



















Quick facts on context engineering for AI analysts
Permalink to “Quick facts on context engineering for AI analysts”| Field | Detail |
|---|---|
| What it is | The practice of curating, governing, and delivering the right information to an AI model at the moment it answers |
| Key benefit | Closes the context gap that causes most enterprise AI pilots to die in production |
| Replaces | Ad hoc prompt stuffing, hardcoded business logic in prompt templates, and one-off RAG pipelines |
| Prerequisites | A trusted metadata foundation: catalog, glossary, lineage, quality signals, and access policies |
| Key metric | Anthropic’s multi-agent research system beat its single-agent baseline by 90.2%, with 80% of the variance explained by token usage alone |
| Core components | System instructions, business glossary, semantic layer, retrieval, tool definitions, memory, governance |
Ask three people at any large company what counts as an active customer. You will get different answers.
Marketing tracks email opens in the last 90 days. To finance, the test is whether a customer holds a paid contract that has not churned. Product looks at weekly logins. The customer success team waits until the next renewal date before retiring anyone from the active list.
None of these definitions is wrong on its own. It’s active use. Each one feeds a dashboard that somebody on the leadership team checks.
The trouble starts the moment somebody asks the AI analyst, in plain English, how many active customers the company has right now. The model has to pick among several definitions. It usually picks the definition most loudly written into the table names it can see. It’s almost never the same definition the executive had in mind.
This is the gap that ends several enterprise AI pilots because the model never receives a shared understanding.
What does context engineering really mean?
Permalink to “What does context engineering really mean?”Context engineering is the practice of designing the information an AI model sees before it answers. That includes system instructions, the user’s question, retrieved documents, tool definitions, conversation history, and the policies that govern what the model can use.
Anthropic’s September 2025 engineering playbook defines it cleanly. The discipline is “the set of strategies for curating and maintaining the optimal set of tokens (information) during LLM inference, including all the other information that may land there outside of the prompts.”
Prompt engineering treated the prompt as the whole job. Context engineering treats the prompt as one input among many. Every one of those inputs has to be designed and governed as a system.
Context engineering vs. prompt engineering
Permalink to “Context engineering vs. prompt engineering”Prompt engineering and context engineering aren’t twins. Prompt engineering is the craft of writing instructions. It tunes wording, examples, role framing, and output format. The unit of work is one prompt. Context engineering is about deciding what information the model gets to see in the first place. Its unit of work is the full context window, spanning an entire session, sometimes an entire organization.
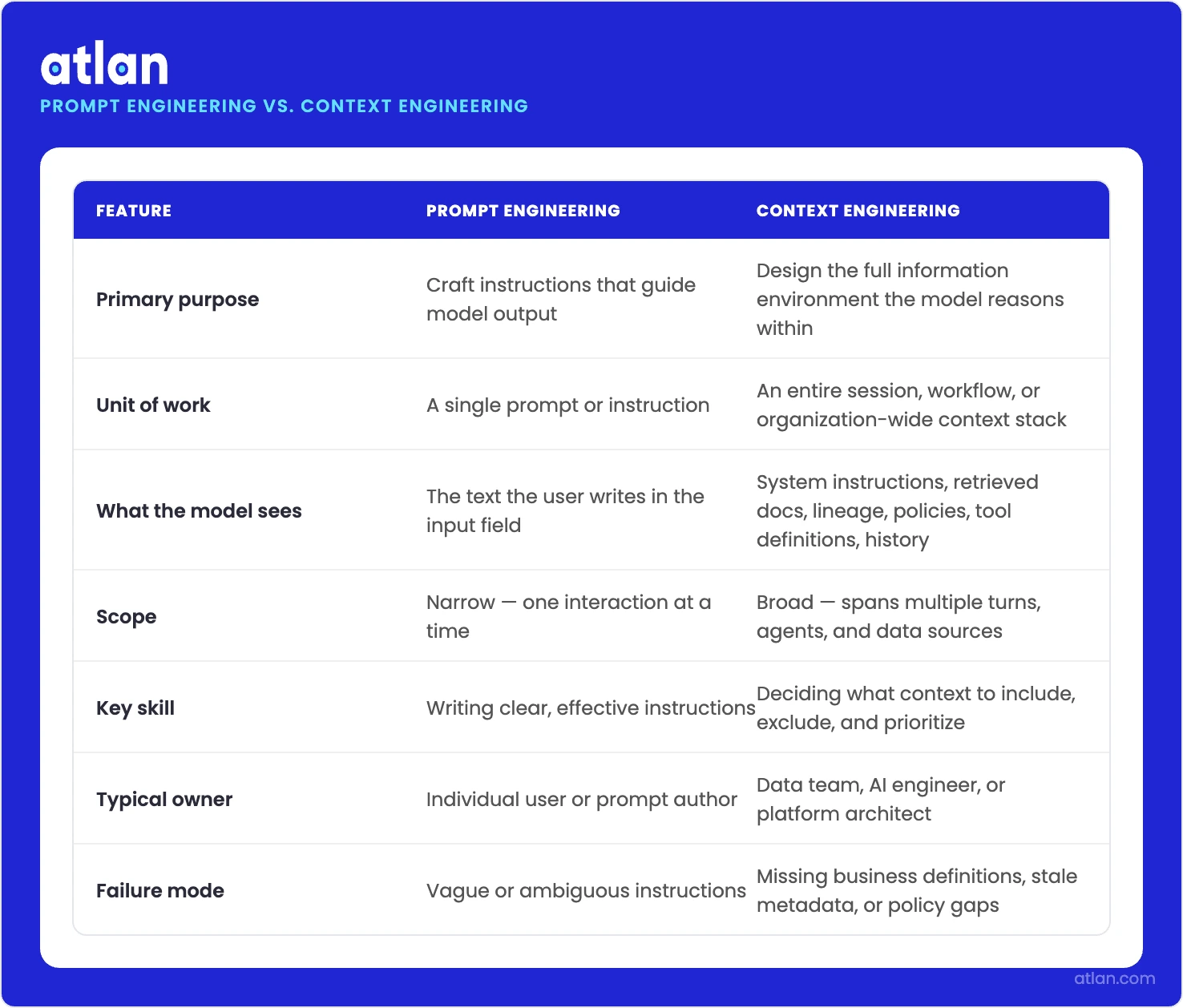
How prompt engineering and context engineering differ in scope, unit, and purpose. Source: Atlan.
To do the context engineering job well, you need data engineering and governance skills far more than you need writing skills.
The differences are easier to see laid out side by side:
Context engineering vs. prompt engineering
| Dimension | Prompt engineering | Context engineering |
|---|---|---|
| Unit of work | A single prompt template | The full context window across a session |
| Who owns it | Whoever writes the prompt | A cross-functional data, AI, and governance team |
| Scope | Wording, examples, output format | Definitions, retrieval, memory, tools, policies, lineage |
| Failure mode | Wrong wording or missing examples | Missing definitions, stale data, ungoverned access |
| Maintenance | Edit the prompt | Update the underlying context layer |
| Skill background | Writing and instruction design | Data engineering, semantics, governance |
Gartner’s July 28, 2025 research note captured the shift in unusually direct language for an analyst firm. “Context engineering is in, and prompt engineering is out. AI leaders must prioritize context over prompts, build context-aware architectures, integrate dynamic data, and reimagine human-AI interfaces.”
Strong claims are not Gartner’s house style. This one landed less than six weeks after Lütke’s tweet.
Is context engineering just retrieval-augmented generation with a fresh paint job?
Permalink to “Is context engineering just retrieval-augmented generation with a fresh paint job?”No. RAG is one retrieval technique that pulls relevant chunks into a prompt. Context engineering decides what the model sees at all, in what order, from which sources, at what freshness, and what to drop when the window fills.
The question RAG answers is narrow: what extra information should this model see for this query?
| Dimension | RAG | Context engineering |
|---|---|---|
| Scope | One retrieval technique | The full discipline of designing what the model sees |
| Core question | What documents should I fetch for this query? | What should the model see at all, from where, how fresh, and what to drop? |
| Unit of work | A single retrieval call | The entire context window across a session |
| What it covers | Document chunks from a vector store | Instructions, retrieval, tools, memory, history, and governance signals |
| Governance | Minimal; returns whatever the index has | Classifications, certifications, lineage, and access policies as quality gates |
| Owner | ML or platform engineering | Data engineering, semantic modeling, and governance combined |
| Relationship | Fits inside context engineering | The broader discipline that decides how and when RAG is used |
Context engineering answers a much larger question. What should the model see at all? In what order, with what governance, drawn from which sources, at what freshness, and what should be discarded when the window fills up?
RAG fits inside context engineering as one of several retrieval strategies. Not the whole discipline.
Anthropic makes a related point through what it calls the just-in-time pattern. Instead of preloading everything an agent might possibly need, the agent fetches context on demand from authoritative sources. Anything no longer relevant gets dropped on the spot. The pattern is closer to how a senior analyst actually works on a hard question.
Why AI analysts fail without context engineering
Permalink to “Why AI analysts fail without context engineering”Context engineering exists because most enterprise AI pilots fail in production. MIT NANDA found 95% of GenAI pilots delivered no P&L impact across $30 to $40 billion in spending. The model is no longer the bottleneck. The data and governance feeding it are.
The same MIT report asked executives what they actually want from AI tools. Sixty-six percent of executives want systems that learn from feedback. Right behind that, sixty-three percent demand tools that retain context between sessions and across workflows.
Context retention is no longer a future roadmap item. It is the second-most-cited demand from the people writing the checks, ahead of nearly every model capability.
LangChain’s State of Agent Engineering 2025 survey sharpened the picture from the practitioner side. Quality remained the top blocker in the same survey. Roughly a third of respondents named it as their biggest production headache.
Write-in answers from large enterprises pointed at one specific cause: ongoing difficulties with context engineering and managing context at scale.
What are the components of context engineering?
Permalink to “What are the components of context engineering?”Context engineering pulls together eight working parts: system instructions, user input, retrieved knowledge, tool definitions and outputs, memory, conversation history, and governance signals. You decide which ones a task actually needs, how fresh they should be, and how tightly to compress them.
The clearest taxonomy of what context engineering actually contains comes from A Survey of Context Engineering for Large Language Models, an arXiv paper by Mei et al. published in July 2025.

Every working part that shapes what an AI model sees before it answers. Source: Atlan.
The paper runs 166 pages. It reviews 1,411 separate research papers. The authors treat context engineering as a formal field rather than a tooling category. From there, they organize the moving parts into a few clean families, including:
- System instructions are the standing rules. They tell the model how to behave, what tone to take, and which guardrails to respect. Once set, these rarely change between requests.
- User input is the actual question or task the model is currently facing.
- Retrieved knowledge is the documents, rows, definitions, and examples pulled from external stores at query time. Most people associate this layer with retrieval-augmented generation, though it covers more than that.
- Tool definitions and outputs describe which functions an agent can call, plus the structured results of any calls it has already made.
- Memory holds short-term scratchpads from the current session and long-term records from prior ones.
- Conversation history is the running transcript of the current exchange. It gets summarized or compacted as it grows.
- Governance signals are the access policies, classification tags, and quality flags that decide what the model can see.
The trap is treating these as a checklist.
Context engineering is not about stuffing all of them into a window. It is the act of choosing, for any given task, which to include, how fresh they need to be, and how to compress them so the model still has room to think.
Context rot: why bigger context windows are not the fix
Permalink to “Context rot: why bigger context windows are not the fix”For most of 2024, the prevailing instinct was to wait for longer context windows. Bigger window, more information, better answer.
The instinct turned out to be wrong. There is now hard evidence to back the correction.
Chroma’s July 2025 Context Rot study put eighteen frontier LLMs through a stress test. The list included Claude Opus 4 and Sonnet 4, GPT-4.1, Gemini 2.5 Pro, Qwen3 235B, and o3.
The study ran 194,480 LLM calls across eight input lengths and eleven needle positions. Its headline finding was that model performance varies sharply as input length grows, even on tasks that the same models handle perfectly when the input is short. Chroma named the failure mode “context rot.”
One of their tests, using LongMemEval, compared full prompts averaging around 113,000 tokens against focused prompts averaging around 300 tokens. The focused prompts won.
Anthropic also explains the underlying mechanism in physical terms. In a transformer, every token attends to every other token, producing roughly n² pairwise relationships. As the context grows, the model’s ability to track those relationships gets stretched thin. Anthropic calls it “a natural tension between context size and attention focus.”
The takeaway for enterprise teams is simple in principle and uncomfortable in practice. Pouring more documents into a longer window does not produce a better answer. It produces a more confused one.
Context engineering treats the window as a scarce resource and deliberately decides what gets in.
The five-layer context framework for AI analysts
Permalink to “The five-layer context framework for AI analysts”The five-layer structure for AI analysts includes the model layer holding instructions, the user layer carrying the question and permissions, the business layer defining metrics and policies, the domain layer mapping relationships and lineage, and the data layer holding the actual rows and freshness signals.
For data teams building AI analysts, there is a more workable mental model than the academic taxonomy. Five layers, each with one owner and one job.
- The model layer holds the standing instructions and the model’s pretrained knowledge. Role framing and behavioral rules live here.
- The user layer carries the question, plus signals about who is asking and what that person can see.
- The business layer holds the definitions, the metrics, the policies, and the canonical glossary. “Active customer” is defined here once for use everywhere.
- The domain layer captures the relationships between business concepts, ownership, and lineage. It’s the map the agent uses to find the right table, not just any table.
- The data layer is the actual rows, columns, and freshness signals, governed by access policies and quality rules.
The framework is not a diagram for a diagram’s sake. It exists so that a data team has somewhere to look when the AI analyst gives a wrong answer.
Wrong because the metric definition is off? That is a business-layer fix. If the agent picked a deprecated table, the problem lives in the domain layer. Stale row? Look at the data layer.
Each layer has its own owner, its own tool, and its own remediation path. None of them is the model.
Context engineering for agentic AI: what changes when agents replace analysts
Permalink to “Context engineering for agentic AI: what changes when agents replace analysts”Agents plan, call tools, and run for hours, so context management decides whether they stay coherent. Anthropic’s multi-agent research system beat a single-agent baseline by 90.2% using the same model. Token usage alone explained 80% of the variance in performance.
So far, this guide has assumed a single AI analyst answering a single question. Agents change the math.
An agent does not answer once. It plans, calls tools, spawns subagents, runs for hours, and decides what to remember along the way. The longer the run, the more carefully the context has to be managed.
Anthropic’s June 2025 writeup of its multi-agent research system gives the clearest empirical view available right now. A lead agent on Claude Opus 4, coordinating subagents on Claude Sonnet 4, beat a single-agent Claude Opus 4 baseline by 90.2% on internal research evaluations. The model stayed the same. Only the architecture changed.
Three factors explained 95% of the variance in the BrowseComp evaluation. The largest single factor was token usage, which by itself explained 80%. The number of tool calls and the choice of models rounded out the rest.
The token bill that came with this architecture was steep. Multi-agent systems used roughly 15 times as many tokens as chat interactions. Even a standard agent burned through about 4 times more.
Subagents in Anthropic’s research system might explore extensively, burning through tens of thousands of tokens while they investigate. They return only a condensed summary to the lead agent, often 1,000 to 2,000 tokens. The compression step is context engineering at its purest.
Claude Code uses a similar move at the session level. When the message history grows too long, the assistant compacts it into a summary, then continues with this compressed context plus the five most recently accessed files.
The choice of what to keep, what to summarize, and what to drop is not incidental. It is the design surface that decides whether the agent stays coherent over a long task.
Stanford HAI’s 2025 AI Index put numbers on the broader pattern. On RE-Bench, top AI systems score four times higher than human experts at a 2-hour task budget. Humans flip the result 2-to-1 once the budget reaches 32 hours.
The longer the horizon, the more the agent needs disciplined context management to stay on track. This is where the real bottleneck exists.
For data teams, supporting agents is a different job from supporting analysts. Agents need stable context products they can call repeatedly, the way a library of functions works for a human developer. Predictability is the whole point.
Clear tool boundaries matter just as much. An agent has to reason about which calls are even available before it can reason about which one to make. The lineage they consume cannot be the kind that just looks good in a UI. It has to explain relationships that the agent can act on. And the working memory must be able to compact itself without losing the threads that mattered most.
How does MCP fit into the context engineering stack?
Permalink to “How does MCP fit into the context engineering stack?”The Model Context Protocol lets any AI assistant query a standardized server for context, tools, and resources. A catalog exposes one MCP endpoint, and every compliant assistant uses it. Whoever owns that endpoint owns the context layer, while models stay interchangeable underneath.
One of the quieter shifts in the second half of 2025 was the rise of the Model Context Protocol (MCP).
MCP is an open protocol. It lets any AI assistant query a standardized server for context, tools, and resources, without each AI product having to build a custom integration into your catalog, glossary, and lineage.
The catalog exposes an MCP server once. Every compliant assistant uses it from there. ChatGPT, Claude Desktop, IDE copilots, and in-product agents all talk to the same governed source of truth.
For a data team, this changes the procurement question entirely. The decision is no longer which AI tool to standardize on. It becomes the context source every AI tool should standardize on.
Whoever owns the MCP endpoint owns the context layer. Models become interchangeable. The context layer underneath them does not.
There is a structural reason metadata platforms moved fast on MCP support. A catalog already contains the glossary, lineage, certifications, and access policies. By accident of history, a metadata platform is the most natural MCP server in the enterprise.
Atlan’s MCP server, for example, exposes the same business definitions and column-level lineage that human analysts already use. An AI agent asking “what is active revenue” gets its answer from the same source the finance team curated, instead of guessing from table names.
Context products: Context engineering’s unit of production
Permalink to “Context products: Context engineering’s unit of production”A context product is a versioned, governed bundle built around one business concept, packaging its definition, lineage, access policies, certifications, and test cases into something an AI agent can call directly. Treating context this way forces the same hygiene that data products forced on raw tables, and it stops definitions from drifting across teams.
If context engineering is the discipline, context products are the unit you ship.
A context product is a versioned, governed bundle built around a specific business concept. It might cover monthly recurring revenue under the canonical definition, the lineage of every input table, the policies on who can see which slices, the certifications, and the test cases that confirm the definition still holds in production.
Treating context this way forces the same hygiene that data products forced on raw tables.
Without those guardrails, context drifts.
The arXiv survey points to a deeper version of the same problem. It identifies what the authors call a “fundamental asymmetry” between what models can understand and what they can generate.
With good context engineering, models absorb astonishingly complex inputs. You cannot rely on the model alone to maintain consistency over time. The consistency has to live in the context layer; in versioned products, the model can call.
Why is governance the foundation of context quality?
Permalink to “Why is governance the foundation of context quality?”An ungoverned context actively harms AI accuracy. Without classifications, certifications, and lineage, an agent confidently pulls from deprecated tables or wrong-grain copies. You need a governed context for accurate AI outcomes.
A point gets lost in most developer-focused coverage of context engineering. An ungoverned context is not neutral. It is actively harmful.
Picture an AI analyst with permission to retrieve from any table it can find. Sometimes the agent reaches for a deprecated table. On the next query, it ends up in a personal sandbox copy that some analyst spun up six months ago. And occasionally it lands on a table whose name is correct but whose grain is all wrong.
The answer it gives looks confident every single time. Models do not know what they do not know. The cost of a confidently wrong answer in a board meeting is much higher than the cost of no answer at all.
Governance is what stops this. Classifications tag PII so the agent never pulls it into a window where it does not belong. The certification layer is what flags a table as the source of truth. At retrieval time, row-level access policies determine who sees what, rather than leaving cleanup until after the fact. Why did a number change? Lineage answers that question. And when a freshness SLA gets missed, the quality signal raises a flag.
In a context engineering practice, every one of these governance primitives doubles as a context quality gate. Human users were the original audience for these controls. AI agents happen to need exactly the same things.
Gartner’s June 17, 2025 newsroom prediction underlined the economics of getting this right. “By 2027, organizations that prioritize semantics in AI-ready data will increase their GenAI model accuracy by up to 80% and reduce costs by up to 60%. Poor semantics in GenAI lead to greater hallucinations, more tokens required, and higher costs.”
Bad semantics do not just produce wrong answers. Each wrong answer also arrives with an inflated token bill. The model burns context window space trying to disambiguate things that a glossary should have settled in advance.
What enterprise data teams already have
Permalink to “What enterprise data teams already have”Here is the reframe that matters most for the audience this guide addresses.
If you have spent the last several years building catalogs, glossaries, lineage, and quality programs, you have already been doing context engineering. You did not call it that because nobody called it that until last summer. The artifacts you produced are exactly the ones AI agents now need.
A business glossary is a context product wearing the wrong label. The lineage graph you already maintain works as a retrieval index, except its current consumer is human. Behind every certification workflow sits a context quality gate, originally intended for human analysts. As for access policies, they already know how to enforce row-level rules and PII tagging. The only thing missing is pointing them at AI agents instead of humans.
The work that remains is not to start over. It is to expose what already exists through interfaces that AI agents can actually consume.
An MCP server handles this exposure at the protocol level. Building a context layer is what turns that exposure into a discipline. It’s the gap most enterprises are looking at right now.
How Atlan helps enterprise teams build the context layer
Permalink to “How Atlan helps enterprise teams build the context layer”Atlan started life as a metadata platform for human data teams long before context engineering had a name.
The same primitives that powered a decade of governance work, the business glossaries, the column-level lineage, the certifications, the classifications, the active metadata, and the metadata lakehouse, turned out to be the exact ingredients an enterprise context layer needs.
Gartner named Atlan a Leader in its 2026 Magic Quadrant for Data and Analytics Governance Platforms. The recognition matters for one specific reason here: the same governance and metadata foundation that earned those placements is what the context layer runs on.
A few capabilities are doing the heavy lifting for context engineering, specifically.
- The Context Engineering Studio gives data teams a hub for bootstrapping, enriching, and testing context products. It captures business definitions, links them to physical tables through lineage, and routes the result into AI systems through APIs and MCP.
- The MCP server exposes glossary, lineage, certifications, and policies through the open Model Context Protocol. Agents in ChatGPT, Claude, and in-product copilots all draw from the same governed source.
- Active metadata keeps the context graph current as schemas, ownership, and definitions change. It is the only practical defense against context drift.
- Column-level lineage translates the structural relationships between tables into a form an agent can reason about, not just a diagram a human can read.
- Governance policies apply the same access controls used for human users to AI agents at query time, so PII and access rules do not collapse the moment an LLM enters the loop.
The customer evidence so far points in the same direction. In Atlan AI Labs workshops, customers, including Workday, saw a 5x improvement in AI analyst response accuracy after embedding metadata context through Atlan’s MCP server.
In a separate Atlan test, 174 queries were evaluated three times each, 522 total runs, against a Formula One dataset. The only variable changed was the context delivered through Atlan, and AI accuracy improved by 38%.
The isolation matters. It is direct evidence that context, on its own, was the variable.
FAQs about context engineering
Permalink to “FAQs about context engineering”What is the difference between context engineering and prompt engineering?
Permalink to “What is the difference between context engineering and prompt engineering?”Prompt engineering optimizes the wording of a single instruction to a model. Context engineering decides what information the model gets to see at all, including retrieved data, business definitions, lineage, memory, and tool outputs. Prompt engineering lives inside a prompt. Context engineering lives across the full pipeline that feeds the model.
What are the components of context engineering?
Permalink to “What are the components of context engineering?”The core components are system instructions, user input, retrieved knowledge, tool definitions and outputs, memory, conversation history, and governance signals such as access policies and quality tags. The July 2025 arXiv survey A Survey of Context Engineering for Large Language Models organizes these into a formal taxonomy across 1,411 reviewed papers.
Why is context engineering important for AI agents?
Permalink to “Why is context engineering important for AI agents?”Agents run for longer, call more tools, and carry more state than single-shot AI analysts. Anthropic’s research found that token usage alone explained 80% of the variance in agent performance, and that a multi-agent architecture lifted results 90.2% over a single-agent baseline. Without disciplined context management, agents lose coherence as the window fills with stale or irrelevant information.
How does context engineering differ from RAG?
Permalink to “How does context engineering differ from RAG?”Retrieval-augmented generation is one technique for assembling context. Context engineering is the broader discipline that decides what to retrieve, how to compact it, what governance to enforce, what tools to expose, and what to discard when the window fills up. RAG fits inside context engineering as one of several retrieval strategies.
Who coined the term context engineering?
Permalink to “Who coined the term context engineering?”Shopify CEO Tobi Lütke posted the term on X on June 19, 2025. Six days later, Andrej Karpathy reposted and endorsed it, describing the practice as “the delicate art and science of filling the context window with just the right information for the next step.” Karpathy’s post garnered over 2.3 million views and made the term a recognized discipline within weeks.
What does a context engineer do?
Permalink to “What does a context engineer do?”A context engineer designs the interfaces between enterprise knowledge and AI systems. The role typically combines data engineering, semantic modeling, and governance. Day to day, the work involves curating glossaries and ontologies, designing retrieval strategies, building context products, monitoring for context drift, and integrating context sources with AI tools through protocols like MCP.
How do I get started with context engineering?
Permalink to “How do I get started with context engineering?”Start with what you already have. Audit your business glossary, your lineage graph, your certifications, and your access policies. Identify the top three questions your AI analyst gets wrong, and trace each wrong answer back to the layer it belongs to in the five-layer framework. Fix those layers first. Then, expose the fixed context through an MCP server or API so multiple AI tools can reuse it.
Does a larger context window eliminate the need for context engineering?
Permalink to “Does a larger context window eliminate the need for context engineering?”Research from Chroma shows model accuracy degrades, often in non-uniform, surprising ways, as context grows, a failure mode Drew Breunig calls context rot. Even within supported window lengths, practitioners like Manus recommend using only a small fraction of the window (on the order of ~20%) to avoid drift.
Should agents be built as single-agent or multi-agent systems?
Permalink to “Should agents be built as single-agent or multi-agent systems?”Cognition, Manus, and Microsoft have all argued that splitting coding work across subagents often creates fragmented context and silent miscoordination. Anthropic reported that multi-agent systems outperform single agents by about 90% on parallel research tasks, though they use roughly 15x more tokens.
Who should own context engineering inside a company?
Permalink to “Who should own context engineering inside a company?”Gartner recommends CIOs appoint a context engineering lead or team, typically sitting between data engineering, ML engineering, and governance. EY already lists Context Engineer as a Manager-level consulting role requiring six years of software or data engineering experience. In practice, the role anchors metadata schemas and semantic models, while day-to-day context work is federated across data, AI, and governance teams.
Where does this leave enterprise data teams?
Permalink to “Where does this leave enterprise data teams?”Context engineering is not a new product category wearing fresh paint. It is the plain recognition that enterprise AI lives or dies on the information the model sees.
The 2025 data points converge from every direction. Gartner declared the shift. Anthropic published the playbook. The arXiv survey gave the field an academic spine. Chroma proved the underlying physics, LangChain named it the top-quality blocker within large enterprises, and MIT put a number on executive demand: 63% want AI tools that retain context.
Independent groups rarely land on the same conclusion within months of each other. This time they did. The encouraging part is that most of the foundation already exists. Catalogs, glossaries, lineage, and a decade of governance work turn out to matter for a use case no one planned.
What remains is to expose that infrastructure through interfaces that AI systems can use, and to treat context as a product worth versioning, testing, and shipping.
The teams that move first will not be the ones with the biggest models. They will be the ones whose AI agents reflect how the business actually works.
