them AI-readable. At the other, the agent runtimes and applications that execute the work. Native semantic tooling, metadata connectors, open standards, agent identity: these are real investments in making infrastructure machine-readable and giving agents governance primitives. They are necessary. They are also not the same thing as the layer of shared meaning that sits between the two.
Then Ramaswamy named the actual problem in the same keynote: too many enterprises still struggle to exploit their data because it sits in fragmented silos, each with its own version of the truth.
Their own versions of the truth. No semantic model resolves that. No metadata connector decides which version is authoritative. Two teams disagree on what “revenue” means, both are correct within their own context, and nothing announced during the summit holds the layer where that conflict gets reconciled and kept reconciled. This is not a gap in the warehouse. It is a missing layer above it, and that layer has to be engineered, not just willed into existence with more meetings.
Josh Klahr, who leads analytics product management at Snowflake, had named the underlying tension on LinkedIn months before the summit opened: why can’t semantic models interoperate across platforms? Four days of announcements later, that question still does not have a clean answer. The new open standard for semantic portability is a step toward it. But the hardest part is not the specification. It is what the specification is supposed to represent, and who gets to decide.
Sanjeev Mohan, an independent analyst, said it plainly in a floor interview: the moat has moved to the context layer, because that is where you can apply security. Then he added the line that did not make the summaries: the entire attempt to build a single corporate data warehouse is fraught, and it is not for everybody.
That second point is worth sitting with. The industry has treated the centralized model as basically working for decades, and organizations are still struggling with it. The struggle is not new, and it is not going away because a keynote said context is solved.

What the floor was asking that the stage didn’t answer
Permalink to “What the floor was asking that the stage didn’t answer”Across the booth sessions and demo conversations this week, a pattern emerged that the product announcements did not fully anticipate.
The demos landed. When practitioners watched an undocumented environment go from zero to AI-ready, lineage mapped, definitions bootstrapped, an agent returning a trusted query result, the reaction was consistent: this is real, I can see how it works. The demos are real, and the automation behind them is accelerating. It is worth being precise about what was shown, though. Bootstrapping context from a cold, undocumented estate is a strong assist today, not a finished capability. The direction is not in doubt. The maturity is still arriving.
The questions that followed were not about the technology. They were about what happens after the demo. Who maintains the definitions when the team that built them turns over? When a new data source lands, who governs its meaning before an agent starts querying it? When two business units define the same metric differently, and an agent has to answer a question that spans both, who decides which definition it uses, and what happens when the answer is wrong?
Those questions do not have answers in a product catalog. They have answers in organizational structure, accountability, and process. And the practitioners asking them were not confused about the technology. They were clear-eyed about the distance between what the technology provides and what their organizations need to run on top of it.
Madison Mae, an analytics engineer whose practitioner newsletter is one of the sharper reads in the field, published her verdict the same week: most teams are not at a place where they can use these features for governance reasons. Not some teams, most. After two days of keynotes explaining that context is solved.
The question that did not have a booth
Permalink to “The question that did not have a booth”Four questions came up repeatedly in floor conversations during the summit. None had a product announcement attached.
The first was memory. There was a memory feature announced, but it was the kind that lives with an individual agent session: per-user recall, preferences, query history. Useful, and not what practitioners were asking about. They were asking about organizational memory. How does an agent know that your definition of “churn” changed after a product pivot? How does it know that “customer” means something different in your North American operations than in EMEA, because an acquisition was never fully integrated? That is durable, shared knowledge that has to outlive any one session and any one person. The feature in the booth remembered the user. The floor was asking how the organization remembers itself.
The second was portability. Why can’t an agent just read the YAML file that defines the semantic layer? The question sounds technical. The reason it isn’t: a YAML file is a snapshot. It does not know who is responsible for updating it. It does not know when it stopped being accurate. It does not have an owner. You can federate a schema. You cannot federate accountability.
The third was ownership. When two teams disagree on the definition of “revenue,” and they will, who decides, and where does that decision live so an agent can act on it? The technical layer can surface the discrepancy. Resolving it, and keeping it resolved, takes a layer built to hold that decision, version it, and serve it to every agent that asks. That layer is buildable.
The fourth was gravity, where the agent actually gets built. This one surfaced less as a question than as a behavior the field had already settled into. Snowflake brought agentic development closer to the warehouse with Snowflake Cowork, and that is the rational move for any platform: pull agent-building toward your center of gravity, and in this case that is data. But the business’s center of gravity is the business process, and the problems it needs to solve. So the teams closest to those problems reach for what is in their orbit, general-purpose coding agents, or specialized agentic platforms built for a particular workflow. Some attendees said they are comfortable with consumer AI tools in their personal life, but their company has not licensed those harnesses for work. They will have the warehouse’s agent environment, so that is where they will start. No enterprise will standardize on a single one of these, and that is fine. The point is not which one wins. Agent development will start in many different platforms across many teams. The context an agent depends on cannot stay locked inside whichever platform a team starts in. It has to be portable across them. Each platform has its own gravity, and agents will form around all of them. Context cannot live in any single orbit. It is the center of mass they all share.
The pattern underneath all four is the same. Each one is a piece of context that the warehouse-layer announcements do not hold: the meaning, the ownership, the freshness, the portability. None of that is unmanageable human overhead. It is a layer that can be engineered, with the same rigor the industry just spent four days celebrating one layer down. The reason it feels unsolved is not that it is about people. It is that no platform builds it as a standalone layer, because each platform’s gravity pulls context back into its own product. Bob O’Donnell, a veteran industry analyst on the floor, said what practitioners have been saying quietly for years: this sounds great in theory, but the nuts and bolts of actually doing it are very hard. He has been saying some version of that for a decade. He is still saying it. The nuts and bolts are exactly the point. They are buildable. They are just not built from inside a warehouse.
The delta
Permalink to “The delta”The announcements at the summit were real infrastructure. Native semantic tooling that connects BI definitions to AI queries without rebuilding them. Lineage and metadata connectors that unify governance across third-party assets. Agent identity and permission models that give AI actions the same audit trail as human actions. A portability standard so metric definitions are not locked into one vendor’s format. Organizations that do not have this infrastructure should be building toward it.
But the infrastructure is not the whole of context. Tooling makes a definition machine-readable, which is real work the layer does well. On its own, though, it does not keep that definition current as the business changes, reconcile it when two teams disagree, or stop every new team and every new agent from quietly minting its own version of the truth. That is not a limit of the technology. It is what a context layer is for: it carries the definitions, versions them as they change, reconciles the conflicts, and serves a single trusted answer to every agent that asks. People set the policy and stay accountable for it. They do not hand-maintain it. The layer does the work and keeps humans on the loop, which is what makes it scale past a wiki page.
SiliconANGLE’s analysts framed the bet precisely: context determines agent quality. The frontier model vendors have the reasoning engines, the app vendors have the workflow context, and the bet on enterprise context organized around data is directionally correct. But a catalog defines nouns. The layer enterprises actually need has to model verbs: the actions, decisions, exceptions, and business logic that govern how work actually happens. Organizing context around data gets you the technical layer. It does not get you the agreement.
That is the word doing the quiet work this week: trust. Snowflake’s own framing was that every person, tool, and agent should operate from the same trusted business context. A schema can be documented and a definition can be specified, but trust is something an organization decides on together and then maintains. It sits outside the toolchain even when the tools are what make it durable.
What this means
Permalink to “What this means”Precision is the part that compounds trust, and in enterprise AI, precision failures are almost never model failures. They are organizational context failures: the agent using the wrong version of the truth because nobody decided which version was right.
Brendan Cyrus, Director of Product for AI Analytics and Data Platforms at Indeed, described what closing that gap looks like: “That single source of truth has eliminated metric discrepancies across teams and given us the confidence to scale AI-driven analytics knowing the answers are grounded in governed logic.” Not a semantic model. Not a metadata schema. A source of truth teams agreed on. The technology made it possible. The governance made it work.
Jeff Miller, Global Head of Data Factory and Enterprise Data Platform at BlackRock Aladdin, framed the same requirement: “As AI becomes increasingly embedded across our enterprise, it’s essential that applications, analytics and agents operate from the same trusted understanding of the business.”
The trusted understanding. Both of them reach for the same word, and trust is not something a schema confers. It is the thing an organization has to establish and keep establishing as the business moves.
What your data looks like and what your business means are not two layers an enterprise buys in sequence. They are one layer, and an agent that has the first without the second will answer confidently and wrongly. The summit showed the half that ships. The other half is still the work.
For teams building agents today, the reframe is this: context is not a documentation sprint you run before launch, and it is not an org chart you redraw until someone owns the word “customer.” It is a layer you engineer and operate, the same way you engineer and operate the data platform underneath it. The definitions that make your agent accurate on day one drift the moment a team reorganizes, an acquisition closes, or a product line changes its terminology. Whether those changes reach the context your agents act on, and how fast, depends on whether that context is built to be versioned, owned, and kept current, or whether it is a static file someone wrote once.
The summit made one thing unmissable. Every platform now agrees context is the point, because every agent being built needs it. But almost every announcement defined context in its own image: semantics for the BI vendors, schemas for the warehouses, embeddings for the vector stores, memory for the agent frameworks. Each one is describing the slice of context its own product happens to produce. That is the tell. If context only means what your platform already does, it was never really about the agent’s understanding of the business. It was about the platform’s center of gravity.
So the useful question to take out of this year’s Snowflake Summit is not which platform to use for the context layer. It is whether the meaning your agents run on is tied to a single platform’s definition of context, or whether it lives in a layer that holds across all of them, the BI tool, the warehouse, the vector store, the agent frameworks you have not adopted yet. The summit built the floor and the ceiling. The layer in between, the one that decides whether your agents are right and is the one piece no single vendor’s definition fully covers, is still the work. It is buildable. The question is who builds it independently of any one platform’s gravity.
The teams that build it that way, rather than accept whichever definition of context their platform hands them, will spend less time debugging confident wrong answers and more time putting agents into production that hold up. The infrastructure from the summit week is real. The layer that makes it trustworthy, and keeps it trustworthy no matter which platform an agent runs in, is the one piece no single platform’s gravity can hold. That makes it the most valuable layer in the stack, and the one still waiting to be built where it belongs: above all of them.
The Cats of Context & Chaos
Permalink to “The Cats of Context & Chaos”
About Context & Chaos
Permalink to “About Context & Chaos”Context & Chaos isn’t just a newsletter. It’s shared community space where practitioners, builders, and thinkers come together to share stories, lessons, and ideas about what truly matters in the world of data and AI: context engineering, governance, architecture, discovery, and the human side of doing meaningful work.
Our goal is simple, to create a space that cuts through the noise and celebrates the people behind the amazing things that are happening in the data & AI domain.
Whether you’re solving messy problems, experimenting with AI, or figuring out how to make data more human, Context & Chaos is your place to learn, reflect, and connect.
Got something on your mind? We’d love to hear from you. Hit Reply!
Share this article