


















Agents querying a stale model invent answers. With 40% of enterprise applications integrating task-specific AI agents by 2026, the gap between static documentation and operational reality has become the difference between a grounded agent and a hallucinating one.
Quick facts about active ontology
| Attribute | Detail |
|---|---|
| What it is | An ontology continuously synchronized with live data, lineage, and governance signals |
| Key benefit | Reduces AI agent hallucination and prevents ontology drift |
| Best suited for | Enterprises deploying AI agents on heterogeneous data stacks |
| Implementation time | 4 to 12 weeks for the first domain; incremental thereafter |
| Core components | Ontology graph, knowledge graph, governance graph, data graph, metadata lakehouse, MCP serving |
| Where it fits | Inside the context layer, between the catalog and the AI agent |
What is an active ontology?
Permalink to “What is an active ontology?”An ontology is a formal, machine-readable model of the concepts, relationships, properties, and constraints inside a domain. An active ontology adds a single but load-bearing modifier: the model stays bound to the live data estate it describes. When a column gets deprecated, a policy changes, or a downstream dashboard goes stale, the ontology learns about it. The document and the operational reality do not drift apart.

How a static knowledge model becomes a live, self-updating data contract. Image by Atlan.
The reason that the modifier matters in 2026 is simple. Static ontologies ship once and decay.
Alexander Shereshevsky, Co-founder of DataFab, wrote in a Medium article that, according to a Google Cloud survey, only 27% of organizations had knowledge graphs in production as of late 2025. The other 73% likely have something on paper that nobody trusts to run an agent on. Because agents running on static ontologies would fail due to stale operational reality.
According to the MIT NANDA Report, 95% of generative AI pilot programs are failing, and only 5% are achieving rapid revenue acceleration, as reported by Fortune. The numbers do point to a potential root cause that the agents lack an understanding of business meaning.
In the 2026 context, meaning has become infrastructure, and ontologies have moved from library-science conversations to a budget line item.
What an active ontology is not
There’s an older meaning of the term, which often confuses readers.
In 2010, Apple filed a US patent US20120016678A1, naming “active ontologies” as the execution environment used by an intelligent automated assistant, the work that became Siri. In that context, the active ontology is the runtime plumbing for a voice assistant. It dispatches services, parses intent, and routes a spoken request to the right component. Apple engineer Jerome R. Bellegarda described it in a 2013 paper as “a relational network of concepts… an execution environment” for the assistant.
This article is not about that meaning. The Siri-era definition is the historical anchor for the term. The 2026 enterprise-AI meaning shares the spirit, a living and executable model, but applies it to a different domain: the data and governance signals that AI agents reason against, rather than the language plumbing for a voice assistant. When this article uses “active ontology,” it refers to the enterprise-AI meaning.
How does an active ontology work?
Permalink to “How does an active ontology work?”The architecture rests on three ideas that work together: a graph-native substrate, four interconnected graphs that share signals, and an inference-time delivery channel for AI agents. It enables AI to connect and reason across data sets and systems to create a single source of truth for the enterprise.
The four-graph architecture
Permalink to “The four-graph architecture”The active ontology is not a single store. It sits within a co-located set of four graphs, each of which updates from the same metadata events.
- Data graph: assets, schemas, and lineage across every platform in the stack.
- Governance graph: ownership, policies, certifications, and quality signals.
- Knowledge graph: business terms, classifications, and the semantic relationships between them.
- Active ontology graph: formal classes, properties, constraints, and reasoning rules that update from operational signals.
Because the four graphs share a substrate, they evolve together instead of drifting into separate systems. A schema change in the data graph propagates a definitional event into the ontology graph. A policy update in the governance graph can adjust which assets a given concept is allowed to reference.
The ontology stays consistent with the catalog because both live in the same place.
The metadata lakehouse substrate
Permalink to “The metadata lakehouse substrate”Traditional catalogs are typically optimized for human discovery, not the kind of active, machine-speed co-evolution AI systems require. The four graphs need graph-native storage, open formats, and a substrate that can absorb high-volume metadata events without locking on every update. A metadata lakehouse, typically Iceberg-backed, gives the four graphs a shared home and lets them evolve from the same signals.
How AI agents query it at inference time
Permalink to “How AI agents query it at inference time”The last piece is delivery. An ontology that lives on disk does not help an agent in production. The agent needs to query the governed context at inference time, not pull a static OWL file at training time. The Model Context Protocol (MCP) is the open standard that lets agents fetch this context on demand. The active ontology graph is exposed through an MCP server, so when an agent needs to know what a “high-risk customer” means in this enterprise, it asks the substrate, not its weights.
The developer-side vocabulary now reflects the same shift. Andrej Karpathy popularized the term “context engineering” on X in June 2025, describing it as the art of filling the context window with the right information for each step of an agent’s work.
The active ontology is the data platform’s answer to the same question. The goal is to fill the context window with governed truth rather than best guesses.
Static vs. active ontology
Permalink to “Static vs. active ontology”A static ontology is a fixed model of business concepts and relationships, typically authored as an OWL or RDF file and reviewed on quarterly or annual cycles. An active ontology is the same model bound to live signals from the data estate, updating in response to lineage events, governance changes, schema updates, and usage patterns as they happen. The practical difference shows up in production: static ontologies are accurate on day one and drift from there, while active ontologies stay synchronized with operational reality.
The clearest way to see what “active” adds is to put the two side by side.
| Dimension | Static / passive ontology | Active ontology |
|---|---|---|
| Update cadence | Quarterly or annual reviews | Continuous, signal-driven |
| Source of truth | An OWL or RDF file in a repository | A graph store inside the metadata lakehouse |
| Connection to data | Manually mapped, often by hand | Bound via lineage and active metadata |
| Agent access | Pre-loaded at training time | Queried at inference via MCP |
| Drift detection | None; accurate on day one | Operational signals plus governance graph |
| Typical maintenance | Multi-FTE, ongoing curation | Embedded in catalog workflow |
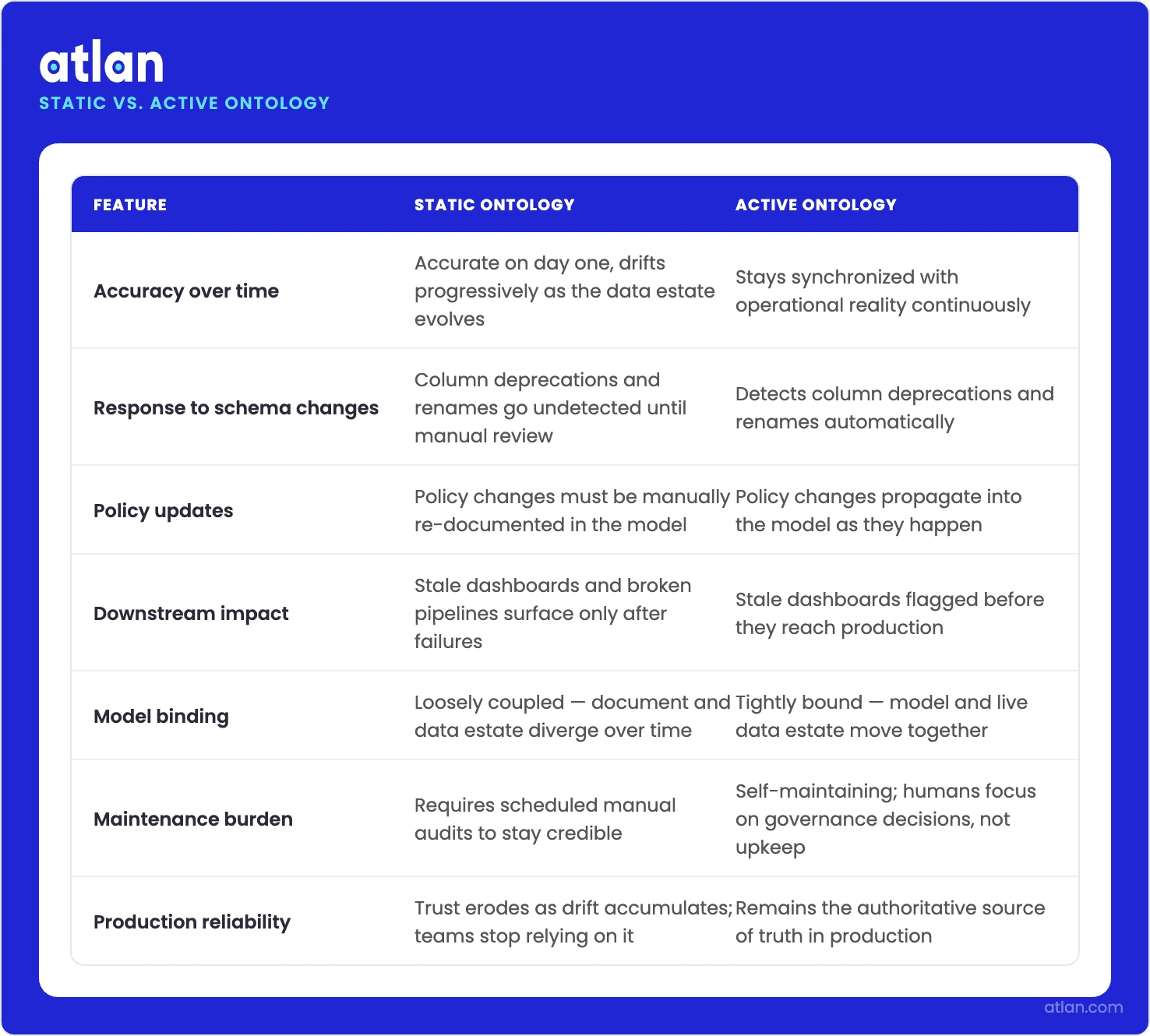
Static ontologies drift from reality. Active ontologies stay synchronized with your live data estate. Image by Atlan.
Related: How does Atlan's four-graph approach compare to Palantir Foundry?
Palantir Foundry is the most-cited commercial implementation of an active ontology, organized into three layers: Semantic, Kinetic, and Dynamic. The Atlan approach takes a different shape, using four co-located graphs inside a metadata lakehouse.
Why do enterprises need active ontologies in 2026?
Permalink to “Why do enterprises need active ontologies in 2026?”Three drivers are converging at once: agentic AI is moving from pilot to production, the cost of getting context wrong is rising, and regulators are asking for traceable answers. Each driver maps to a use case where active ontology earns its place.
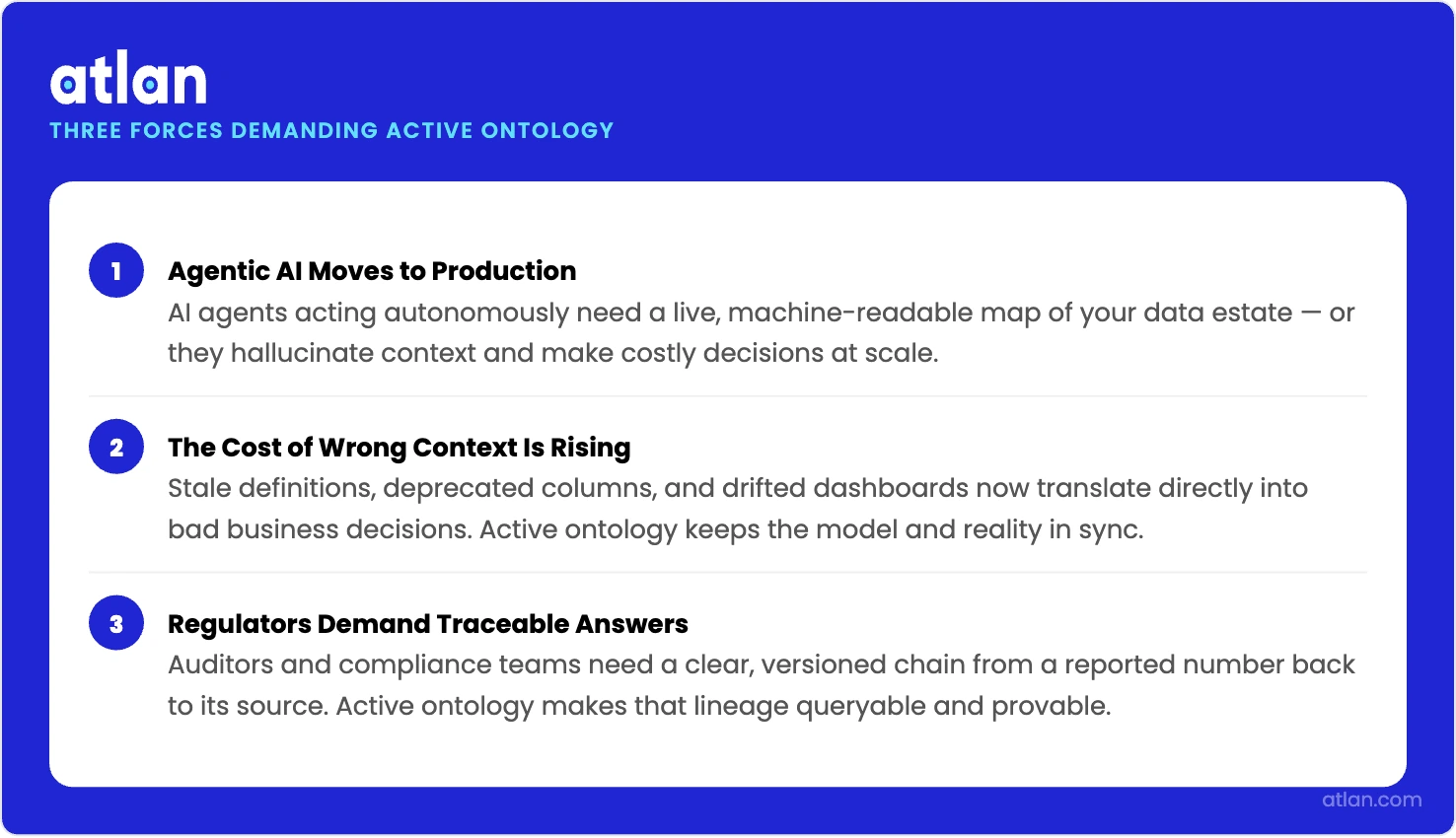
Agentic AI, rising context costs, and regulatory traceability converge around active ontology. Image by Atlan.
How does an active ontology reduce AI agent hallucination?
Permalink to “How does an active ontology reduce AI agent hallucination?”More than 80% of enterprises will have used generative AI APIs or deployed gen-AI applications in production by 2026, up from less than 5% in 2023. Agents fail where semantic understanding was supposed to live: they cannot tell whether a “customer” in the CRM is the same entity as a “customer” in the billing system, and they invent plausible-sounding answers when forced to guess.
An active ontology constrains what an agent can assert. The model defines canonical entities, the constraints rule out impossible joins, and the lineage tells the agent which physical table actually backs the concept it is reasoning about.
The forward-looking number from Gartner is consistent: by 2028, more than 50% of enterprise AI agent systems will incorporate context graphs, the superset that includes active ontology layers, for guardrailing, observability, evaluation, and self-learning.
How do you prevent ontology drift in a fast-moving business?
Permalink to “How do you prevent ontology drift in a fast-moving business?”An ontology shipped on day one is drifting by day 30. Schemas change, definitions evolve, regulations shift, and new domains get added. Without a feedback loop, the model rots quietly until an agent gives a wrong answer in a board meeting.
Active ontology closes the loop with named signal types: lineage events when an upstream column changes, usage drops when a once-popular asset goes quiet, governance changes when ownership shifts, schema events when a table is renamed, and deprecation events when an asset gets retired. Each signal can trigger a review, a re-binding, or an automated update.
According to Gartner’s Magic Quadrant for Data and Analytics Governance summary, companies that broadly leverage metadata analytics will deliver new data assets up to 70% faster by 2027. The mechanism is straightforward: when meaning stays current, teams stop rebuilding the same definitions every quarter.
How does an active ontology support governed reasoning in regulated industries?
Permalink to “How does an active ontology support governed reasoning in regulated industries?”Regulators want auditable answers. An LLM alone cannot deliver provenance because its reasoning is a statistical artifact, not a traceable chain. An active ontology gives agents a different kind of substrate: every answer can trace back through the ontology to a governed concept, and from that concept to a governed data asset, with the policy and the owner attached.
This matters because the failure mode is not abstract. Gartner has predicted that over 40% of agentic AI projects will be canceled by the end of 2027 due to escalating costs, unclear business value, and inadequate risk controls. Agents that cannot explain themselves get pulled before they reach production.
How to implement an active ontology
Permalink to “How to implement an active ontology”The shortest path is also the most disciplined: do not model from scratch, do not boil the ocean, and do not wait for a complete formal model. Bind what you already have to what you already use, then iterate.
Prerequisites
Permalink to “Prerequisites”Before starting, four conditions should already be true.
- A working data catalog with lineage already turned on across the priority domain.
- One named business domain to start with, such as revenue, customer, or claims.
- Stakeholder agreement on who owns each definition inside that domain.
- Active metadata signals from usage, governance, and quality already feeding the catalog.
Steps to follow
Permalink to “Steps to follow”Follow these implementation steps:
- Pick one domain: The goal is one operational ontology for a real use case, not a corporate taxonomy. Resist the urge to model everything.
- Bind glossary terms to live assets: Map each business concept to the tables, columns, and dashboards that actually implement it. This is what turns a glossary into an ontology in action.
- Add formal relationships and constraints. Define how the concepts relate: a Customer places an Order, an Order contains Line Items, and so on. Keep the formalism light at first.
- Wire in operational signals: Lineage events, ownership changes, deprecation flags, and usage drops feed the drift-detection loop.
- Expose via MCP to agents: Make the ontology queryable at inference time, not just human-browsable in a catalog UI.
- Iterate to the next domain: Once the first domain is producing grounded agent answers, the second is faster.
The methodological proof for steps two and three sits in Atlan’s own benchmark work: adding rich semantic metadata delivers a 38% relative improvement in AI-generated SQL accuracy, with a p-value less than 0.0001, based on Atlan’s internal study. The improvement is statistically significant, which is the kind of methodological rigor a stakeholder would look for before greenlighting an investment.
Three common pitfalls to avoid
Permalink to “Three common pitfalls to avoid”| Pitfall | Why it happens | How to avoid it |
|---|---|---|
| Treating it as an OWL modeling project | Teams chase formal completeness before the first agent ships | Bind to live assets from day one; layer formalism in later |
| Letting the ontology fork from the catalog | Separate teams own each, and the two drift apart | Co-locate the ontology graph inside the same metadata lakehouse as the catalog |
| Building for completeness instead of for the first agent | Scope creep replaces a shippable use case with a multi-year program | Pick one real agent use case and ship it |
How to evaluate active ontology platforms
Permalink to “How to evaluate active ontology platforms”The vendor field is crowded, and the distinction between static-with-good-PR and genuinely active isn’t seemingly obvious. Five criteria separate them.
| Criterion | Why it matters | What to look for |
|---|---|---|
| Graph-native storage | Static OWL files cannot update from operational signals | A graph store inside a metadata lakehouse, ideally Iceberg-backed |
| Live binding to assets | Definitions decay without it | Lineage-backed mapping from glossary terms to tables, columns, and BI assets |
| Drift detection | An ontology is most accurate on day one and then declines | Operational signals feeding a governance graph, with explicit drift dashboards |
| MCP-served context | Agents need inference-time access, not a training-time pre-load | A first-class MCP server, not just a REST API |
| Governance integration | Reasoning must be auditable | Governance graph co-located with the ontology graph |
Ask these five questions to evaluate vendors:
- Where does the ontology physically live, and is it in the same store as your lineage?
- How do you detect drift between the ontology and live operational reality?
- How do AI agents access it: pre-load, RAG, or MCP at inference time?
- How do you handle entity-resolution conflicts, such as customer vs. client vs. account?
- What is the ongoing maintenance overhead in FTEs, cadence, and automation level?
How Atlan approaches active ontology
Permalink to “How Atlan approaches active ontology”Most enterprise ontology projects ship a polished OWL file that is already drifting by the time it hits production. Buyers do not lack frameworks. They lack a substrate that keeps the ontology bound to live operations.
Atlan’s active ontology graph lives inside the metadata lakehouse alongside three other graphs: the data graph for assets and lineage, the governance graph for ownership and policy, and the knowledge graph for terms and relationships. Each graph updates from the same active metadata signals, which helps keep the ontology aligned with operational reality. The MCP server exposes the ontology graph to AI agents at inference time. Agents reason against governed concepts rather than statistical guesses. The business glossary acts as the human-readable surface, while the active ontology graph is the machine-readable substrate underneath.
The customer evidence sits in the outcomes. Joe DosSantos, Vice President, Enterprise Data and Analytics, described the gap. They built an agent for recurring revenue, their most critical metric, but it couldn’t answer a single finance-related question. They realized they were missing a translation layer. Closing that gap in Atlan AI Labs’ controlled enterprise experiments delivered up to a 5x improvement in AI analyst accuracy over baseline. The Atlan and Snowflake Intelligence partnership reports a 3x improvement in conversational analytics accuracy using the same context-layer pattern, with a documented p-value below 2e-10.
The scale evidence is from CME Group’s first year on Atlan, when the team cataloged 18 million data assets and more than 1,300 glossary terms. That is the substrate on which an active ontology runs.
FAQs about active ontology
Permalink to “FAQs about active ontology”What makes an ontology “active” rather than static?
Permalink to “What makes an ontology “active” rather than static?”The modifier “active” means the model stays bound to live signals from the data estate it describes, rather than living as a fixed file reviewed on a quarterly or annual cycle. An active ontology updates from lineage events, governance changes, schema updates, and usage patterns as they happen, so the definitions inside it match what the data actually looks like in production today.
How is “active ontology” different from Apple’s Siri active ontology?
Permalink to “How is “active ontology” different from Apple’s Siri active ontology?”Apple’s 2010 patent introduced active ontology as the execution environment for an intelligent assistant, the components that carry out tasks for Siri. The 2026 enterprise meaning shares the spirit of a living, executable model but applies it to a different domain: the business concepts and governance signals that AI agents reason against. One is voice-assistant plumbing. The other is enterprise data context.
How does an active ontology reduce AI hallucination?
Permalink to “How does an active ontology reduce AI hallucination?”By constraining what an agent can assert. Instead of letting an LLM pattern-match definitions from training data, an active ontology forces canonical entity resolution, governed definitions, and explicit relationships.
What is ontology drift, and how do you prevent it?
Permalink to “What is ontology drift, and how do you prevent it?”Ontology drift is the growing gap between an ontology’s definitions and how the business actually operates. Schema changes, new domains, and policy updates cause the divergence. Prevention needs feedback loops from operational signals and co-location inside a metadata lakehouse, so the ontology cannot fork from the rest of the stack.
How is an active ontology different from a semantic layer?
Permalink to “How is an active ontology different from a semantic layer?”A semantic layer standardizes measurement: what revenue means in your BI tools. An active ontology standardizes meaning: what a customer is and how that customer relates to other concepts. Semantic layers serve dashboards. Active ontologies serve agents.
Do you need to learn OWL or RDF to build an active ontology?
Permalink to “Do you need to learn OWL or RDF to build an active ontology?”Not to start. Pragmatic 2026 implementations begin by binding existing business glossary terms to actual data assets via lineage. Formal OWL or RDF constraints can be layered in later for domains that need decidable inference, such as regulated audit settings. Starting with operational binding beats waiting for a complete formal model.
When is an active ontology worth the investment?
Permalink to “When is an active ontology worth the investment?”When AI agents are part of the roadmap, the answers need to be defensible. If teams are still in dashboards-only mode without agentic use cases, a well-maintained semantic layer may be enough. Once agents start producing decisions that touch revenue, risk, or regulated workflows, an active ontology shifts from a nice-to-have into core infrastructure.
The architecture choice that decides whether your agents ship
Permalink to “The architecture choice that decides whether your agents ship”Active ontology is not a new species of ontology. It is the version that survives contact with production. The 2026 default expectation is that an ontology is graph-native, bound to live metadata, drift-detected, and queryable by agents at inference time. Teams that pick the modifier seriously will ship governed AI.
Teams that ship static OWL files might spend the next two years explaining hallucinations. For Atlan, the architecture choice is a metadata lakehouse with four co-evolving graphs and MCP-served context.
With agentic adoption climbing fast and project cancellations climbing alongside it, the difference between an ontology that survives and one that decays is now a strategic decision, not a technical one.
