


















Context graphs and ontologies are frequently discussed together, but they serve different functions in enterprise AI architectures. An ontology defines the vocabulary and reasoning rules for a domain. A context graph is the operational layer that delivers that vocabulary to AI agents at runtime, with lineage, access controls, and temporal validity attached. The distinction matters because the right tool depends on whether you are modeling meaning or delivering it. Atlan’s context layer implements the context graph side of this: a live, queryable network of data assets, business definitions, lineage paths, and access policies that AI agents traverse at inference time to get the operational context an ontology alone cannot provide. The verdict for enterprise AI: ontology is a sub-component of the context graph, and Atlan delivers the graph through its Enterprise Data Graph, governed at query time.
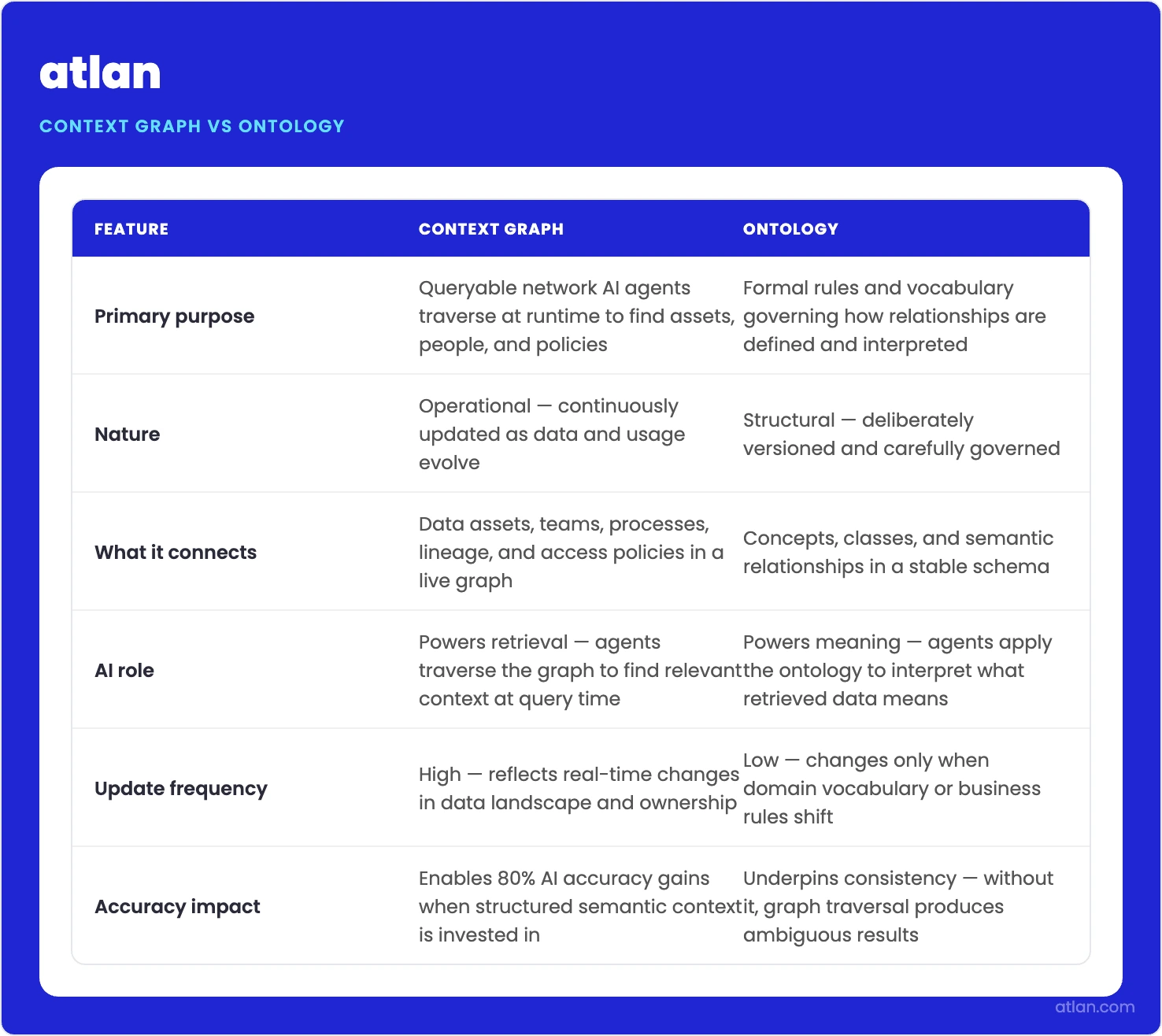
Context graph vs. ontology: comparison at a glance
Permalink to “Context graph vs. ontology: comparison at a glance”| Dimension | Context graph | Ontology |
|---|---|---|
| Definition | Queryable network of assets, people, policies, and processes | Formal vocabulary and inference rules for a domain |
| Primary purpose | Operational context for AI agents and data users | Define meaning and relationships formally |
| Structure type | Property graph or RDF graph; runtime-maintained | OWL/RDF class hierarchies; design-time authored |
| When it changes | Continuously, as pipelines, owners, and policies evolve | Infrequently, versioned by domain experts |
| Who maintains it | Data engineering and governance teams | Data architects and ontologists |
| AI agent relevance | The primary context source for enterprise AI agents | Provides vocabulary for consistent agent reasoning |
| Governance dependency | Requires governed metadata to be trustworthy | Governance defines its authority |
| AI agent query method | API or MCP server at inference time | Embedded as part of agent system prompt or retrieval schema |
| Verdict for enterprise AI | The operational layer you run; Atlan delivers it as the Enterprise Data Graph | A sub-component of the context graph, not a substitute |
AI agents query data from dozens of systems, each interpreted differently by different teams. Without a shared semantic layer, the agent takes it all at face value. That’s how confident-sounding incorrect answers surface. This guide breaks down what context graphs and ontologies are, how they differ, and where each fits, including in platforms like Atlan.
What is a context graph?
Permalink to “What is a context graph?”A context graph is a queryable network of data assets, people, processes, and policies built for AI agent consumption. Unlike a knowledge graph, which captures general world knowledge, a context graph is enterprise-specific and operationally maintained. It answers: what does this dataset mean, who owns it, how it was built, and whether it is trusted.
A knowledge graph might tell you that a customer placed an order. A context graph tells you:
- Why was that order approved despite violating standard discount terms
- What precedent existed for similar exceptions
- Who had the authority to approve it
Context graphs vs. knowledge graphs
Permalink to “Context graphs vs. knowledge graphs”The terms get used interchangeably in vendor marketing. They shouldn’t be.
A knowledge graph captures general relationships between entities. Google’s Knowledge Graph, for example, connects facts about the world: cities, people, companies, and their relationships. It’s broad.
A context graph is enterprise-specific and operationally maintained. It answers questions like: What does this dataset mean? Who owns it? How was it built? Is it trusted? What governance policy applies right now? It’s narrow, deep, and designed specifically for AI agent grounding.
What makes context graphs different from regular knowledge graphs comprises three additional layers:
- Ontological grounding: The semantic vocabulary that defines what types of entities exist and how they relate. Without this, the graph stores facts but not meaning.
- Operational metadata: Lineage, usage patterns, quality scores, ownership, and access policies. This is the “how” layer. It documents how data flows through systems and how teams actually use it.
- Decision traces: Approvals, exceptions, overrides, and the reasoning behind them. When a VP approves a 20% discount that exceeds the standard policy cap, the context graph records the rationale, the precedent, and the conditions — stored as structured fields like
exception_approved_by,override_reason, andprecedent_case_id. Not just the outcome.

Property graphs and RDF: the underlying structures
Permalink to “Property graphs and RDF: the underlying structures”Under the hood, context graphs run on one of two structural families. Property graphs, the kind Neo4j uses, store attributes directly on nodes and edges. They’re the more developer-friendly option. RDF graphs take a different approach: subject-predicate-object triples inherited from the Semantic Web tradition, more verbose but more expressive when you need formal reasoning.
In 2026, Neo4j repositioned as “AI agent memory graph” infrastructure, blurring the line further. This is a context graph in function, not a knowledge graph. The distinction matters because a graph database stores relationships. It doesn’t govern them.
Platforms like Atlan work above both structural families, providing the governance, lineage, and semantic layers that make raw graph data trustworthy for AI consumption.
What is an ontology?
Permalink to “What is an ontology?”An ontology is a formal definition of concepts and relationships within a domain. It specifies vocabulary, hierarchy, and inference rules. In data management, ontologies define what a “customer,” “transaction,” or “pipeline run” means and how those concepts relate. Without an ontology, context graphs lack an interpretable structure.
Think of an ontology as the schema that defines what entities can exist and how they relate.
It doesn’t contain data about specific customers or transactions. It defines the types of things that can exist, their properties, and the rules governing their relationships. For example, the word “diagnosis” could mean a medical diagnosis or a software bug diagnosis. The ontology removes that ambiguity.
Ontology authors typically use formal languages like Web Ontology Language (OWL) or RDF Schema to define classes, properties, hierarchies, and logical axioms. The result is both human-readable and machine-interpretable.
Ontologies are intentionally static. Changes go through the proposal, review, approval, and versioning processes. That deliberateness is the point. And they support inference: if Drug X treats Disease Y, and Patient Z has Disease Y, the system can figure out Drug X is relevant to Patient Z without anyone writing that rule explicitly.
Structured semantic investments improve model accuracy and reduce operational costs because AI systems spend less time reasoning over ambiguous or conflicting context. Ontologies are the semantic contract that makes everything else interpretable.
OWL, RDF, and the semantic web tradition
Permalink to “OWL, RDF, and the semantic web tradition”Tim Berners-Lee and the W3C envisioned a web where machines could understand and reason about content, powered by RDF, OWL, and SPARQL.
That vision didn’t fully materialize for the web. But in enterprise data management, ontologies took hold in industries where precision matters: healthcare uses FHIR and SNOMED CT for interoperability. Financial services use FIBO for regulatory compliance. Pharma companies use biomedical ontologies for drug discovery.
The Semantic Web’s unfulfilled promises left baggage. As one Hacker News commenter noted in 2021 (community commentary, not peer-reviewed), the community’s insistence on “open world” assumptions proved “insanely impractical for data practitioners.” But the core technology was sound. AI is now the driving force, making ontologies necessary at scale.
Where ontologies fit
Permalink to “Where ontologies fit”These concepts build on each other in order of semantic complexity:
- Taxonomy: Hierarchical classification (e.g., Animal > Mammal > Dog). Organizes things into categories.
- Thesaurus: Adds synonyms, related terms, and broader/narrower relationships. Richer than taxonomy but still limited.
- Ontology: Adds formal logic, properties, constraints, and inference rules. Can represent complex relationships like “Drug X treats Disease Y, which shares pathways with Disease Z.”
- Knowledge graph: Populates an ontology with actual instance data. The ontology is the schema; the knowledge graph is the database.
Most enterprise data teams already maintain some form of ontology, even if they don’t call it that. Business glossaries, logical data models, and AI-generated knowledge graphs are all ontological artifacts. However, they live in separate systems, maintained by separate teams, with no way to keep them consistent across systems.
How are ontology, semantic layers, and context graphs different from each other?
Permalink to “How are ontology, semantic layers, and context graphs different from each other?”These three concepts solve related but distinct problems. An ontology defines meaning. A semantic layer translates meaning into business metrics for BI tools. A context graph puts meaning to work across all data assets and AI agents. Conflating them leads to misdirected tooling decisions.
Why the confusion persists
Permalink to “Why the confusion persists”Vendors often use different terminology for similar concepts, prioritizing marketing clarity over technical precision.
The cost of that confusion is real. Teams buy graph databases, thinking they have solved the context problem. They haven’t. A graph database stores relationships. A governed context graph actively maintains lineage, ownership, quality signals, and access policies across the entire data estate.
Jessica Talisman points at the distinction in Metadata Weekly, saying, “Metric definition and ontology engineering are fundamentally different disciplines. Let’s not fool ourselves into thinking that ontologies and semantic layers are remotely similar in objectives or end results.”
If you need an in-depth comparison of the ontology vs. semantic layers, there’s a dedicated guide doing justice to the differences between them.
How do context graphs work in practice?
Permalink to “How do context graphs work in practice?”A context graph ingests metadata from data sources, pipelines, BI tools, and governance policies. It maps relationships like column-level lineage, ownership, data quality scores, and access controls into a traversable network. AI agents query this network via APIs or MCP (Model Context Protocol) to retrieve trusted, governed context before generating outputs.
Here’s what that looks like in a real data stack. On the technical side, the graph pulls from schemas, column types, and pipeline configs. Business context comes from glossary definitions, metric formulas, and ownership records. Query logs and usage frequency show which datasets are actively used. Access policies, classification labels, and compliance rules round it out so governance is baked in rather than bolted on.
The most useful context graphs also capture decision traces. When a VP approves a policy exception or a data steward overrides a quality flag, the context graph records the reasoning, the rules that applied, and the precedents that informed the call. Every automated decision adds another trace.
Over time, the graph accumulates enough precedent to make future decisions faster and more consistent.
When should you use a context graph vs an ontology?
Permalink to “When should you use a context graph vs an ontology?”Use ontologies when domain knowledge is stable, cross-organizational interoperability matters, or formal reasoning is required. Use context graphs when AI agents need operational context at inference time, decision auditability is critical, or governance must be enforced at runtime. Use both when building production-grade AI agent systems. The ontology provides the semantic foundation; the context graph adds the operational layer.
When to use context graphs vs ontologies vs both
| Scenario | Use an ontology | Use a context graph | Use both |
|---|---|---|---|
| Domain knowledge is stable (healthcare, finance) | Yes | Optional | Ideal |
| AI agents need context at inference time | Supporting role | Yes | Ideal |
| Cross-organizational data sharing is required | Yes | No | Yes |
| Decision auditability and compliance are required | Supporting role | Yes | Ideal |
| Data stack changes frequently (multi-vendor) | Too rigid alone | Yes | Ideal |
| Formal reasoning and inference are needed | Yes | No | Yes |
| Governance must be enforced at runtime | No | Yes | Ideal |
| Evolving from BI to AI | Preserve existing | Extend with an operational layer | Ideal |
Use ontologies when:
Permalink to “Use ontologies when:”Ontologies shine where domain knowledge is stable, and precision is non-negotiable. Healthcare organizations rely on FHIR ontologies so that Patient, Medication, and Observation mean the same thing across every hospital system. Financial services use FIBO for the same reason: Customer and Transaction definitions can’t drift when regulators are watching.
They also shine when formal reasoning is the point. Pharma companies use biomedical ontologies for drug discovery, where the ability to infer that Drug X might treat Disease Z (because it treats Disease Y, and Y shares pathways with Z) is the primary value driver. If your primary consumer is a human knowledge worker who needs a reliable reference for what things mean, ontologies are the right foundation.
Use context graphs when:
Permalink to “Use context graphs when:”Context graphs earn their keep in environments where static definitions aren’t enough. An AI agent writing SQL needs to know not just what a column means, but which metric definition is current, whether the data quality is good enough to act on, and who owns the table if something looks wrong.
They’re also critical for decision auditability. Regulated industries need to trace the full chain: what data was used, why specific decisions were made, and who approved exceptions. And if your data stack includes dozens of tools from different vendors and changes every quarter, static ontologies can’t keep up. Context graphs capture operational reality as it unfolds.
Use both when:
Permalink to “Use both when:”Most production AI systems need both layers working together. Here’s how to tell:
| Signal | What it means |
|---|---|
| Multiple domains with shared terms | The ontology keeps “customer” consistent. The context graph shows how each domain actually uses the data. |
| Moving from BI to AI | The ontology preserves existing semantic investments. The context graph adds the operational intelligence agents need. |
| Regulatory audit requirements | The ontology provides the formal vocabulary auditors expect. The context graph produces the decision traces and lineage they verify. |
| Agents acting across systems | The ontology grounds meaning. The context graph enforces governance at each step. |
Why does a context graph need governance?
Permalink to “Why does a context graph need governance?”An ungoverned context graph is a liability. Without ownership metadata, lineage, quality scores, and access policies, AI agents retrieve context they can’t trust. The governed context graph embeds these controls at the metadata layer, not as an afterthought. It requires five layers: asset inventory, column-level lineage, ownership, quality observability, and access policy enforcement.
Context without governance doesn’t reduce hallucinations. It makes them harder to detect.
What makes a context graph governed
Permalink to “What makes a context graph governed”Five layers separate a governed context graph from a raw graph database:
- Asset inventory: You can’t govern what you haven’t cataloged. The base layer maps what exists across the entire data stack.
- Column-level lineage: When something breaks downstream, lineage tells you why. It traces dependencies across every transformation so you know exactly which upstream change caused the problem.
- Ownership and stewardship: When an AI agent hits ambiguity, it needs a human to escalate to. Ownership metadata provides that escalation path.
- Quality and observability: Not all data deserves the same confidence level. How fresh is it? How accurate? How complete? Agents and humans need those signals before deciding whether to act on what they find.
- Access policy: Different users and agents should see different things. Permission-aware retrieval stops sensitive data from leaking into the wrong context window.
Why bolting governance onto an existing graph doesn’t work
Permalink to “Why bolting governance onto an existing graph doesn’t work”Several emerging tools give developers a head start on context graph infrastructure. They’re good at ingestion, entity extraction, and graph construction. But they’re scaffolding, not governance. The distinction matters because an enterprise doesn’t just need a graph that stores relationships. It needs a graph in which each node carries ownership, quality scores, and access policies that update as the underlying data changes.
How context graph frameworks compare on governance
| Capability | Neo4j | Glean | Cognee / Graphlit / TrustGraph | Atlan |
|---|---|---|---|---|
| Graph storage | Yes | No | Yes | Yes |
| Enterprise search | No | Yes | Limited | Yes |
| Column-level lineage | No | No | No | Yes |
| Active metadata capture | No | No | No | Yes |
| Ownership and stewardship tracking | No | No | No | Yes |
| Data quality signals | No | No | Limited | Yes |
| Access policy enforcement | No | Limited | No | Yes |
| MCP server for agent delivery | Yes | Yes | Limited | Yes |
Neo4j and Glean both expose MCP servers, but they function as search or memory endpoints. Atlan’s MCP server delivers a governed context graph: metadata, lineage, policies, and quality signals, not just content retrieval.
Atlan combines an enterprise data graph (technical metadata), a governance graph (policies, classifications, access), a knowledge graph (business concepts and decision traces), and an MCP server that exposes this governed context directly to AI tools. The context graph and governance live in the same system, not in separate tools stitched together.
The active ontology is the part most teams haven’t seen before. Traditional ontologies fall out of sync with operational reality because changing them is expensive and risky. An active ontology maintains the formal semantic rigor while updating itself based on operational signals.
Atlan is a Leader in the 2025 Gartner Magic Quadrant for Metadata Management Solutions and a Visionary in the 2025 Gartner Magic Quadrant for Data & Analytics Governance Platforms. That’s not a coincidence.
How do you build a governed context graph?
Permalink to “How do you build a governed context graph?”Start with the metadata inventory: catalog every data asset, owner, and pipeline. Add column-level lineage to trace data dependencies. Enforce governance policies on context graph queries. Connect to AI agents via MCP or API. Validate context quality continuously. That sequence is a governed context graph. The five steps below move you from existing infrastructure to production.
A governed context graph isn’t a greenfield project. It’s a layer you build on top of what you already have. Five steps get you there.
- Start by mapping what exists. Connect your data warehouse, pipelines, and BI tools to a metadata platform. You can’t govern what you haven’t cataloged.
- Then trace how it was built. Enable column-level lineage across dbt, Snowflake, Databricks, BigQuery. When a metric definition changes upstream, lineage shows you exactly what breaks downstream.
- Add the governance layer. Assign stewards, classify sensitive assets, and set access policies. The important part: make these policies active elements in the graph, not static documents in a wiki nobody reads.
- Make it available to agents. Expose your governed graph via an MCP server or API so AI agents can query it at inference time. Until this step, the context graph is a reference system. After it, agents can actually use what you have built.
- Monitor for drift. Context drift occurs when the graph loses synchronization with reality: new pipelines go uncataloged, owners change without updates, and quality scores go stale. Active monitoring catches drift before it corrupts agent outputs.
Context as culture: Workday's AI-ready semantic layer
"As a part of Atlan's AI labs, we are co-building the semantic layers that AI needs with new constructs like context products that can start with an end user's prompt and include them in the development process."
Joe DosSantos, Vice President of Enterprise Data & Analytics
Workday
Workday achieved 5x improvements in AI analyst response accuracy
Watch Now →
Context by design: Mastercard's foundation-first approach
"At Mastercard, we've learned you can't just bolt things on at the end. We've learned that from privacy by design and now we're going to make sure we do that with context by design. You have to build it in from the get-go because when you do that, you can not just keep up with AI, but you can build trust in your journey."
Andrew Reiskind, Chief Data Officer
Mastercard
Mastercard's building context from the start
Watch Now →Frequently asked questions
Permalink to “Frequently asked questions”What is the difference between a context graph and a knowledge graph?
Permalink to “What is the difference between a context graph and a knowledge graph?”A knowledge graph captures general relationships among entities, such as how cities, people, and companies connect. A context graph is narrower: enterprise-specific, operationally maintained, and layered with governance policies, decision traces, lineage, and temporal context. Knowledge graphs serve human exploration. Context graphs serve AI agent execution.
Can you build a context graph without an ontology?
Permalink to “Can you build a context graph without an ontology?”You can, but you shouldn’t. Without ontological grounding, a context graph stores facts without guaranteed meaning. The ontology provides the semantic contract that ensures “revenue” means the same thing across every team, dashboard, and AI agent. Building without one works for prototypes. It breaks in production.
What is the difference between an ontology and a taxonomy?
Permalink to “What is the difference between an ontology and a taxonomy?”A taxonomy classifies things into hierarchies (Animal > Mammal > Dog). An ontology goes further: it adds formal logic, properties, constraints, and inference rules. An ontology can express that “all mammals are warm-blooded” and use that rule to infer properties of new entities. A taxonomy can only classify them.
What is a governed context graph?
Permalink to “What is a governed context graph?”A governed context graph is a queryable network where every node carries ownership, lineage, quality, and access metadata. The “governed” part is what matters: unlike a raw graph database, a governed context graph updates continuously as data changes. It requires a platform that automatically captures and enriches metadata, not a graph you populate once and hope stays current.
How do AI agents use context graphs?
Permalink to “How do AI agents use context graphs?”AI agents query context graphs before generating any output. The graph shows which assets exist, who owns them, how trustworthy the data is, and which access policies apply. This grounds the agent’s response in verified facts rather than guesses. MCP is the emerging standard for this delivery. Organizations using governed context consistently report higher AI response accuracy when agents consume rich metadata rather than raw database schemas.
What is the difference between a context graph and a semantic layer?
Permalink to “What is the difference between a context graph and a semantic layer?”A semantic layer translates raw data models into business metrics for BI tools. A context graph connects data assets, people, processes, and policies into a queryable network for AI agents and data teams. Semantic layers serve analytics. Context graphs serve operational decision-making. AI agents need both, but the context graph covers more ground.
How is a governed context graph different from Neo4j?
Permalink to “How is a governed context graph different from Neo4j?”Neo4j is a graph database built for storing and querying graph data structures. A governed context graph platform does something different: it maintains active metadata, column-level lineage, ownership, and governance policies across the entire data estate. Neo4j handles storage. A governed context graph handles meaning, trust, and access on top of that storage.
What causes context drift in a context graph?
Permalink to “What causes context drift in a context graph?”Context drift occurs when the context graph falls out of sync with the underlying data. New pipelines aren’t cataloged. Owners change without updates. Quality scores aren’t refreshed. Governed context graphs prevent drift through active metadata, automatically updating context as data assets change. Without active monitoring, drift accumulates silently until an agent produces a decision based on stale context.
Are context graphs just rebranded knowledge graphs?
Permalink to “Are context graphs just rebranded knowledge graphs?”Traditional knowledge graphs weren’t designed to capture decision traces, enforce runtime governance, or track temporal validity. If your knowledge graph does all of that, you’ve already built a context graph. Most haven’t.
What are decision traces and why do they matter?
Permalink to “What are decision traces and why do they matter?”A decision trace records how a specific decision was made: what data was used, what rules applied, who approved, what exceptions were granted, and what precedents existed. Decision traces capture why something was allowed to happen. That reasoning currently lives in Slack threads, Zoom calls, and people’s heads. Context graphs make it queryable.
Can a semantic layer replace an ontology for AI agents?
Permalink to “Can a semantic layer replace an ontology for AI agents?”Metric definition and ontology engineering are fundamentally different disciplines. A semantic layer defines how metrics are calculated for BI tools. An ontology defines what entities are, how they relate, and what rules govern them. LLMs need to understand what things are and how they connect, not just how to compute a quarterly number. Semantic layers handle the analytics question. Ontologies handle the reasoning question. AI agents need both.
What do AI systems need in 2026?
Permalink to “What do AI systems need in 2026?”Enterprise investment in structured context infrastructure is accelerating. The trend is clear across analyst reports and vendor roadmaps: AI systems need governed context to work reliably.
Ontologies provide the semantic backbone. They define what things mean. Context graphs add the operational layer: how things are used, who decided what, and why. You need both to build AI systems that hold up in production.
Gartner’s Rita Sallam called context “the brain for AI” and predicted universal semantic layers will be treated as critical infrastructure by 2030. The spending data supports the urgency: organizations with the highest AI satisfaction invest nearly twice as much in foundations (data quality, governance, talent) as in AI tools.
The winners in this space won’t be the companies that build the best graph database or the most elegant ontology schema. They’ll be the platforms that unify both into a single, governed context layer: meaning and operations in one system, serving humans and agents, stable enough for semantic consistency and dynamic enough for real-time governance.
Atlan’s unified context layer bridges these approaches by unifying semantic modeling with active metadata capture, providing foundations for both human collaboration and AI reasoning.
