When I was in middle school, I had a physics teacher who made the subject feel like magic. He dragged everything out of the textbook and into real life with wild demonstrations. Water bending without being touched. A magnet floating in mid-air. The first time you saw it, it felt impossible. Then you looked closer and the magic disappeared. No magic at all. Just basic principles, working together in a way that made the outcome look more mysterious than it was.
I have a lot of conversations with enterprise leaders that feel exactly like that.
A team runs enrichment agents against their warehouse. Descriptions appear. They are specific. They are accurate. They are often better than what a team has managed to produce manually in months. Then there is a pause.
“Okay. What’s the catch?”
Sometimes it is polite skepticism. Sometimes it is open disbelief. Sometimes someone points at a description and says, “Wait, this is actually right?”
The doubt is rational. Most data leaders I talk to have been burned by AI already. A project that hallucinated through a domain model. A tool that promised semantic understanding and shipped string matching. So when the output is genuinely good, the instinct is to assume cherry-picking, or some hidden dependency on perfectly curated input that no real warehouse has.
What I tell them is that the good output is real, and it is also not the interesting part. The interesting part is what comes after you accept it: context is not a yes-or-no property. It has a floor. And almost nobody is measuring where theirs sits.
The Godfather Problem
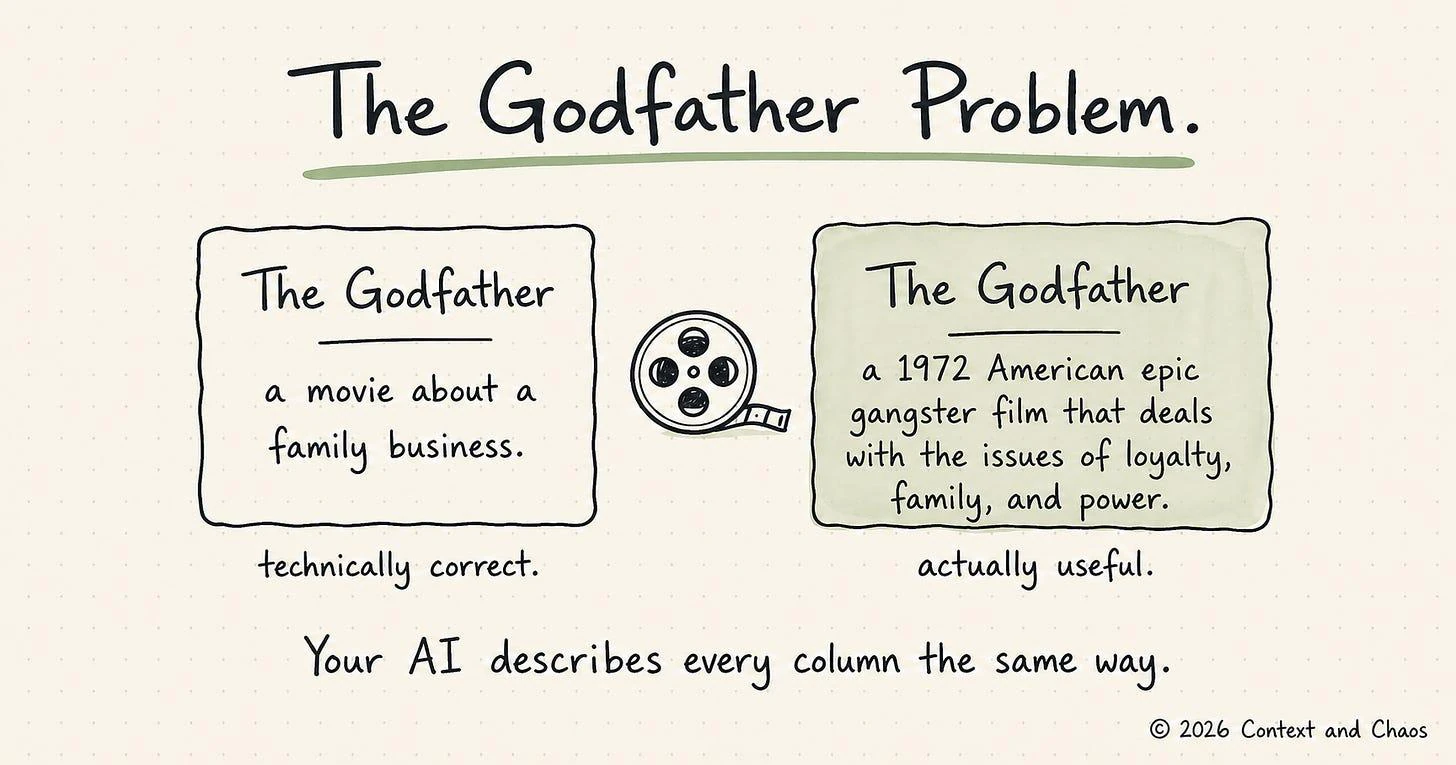
Permalink to “The Godfather Problem”Ask a general-purpose model to describe a column called revenue_usd and you get “Revenue in US Dollars.” Which is correct, the way calling The Godfather “a movie about a family business” is correct. Technically accurate. Useless in practice.
The same column, described two ways | Source: Author
Feed an agent lineage, query history, glossary, and downstream consumption, and the same column comes back as: recognized USD revenue, computed from orders.amount × fx_rate, filtered to shipped and delivered orders, consumed in the Finance team’s MRR dashboard.
Same model. Different diet. Not smarter, but better fed.
What matters is the assumption hiding inside that line. The second output is available to anyone who plugs in those signals, it is not. It is available to anyone whose signals are actually good enough. Most are not, and most teams have no way to tell.
How the descriptions actually get built
Permalink to “How the descriptions actually get built”It helps to see the chain. The agent is not doing one hard thing in a single pass. It is running a sequence where each step narrows the ambiguity the next one inherits.
A column’s meaning is the union of four signals: how it was built, how it is used, what it is called, and what it feeds. The schema, the column name and type on its own, is too thin to carry any of that. Lineage tells you construction. Query history tells you what analysts have implicitly said about a column through their behavior: if customer_tier is always grouped with SUM(revenue) and filtered to enterprise and mid-market, it is a revenue segmentation dimension whether the docs say so or not. Glossary tells you the agreed business vocabulary, the terms your organization has already defined and stood behind. Downstream consumption tells you the anchor: a column feeding a Finance-owned tile called MRR has its meaning fixed by that usage.
Once columns carry that kind of semantic weight, they cluster by meaning instead of by name. That matters because cust_id, customer_sk, party_id, and AccountId can all point to the same concept across different systems, and string matching alone will not catch that. Resolve those, and the domain map stops looking like tag soup and starts looking like a typed graph with known join keys. From there a KPI is just an aggregation over a known semantic scope. MRR is the right revenue, over the right products, with the right recognition date, in the right domain. A bare sum of a revenue column is not MRR, and the agent can only assemble the real thing if the layers underneath it resolved correctly first. Without that, you are standing in the middle of the warehouse asking which of the forty-seven revenue columns is the real one, and watching all of them raise a hand.
That dependency is the whole game. It is also where the floor lives.
The diet has a floor
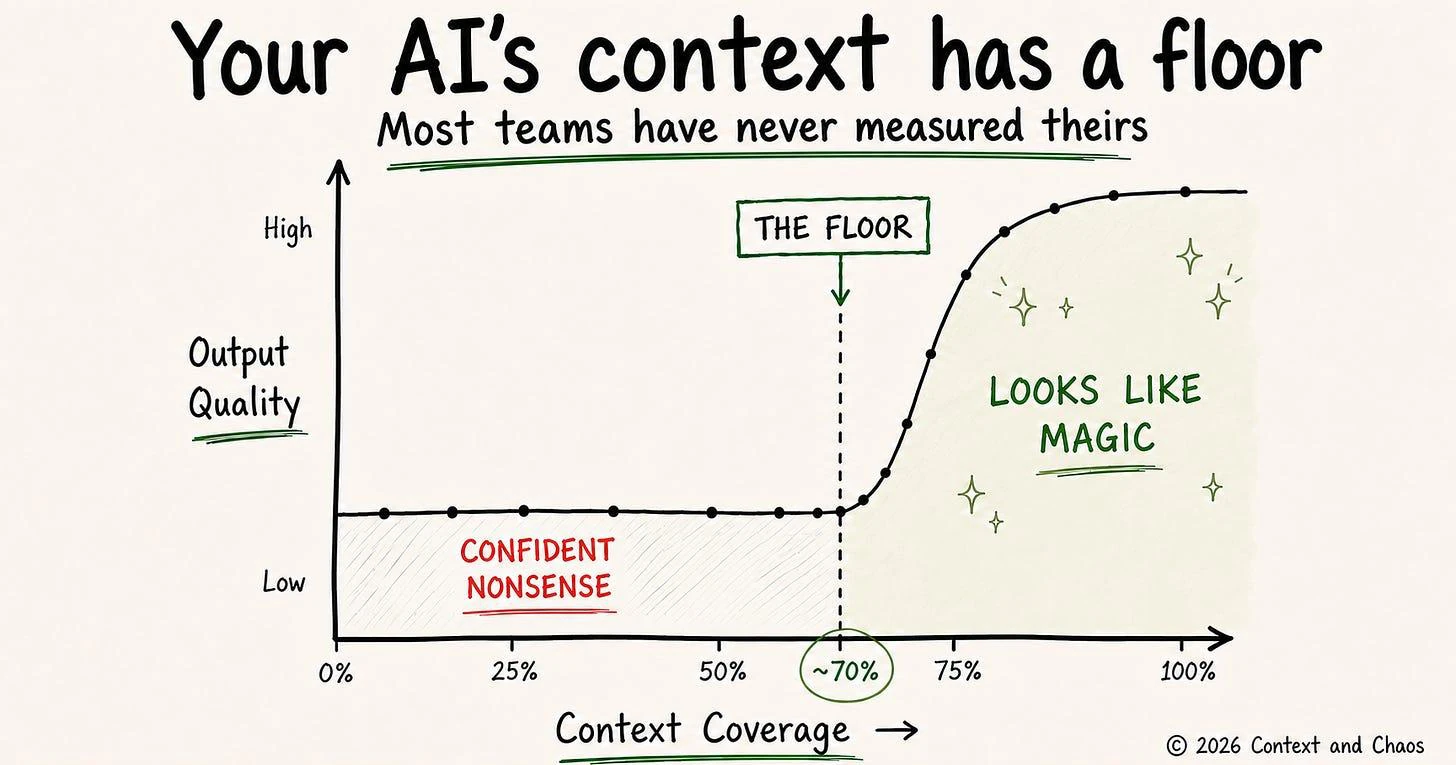
Permalink to “The diet has a floor”Here is what nobody puts on the keynote slide. The effect that makes context-fed AI look like magic only runs above a coverage threshold. Below it, the same architecture produces confident nonsense.
The failure mode below the floor is not the one most teams expect. Teams brace for gaps. What they get is confident errors. A plausible-but-wrong description, certified by a steward skimming a batch of two hundred, is worse than a blank field. The blank field signals “unknown.” The wrong description signals “trust me.” You have made your catalog more authoritative-looking and less reliable at the same time.
Two places the floor gives way.
Lineage coverage. The agent reconstructs what a column means partly from how it was built. If your upstream transformations sit outside the lineage graph (Python pipelines nobody captured, ad-hoc notebook transforms, transformation models whose lineage was never exposed), the agent does not know what it does not know. It infers construction logic from naming patterns and column shapes. The inference is plausible. It is sometimes wrong.
Query history depth. The agent reads behavior to infer meaning. A new warehouse, a freshly migrated dataset, or a low-usage domain has a thin behavioral signal. The agent has less to read, and the output drifts back toward the generic “Revenue in US Dollars” you were trying to escape.
The mechanic is real. So is the floor it stands on. Which raises the only question that actually predicts whether AI on data will work for you: is your context above the floor or below it?
A number that answers it
Permalink to “A number that answers it”There is a benchmark worth carrying into any evaluation, whatever tool you are looking at. Seventy percent steward acceptance on a scoped domain, inside a thirty-day window.
Not “the descriptions look good.” A measurable rate: of the descriptions the agent proposes for a bounded domain, how many do your own stewards accept against their own judgment, without edits. Run it on one domain you know cold. Count.
Why 70%? In the projects I have worked on, that is around where the governance overhead of catching errors stops exceeding the productivity gain. Below it, stewards spend more time on corrections than they would have spent writing descriptions from scratch. Above it, they are in editing mode, materially faster, and the cycle accelerates as better descriptions feed the next run.
The 70% test | Source: Author
I will put my own numbers on the table, with the caveat that they are mine and not an industry average. In my deployments, enrichment agents have applied descriptions at six-figure scale within weeks, with steward acceptance holding above 90% once a domain was above the floor. The pattern I trust most is not any single figure: rollouts that used to run the better part of a year compressed dramatically whenever the substrate underneath was already in good shape.
That last clause is the one that matters. The compression is a property of the substrate the agents were standing on, not of the agents themselves. The teams that hit it were not running newer models. Their lineage and query history were above the floor before the agents arrived.
The flywheel, and why sequence matters
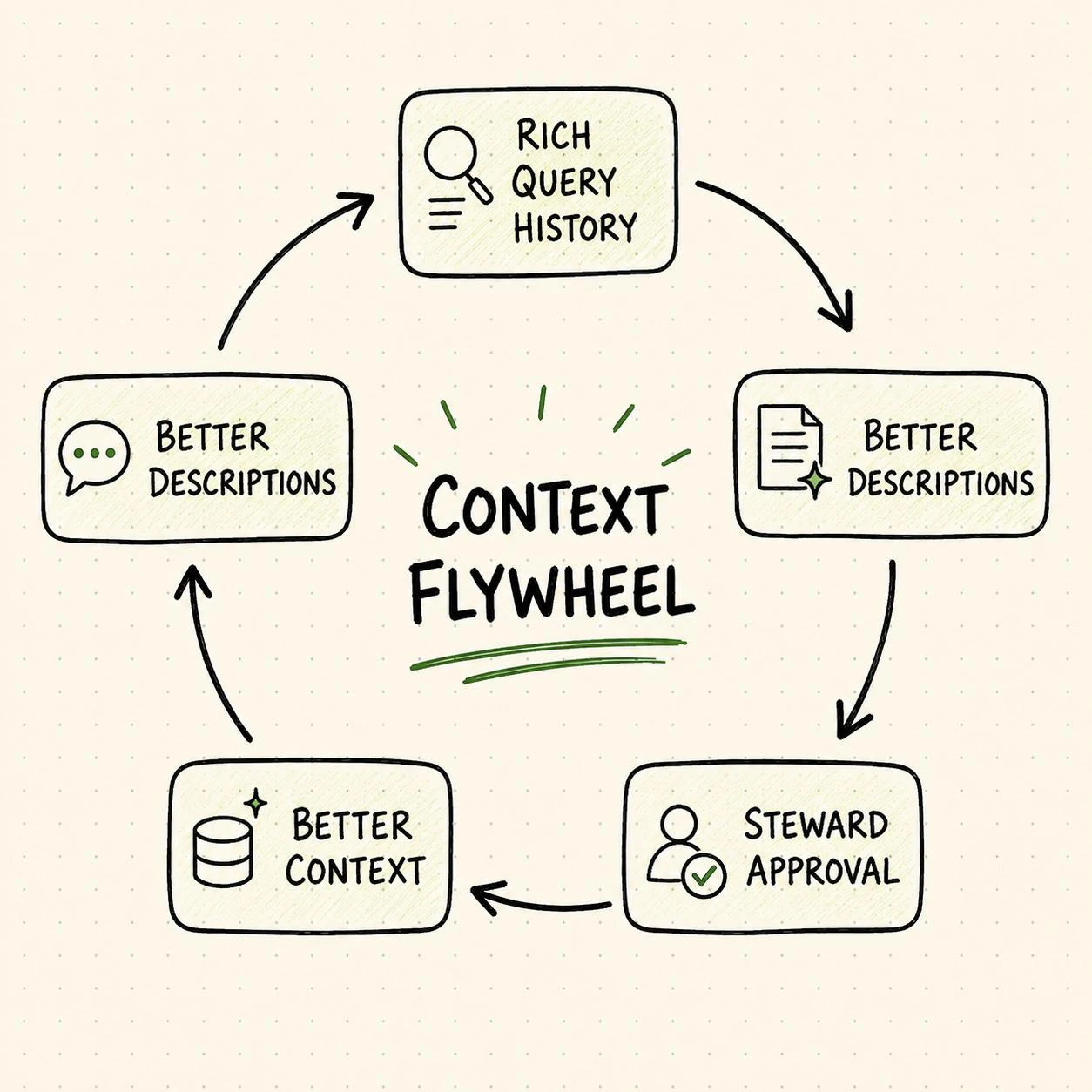
Permalink to “The flywheel, and why sequence matters”There is a reason the order of operations changes your results, not just your timeline.
Every description a steward approves becomes a signal for the next run. Approved output is the cleanest example a domain can produce: a human looked at it and said yes. Feed that back in and the next pass starts from a higher floor. Run enrichment on your cleanest, most-used domain first, certify it, and the agent carries that resolved vocabulary into the messier domains next door. Run it in the wrong order, starting in the sparse, low-traffic corner of the warehouse, and you are asking the agent to do its hardest work with its thinnest signal, then feeding those shakier results forward.
Context Flywheel | Source: Author
Which leads to the only cold-start advice that has ever worked for me: start with your most-queried assets. Not the messiest, not the most neglected, not the ones somebody has been meaning to document for two years. The most-queried. They have the richest behavioral signal, they clear the 70% bar fastest, and they give the flywheel its first real push. The neglected corners get easier once the well-traveled ones have taught the agent what your organization means by its own words.
How to keep it honest above the floor
Permalink to “How to keep it honest above the floor”Clearing the bar is necessary, not sufficient. An enrichment layer that is accurate but ungoverned is its own failure mode. Any system doing this work, whether you build it or buy it, needs four conditions in place.
The agent proposes; a human certifies. Nothing publishes automatically. The steward’s job shifts from writing documentation to certifying output and handling exceptions, which is a more interesting job than it sounds.
Generated content stays in its own lane. Machine-written descriptions are kept distinguishable from human-written ones, and human authorship always wins. Where a person has written the description, the generated one steps aside.
Everything is marked, logged, and gap-fill only. Every generated output is visibly flagged as generated, every run is auditable, and the system fills empty fields rather than overwriting work that already exists. No silent edits, no mystery changes.
Runs are deliberately scoped. Enrichment is pointed at a bounded set of assets a team chooses on purpose, not loosed on the whole catalog, and it is triggered when the team decides to run it. It reads metadata and usage logs rather than raw data, and it inherits the warehouse’s existing permissions, so nothing is read that the requesting user could not already read. (Exact batch sizes and refresh cadences are implementation details that vary and keep changing; the durable principle is deliberate scope, existing permissions, and metadata over raw data.)
If you are building this yourself, those are your design constraints. If you are evaluating a vendor, those are your evaluation criteria. Skip any one and the failure mode is predictable: a tired steward batch-approves a thousand confident, wrong descriptions, and the catalog gets worse instead of better. Notice that this is the same failure the floor produces. Below-floor coverage, and above-floor coverage without governance, fail in exactly the same way: a catalog full of plausible wrong answers. The 70% bar tests the first. These four conditions test the second.
The catch
Permalink to “The catch”When data leaders ask what the catch is, they expect one of two answers. Either the demo was rigged, or the system needs a level of upstream cleanliness their team will never reach. Neither, usually. The catch is that “feed it context” was never a switch. It is a coverage threshold most teams have simply never measured.
So before you evaluate another model, run the 70% test on one domain you know cold. The number will tell you whether your problem is the model or the diet. It is almost always the diet.
The AI is not smarter than anyone else’s. It is just better fed, and now you can prove whether yours is.
The Cats of Context & Chaos
Permalink to “The Cats of Context & Chaos”
About Context & Chaos
Permalink to “About Context & Chaos”Context & Chaos isn’t just a newsletter. It’s shared community space where practitioners, builders, and thinkers come together to share stories, lessons, and ideas about what truly matters in the world of data and AI: context engineering, governance, architecture, discovery, and the human side of doing meaningful work.
Our goal is simple, to create a space that cuts through the noise and celebrates the people behind the amazing things that are happening in the data & AI domain.
Whether you’re solving messy problems, experimenting with AI, or figuring out how to make data more human, Context & Chaos is your place to learn, reflect, and connect.
Got something on your mind? We’d love to hear from you. Hit Reply!
Share this article