



















Build Your AI Context Stack
Get the blueprint for implementing context graphs across your enterprise. This guide walks through the four-layer architecture—from metadata foundation to agent orchestration—with practical implementation steps for 2026.
Get the Stack GuideWhy do AI agents need a context graph?
Permalink to “Why do AI agents need a context graph?”AI agents are moving into production, and most failures trace back to context, not capability. The model is not the bottleneck. What breaks is the agent’s ability to ground decisions in the facts that define how an enterprise actually works.
Enterprise AI agents have a context problem. Raw data tells an agent what a number is, not what it means or whether it can be trusted. Databases have schemas but no business semantics. Policies live in documents rather than in a queryable structure. Decisions made in the past are invisible to the next agent that faces the same situation. An agent operating in this environment can only guess, and guesses at machine speed compound into confident, wrong outcomes.
The context graph is the solution to that problem. It gives an agent a structured, queryable view of the enterprise that captures entities, relationships, policies, time, and decision history in one place so the agent can read what it needs, check what it is allowed to do, and write back what it learned.
What is an agent context graph? 4 key components
Permalink to “What is an agent context graph? 4 key components”The simplest definition of an agent context graph is an equation:
Context graph = Knowledge graph + temporal validity + policy nodes + agent write-back
Think of an agent context graph as GPS with history: they show the route taken, the conditions at decision time, and why one path was chosen over another.
Each component does specific work for the agent:
1. Knowledge graph: The entity and relationship backbone
Permalink to “1. Knowledge graph: The entity and relationship backbone”The knowledge graph is the foundation. It models the business as a connected graph of entities (customers, products, datasets, systems, people) and typed relationships (feeds, owns, depends on, governs). This is what lets an agent ask “what is this thing and how does it connect to everything else?” and get a structured, traversable answer — the defining capability of native graph databases over traditional relational stores.
2. Temporal validity: Time-bounded context
Permalink to “2. Temporal validity: Time-bounded context”A knowledge graph is typically a snapshot. An agent context graph is time-aware. Temporal validity records when a definition, relationship, or policy was true, so an agent can reason about the present (“is this metric still certified?”) and the past (“what did the compliance rule say on the date of the audit?”). Without this, agents answer questions from a fixed snapshot and cannot detect that the world has changed.
3. Policy nodes: Compliance rules as traversable graph elements
Permalink to “3. Policy nodes: Compliance rules as traversable graph elements”In most architectures, compliance rules are applied after context is retrieved, through system prompts or wrapper functions. In an agent context graph, policies are first-class nodes. An agent can traverse to a policy node in the same query that fetches an asset, so access control, compliance rules, and retention policies are checked at retrieval time rather than bolted on afterward. This makes policy context queryable at traversal time rather than a separate enforcement layer, and is the foundation for trustworthy, auditable agent behavior.
4. Agent write-back: Decisions as compounding context
Permalink to “4. Agent write-back: Decisions as compounding context”Most context graphs are read-only for agents. An agent context graph is bidirectional. After an agent acts, its observation, correction, or approved decision can be written back into the graph under governance. This turns each agent interaction into a contribution to shared organizational memory. The next agent that faces the same situation has more context than the last one did.
For Data Leaders Evaluating Where to Start
Atlan's CIO guide to context graphs walks through a practical four-layer architecture from metadata foundation to agent orchestration.
Get the CIO GuideWhat does an agent context graph look like in practice?
Permalink to “What does an agent context graph look like in practice?”An agent context graph is a living substrate that the entire agent fleet draws from and writes back to. Its structure is the enterprise modeled as a graph, covering:
- Asset nodes: Databases, tables, dashboards, models, APIs, pipelines, documents.
- Business concept nodes: Glossary terms, metrics, dimensions, domains, and their approved definitions.
- People and role nodes: Owners, stewards, approvers, and teams, linked to the assets they are accountable for.
- Policy nodes: Access rules, compliance requirements, retention schedules, and certification criteria, each linked to the assets they govern.
- Event nodes: Data quality checks, lineage runs, audit events, and agent decisions, each with a timestamp so the graph records what happened and when.
The relationships between these nodes are what give the graph its explanatory power. An agent traversing from a dashboard to its underlying tables, through their certified glossary terms, across to the owners and their applicable policies, receives everything it needs to reason and act in one connected structure.
At Atlan, we think of the context graph as the enterprise memory for AI, the place where everything an agent needs to know about the business is stored, organized, and kept current.
What are the enterprise use cases for agent context graphs?
Permalink to “What are the enterprise use cases for agent context graphs?”The value of an agent context graph shows up most clearly in the enterprise workflows where context failures are costly.
Financial reporting and reconciliation
Permalink to “Financial reporting and reconciliation”Quarterly closes and regulatory reports require an agent to resolve which revenue definition applies to which business unit, trace that metric back through the lineage to its certified source tables, verify that each source passes quality checks, and produce an auditable record of those checks. A context graph exposes all of that in traversable form. Without it, agents guess at definitions and produce outputs no finance team can certify.
Regulatory compliance and audit response
Permalink to “Regulatory compliance and audit response”When a regulator asks “show me the lineage and policy history for this dataset,” the answer requires time-bounded traversal, showing what was true on a specific date rather than what is true now. Temporal validity nodes make that possible. Agents can reconstruct the state of the context graph at a past date and produce a verifiable audit trail.
Data product deployment
Permalink to “Data product deployment”Before an agent publishes a data product, it needs to check certification, ownership, quality scores, and downstream impact simultaneously. A context graph delivers all of those signals in one traversal. Without it, an agent checks each signal independently and misses the relationships between them.
Cross-system entity resolution
Permalink to “Cross-system entity resolution”The same customer, product, or account often appears under different identifiers in CRM, ERP, and the data warehouse. A context graph reconciles these into canonical nodes an agent can traverse, so it is not puzzled by conflicting representations and does not need to infer which record to trust.
Knowledge and precedent discovery
Permalink to “Knowledge and precedent discovery”After an agent resolves an exception or approves a classification, the decision can be written back as an event node linked to the entities and policies involved. Future agents can traverse those decision nodes to find precedent, so similar cases are handled consistently rather than decided from scratch each time.
How do you implement an agent context graph?
Permalink to “How do you implement an agent context graph?”Implementation follows a sequence: foundation first, then policy nodes, then agent access, then write-back.
Phase 1: Build the entity and relationship foundation: Connect your data estate (warehouses, BI tools, pipelines, docs) to create the asset and lineage backbone. This is usually where existing metadata management or data catalog infrastructure is extended rather than replaced.
Phase 2: Populate business concepts and policy nodes: Attach glossary terms, metric definitions, and domain-scoped business concepts as nodes. Add policy nodes linked to the assets they govern. This is where a business glossary and an ontology become queryable graph elements rather than documents.
Phase 3: Add temporal validity: Ensure that every node and relationship carries a validity window, so the graph can be queried as of a past date and can detect when context has changed.
Phase 4: Expose to agents through standard interfaces: Connect the context graph to agent runtimes via the MCP (open standard), APIs, and SQL so agents can call traversal tools at inference time. Policy checks should run inside the traversal, not as a separate post-retrieval step.
Phase 5: Enable governed write-back: Define which agent-generated information can be written back, under which approval rules, and with which audit trail. Start conservatively, then expand as the governance model matures.
Atlan supports all five phases through its Enterprise Data Graph, business glossary, Context Engineering Studio, MCP server, and Context Agents. Teams typically start with phases 1 and 2 in weeks rather than months by bootstrapping context from existing metadata, SQL history, and dashboards.
Inside Atlan AI Labs & The 5x Accuracy Factor
Learn how context engineering drove 5x AI accuracy in real customer systems. Explore real experiments, quantifiable results, and a repeatable playbook for closing the gap between AI demos and production-ready systems.
Download E-bookReal stories from real customers building enterprise context layers
Permalink to “Real stories from real customers building enterprise context layers”How Workday is building an AI-ready semantic layer
Permalink to “How Workday is building an AI-ready semantic layer”"Atlan captures Workday's shared language to be leveraged by AI via its MCP server. As part of Atlan's AI labs, we're co-building the semantic layer that AI needs."
- Joe DosSantos, VP Enterprise Data & Analytics, Workday
How DigiKey built a unified, sovereign context layer for its data and AI estate
Permalink to “How DigiKey built a unified, sovereign context layer for its data and AI estate”"Atlan is our context operating system to cover every type of context in every system including our operational systems. For the first time we have a single source of truth for context."
- Sridher Arumugham, Chief Data Analytics Officer, DigiKey
Moving forward with agent context graphs
Permalink to “Moving forward with agent context graphs”The shift from knowledge graph to agent context graph is practical and incremental. Most enterprises already have the entity backbone in a catalog or metadata store. The work is adding temporal context, governance as graph nodes, and a write-back channel.
The payoff is an agent fleet that gets more accurate over time rather than starting from scratch on every new deployment. Each decision, correction, and observation written back into the shared graph makes the next agent’s reasoning better. That compounding effect is what separates organizations that scale agentic AI from those that keep running isolated pilots.
Build the foundation on what you already have. Expose it through open standards. Let context compound.
FAQs about agent context graphs
Permalink to “FAQs about agent context graphs”1. What is a context graph in AI?
Permalink to “1. What is a context graph in AI?”In AI, a context graph is a structured representation of an enterprise that captures entities, relationships, policies, lineage, temporal context, and decision traces in a form agents can query at inference time. It extends a knowledge graph by adding the operational and governance metadata that production agents need to act safely, including when definitions were valid, which policies apply, and what decisions have been made before.
2. What is the context graph equation?
Permalink to “2. What is the context graph equation?”The equation is: Context graph = Knowledge graph + temporal validity + policy nodes + agent write-back. A knowledge graph gives you the entity and relationship backbone. Temporal validity gives agents the ability to reason about time. Policy nodes make policy context queryable rather than a separate layer. Agent write-back lets decisions and observations flow back into the shared graph, so context compounds with each interaction.
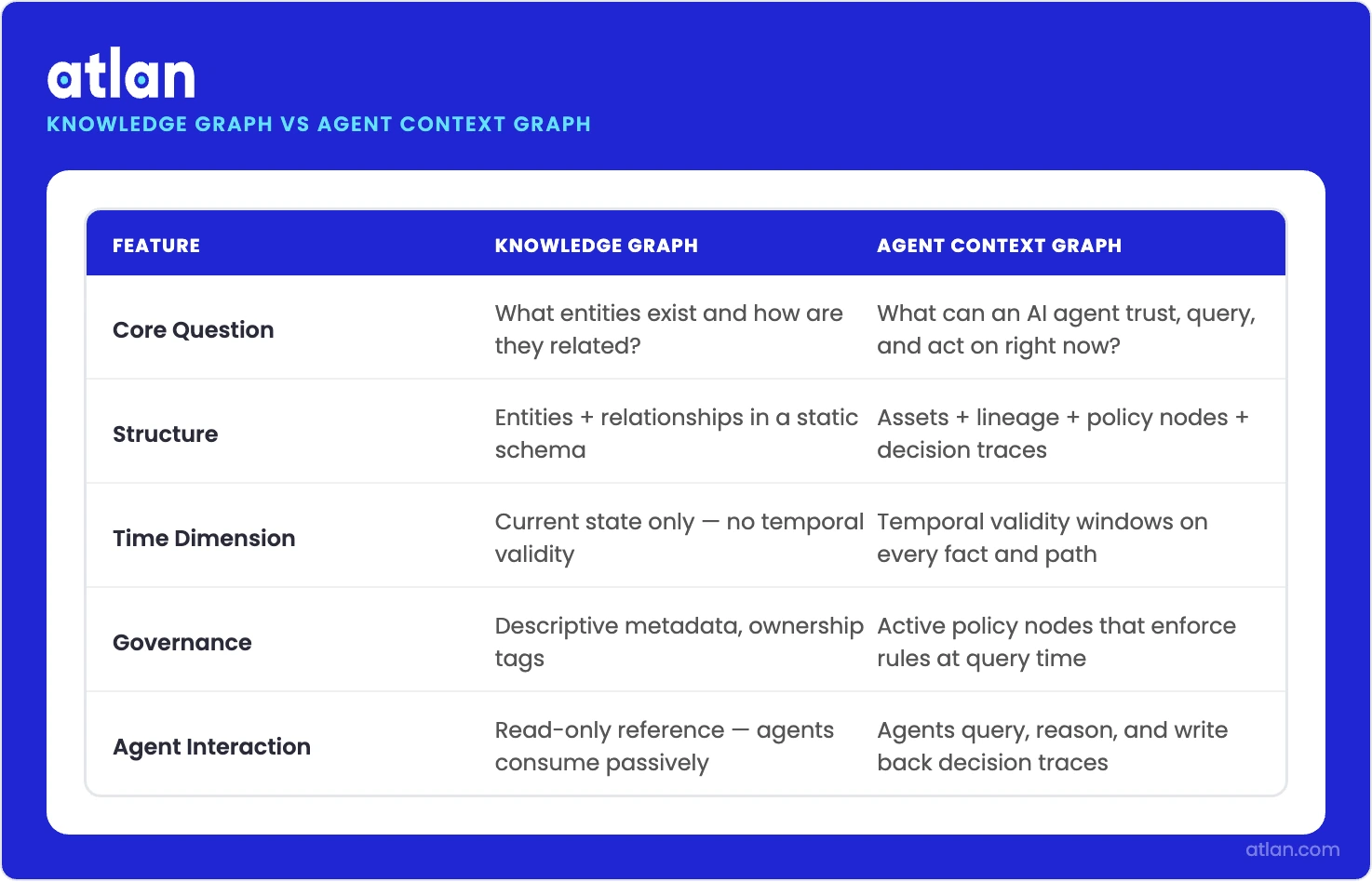
3. How is an agent context graph different from a knowledge graph?
Permalink to “3. How is an agent context graph different from a knowledge graph?”A knowledge graph models what entities exist and how they relate. An agent context graph extends that with time, policy context, and decision traces, answering not just what exists but when it was valid, which rules apply, and what actions have been taken and why. The difference is between a well-organized directory and an organizational memory.
4. Why do AI agents need a context graph?
Permalink to “4. Why do AI agents need a context graph?”AI agents need a context graph because enterprise operations are too complex for an agent to reason about from raw data alone. Without structured context, agents hallucinate or use stale information because they have no way to verify what is current, what is certified, or what policies govern a given situation. A context graph provides the grounded, governed, traversable context that lets agents act reliably in production.
5. What does agent write-back mean?
Permalink to “5. What does agent write-back mean?”Agent write-back is the ability for an AI agent to log its decisions, observations, and corrections back into the shared context graph after taking an action. This makes future context richer because each agent interaction adds to the organizational memory rather than disappearing after the session ends. Write-back must be governed, which means it is rule-bound and logged, so the graph does not accumulate unreviewed noise.
