


















The world's first context store
engineered natively for AI.
The Context Lakehouse is the only knowledge architecture built for a world where AI
is both the primary producer and consumer of context.
Intelligence
Metadata
Store
Ready
Foundation
Trusted by AI-forward enterprises

"AI initiatives require more context than ever. Atlan's metadata lakehouse is configurable, intuitive, and able to scale to hundreds of millions of assets."
Andrew Reiskind
Chief Data Officer, Mastercard



"AI initiatives require more context than ever. Atlan's metadata lakehouse is configurable, intuitive, and able to scale to hundreds of millions of assets."
Andrew Reiskind
Chief Data Officer, Mastercard
Analytics needed data infrastructure.
AI needs context infrastructure.
The data world built lakes, warehouses, and pipelines to tame data at scale. AI demands the same architectural investment — but for context.
Context at machine speed
Data needed fast pipelines. AI needs fast context. Agents query definitions, policies, and relationships thousands of times per hour — infrastructure built for human-speed access compounds into minutes of latency per run.
Context is big data
Data grew until you needed a data lake. Context is growing the same way. Every agent interaction creates observations, quality signals, usage patterns. Infrastructure that only reads collapses when agents write back at scale.
Context is relational
Data needed schemas. AI needs graphs. Agents traverse lineage chains, cross domain boundaries, and check governance policies in a single call. A flat index can't support that. You need a traversable map of the entire estate.
Context needs versioning
Data needed lineage. Context needs time travel. When an agent makes a mistake, you need to reconstruct exactly what context it saw and when. Without it, you can observe the output but never explain the reasoning.
One open store. Every protocol
AI agents speak. Built natively for AI.
Built for agents that read context, write it back, and traverse it at scale.
A knowledge graph for relationships and meaning. Iceberg-native file storage for scale and portability. Together, they give AI agents the richest possible context in the most open possible format.
Speaks every protocol AI agents use and every protocol humans already know.
Every interface an agent needs, and every interface a human already uses. From MCP for governed queries to SQL for analytics — Context Lakehouse meets your stack where it is.
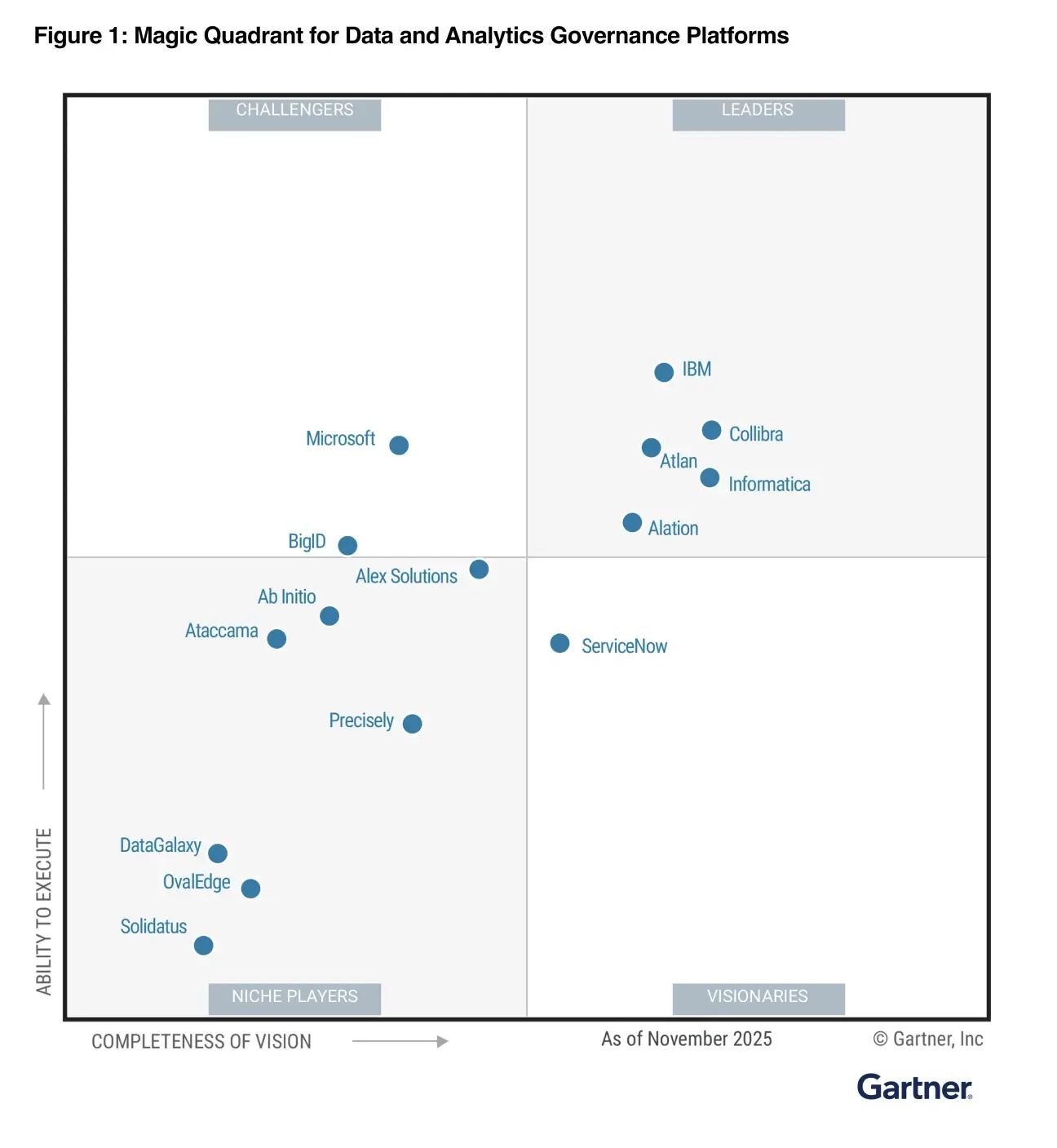
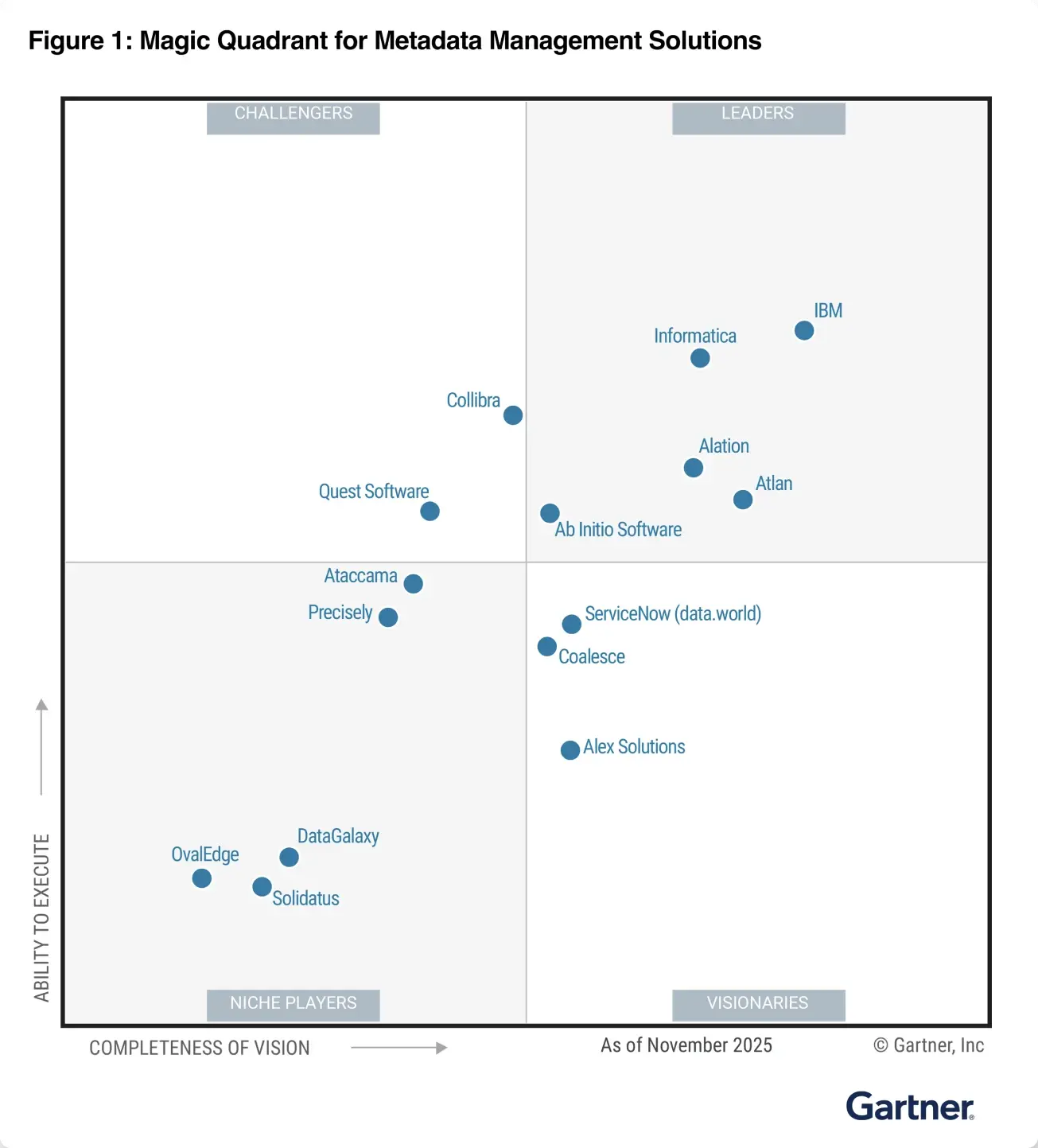
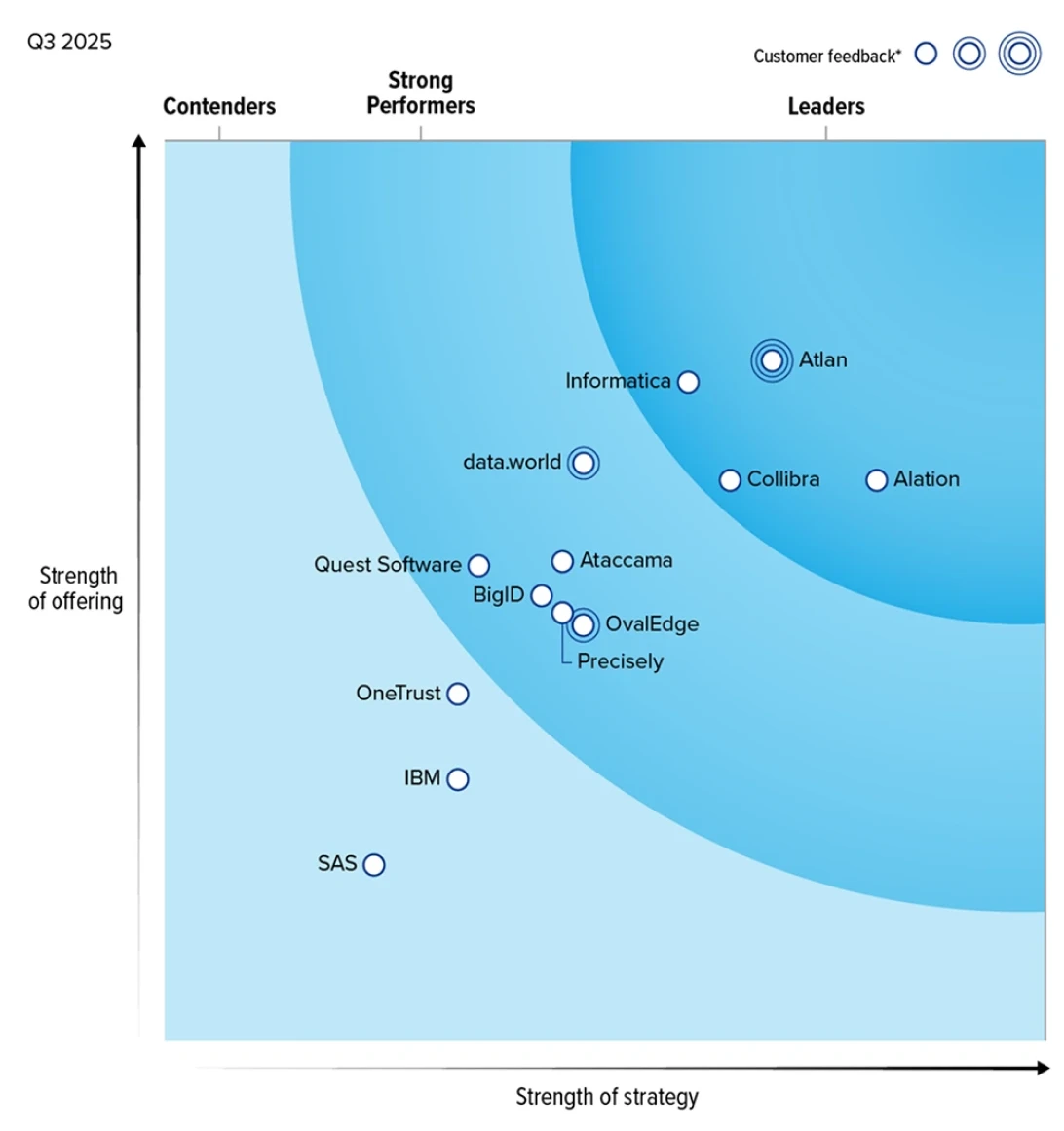
The only context infrastructure
validated by Gartner and Forrester
Learn more about context infrastructure with Atlan.

The enterprise context layer — 53+ resources
The complete resource hub on the context layer: what it is, why AI agents need it, how to implement it, and why teams that have it are 5x more likely to reach production.

Context graphs: $1T opportunity. Four positions. Zero consensus.
Bob Muglia, Karthik Ravindran (Microsoft), Tony Gentilcore (Glean), and Prukalpa Sankar debate who should own the context graph. Four distinct architectures, no agreement — the most consequential infrastructure decision of 2026.

84% invest in AI. 17% reach production. Here's the gap.
550+ data leaders on what separates the teams that scale from the ones that stall. The 7 structural shifts forcing data teams to rebuild for an AI-first world — and what context infrastructure has to do with it.

Mastercard CDO on context by design
Andrew Reiskind, Chief Data Officer at Mastercard, on why AI initiatives require more context than ever — and how Atlan's architecture scales to hundreds of millions of assets.

Metadata lakehouse vs. data catalog — what's the difference?
A catalog stores metadata for humans to browse. A metadata lakehouse is active infrastructure — Iceberg-native, bidirectional, traversable at machine speed. Here's exactly where the line is.
The enterprise context layer — 53+ resources
The complete resource hub on the context layer: what it is, why AI agents need it, how to implement it, and why teams that have it are 5x more likely to reach production.
Context graphs: $1T opportunity. Four positions. Zero consensus.
Bob Muglia, Karthik Ravindran (Microsoft), Tony Gentilcore (Glean), and Prukalpa Sankar debate who should own the context graph. Four distinct architectures, no agreement — the most consequential infrastructure decision of 2026.
84% invest in AI. 17% reach production. Here's the gap.
550+ data leaders on what separates the teams that scale from the ones that stall. The 7 structural shifts forcing data teams to rebuild for an AI-first world — and what context infrastructure has to do with it.
Mastercard CDO on context by design
Andrew Reiskind, Chief Data Officer at Mastercard, on why AI initiatives require more context than ever — and how Atlan's architecture scales to hundreds of millions of assets.
Metadata lakehouse vs. data catalog — what's the difference?
A catalog stores metadata for humans to browse. A metadata lakehouse is active infrastructure — Iceberg-native, bidirectional, traversable at machine speed. Here's exactly where the line is.
Everything you need to know about
Context Lakehouse
The Context Lakehouse is Atlan's knowledge architecture for storing, managing, and serving the context AI agents need to operate accurately at enterprise scale. It combines a knowledge graph for relationships and meaning, Iceberg-native file storage for portability and ACID guarantees, vector-native search for semantic retrieval, and full time-travel for compliance and audit. It is the store that every Atlan product reads from and writes to — and that any external agent can access via MCP, A2A, SQL, or API.
A data catalog stores metadata for humans to browse. The Context Lakehouse is an active knowledge architecture designed for machine-speed access. The differences are structural: Iceberg-native storage means context is queryable with standard SQL from any engine. The knowledge graph means relationships are traversable at depth in under 100ms. Bidirectional writes mean agents improve context on every interaction. And vector-native search means retrieval is by meaning, not search bar. A catalog is a directory. A Context Lakehouse is infrastructure.
Iceberg-native means the Context Lakehouse stores all metadata in Apache Iceberg table format — the same open standard your best data already lives in. This gives you ACID transaction guarantees, schema evolution without breaking consumers, time travel for any historical state, and compatibility with every SQL engine your team already runs (Spark, Trino, DuckDB, Snowflake, BigQuery, Flink). It also means your context is stored in open formats you own and can query independently of Atlan. Your context is your IP — Iceberg-native ensures you can always access it.
Context Lakehouse supports four protocols natively: MCP (Model Context Protocol) for governed, trust-checked context delivery to any AI agent; A2A (Agent-to-Agent) for bidirectional writes where agents post quality signals and observations back; SQL via Apache Iceberg for programmatic access from any compatible engine; and REST and Graph APIs with SDKs in Python, Java, Node.js, and Go for custom integrations. Every AI agent your team builds or buys can access context through the interface it already speaks.
Because Context Lakehouse is built on Apache Iceberg, every version of every asset state is automatically preserved and queryable. For GDPR: you can prove exactly what data classification applied to an asset on any past date, and demonstrate that deletion policies were enforced. For CCPA: access and deletion audit trails are built into the storage layer. For SOX: every change to any financial data asset — who changed it, when, and what the previous state was — is queryable as a table. Compliance is a query, not a manual process.
Yes. Context Lakehouse is designed around open formats and bring-your-own-compute (BYOC) principles. Because context is stored in Apache Iceberg, it can live in your own cloud storage (S3, GCS, ADLS) and be queried by your own compute engines. You are not locked into Atlan's infrastructure. Your context files are portable, owned by you, and readable by any Iceberg-compatible tool — today and in the future.
Build AI on infrastructure
that's built for AI.
