


















Context engineering vs RAG quick comparison table
Permalink to “Context engineering vs RAG quick comparison table”Context engineering and RAG are not competing approaches. Atlan’s Context Layer operationalizes this separation: its Context Agents continuously harvest definitions, ownership, lineage, and semantic models from 75+ data systems so that RAG retrieval draws from governed, up-to-date context rather than raw, ungoverned metadata.
This page breaks down where RAG ends, where context engineering begins, and how to decide which one your system actually needs.
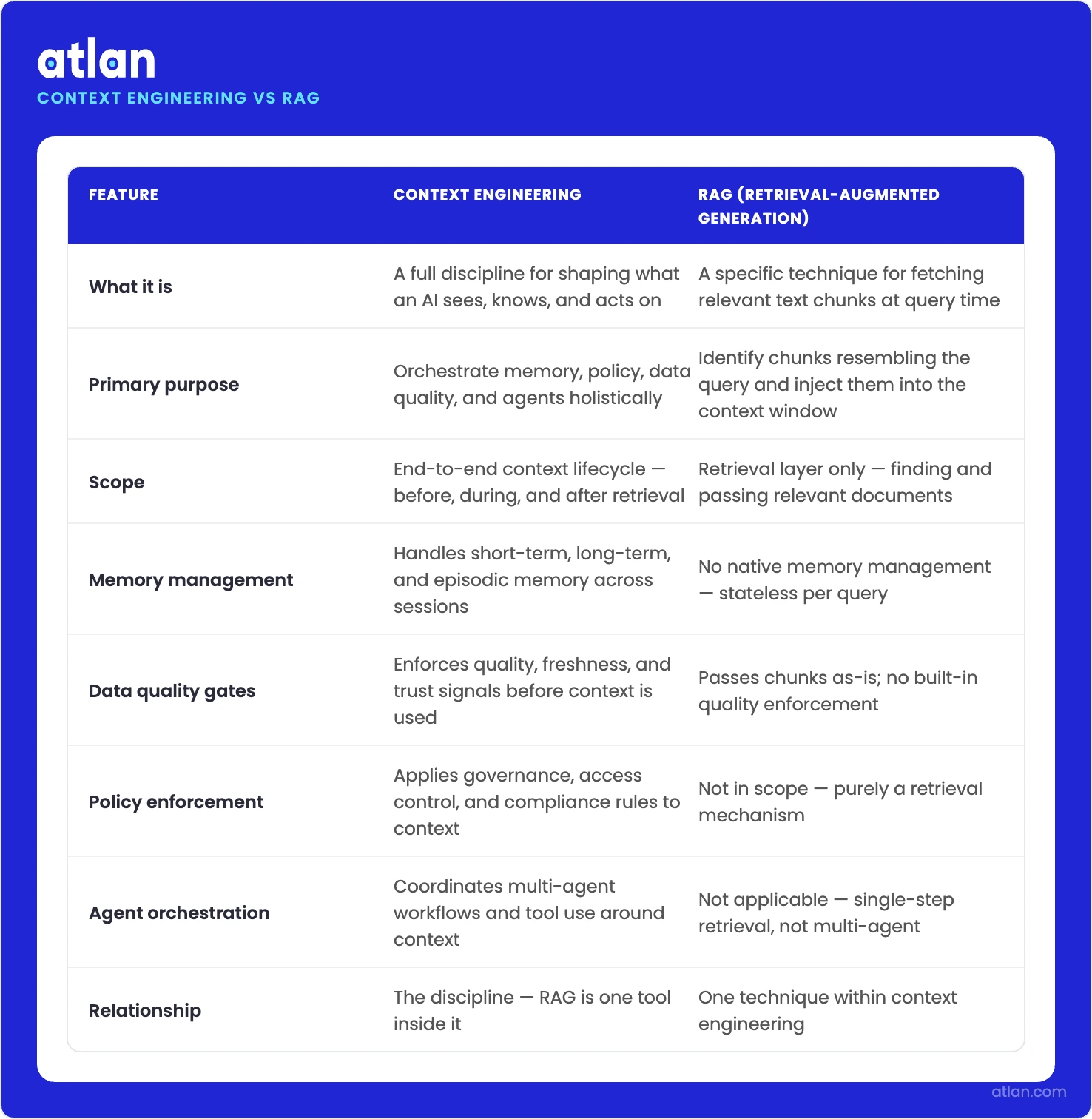
| Dimension | Context engineering | Retrieval-Augmented generation (RAG) |
|---|---|---|
| What it is | A discipline covering all information that enters the context window | A retrieval technique using vector search to fetch relevant chunks |
| Relationship | The superset that includes RAG plus memory, governance, and orchestration | One component inside context engineering |
| When it’s enough | Required when live data, memory, multiple agents, or audit trails are in scope | Simple Q&A on a static, trusted corpus with no compliance requirements |
| The key question it answers | “What is relevant, trustworthy, and auditable?” | “What is relevant?” |
| Primary failure mode | Needs a context governance layer to close the gap RAG leaves open | Returns relevant but ungoverned chunks (stale, incorrect, policy-violating data) |
What is the difference between context engineering and RAG?
Permalink to “What is the difference between context engineering and RAG?”Context engineering is a discipline, and RAG is one of its techniques. RAG handles the mechanical work at the retrieval layer, identifying chunks that resemble the query and dropping them into the context window. Context engineering takes a broader remit, covering memory management, data quality gates, policy enforcement, and agent orchestration in addition to retrieval itself.
It helps to settle what each term actually means.
- Context engineering sits a level above that. It is the discipline of curating everything the model sees at inference time, with retrieval (where RAG lives) as just one piece alongside memory, tool outputs, data quality filters, policies, and orchestration logic.
- Retrieval-Augmented Generation (RAG) is a technique. Given a user query, it fetches relevant text chunks from an external corpus through semantic search and injects them into an LLM’s context window before the model generates a response.
How enterprise teams govern what AI agents see before they reason. Source: Atlan.
What RAG does, and what it was designed for
Permalink to “What RAG does, and what it was designed for”To understand why RAG alone falls short in production, it helps to remember the problem it was originally designed to solve. Language models arrive with a static knowledge cutoff, and retrieval was the workaround — a way to let them reach beyond training data at inference time. Nothing about its original design involved governing data quality, enforcing access policies, or tracing data lineage.
A standard RAG pipeline runs through four stages:
- The user query gets encoded as a vector
- A vector database returns the top-k most similar chunks
- Those chunks assemble into the context window
- The LLM generates a response grounded in whatever text it just received
The chunking strategy is what determines retrieval granularity. Teams pick between sentence-level, paragraph-level, and sliding-window approaches, each of which carries different tradeoffs between precision and recall, latency, and completeness. None of them changes the pipeline’s core shape.
What RAG does not do is identify where the production problems live. Recent research cataloging 1,400+ papers on context engineering places RAG as one of several retrieval-layer techniques, alongside memory systems, tool-integrated reasoning, and multi-agent orchestration.
Those missing pieces are why building a RAG prototype and shipping a reliable AI system in production are two very different projects. One is a weekend build. The other needs context engineering.
What context engineering adds that RAG cannot provide
Permalink to “What context engineering adds that RAG cannot provide”Context engineering extends RAG by wrapping retrieval with governance. Where RAG asks “what is relevant?”, context engineering is asking something harder: what is relevant, trustworthy, lineage-traced, and policy-compliant?
Five capabilities separate a RAG prototype from a production context engineering system:
- Data quality gates
- Data lineage tracing
- Context products
- Memory management
- Agent orchestration
Getting all five right is what determines whether an AI system holds up under real enterprise load.
How do data quality gates filter context before it reaches the model?
Permalink to “How do data quality gates filter context before it reaches the model?”When a RAG pipeline hallucinates in production, the culprit is usually a chunk that was statistically relevant but factually stale. The fix is a data quality gate — a retrieval-time check that evaluates whether a chunk meets a minimum trustworthiness threshold before it enters the context window.
Freshness scores, completeness flags, validation status, known-bad markers — these are the signals a quality gate consults. A chunk from a table that has not been validated in six months is rejected, regardless of how close the embedding match is. It’s the defining move of context engineering: quality enforcement happens at retrieval time, not as downstream cleanup.
Empirical justification for this approach comes from Chroma Research’s July 2025 Context Rot report. Testing 18 frontier models, the team found that performance degraded non-uniformly as context grew. Perhaps counterintuitively, full conversation history performed worse than curated excerpts, even on simple retrieval tasks.
The takeaway: context should be treated as a finite, curated resource rather than a dumping ground.
Why does lineage matter for every context chunk?
Permalink to “Why does lineage matter for every context chunk?”Lineage answers the questions RAG cannot: which upstream system produced this chunk? Who owns it? When was it last validated? Did it pass quality checks? A standard RAG pipeline has no native way to answer any of these.
The value becomes obvious when something goes wrong. Imagine a model returning a confident but incorrect answer. A lineage-enabled system points immediately to the table, column, and pipeline stage that introduced the error. Strip that audit trail away, and you are left with the worst-case debugging scenario — where the retrieval matched semantically, the model sounded sure, and nobody can say why the output was wrong.
Finance, healthcare, and legal teams sit at one end of the spectrum here. They have to demonstrate that their AI outputs trace back to approved, governed data sources, which is why column-level lineage becomes the diagnostic layer that makes production AI debuggable.
What makes context products different from raw RAG chunks?
Permalink to “What makes context products different from raw RAG chunks?”Think of a context product as the managed counterpart to a raw RAG chunk. Each one is a curated bundle built for a specific AI use case, combining schema definitions, business glossary terms, ownership metadata, quality scores, and approved transformation logic into a single governed artifact.
The contrast with ad hoc chunks is stark. RAG chunks have no owner, no version, and no freshness SLA. A context product turns each retrieval unit into an owned, versioned, first-class asset that can be audited and rolled back like any other piece of enterprise software. Architects familiar with data mesh will recognize the pattern.
A context product is to an AI agent what a data product is to a business team, with the same ownership, SLA, and contract obligations.
Reproducibility is where this pays off operationally. If an AI analyst gave a wrong answer last Tuesday, a governed context system can recreate the exact context the model saw at that moment. A chunk-based RAG pipeline cannot, which is why regulated teams increasingly insist on context products for anything that touches production.
When to use RAG, full CE, or governed CE
Permalink to “When to use RAG, full CE, or governed CE”Three factors determine the right architecture: your data environment, your compliance requirements, and the complexity of your agent setup. RAG alone covers a narrow band of use cases. Full context engineering covers most production AI work. Governed context engineering is the baseline for regulated industries.
Here’s a decision framework on when to use RAG, full context engineering, or governed context engineering.
| Scenario | RAG alone | Full CE | Governed CE (with context layer) |
|---|---|---|---|
| Simple Q&A on a static, trusted corpus | Sufficient | Overkill | Overkill |
| Production AI analyst with live data | Fails | Required | Required |
| Multi-agent system with memory | Fails | Required | Required |
| Regulated industry (finance, healthcare, legal) | Fails | Insufficient | Required |
Here’s the reasoning behind the choices suggested:
- Static corpus, single agent, no compliance pressure: RAG handles this cleanly. An internal documentation chatbot running against a curated wiki is a fair example. The data rarely changes, the audience is internal, and there is no auditor to satisfy.
- Live data and multi-agent systems: Everything changes once the corpus starts updating hourly or daily. Staleness becomes the primary risk when chunks come from pipelines that move fast. If context has to persist across sessions without poisoning shared state, memory management enters the picture too. Agent orchestration adds another layer: knowing which context each agent saw, when it saw it, and why. None of that falls inside RAG’s scope, and all of it falls inside context engineering’s.
- Regulated industries: The bar goes up again here. Auditors want to see not just what was retrieved, but where it came from, who owns it, when it was last validated, and which policy it was subject to. Full-context engineering gets most of the way there, but a governed context layer closes the final gap — exactly why AI agents need an enterprise context layer, particularly in AI governance and traceability.
LangChain’s State of Agent Engineering survey (1,340 respondents, late 2025) found that 57.3% of organizations already run agents in production. Among teams with 10,000+ employees, the top-named challenges were hallucinations, output consistency, and “ongoing difficulties with context engineering and managing context at scale.” The failure mode is named as a context problem, not a retrieval problem.
Why RAG fails in production, and what the root cause actually is
Permalink to “Why RAG fails in production, and what the root cause actually is”RAG failures are usually due to data quality and governance issues, not to the retrieval algorithm. The vector search works exactly as designed and returns the chunk closest in embedding space to the query. Relevance and trustworthiness are two different properties, though. A perfectly relevant chunk can still be completely wrong if it is stale or pulled from a deprecated source.
Engineers often debug in the wrong place. Chunk sizes get tuned. Top-k gets adjusted. Rerankers get swapped, and new embedding models get tested. None of that touches the real issue. The algorithm did its job. The chunk it found happened to come from a deprecated report, and the retriever has no way to know the difference.
The gap shows up more clearly in code. Below are two versions of the same query. One runs a standard RAG pipeline; the other adds governance gates on quality, ownership, and lineage.
RAG without governance:
# Vector similarity search returns a relevant chunk with no quality or lineage check
def retrieve_context_rag(query: str, top_k: int = 3) -> list[str]:
query_embedding = embed(query)
results = vector_db.similarity_search(
embedding=query_embedding,
top_k=top_k,
index="financial_reports_2025"
)
# Returns the most semantically similar chunks
# No check: Is this data current? Who owns it? Did it pass validation?
# A chunk from a deprecated report is indistinguishable from a current one
return [r.text for r in results]
Context-engineered retrieval with governance:
# Retrieval gated on data quality score, ownership, and lineage metadata
def retrieve_context_governed(query: str, top_k: int = 3) -> list[str]:
query_embedding = embed(query)
candidates = vector_db.similarity_search(
embedding=query_embedding,
top_k=top_k * 3, # Over-fetch to allow governance filtering
index="financial_reports_2025"
)
governed_chunks = []
for chunk in candidates:
# Gate 1: Data quality score from the context layer
if chunk.metadata["data_quality_score"] < 0.9:
continue
# Gate 2: Ownership — only finance_team-owned data enters the context
if chunk.metadata["owner"] != "finance_team":
continue
# Gate 3: Lineage check — confirm the source table is active and validated
if not lineage_registry.is_active(chunk.metadata["source_table"]):
continue
governed_chunks.append(chunk.text)
if len(governed_chunks) >= top_k:
break
return governed_chunks
Examples use simplified pseudocode for illustration.
Notice what changed between the two. The retrieval algorithm is identical; the difference is an entire governance layer sitting around it. Quality scores, ownership metadata, and a lineage registry have to be computed and maintained somewhere for the second pipeline to work, and that somewhere is the context layer.
The business cost of this failure mode is real. LangChain’s State of Agent Engineering survey found that teams at organizations with 10,000+ employees name hallucinations and context management as their top production challenges. Each ungoverned retrieval call in a regulated workflow creates rework, a compliance risk, or both.
How Atlan governs the context engineering pipeline
Permalink to “How Atlan governs the context engineering pipeline”Atlan sits between the RAG retrieval layer and the LLM inference layer, acting as the governance proxy through which every context retrieval call flows. Before a chunk reaches the context window, Atlan evaluates four things: the data quality score for the source table, column-level lineage back to the origin, access policies, and freshness or validation status. The retrieval algorithm itself stays the same. What changes is what the retrieval is allowed to see.
Column-level lineage
Permalink to “Column-level lineage”Every context chunk can be traced from the LLM’s context window back to the originating column in the source system, including intermediate transformations.
When a model returns an incorrect answer, the lineage trail fills in the diagnostic blanks: which column, which table, which pipeline stage, which data owner. Debuggability replaces mystery.
Data quality gates
Permalink to “Data quality gates”Quality scores are computed at the column and table levels using active metadata, drawing on signals such as freshness, completeness, consistency, and known-bad flags. Context engineering pipelines then consume these scores as retrieval-time gates, the same pattern shown in the code example above.
Chunks from tables that fail the threshold never make it into the context window. In Atlan AI Labs pilots, customers like Workday saw up to a 5x improvement in AI analyst accuracy from this mechanism, which structured and governed the context that retrieval could access.
Context products and MCP
Permalink to “Context products and MCP”Rather than retrieving ad hoc chunks, an AI analyst using Atlan retrieves a context product, which is a versioned, governed bundle that includes schema definitions, business glossary terms, ownership metadata, and approved transformation logic.
These products are exposed through the Model Context Protocol (MCP), so any agent framework can consume them.
What role does active metadata play in context governance?
Permalink to “What role does active metadata play in context governance?”Quality signals, ownership changes, and lineage updates propagate in real time instead of through scheduled batch jobs. The moment a source table is deprecated, the context layer flags it, preventing any downstream context engineering pipeline from retrieving from it.
Most RAG pipelines fail in production precisely because this governance signal never reaches them in time. Explore active metadata management in detail.
Industry recognition reflects this design choice. Atlan was named a Leader in the 2026 Gartner Magic Quadrant for Data & Analytics Governance Platforms. Atlan’s own product strategy has been to build an active metadata infrastructure first, then extend it into context graphs and the Metadata Lakehouse for AI.
FAQs about context engineering vs RAG
Permalink to “FAQs about context engineering vs RAG”Is RAG dead, or is context engineering just a rebranding?
Permalink to “Is RAG dead, or is context engineering just a rebranding?”RAG remains a specific retrieval technique involving embedded queries, vector similarity search, and top-k chunk injection. Context engineering names the broader discipline that includes RAG alongside data quality governance, memory management, lineage tracing, and agent orchestration. The scope is different.
When does RAG fail, and when should I use context engineering instead?
Permalink to “When does RAG fail, and when should I use context engineering instead?”RAG breaks in four common situations. Chunks turn out stale or come from deprecated sources. Data lacks ownership and quality validation. State must persist across sessions, which RAG cannot do natively. Auditors require a traceable record of what the model saw. Any of these pushes you into context engineering. RAG alone fits a simple, static, trusted corpus with no compliance requirements.
Can I use RAG and context engineering together?
Permalink to “Can I use RAG and context engineering together?”The combination is actually the design intent. Context engineering does not replace the retrieval mechanism; it wraps retrieval with governance. A governed context architecture still relies on vector search and semantic retrieval to find relevant chunks, but it adds quality gates, lineage checks, and policy enforcement before any of those chunks reach the context window. Think of RAG as the retrieval mechanism and context engineering as the system that governs when and what RAG retrieves.
How does context engineering differ from a RAG pipeline with memory?
Permalink to “How does context engineering differ from a RAG pipeline with memory?”Memory by itself closes only one of the gaps. A RAG pipeline with memory becomes stateful across turns, which is useful, but it still lacks the other four capabilities that define context engineering: data quality gates to filter ungoverned chunks, data lineage to trace chunks back to source systems, versioned context products as managed retrieval units, and policy enforcement at retrieval time. Adding memory closes one of five gaps.
Is context engineering replacing RAG?
Permalink to “Is context engineering replacing RAG?”The more accurate verb is “enclosing.” Because context engineering is a superset, RAG remains the primary mechanism for semantic retrieval inside it, while the governance, memory, and orchestration layers simply wrap around that retrieval mechanism. The right question is not “RAG or context engineering” but “RAG as a standalone tool, or RAG as a governed component within a context engineering architecture?”
What are the limitations of RAG?
Permalink to “What are the limitations of RAG?”Five limitations consistently appear in production RAG deployments. Without data quality validation, relevant but stale chunks pass through unchecked. Without lineage, retrieved chunks cannot be traced back to source systems or owners. Memory fails to persist between sessions. Policy enforcement has to be bolted on externally. And retrieved context is never a managed, versioned artifact. Context engineering addresses all five.
What is RAG 2.0, and how does it relate to context engineering?
Permalink to “What is RAG 2.0, and how does it relate to context engineering?”Most teams use “RAG 2.0” as shorthand for RAG with reranking, query routing, or hybrid retrieval. All three are useful upgrades, but all three sit at the retrieval layer. A RAG 2.0 pipeline still lacks data quality gates, lineage, and policy enforcement. Context engineering operates at a different layer entirely, governing what retrieval is allowed to see in the first place.
Ready to build a governed foundation in 2026?
Permalink to “Ready to build a governed foundation in 2026?”RAG and context engineering are not in competition. The real choice is between a retrieval prototype and a production-ready AI system.
Return to the two code examples for a moment. Same query, same vector search, two entirely different levels of trustworthiness, because one is wrapped in a governance layer and the other is not. That layer is what converts a RAG pipeline from a demo into a deployable system, and it is the piece most teams underestimate when they move from proof-of-concept to production.
Explore the Context Engineering Studio, or start with context layer 101 for a framework-level view, to get started building a governed foundation.
Context engineering is where RAG stops being enough. WTF Is the Context Layer, a 42-page field guide, shows how accuracy stalls near 50 percent without a grounding layer, and the five stages to move past it.
