



















The business graph is the semantic spine an AI agent uses to interpret an ambiguous question — Revenue ≠ Bookings ≠ ARR. Context graphs are how that spine becomes durable enterprise memory instead of something an agent forgets between sessions. A VP of Data at a large financial services firm described the moment her team knew they had a structural problem: they had upgraded to a more capable model, but the agent’s outputs got worse, more polished and more confident yet more wrong in ways that took two weeks to catch.
The previous model had been obviously unreliable; this new one was unreliably convincing. Her team had spent the prior quarter on prompt engineering and better retrieval. None of it had helped, because neither addressed what the agent was actually missing: a governed, shared understanding of what “closed won,” “EMEA,” and “net revenue” mean at her company, built by her company, verified by the people who actually run the numbers.
This is the difference between session memory and enterprise knowledge. Session memory is what your agent carries between conversations. Enterprise knowledge is what your business means by “revenue,” “EMEA,” and “closed won” — permanently, across every agent, regardless of which model runs them. The industry is solving hard for the first. Almost nobody is building the second.
The session memory trap
Permalink to “The session memory trap”Most of the energy in the agent space right now is focused on session memory: why agents forget things between conversations, how to give them better in-context recall, how to persist key facts across threads. Augment Code’s widely-shared piece on why AI agents keep asking the same questions when their context window resets indicates clear interest in the topic.
But while the framing is accurate and the ceiling it describes is real, this angle is looking at the wrong problem.
Session memory addresses the gap between what an agent learned in conversation one and what it carries into conversation two. That’s a session problem. Underneath it sits a different problem: the gap between what an agent knows about your business’s operations and what it would actually need to know to reason correctly about them. That’s an enterprise problem.
A bigger context window doesn’t solve that. Neither does better RAG. You can’t retrieve context that was never encoded. The question isn’t “where did the agent forget?” — it’s “what was never told to the agent in the first place?”
The five context layers agents are missing
Permalink to “The five context layers agents are missing”Here’s a framework that makes the gap concrete. A data agent operating in an enterprise environment needs five types of context to reason correctly:
User context — who is asking, and what decision are they making? The answer shapes everything: which metric is relevant, which data source to trust, which edge case applies.
Knowledge context — how does this business work? The SOPs, the rules, the exceptions. That EMEA includes Brazil for sales but excludes it for regulatory reporting isn’t in any table. It lives in the heads of the people who built the process.
Meaning context — what does “revenue” mean here? “Closed won”? “Active customer”? In almost every enterprise we encounter, these terms have different definitions across systems, teams, and quarters. The agent doesn’t resolve that ambiguity by asking. It picks one definition and proceeds.
Data context — which tables, how calculated, raw versus aggregated, what lineage exists? The technical layer that determines whether a query returns the right number or an internally-consistent-but-wrong number.
Operational context — what is the current state of the business, and which conditions apply right now? This is the only layer that changes continuously, meaning it’s the one most likely to be stale when an agent needs it. It ensures agents’ answers are situationally correct, not just semantically correct.
Miss any one of these and the agent fails, but not because of a session memory problem. It’s because the context was never built. This is why Gartner analyst Andrés García-Rodeja predicts that the absence of a consistent context layer will cause 60% of agentic analytics projects to fail by 2028.
Why better models make this worse
Permalink to “Why better models make this worse”Many companies haven’t gotten to this point yet, but they will: upgrading your model amplifies a context gap instead of fixing it.
When a weak model gets the context wrong, the answer is obviously wrong. Stakeholders notice, incidents are filed, and the problem quickly surfaces.
When a strong model gets the context wrong, the answer sounds right. It’s internally consistent and passes basic human review. But by the time the damage surfaces — via misdirected outreach built on last quarter’s customer tier definition, a capacity plan that used the wrong revenue metric, or something else — hundreds of agent decisions have already compounded the error.
McKinsey research shows 60% of enterprise AI budgets go to data preparation, not model training. The hard constraint is the context the model is reasoning from. Smarter models with wrong context produce more convincingly wrong answers. That’s not a reason to slow down on model upgrades, but rather to treat context infrastructure as the prerequisite.
Compounding context is the structural moat
Permalink to “Compounding context is the structural moat”Session memory approaches share one characteristic: they start from zero. The agent reloads from scratch for every conversation, so the tenth conversation is no smarter than the first.
On the other hand, enterprise context graphs compound. Every agent interaction that surfaces a definition gap, a wrong metric, or a context collision is a signal that enriches the shared context layer, but only if the infrastructure exists to capture it. Every correction a data steward makes to a business definition propagates immediately to every agent drawing from it. Every certified metric added to the knowledge graph makes every agent in the enterprise smarter, not just the one that prompted the addition.
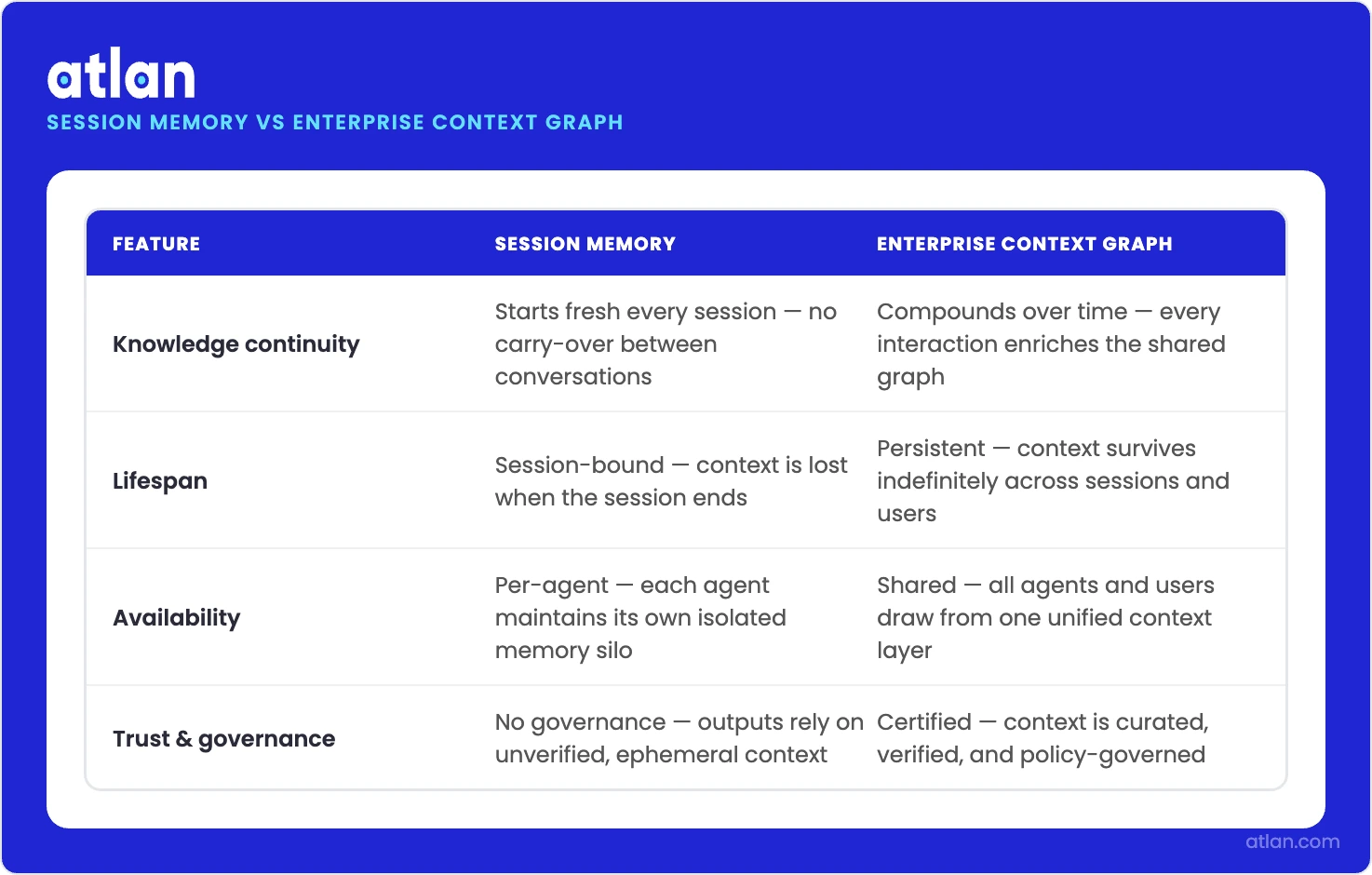
How session memory and enterprise context graphs differ across four key dimensions. Source: Atlan
The flywheel: production usage → agent feedback → context enrichment → better agent reasoning → more production usage. Customers deploying agents on top of Atlan’s context layer report faster agent onboarding as they expand to new use cases because the context layer increases accuracy and reliability over time.
The moat is in the context you’ve built, not the model itself. Unlike model quality, which converges across vendors over time, context is your IP that nobody else can claim.
The hidden cost of hardcoding business logic into agents
Permalink to “The hidden cost of hardcoding business logic into agents”We’ve heard teams say: “We’ve baked our context into tool descriptions. Our agents have enough context to work.”
For narrow, stable use cases, encoding business rules in MCP tool descriptions works. The problem is scale and change. An enterprise with hundreds of data sources and thousands of metrics can’t maintain a semantic layer inside tool descriptions. When a metric changes, which they do constantly, you’re hunting through every tool description that references it. When an agent makes a decision nobody can explain, there’s no audit trail in a tool description.
Let’s say you’re updating your customer_tier definition from seat-based to ACV-based. That change propagates undetected through agent decisions for months before it surfaces in a misrouted expansion play. No error codes or failed assertions were flagged because the answers sounded right.
Tool descriptions scale to tens of use cases. Context graphs scale to hundreds of agents, thousands of definitions, and the governance layer that makes them trustworthy under audit. The more durable option isn’t a question.
Three moves to start building the context layer
Permalink to “Three moves to start building the context layer”Audit your semantic sources of truth. Map where business definitions actually live — in which catalogs, dbt models, tool descriptions, and documentation wikis. Then identify which sources your agents are drawing from. Most organizations discover agents are drawing from multiple conflicting sources with no reconciliation layer between them. Fixing it starts with seeing it.
Instrument for staleness, not just correctness. Every definition in your context layer should carry a last_verified timestamp and a verified_by attribution. A definition that hasn’t been actively certified within your change cycle shouldn’t reach production agents. Passive validity is the assumption that context failure exploits.
Close the human gap. AI gets organizations to roughly 80% of context coverage automatically, via lineage, usage signals, and quality scores that propagate from your existing stack. The last 20% is knowledge only humans hold: that EMEA includes Brazil for sales but not for finance, that closed-lost in 14 days doesn’t count for pipeline reporting, that rev_adj_q4_final_v2 is the board deck source of record. Build the certification workflow that captures it before the agent that needs it ships.
What’s at stake
Permalink to “What’s at stake”That VP of Data didn’t have a model problem. No amount of prompt engineering was going to surface a definition that had never been written down. That’s a knowledge problem. The upgrade exposed it, but didn’t cause it. Her team is now building what the model actually needed from the start: a governed, shared context layer that definitively tells every agent, across every conversation, what “closed won” means at her company.
That’s the failure mode scaling fast across every enterprise deploying agents in 2026. Your agents will be as reliable as the context you give them. Most enterprise agents right now are operating with incomplete user context, undocumented knowledge context, ambiguous meaning context, and inconsistently applied data context. They’re failing because the enterprise hasn’t built the layer the models need.
The organizations building that layer now compound an advantage every quarter, through every agent interaction, definition enriched, and certification added. The organizations treating context as a follow-up project will find themselves at year-end with better models and the same wrong answers.
The question is whether you’re building the context layer now, before wrong answers sink trust in AI agents entirely and the gap becomes too large to close.
