Satya Nadella’s article on what happens when context compounds went viral viral last week on X, and it’s easy to see why. He introduced a beautiful framework: a continuous learning loop where “human capital” and “token capital” reinforce one another, creating a compounding learning loop that will separate the organizations that thrive from those that commoditize.
It is a brilliant vision. But as those of us building the operational infrastructure for enterprise AI know, there’s a lot of work between this vision and reality. In most organizations today, the “hill-climbing machine” is stalled. The learning loop is hard to build, human capital hard to capture, and the whole system suffers from leaks.
But that doesn’t mean it isn’t worth doing. So I want to talk about what it’ll take to make Satya’s vision a reality, the architectural ins and outs of context engineering for AI.
What “human capital” actually means: the three elements of context
Permalink to “What “human capital” actually means: the three elements of context”Satya rightly points to “human capital” as one of the core elements of his vision. It’s easy to think of examples of human capital: private evals that know what “correct” means for your business, reinforcement from real organizational traces, a knowledge base that makes institutional expertise queryable.
In just a few examples, we already have a huge range of what human capital looks like and where it lives. And there’s the problem, most enterprise AI initiatives treat “context” (i.e. human capital) as a simple documentation problem, but it’s so much more complex. After all, there’s a reason why context has been a hot topic these days.
What I call context and Satya calls human capital is actually made up of three things:
- Knowledge, the map of your business. This comprises the semantic entities, definitions, metrics, and relationships. It is understanding exactly what “ARR” means in your finance motion versus your sales motion, or what a qualified lead looks like in your ideal customer profile (ICP).
- Expertise, how work actually gets done. These are the procedures and playbooks that encode tacit knowledge, institutional intuition, and the information that lives in people’s heads but never makes it into your core software systems.
- Norms, the programmatic rules of acceptable action. Which data can this agent access? Who approves this workflow? Which customer can be offered which discount? What data can and cannot leave a specific jurisdiction?
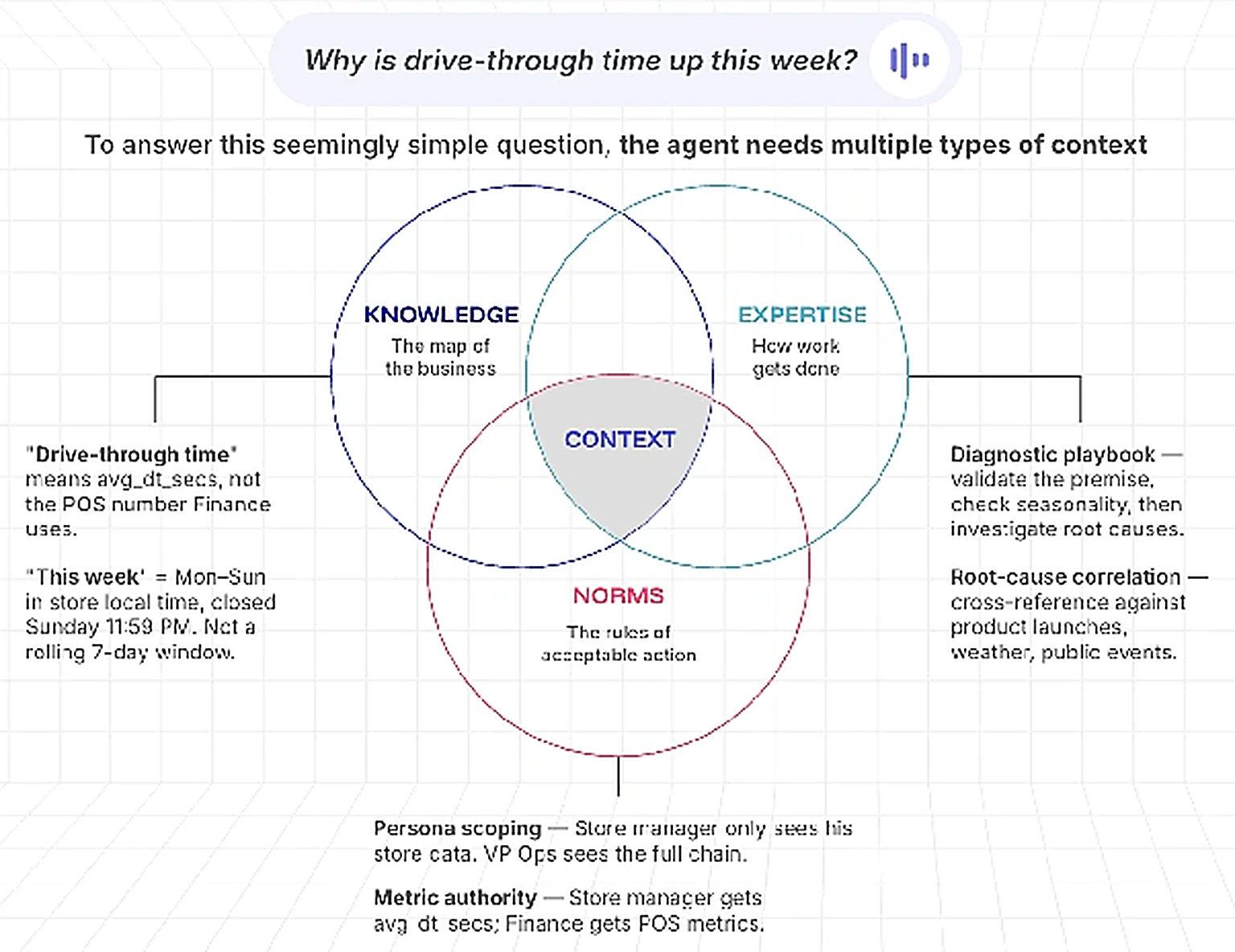
The context layer: a unified, actionable, governed place for all human capital
Permalink to “The context layer: a unified, actionable, governed place for all human capital”All of this context can’t exist in a prompt or database. It needs to live somewhere where it can be built upon and modified and governed over time, something that agents and humans alike can draw upon to create Satya’s hill-climbing machine. That’s what I began to call the context layer a year ago, and it has three distinct and important layers:
- An AI-ready data and knowledge graph makes structured data and unstructured knowledge machine-readable for agents. Tables enriched with descriptions, join paths, SQL patterns, and usage history. Documents identified, classified, and indexed into a governed knowledge graph. Without this, agents can’t distinguish trusted sources from stale ones.
- Semantics and ontology encode the map of the business with shared definitions, metric logic, and entity relationships. This is where it gets precise. Sales and Finance often disagree on the definition of ARR. When an agent queries “ARR,” which definition does it use? In most enterprises today, the answer is whichever one it happens to retrieve first. The semantic layer makes that question have one canonical answer, and reconciles the two versions when they conflict.
- Skills encode how work gets done. A skill is the new primitive that does for procedural knowledge what code did for logic in software. Each skill is a reusable, versionable, testable unit of how-to. The context layer manages skills the way software engineering manages code: version control, testing, lifecycle management, and clear ownership. The tenth agent inherits what the first nine learned.

The “human capital to token capital” linkage that Satya describes can’t function without all three of these layers. Data without semantics is uninterpretable. Semantics without skills can describe the business, but cannot operate it. Either one, deployed without governance, becomes a mess of contradictory instructions that no enterprise can safely trust.
It’s not just documentation: What it actually takes to build human capital
Permalink to “It’s not just documentation: What it actually takes to build human capital”The second structural bottleneck in building Satya’s learning loop is actually creating human capital or context. The default instinct is to think about this as documentation work: write down what everything means, index the documents, and connect the knowledge base. But that won’t be durable or scalable.
Human capital is dynamic. It can’t be captured passively, and it can’t be a one-time effort. The most valuable institutional knowledge isn’t written down anywhere. It’s in query logs, Slack threads where decisions got made, and the judgment calls the veteran employee makes differently from everyone else.
Here’s what it takes to actually find and document all important human capital, i.e. to populate the context layer:
- Skill-building during agent-building: Do the work manually with the agent once, then use AI to examine the session, extract the repeatable pattern, and write the skill with its triggers and edge cases. You can bootstrap an agent at 50% autonomy this way, and keep improving it toward 90%. Each task teaches the system something.
- Context Mining from systems: Read query history, detect where Sales and Finance are using two different definitions of the same metric, and surface the conflict for a human to resolve. The systems, like Slack, emails, and event logs, already contain most of what you need, if you know how to read them.
- Failure-driven capture: Don’t try to encode every procedure upfront. Run the agent, watch where it fails, and capture the missing context at the point of failure. Each failure is a signal. The library grows where agents actually work, not where someone guessed they would.
- Desktop shadowing: Shadow what top operators actually do on their machines via clicks, keystrokes, and app switches, then reverse-engineer their workflows. This captures the complex desktop processes that systems mining misses entirely.
- Structured AI interviews: The most important procedural knowledge is never logged anywhere. It’s judgment. AI can run structured conversations with employees to surface the exceptions, workarounds, and decision rules that observation can’t reach. “Walk me through the approval process. How do you actually decide?”
The context layer is assembled from a mix of approaches like these, actively running and refined over time. None of them produce finished context on their own. They produce candidates that a context development lifecycle, testing, review, approval, deployment, turns into governed, durable artifacts.
Learning leaks: The key failure point in the hill-climbing machine
Permalink to “Learning leaks: The key failure point in the hill-climbing machine”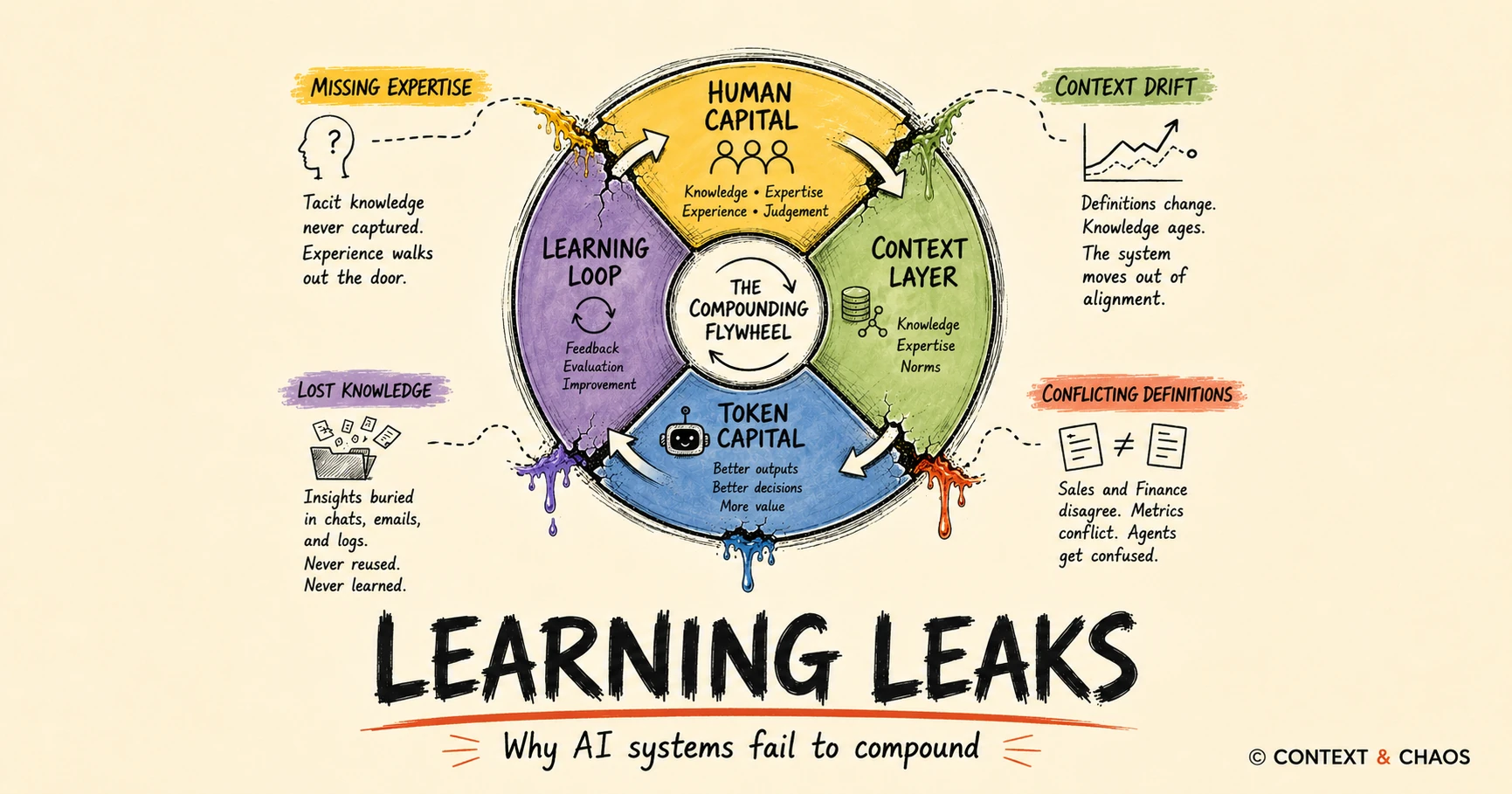
The true magic of Satya’s “hill-climbing machine” lies in its compounding mechanism.
Architecturally, there are four types of memory in any agent system. Working memory and episodic memory belong close to the agent, they represent the immediate execution state. Semantic memory and procedural memory belong deep inside the context layer, representing the knowledge the organization wants to preserve, govern, and make portable across different tools.
The compounding happens when episodic experience gets promoted into shared enterprise knowledge. A repeated exception becomes an explicit policy. A resolution path that consistently works becomes a reusable skill. The system should detect the emerging pattern, propose the update, and ask the right owner to certify it. Each certification makes the layer smarter for every future agent.
The key gap in this loop is context drift.
When a CMO updates company positioning or a finance lead tweaks a metric definition, that change creates an immediate blast radius. If that update doesn’t seamlessly propagate, you get a fragmented ecosystem where the social media skill, the SDR pitch skill, and the analyst call skill are all running on different versions of reality.
The context layer can’t just store knowledge. It has to understand the blast radius of every change and route updates to the right owners at the right moment. This requires building in critical tenets like versioning, change tracking, and context propagation. Without them, the learning loop turns into a learning leak.
The ultimate test: achieving ownership and portability
Permalink to “The ultimate test: achieving ownership and portability”Satya closed his piece with an excellent test: Can a company swap out an underlying generalist model without losing the enterprise veteran expertise it has built?
That’s a great test, but I’d add two more:
Can your AI agents agree on what “ARR” means, trace why they gave different answers last week, and get smarter from the correction, all without anyone touching a model?
Can you take all of your human capital and context from one agent platform or data ecosystem to another without losing a single day of institutional learning?
These are the real tests of enterprise AI today.
If enterprises build their human expertise into a proprietary software, custom GPT stack, or walled-garden orchestration layer, they have only traded model lock-in for platform lock-in. When the next major architectural breakthrough happens outside that ecosystem, their hard-won context will be trapped.
Satya’s warning about the instability of a frontier without an ecosystem and the danger of a few all-consuming models is profoundly right. But the solution isn’t just building local applications on top of big platforms. The solution is creating absolute portability.
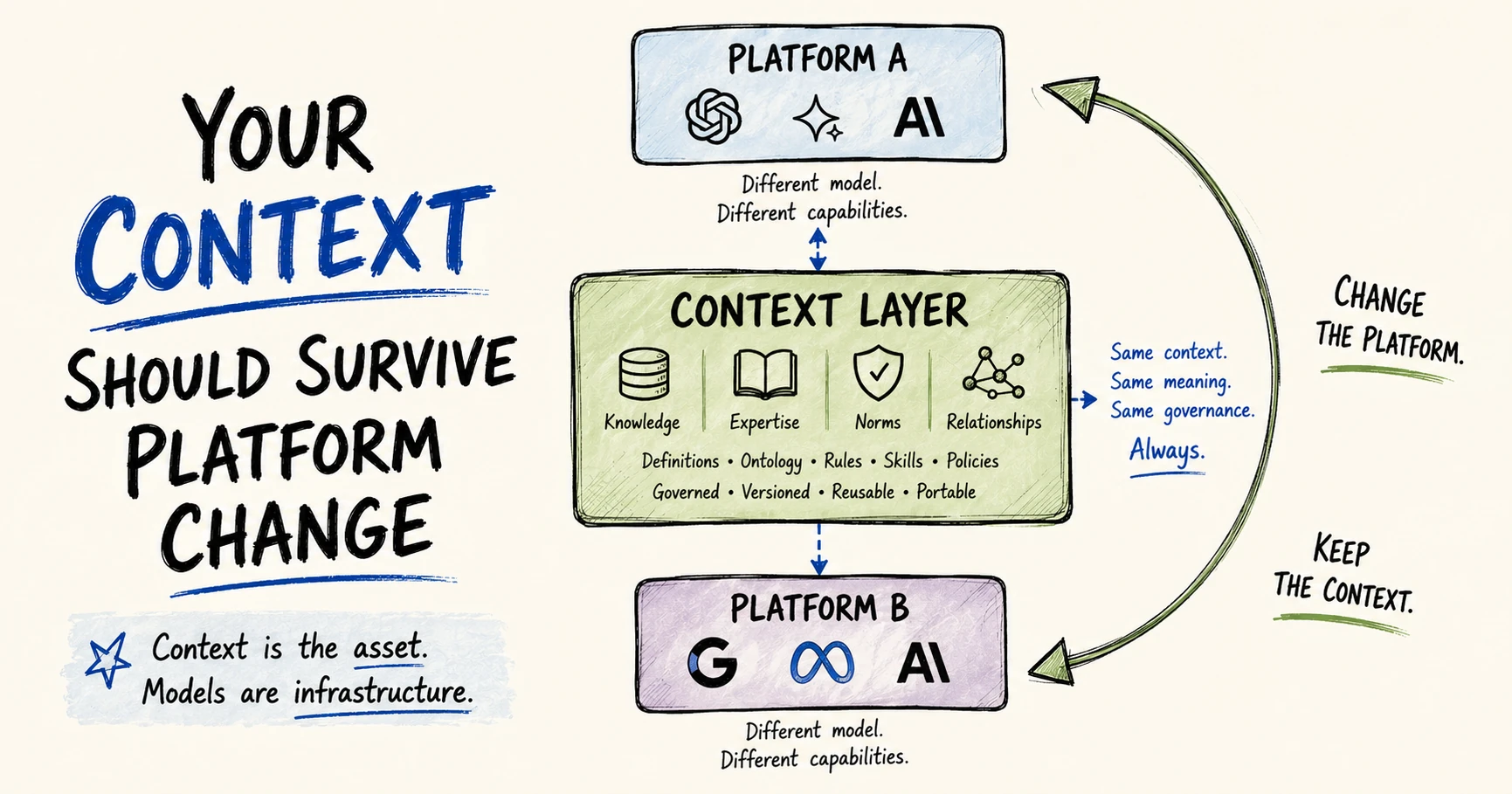
Context is your core IP, the digital distillation of your human capital. The organizations that treat context as a durable asset, rather than a consumed resource or a documentation project, are the ones who will harness this powerful compounding loop and climb the hill to Satya’s vision.
The Cats of Context & Chaos
Permalink to “The Cats of Context & Chaos”
That’s all for this edition. Stay curious, keep exploring, and see you all in the next one!
About Context & Chaos
Permalink to “About Context & Chaos”Context & Chaos isn’t just a newsletter. It’s shared community space where practitioners, builders, and thinkers come together to share stories, lessons, and ideas about what truly matters in the world of data and AI: context engineering, governance, architecture, discovery, and the human side of doing meaningful work.
Our goal is simple, to create a space that cuts through the noise and celebrates the people behind the amazing things that are happening in the data & AI domain.
Whether you’re solving messy problems, experimenting with AI, or figuring out how to make data more human, Context & Chaos is your place to learn, reflect, and connect.
Got something on your mind? We’d love to hear from you. Hit Reply!
Share this article