



















In 2023, an AI product launch event might have been met with questions like: “how fast can I get access to this?” But that was before companies started finding out for themselves that a flawless AI pilot often still fails in production.
Now, with the lived experience of AI failures, questions about AI launches are more wide-ranging — and skeptical. During Atlan Activate, participants lit up the Q&A with nearly 200 of them. And they weren’t random: leaders and practitioners from across different industries and with different tech stacks bubbled up the same themes. That kind of convergence exposes where enterprise AI is stuck.
Here’s what the most-asked questions tell us, and why they’re surfacing as the context infrastructure category becomes real.
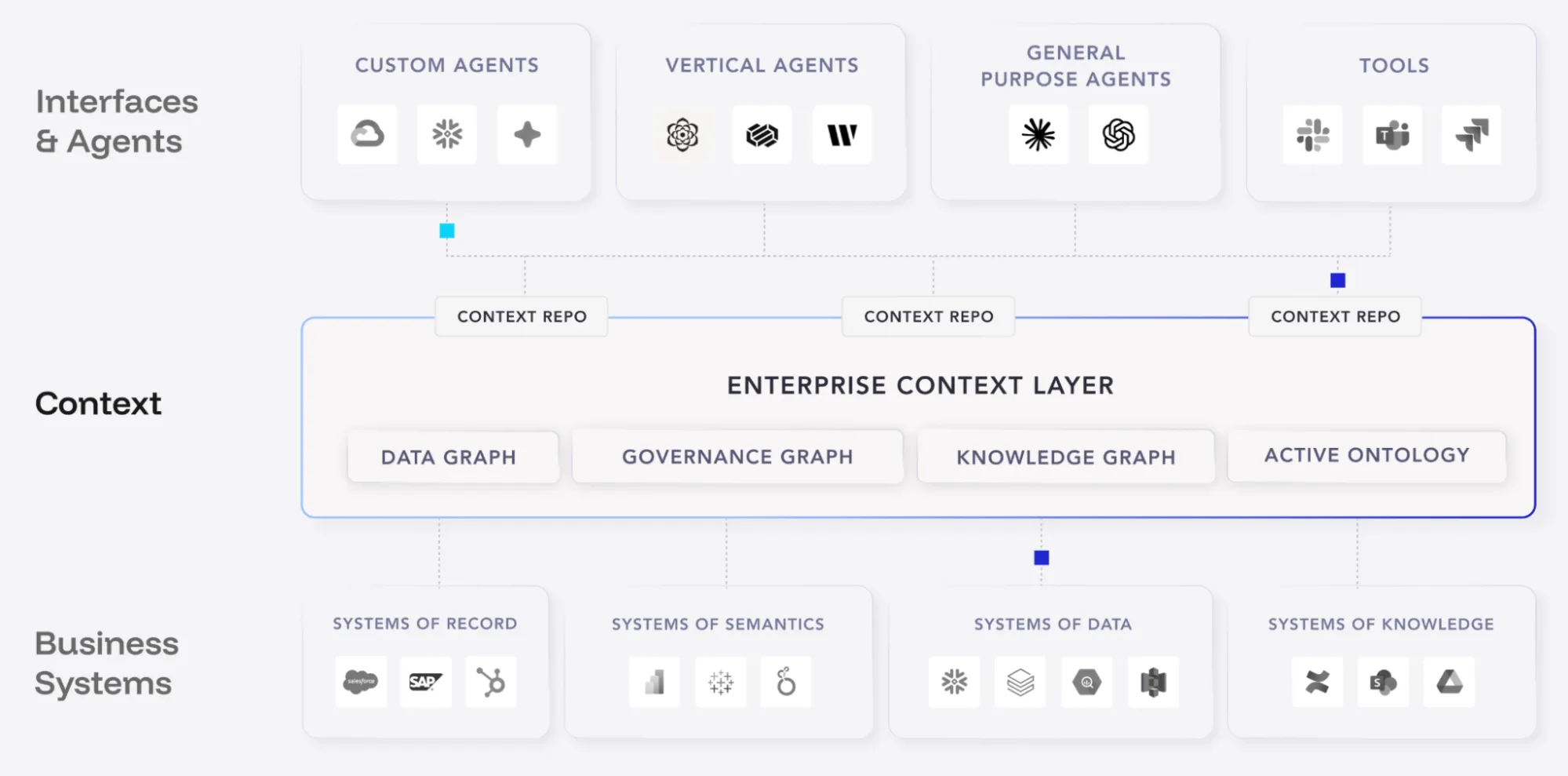
“Where does the context layer sit? Is it the top of the pyramid?”
Permalink to ““Where does the context layer sit? Is it the top of the pyramid?””What it tells us: People are reaching for familiar frameworks to understand and place something new.
The question of where the context layer sits in the tech stack came up more than once, and with good reason. When a new category arrives, people naturally try to map it onto the architecture they already know. It gives a new concept a point of reference that helps people form a mental model. The fact that people reached for a pyramid analogy is a sign that the context layer needs spatial clarity, not just a definition.
Atlan’s answer: It depends on how you think about the pyramid. If the pyramid represents your entire enterprise data graph — the structured data, the business definitions, the lineage, the policies — then yes, the enterprise context layer sits at the top. It’s the layer that makes everything below it usable by AI agents.
But it’s less useful to think of it as a position in a stack, and more useful to think of it as a connective tissue. The context layer runs across every other layer, binding technical metadata to business meaning so that agents can reason with the full picture rather than a fragment of it.
“How do we know that the context created by the agents is correct?”
Permalink to ““How do we know that the context created by the agents is correct?””What it tells us: Trust is the #1 blocker to production, and governance for AI outputs is being designed in real time.
This question came in various different forms across the session:
- What’s the accuracy benchmark?
- How do you prevent hallucinations?
- How do you root-cause a wrong answer?
- Who reviews the outputs, and when?
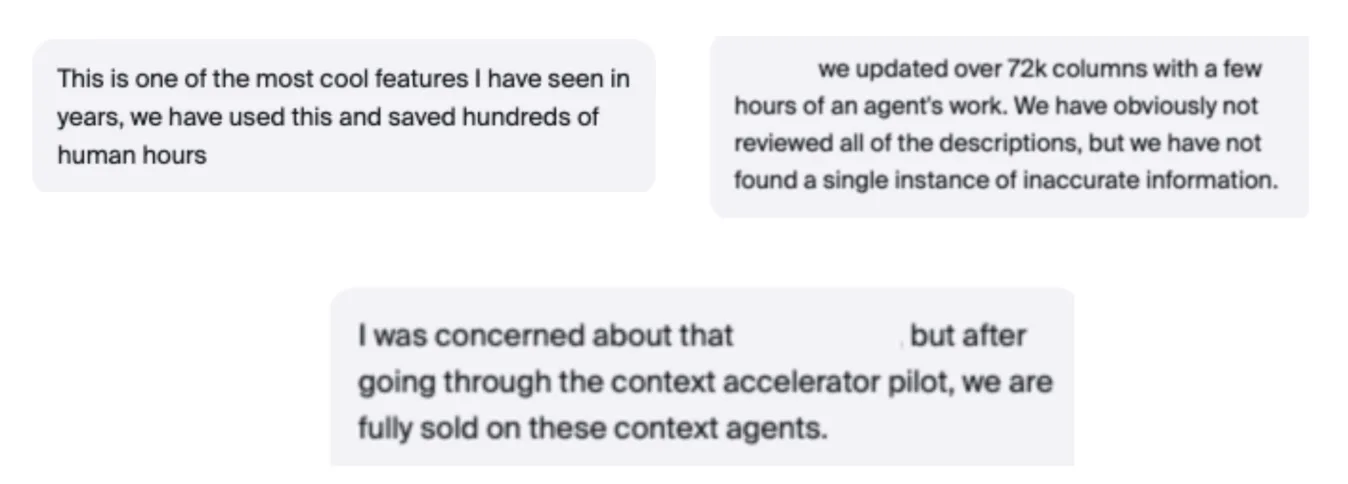
After hearing that Atlan generated more than a million descriptions in a matter of weeks, a data leader at a global insurance company asked: what percentage did a human review? That’s a live governance design problem that nobody in the industry has fully solved yet. The people asking are the ones who will have to answer for it.
Atlan’s answer: No AI system is immune to hallucination. The answer to mitigating it is to establish a feedback loop. Atlan uses evals: structured tests where subject matter experts interrogate the agent, assess its outputs, and trace wrong answers back to gaps in the context repository. When an agent gets something wrong, you improve the underlying definitions so it doesn’t happen again.
For oversight, the model is human-on-the-loop, not human-in-the-loop. In this model, only the assets that matter most require human review, so SMEs aren’t overburdened and workflows aren’t bottlenecked.
Before production, SMEs run simulations across different personas and use cases to build and stress-test the context repository. After production, traces capture what the agent produces and how humans rate responses, feeding further refinements. The goal is to make agents closer to deterministic over time, not to expect perfection from day one.
“Is this a new category or just repackaging?”
Permalink to ““Is this a new category or just repackaging?””What it tells us: Buyer skepticism is warranted, and category creation must be earned.
A senior analyst from a leading industry research firm asked this directly: is the context layer truly a new enterprise software category, or a re-packaging of data catalog, semantic layer, governance, lineage, and knowledge graph under an AI-native narrative? It’s the sharpest question asked at Activate, and it deserves a straight answer.
Atlan’s answer: Last year, enterprises were experimenting with LLMs, prompt engineering, and RAG, and performance was still low. Something was missing: a unified, portable layer that agents can consume at runtime, grounding their responses in lineage, ownership, definitions, and business relationships all at once, not one tool at a time.
The context layer isn’t a rebranded catalog. The right question isn’t “what does this replace?” but “what can my agents do now that they couldn’t before?” Atlan customers who had run Context Agents on their own data weighed in on this in real time during Activate, verifying that descriptions that used to take weeks of manual stewardship are now generated in hours. And 87% of teams in our Context Agent Accelerator program approved outputs with no edits needed.
“Can you read from existing semantic layers in BI, Snowflake, and Databricks?”
Permalink to ““Can you read from existing semantic layers in BI, Snowflake, and Databricks?””What it tells us: Data practitioners aren’t starting from zero, and they don’t want to.
This question surfaced from data architects, cloud platform teams, and analytics engineers. Each of them had already invested in semantic definitions inside their BI tools, their Snowflake environment, or their Databricks workspace. They weren’t asking if Atlan can replace what they have in place, but whether it can read what they’ve already built. That tells us organizations are thinking about the context layer as an aggregator, not a replacement.
Atlan’s answer: Atlan connects to semantic views in Snowflake and Databricks, and ingests the metadata, metrics, and dimension definitions already living there. For BI tools, the same applies: Atlan pulls in the context embedded in your dashboards and reports, including lineage from the BI layer, back to source tables.
Atlan’s context graph starts with what you’ve already defined, rather than asking you to rewrite it. Tools like Databricks AI/BI Genie can then consume the context repo Atlan builds, so the agents reasoning over your data have access to the semantic definitions your analysts already trust.
“How do we secure agents’ activities, and who controls what they can see?”
Permalink to ““How do we secure agents’ activities, and who controls what they can see?””What it tells us: Security and access control for AI agents is the enterprise’s most pressing unsolved problem.
The security questions at Activate came from every angle. A data security lead asked how to prevent a chat agent from surfacing data a user shouldn’t see. A platform architect asked whether AI policy enforcement applies only inside Atlan, or extends to external tools like Dataiku and Snowflake. A governance lead in financial services pushed on audit-defensibility: for regulated use cases, human-in-the-loop explainability isn’t optional.
Underneath all of it was the same question: when an agent acts on behalf of a user, who is responsible for what it accesses?
Atlan’s answer: Agent access in Atlan is controlled entirely through existing connector permissions. An agent inherits the same access rights as the user on whose behalf it operates. If a user can’t see a dataset, neither can the agent. Access control is enforced at the identity level, not the application level, so permission boundaries don’t shift when AI enters the workflow.
For regulated industries, every AI action ties back to governed metadata, lineage, and policies, giving teams full audit trails and the option for human-in-the-loop approvals where required. For less regulated use cases, the same foundation supports a human-on-the-loop model, which is more autonomous but still observable and correctable. The guardrails are the same controls already in place, but extended to cover agents.
“Will enterprises need one context layer, or many domain-specific context layers stitched together?”
Permalink to ““Will enterprises need one context layer, or many domain-specific context layers stitched together?””What it tells us: Organizations are already thinking about context at scale, and they’re worried about fragmentation.
A research analyst in the room asked this precise question. It’s the right one to ask early, because the answer shapes how an organization architects its rollout. The risk of getting it wrong is high: if teams build siloed context repositories per domain, the same fragmentation problem that plagued data catalogs shows up again, one layer higher.
Atlan’s answer: The context layer should be unified. Within each domain, bounded context repositories provide the domain-specific definitions, rules, and relationships that users in that domain need. But the value of a single context layer is that context can be shared across domains. The definition of “customer” that lives in the sales domain can inform how the finance domain’s agents reason about revenue.
Separate layers mean separate truths. A unified layer with domain-bounded repositories gives you both precision and coherence.
“What if we’re starting from scratch?”
Permalink to ““What if we’re starting from scratch?””What it tells us: Many enterprises don’t yet have their context foundations in place, and they know it.
Multiple attendees asked variations of this: What if we have no business documentation? What if the definitions only live in people’s heads? What if our data was never properly modeled?
A data leader at a large distribution company and a platform engineer at a field service software firm framed it most directly: is this a tool for teams that already have governance maturity, or can it help build that maturity from a low baseline?
The answer matters because most enterprises are at the low baseline.
Atlan’s answer: Context agents start from what exists, not from what’s documented. Query logs, lineage, DDL definitions, and connected dashboards all provide a first pass. Even without pre-loaded business documentation, agents build accurate context from technical metadata.
Where definitions conflict or tribal knowledge is missing, the human-on-the-loop feedback loop fills the gap. Governance maturity is an outcome of using the system, not a prerequisite for getting started.
See where your organization falls on the AI context maturity scale
Take the free assessment“Can we use our own LLM?”
Permalink to ““Can we use our own LLM?””What it tells us: Nobody wants to rebuild their context layer in 18 months.
At least three teams asked this, from a technology leader at a multinational IT services firm to a data architect at a major media company. The underlying concern is about vendor lock-in — an issue that’s been plaguing data teams since well before AI became ubiquitous.
If the context layer is built on one vendor’s model, what happens when that model is replaced, deprecated, or superseded? Given how fast the model landscape is moving, it’s the right question to ask before committing.
Atlan’s answer: Atlan uses an off-the-shelf LLM from Azure, with BYO model support on the roadmap. But the more important point is that the context itself is portable, and accessible through MCP, API, and SQL. That means the context repository doesn’t live inside any one model or runtime. When models change, the context moves with you.
“How do we show the CFO the ROI?”
Permalink to ““How do we show the CFO the ROI?””What it tells us: The business case for context is still being written.
A research analyst at Activate asked how to measure compounding context value in a way CFOs will accept. It’s the right question at the right time, as pressure to justify AI infrastructure is growing. IDC research finds that 35% of organizations report difficulty quantifying and demonstrating AI ROI to stakeholders. CFOs may not be resistant to investing, but they do need to understand the business case in objective terms.
Atlan’s answer: The ROI of context shows up in what agents can now do reliably that they couldn’t before, and what that means for the rest of the business. Every description enriched, conflict resolved, and definition validated makes downstream agents more accurate.
The metrics to measure are agent accuracy and adoption over time, and the efficiency gains and business impact that unlocks. Organizations who ran Context Agents in Atlan’s accelerator program saw description generation drop from weeks to hours — and 87% approved outputs without edits. That’s the starting point for a business case that compounds.
What convergence tells you
Permalink to “What convergence tells you”Nearly 200 questions, nine convergent themes. That’s not noise — it’s signal. The questions data and AI leaders asked at Activate 2026 weren’t questions about whether to invest in AI infrastructure. They were questions about how to make it trustworthy, secure, portable, and defensible.
That shift is the real story. Enterprise AI has moved past the “can we do this?” phase. The harder work — the work that actually determines who wins — is in building the context layer that makes agents reliable when it counts.
The organizations that get there first won’t just have better AI. They’ll have the only AI their business can actually trust.
