


















Data quality platforms tell humans what data to trust. Atlan is the context layer for AI that makes sure every agent knows the same thing.
Data quality was built to catch bad data for humans. AI needs to know what's trustworthy too.
Data quality platforms were built for data engineers and stewards — monitoring pipelines, alerting on anomalies, scoring freshness and completeness so humans could decide which data was safe to use. The right tool for a world where humans were the primary consumers of data.
AI agents don't receive quality alerts. They don't review monitoring dashboards before querying. Without quality context surfaced through the context layer, an agent has no way to know whether the data it's acting on is complete, fresh, or certified. It produces answers from stale tables, missing values, and assets your team flagged as unreliable months ago — not because the model is wrong, but because it never knew the data was.
Atlan is the context layer for AI — the infrastructure that makes every AI agent in your stack accurate, trustworthy, and production-ready. The context layer is broader than quality: it includes governance, semantic definitions, lineage, and the institutional business knowledge encoded in every query and dashboard your team has built. But quality context is foundational. Every agent needs to know which data to trust before it can act on it correctly.
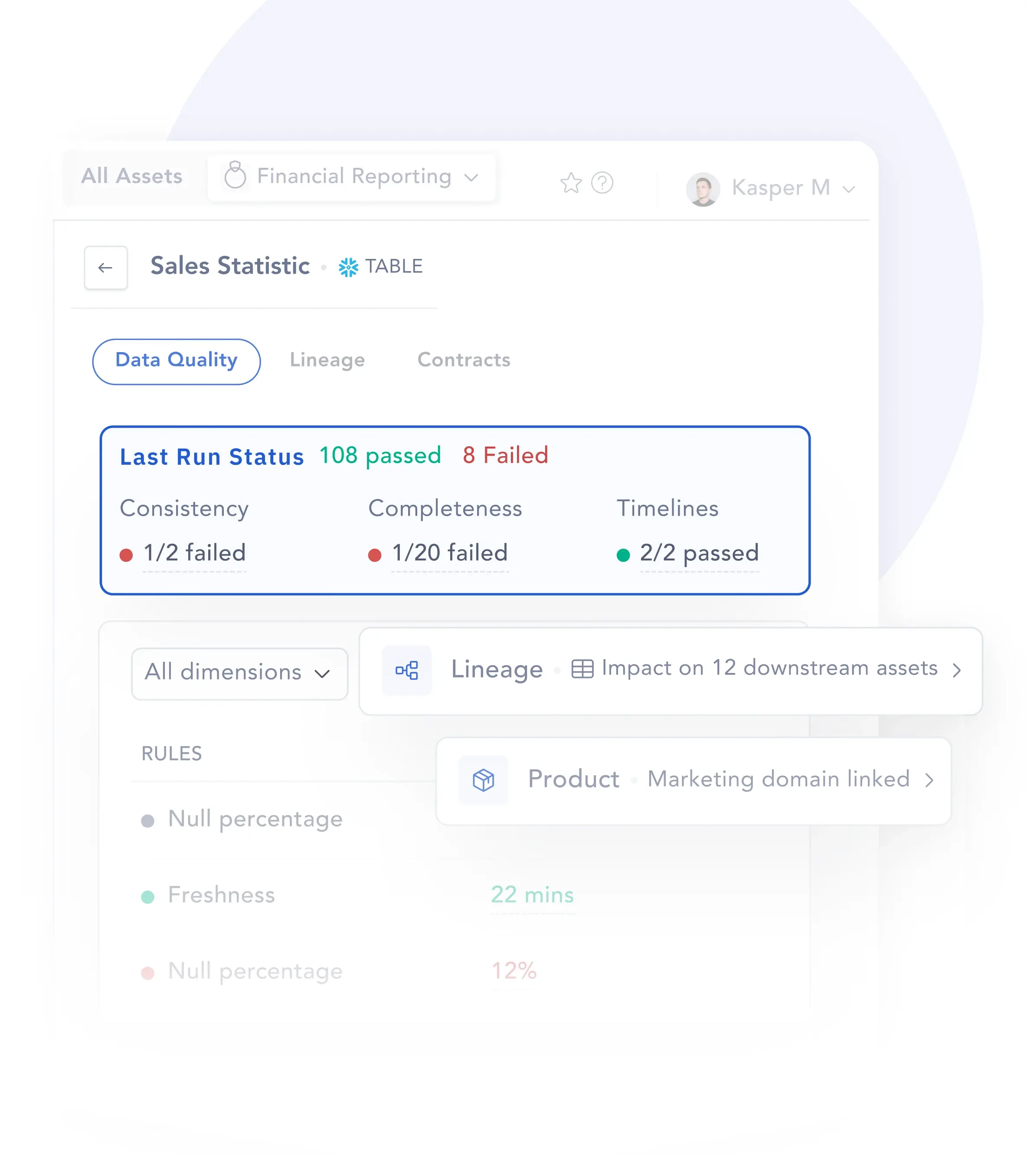
Vera, Atlan's Data Quality agent, continuously scores your critical assets on completeness, accuracy, and freshness. Those scores propagate along Data Lineage to every downstream asset and every AI agent automatically — so quality context travels with your data, not behind it. Context Engineering Studio tests whether agents are producing correct answers against your existing dashboards and business questions — surfacing when quality gaps are causing agents to get things wrong, before users find out in production.
From data quality monitoring to quality context that every agent knows.
The context layer for AI spans governance, semantic definitions, lineage, and business knowledge — but quality context determines which data any agent should trust. Here's how Atlan delivers it automatically.
Quality context scored automatically
Vera, Atlan's Data Quality agent, scores every critical asset on completeness, accuracy, and freshness — continuously, at scale. No manual DQ rule-writing. No monitoring dashboards to review before an agent queries. Quality context is embedded in the asset itself, always current.
Quality context propagates along lineage
Data Lineage carries quality signals downstream. When Vera scores an asset as incomplete or stale, every downstream asset and every AI agent that depends on it inherits that signal automatically. Agents know which data to trust — and which data fails quality thresholds — before they act.
Agent outputs validated before production
Context Engineering Studio auto-generates test suites from your existing dashboards and business questions, then tests agent responses against expected answers. When quality gaps cause an agent to produce wrong results — missing context, wrong numbers, answers that don't hold up — test failures surface the issue before users encounter it in production.
Leading AI teams use Atlan to connect context
- Watch Video


- Watch Video


- Watch Video


- Watch Video


Quality context. Scored automatically. Compounded continuously.
Vera scores every critical asset on completeness, accuracy, and freshness — and every score compounds with governance, lineage, and semantic context so AI agents get a complete picture of what they can trust.

Data catalogs were built for humans... who never documented them.
In 2023, we launched the first AI documentation agent.
We called it Atlan AI. It could write descriptions automatically, but accuracy was at 75%. Good enough to show the vision, but not good enough to replace human work.
We realized AI accuracy at scale needed a rebuild.
To be accurate, AI needed to access rich signals like lineage, query history, usage patterns, relationships between assets. Atlan stored all of that, but AI couldn't use it. So we rebuilt the foundation: the Context Lakehouse.
Today, context agents outperform humans on quality.
Customers are telling us the agent-written descriptions are more accurate and more complete than what their teams were producing manually.
Start your AI-readiness sprint.
Learn how Context Agents can get you to AI readiness in 30 days.
Book a Strategy SessionRollout in 30 days, not 12 months.
Start With What Matters
Most of your catalog nobody touches. Context Agents identify your Gold Layer, Popular BI, Popular SQL, and upstream dependencies first — enriching the assets people actually use before spending cycles on the long tail. Value shows up in days, not months.
AI Scores Every Output
Each agent output carries a composite confidence score across accuracy, clarity, style, and completeness. High-confidence outputs auto-apply. Lower-confidence outputs route to humans.
Humans Decide & Govern
AI generates descriptions, classifies assets, builds metrics, and scores quality at scale. Stewards shift from documentation to certification — sampling, validating, and resolving the cases that require judgment. One click. Not 847 manual reviews.
Know your agents are producing correct answers before they ship.
Context Engineering Studio auto-generates test suites from your existing dashboards and queries — comparing agent outputs against expected answers. When quality gaps cause wrong results, test failures surface the issue before production, not after.
Know when your agent is ready before your users find out it isn't.
Know when your agent is ready before your users find out it isn't.
The hardest problem in enterprise AI is knowing whether your agent works accurately in real world business scenarios and what context it's missing. Context Engineering Studio reads BI dashboards and SQL queries for context, generates 100s of questions that your AI agent needs to answer correctly, and turns those into an evaluation suite.

Trusted by AI-forward enterprises
"Atlan captures Workday's shared language to be leveraged by AI via its MCP server. As part of Atlan's AI labs, we're co-building the semantic layer that AI needs."
Joe DosSantos
VP Enterprise Data & Analytics, Workday
Quality scores that travel with your data. Automatically.
When Vera scores an asset as stale or incomplete, that signal propagates to every downstream asset and every AI agent that depends on it — so agents always know which data to trust, without checking a monitoring dashboard first.
A living graph that connects everything
and compounds everything.
A living graph that connects everything and compounds everything.
"With Google DataPlex, lineage only showed part of the story. Our business operates across many systems and we needed complete, enterprise-wide lineage. Atlan's platform was more intuitive, delivered on complex end-to-end lineage, and had a strong library of connectors. We also used OpenLineage for Spark jobs to tie operational lineage to our data platform."

Zenul Pomal
Core Data Platform & Enterprise Architecture, CME Group
18M+
Assets
Cataloged
1,300+
Glossary terms
connected
100+
Active
Users
The future of context, validated by Forrester and Gartner
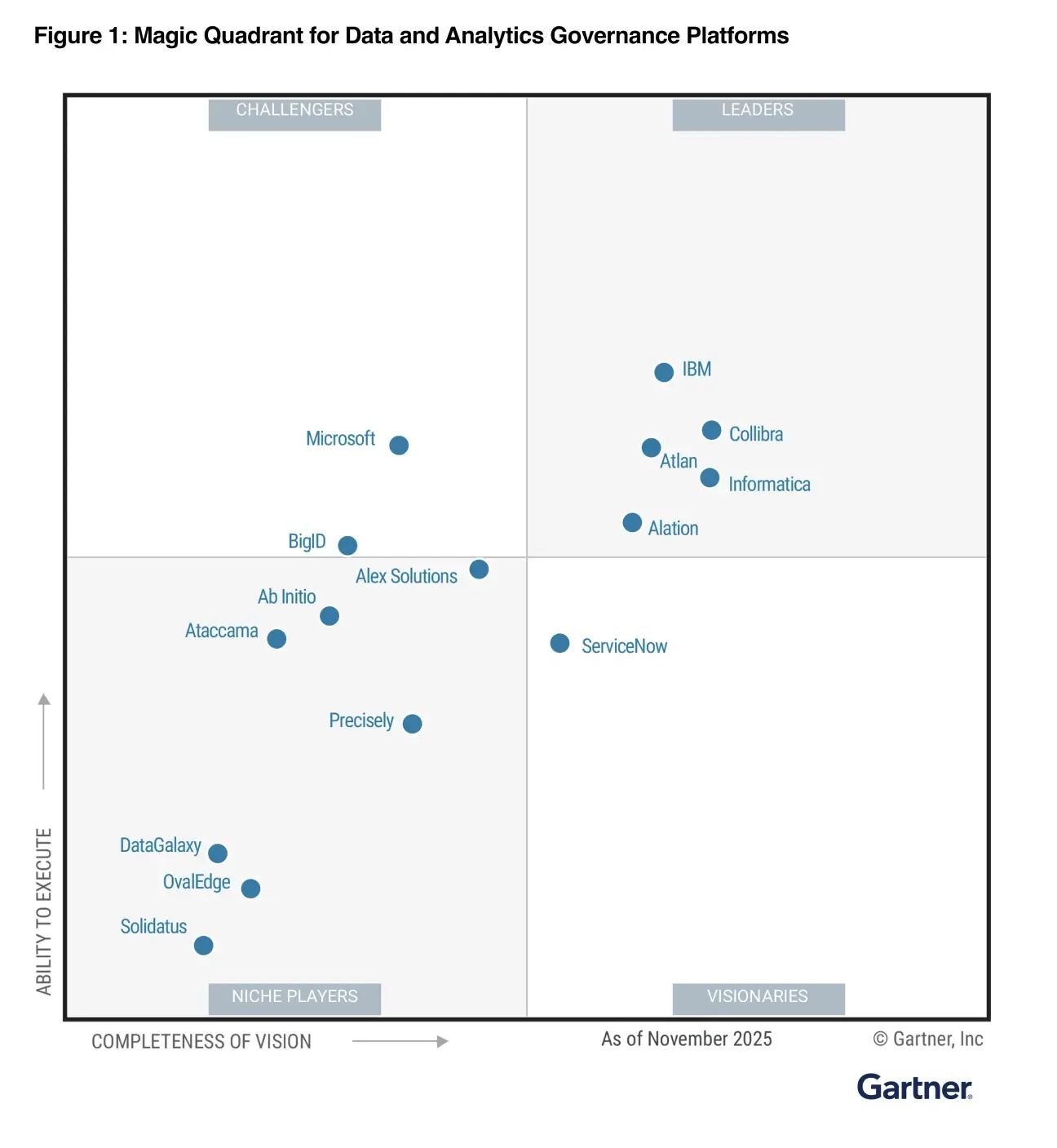
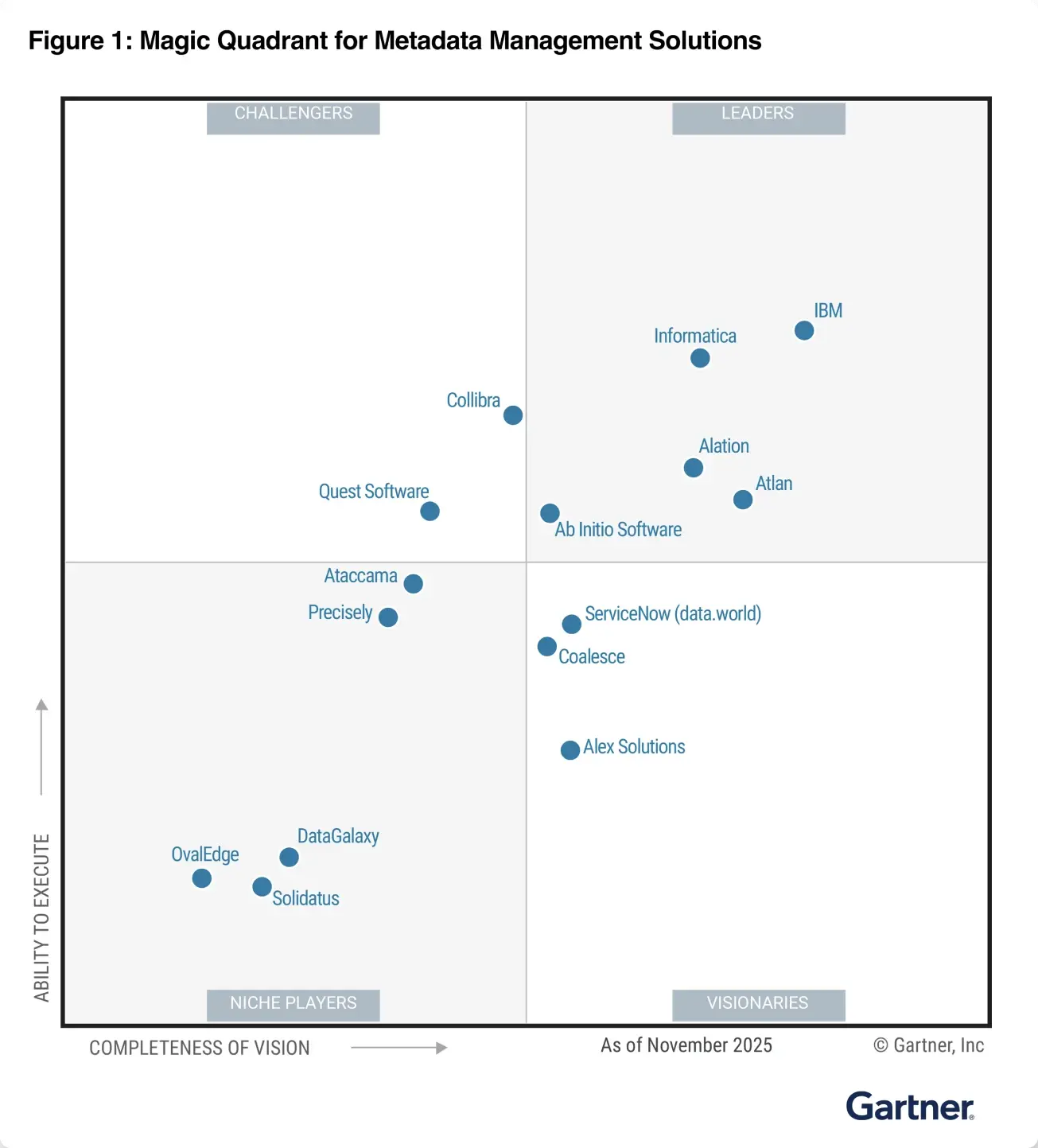
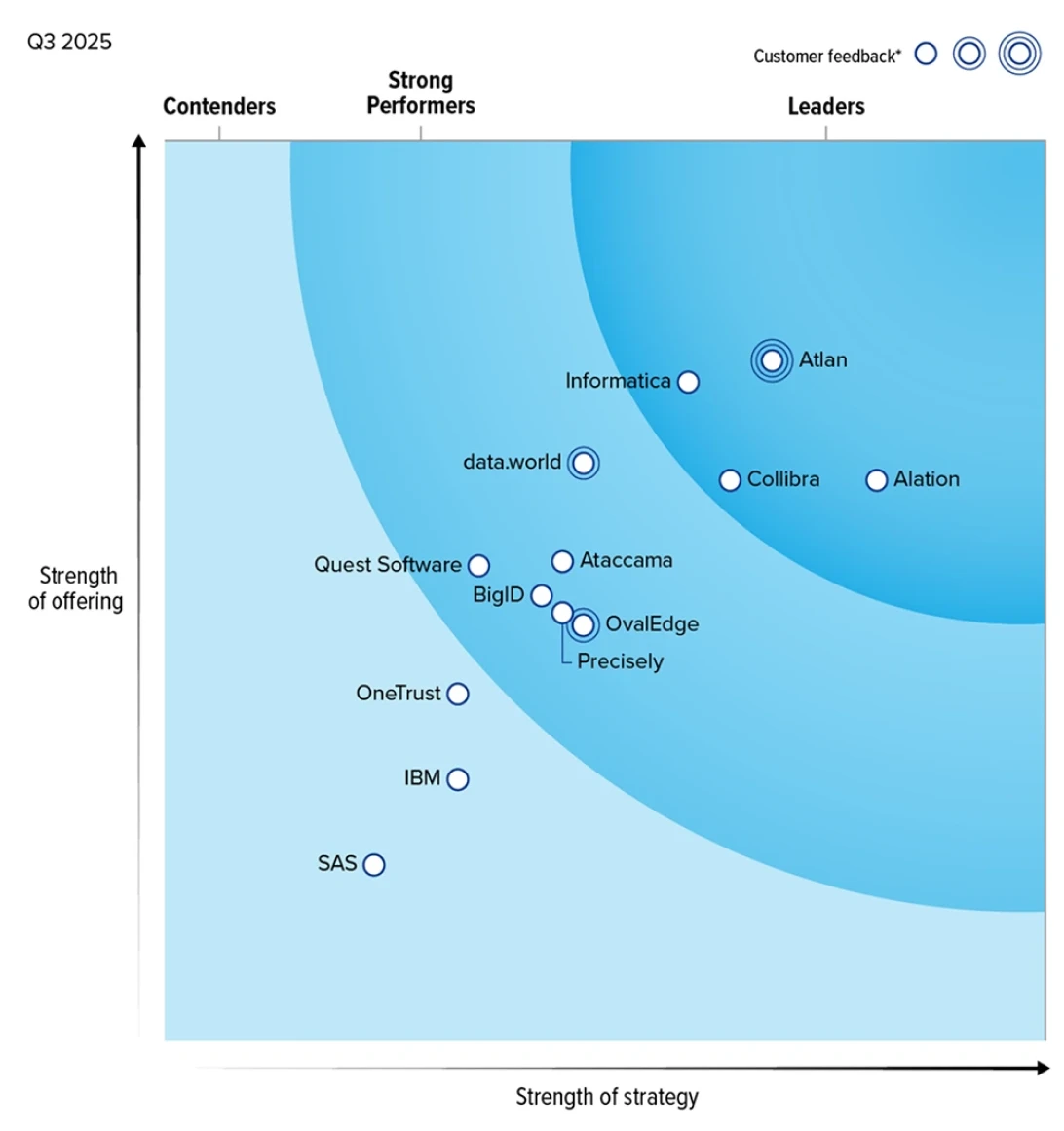
Every layer of the context layer for AI.
Data quality platforms told humans which data to trust.
This is the context layer for AI.
30-min call. An honest conversation