



















AI agents need an enterprise context layer because their failure in production is architectural, not cognitive. The model can reason — frontier models from OpenAI, Anthropic, and Google can plan, call tools, and chain multi-step workflows. What the model cannot do is know what “revenue” means in your organization, which customer ID is canonical across Salesforce and Snowflake, or whether the data it just retrieved is fresh. A context layer fills that gap by governing the metadata, definitions, lineage, and access policies that agents need at inference time. Capgemini found that 80% of organizations lack mature AI infrastructure — that infrastructure gap is where production agents break.
Here is the moment most builders recognize. Your agent passes 100 evals in development. It handles single-system questions cleanly, hits 95% accuracy on the test suite, and ships to staging. The 101st question crosses three systems, and the agent silently joins on the wrong customer key. There is no error in the logs. The number it returned looks reasonable. Three days later, the finance team flags the mismatch in a Slack channel.
The model did not get worse between question 100 and question 101. The architecture changed underneath it. That is the gap a context layer for AI agents closes.
Why is an enterprise context layer necessary for AI agents?
Permalink to “Why is an enterprise context layer necessary for AI agents?”For the program-level evidence on AI pilot failure rates and the business case for context infrastructure, see the companion executive piece on whether enterprises need a context layer between data and AI. What follows is the architectural question underneath those numbers, framed for the builders writing the agent code.
Two findings shape the technical case for an enterprise context layer in 2026.
Trust in autonomous agents is dropping while infrastructure stays immature. Capgemini Research Institute’s Rise of Agentic AI report found that trust in fully autonomous AI agents fell from 43% to 27% in a single year, and 80% of organizations lack mature AI infrastructure. Stronger models are not closing this gap. They are widening it, because more capable agents take on higher-stakes work where the cost of being confidently wrong rises with every deployment.
The token economy of production is dominated by context. Datadog’s 2026 State of AI Engineering report found that 69% of all input tokens in customer LLM traces are spent on system prompts, instructions, policies, and tool descriptions repeated on every call. Only 28% of LLM calls take advantage of prompt caching even when the underlying model supports it. Builders are already paying the price of in-prompt context. They are just paying for it inefficiently and without governance.
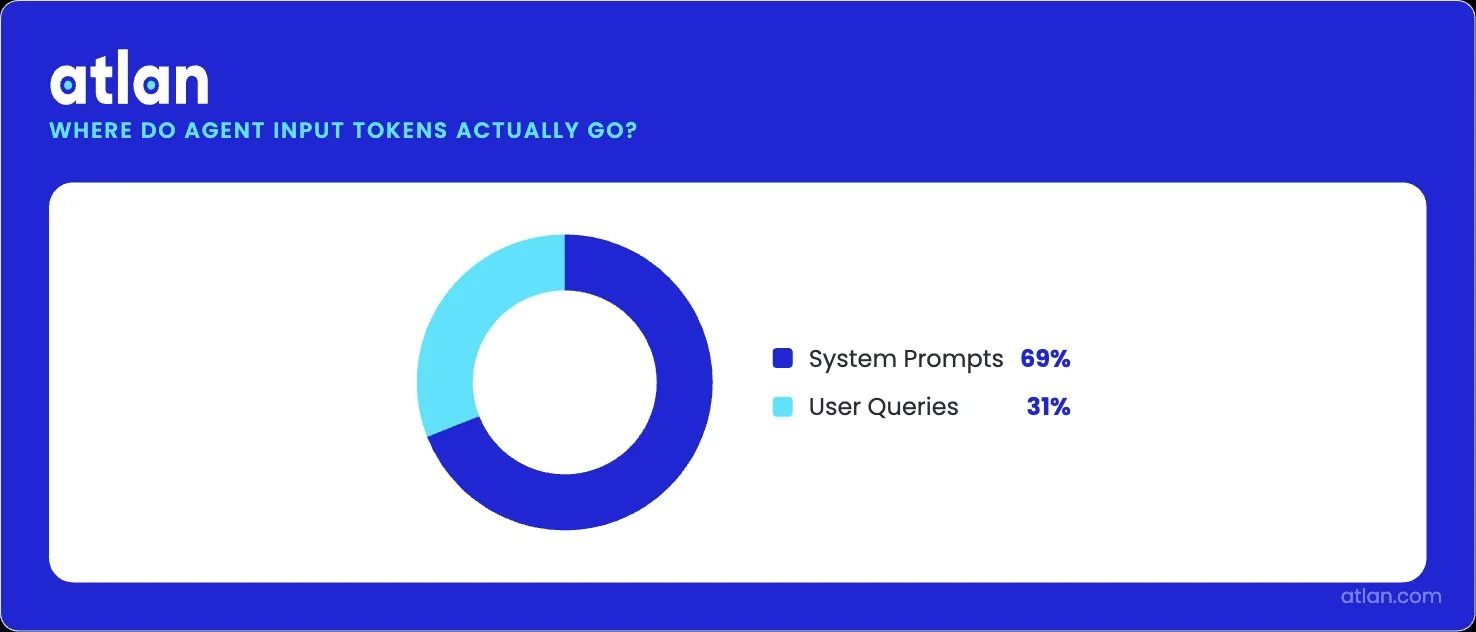
69% of input tokens are system prompts — context dominates over actual queries. Image by Atlan.
The technical case follows from these two findings. Models will keep getting better. The context they need to reason against will keep failing in the same ways. The fix has to live somewhere other than the model.
Governed context layer: measured results (Atlan AI Labs)
| Metric | Result |
|---|---|
| AI SQL accuracy lift | +38% relative (p < 0.0001) |
| Medium-complexity queries | 2.15x improvement |
| Descriptions generated, at scale | 1.7M+ across 50+ enterprises |
| Manual context work saved | 209,000+ hours |
Full benchmark: a 38% accuracy lift across 174 queries (522 evaluations). At-scale ROI: 209,000+ hours saved across 50+ enterprises.
Why do agents look smart in a demo and break in production?
Permalink to “Why do agents look smart in a demo and break in production?”Demos test reasoning on a small, scoped slice of data, while production tests reasoning against an entire enterprise’s worth of fragmented meaning, lineage, and policy. The first is a model problem; the second is a context problem. Most pilots clear the first bar comfortably and collapse on the second within weeks of going live.
Frontier models can plan, call tools, and chain steps better than they could two years ago. The agent has access to your warehouses, BI tools, tickets, and CRM. What it lacks is the durable knowledge that makes those systems make sense together. For example:
- Which definition of revenue does your CFO use?
- Which customer table is the source of truth?
- Which rows can the EU regulator see, and which decision has the upstream agent already made in this case?
Joe DosSantos, VP of Enterprise Data and Analytics at Workday, framed this directly during his Atlan Re:Govern keynote: “It’s no longer about documenting glossary terms in a tool. It’s about building a machine-readable layer of meaning. We’re talking about YAML files, complex mappings, connecting different AI agents and platforms.”
That distinction is the heart of it. Documentation is for humans. Agents need infrastructure that they can read at inference time.
The architectural decision points where pilots break
Permalink to “The architectural decision points where pilots break”Most builders shipping their first production agent hit the same three forks in the road. Each one looks like the right answer at the time. Some teams reach for better prompts, others assume RAG will handle the gap, and a third group bets on agent memory middleware. All three patterns work in dev. All three break in production at scale.
Fork 1: “We’ll just use better prompts.”
Permalink to “Fork 1: “We’ll just use better prompts.””The first context strategy lives in the system prompt. Tell the agent which table to use. Spell out the metric definition. Add a rule to disambiguate ARR from MRR. Repeat for the next agent and the next. The system prompt grows until it competes with the user’s actual question for the model’s attention.
This is the pattern Datadog’s data captures. When 69% of input tokens go to system prompts, the prompt has stopped being a configuration choice and has become the dominant input. New agents copy fragments of it. Definitions diverge between teams. Within a quarter, the patches contradict each other, and the original problem returns.
Anthropic’s engineering team has framed the way out as a generational shift: from prompt engineering, which is per-call and brittle, to context engineering, which configures the entire set of tokens an LLM sees at inference time and treats that as a system rather than a workaround.
Fork 2: “RAG handles this”
Permalink to “Fork 2: “RAG handles this””RAG was designed to address a specific problem. Find the relevant passage in unstructured text, pass it to the model. Enterprise agent questions are usually computational rather than retrieval-shaped. They span structured systems. They depend on definitions that live in nobody’s document.
RAG handles none of that natively. Stack RAG retrieval on top of an already token-heavy system prompt, and you get more retrieved context, mostly ungoverned and unversioned, often duplicating what a properly governed semantic layer would have encoded once. Atlan’s deeper comparison of AI memory systems versus RAG walks through where each pattern actually fits.
Fork 3: “Agent memory middleware will fix it”
Permalink to “Fork 3: “Agent memory middleware will fix it””Memory middleware does something useful, just not the thing enterprises usually need. It maintains session state. It holds working memory across turns. It makes a single agent feel coherent within a single conversation.
None of that gives the agent enterprise-accurate definitions, cross-system identity, or governed policies. Memory is scoped to the agent. A context layer is scoped to the business. The two solve different problems, and treating one as a substitute for the other is how production agents end up smart in conversation but wrong about the company.
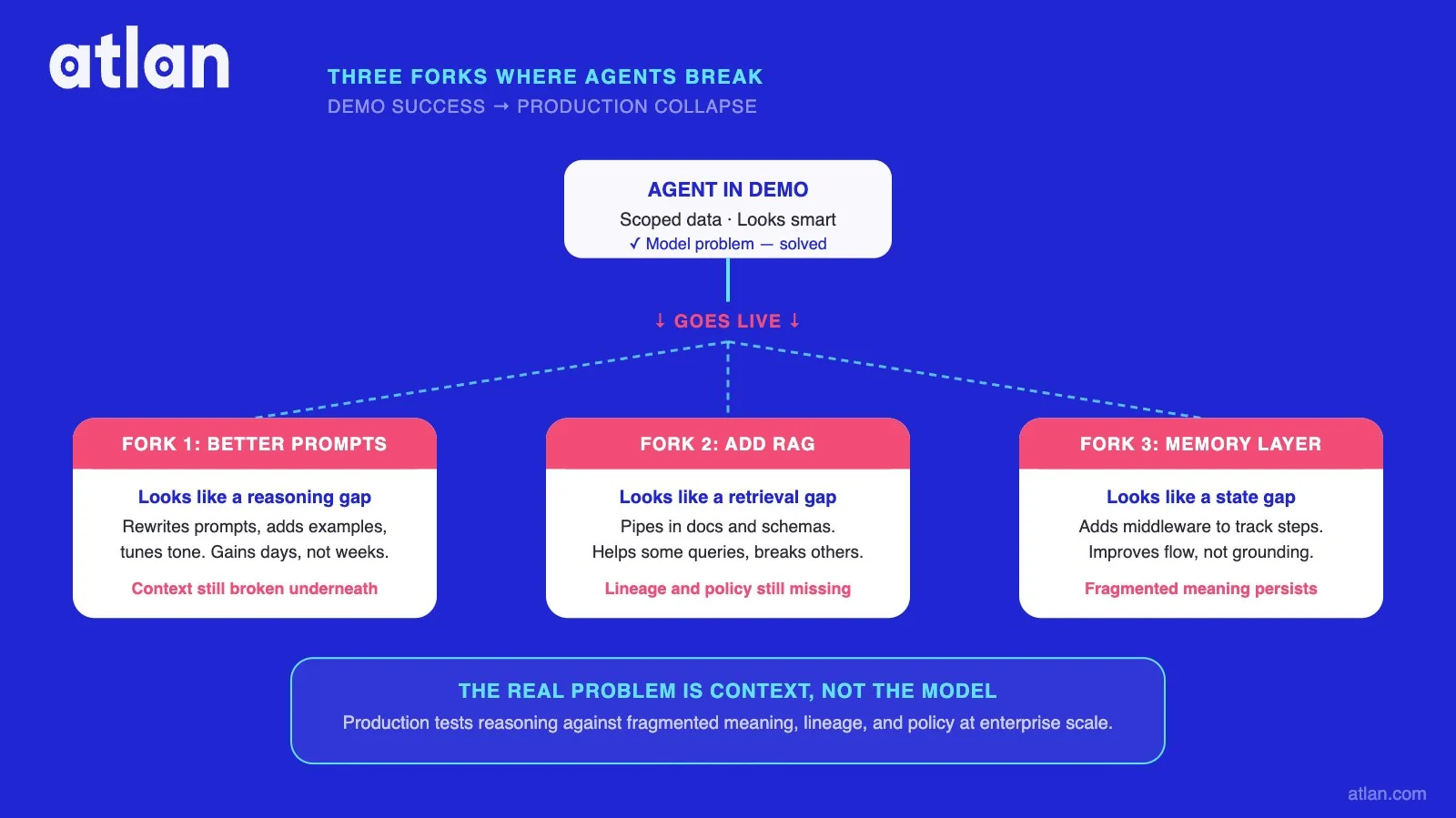
Where production agents diverge from demo success and silently fail. Image by Atlan.
In-window context engineering vs. governed context infrastructure
Permalink to “In-window context engineering vs. governed context infrastructure”The discourse on context has split into two camps. One refines the in-window technique. The other argues that the durable answer is governed metadata infrastructure. Both are real. Their scope is different.
In-window discipline ends at the edge of a single model call. The moment a multi-step agent hands off, switches platforms, or persists a decision past its session, in-window technique runs out of room. You can curate the perfect prompt and still hand the agent a definition of “Q3” that quietly uses the calendar quarter when your business runs on a fiscal calendar.
| Dimension | Context engineering (in-window) | Context layer (governed infrastructure) |
|---|---|---|
| Scope | The token window of one model call | The full enterprise data estate |
| Owners | Prompt engineers, agent developers, model labs | Data, governance, and platform teams |
| Durability | Lasts the length of one call or session | Persists across calls, agents, and models |
| Governance | Best-effort filtering inside the prompt | Policies enforced at the inference boundary |
| Cross-platform reach | Tied to whichever model is being called | Spans warehouses, BI, SaaS, and operational systems |
| Failure mode it solves | Token-level noise: poisoning, distraction, confusion | Meaning, lineage, identity, governance, and memory gaps |
A context layer does not pretend to fix everything. Model reasoning quality, latency, and runtime guardrails are adjacent concerns, each with its own tooling. The layer fixes the meaning gap.

Why agents succeed in demos but collapse in production at enterprise scale. Image by Atlan.
What you can’t fix from inside the agent
Permalink to “What you can’t fix from inside the agent”Some agent failures look like agent problems and turn out to be infrastructure problems. The signal is that the failure survives every fix you can ship from inside the agent itself.
A few patterns make the distinction concrete:
- The join succeeds. The keys match. The result is wrong because the two systems use the same column name for two different entities, and no governed mapping tells the agent which one applies.
- Your prompt patch works. A colleague’s prompt patch for a different agent contradicts it, and both ship to production. Six weeks later, the two agents return different answers to the same question.
- The MCP call returns metadata. The metadata is ungoverned, three months stale, and missing the policy flag that would have stopped the agent from reading restricted rows.
- The agent retrieves the right document. The document defines “active customer” one way. The semantic layer in your warehouse defines it another way. The agent picks one and moves on.
None of these failures is the model’s fault. None is fixable inside the agent runtime. They sit in the gap between the agent and the systems it queries, which is the gap a governed context layer is designed to close.
The architectural taxonomy that organizes them sits in Atlan’s agent context layer architecture guide.
MCP is the wire, not the meaning
Permalink to “MCP is the wire, not the meaning”A context layer is only as useful as the protocol that delivers it. The Model Context Protocol (MCP) is the open standard for serving governed context to agents at inference time, and Agent2Agent (A2A) handles handoffs between agents in a multi-step workflow.
Anthropic introduced MCP in November 2024 and donated it to the Linux Foundation’s Agentic AI Foundation in December 2025 with co-stewardship from Block and OpenAI. A2A handles the other half, carrying decisions and reasoning between agents in a multi-step workflow without dropping state.
Speaking at the Gartner Data and Analytics Summit 2026, analyst Andres Garcia-Rodeja predicted that 60% of agentic analytics projects that rely solely on MCP will fail by 2028 due to the lack of a consistent semantic layer beneath. MCP moves context. It does not produce it.
There’s no doubt that MCP is necessary. But it’s not sufficient. A layer that cannot serve a governed context over MCP needs a bespoke integration per agent stack, which folds back into the platform-native trap. A layer that speaks MCP shows up as governed context in ChatGPT, Claude, Copilot Studio, Cursor, Cortex, Genie, Agentspace, and AgentCore on the same day, with the same definitions, lineage, and policies.
What changes when agents have shared context
Permalink to “What changes when agents have shared context”An agent grounded in a governed enterprise context layer stops guessing at meaning and starts working from a single, auditable version of the business. The behaviors that change are concrete. It picks the right metric definition. It knows when its data is stale. It respects policy at the agent boundary. It carries decisions across multi-step workflows without losing them.
The evidence that this moves the needle is no longer thin. Three independent benchmarks now point in the same direction.
- Snowflake reported that adding a plain-text data ontology to its agent stack improved final-answer accuracy by 20%, reduced average tool calls by 39%, and cut end-to-end latency by 20% against a best-practices baseline.
- Atlan’s controlled study across 522 evaluations and 174 unique queries showed a 38% relative improvement in AI SQL accuracy with enriched metadata, and a 2.15x lift on medium-complexity queries.
These are not model-tuning gains. They are the kind of accuracy lift that shows up when agents query a governed context layer for AI agents instead of raw data, measured across three independent setups by three different teams.
Do smarter models actually fix the context problem?
Permalink to “Do smarter models actually fix the context problem?”Sharper models do not fix bad context. They make its consequences harder to detect. Hallucinations stop looking obviously wrong and start looking institutionally wrong, which is the worst kind of error a finance, risk, or compliance team can chase.
The smaller the error, the longer it lives in the business before anyone discovers it. A weaker model produces obviously wrong answers that humans catch quickly. With a stronger model, the answers look correct, get pasted into reports, and live in the business for days.
Better models raise the cost of bad context. They do not lower it. Governance becomes more urgent as model capability grows, not less.
How Atlan grounds agents in the enterprise context
Permalink to “How Atlan grounds agents in the enterprise context”Enterprise AI teams are scaling agents across heterogeneous estates, and pilots are stalling. The blocker sits between what an agent has access to and what it actually understands. Four shapes of the same problem usually show up at once:
- Definitions differ across platforms, with no canonical version
- Lineage is invisible at inference time, so the agent cannot detect staleness
- Identity remains unresolved across systems with mismatched keys
- Policies live behind warehouse perimeters, not at the agent boundary
Production agents need all four fixed together. Fixing one without the others moves the bottleneck rather than removing it.
Atlan grounds agents in a governed, cross-platform enterprise context layer. The platform unifies definitions, lineage, ontology, identity resolution, and decision memory across 100+ native connectors covering warehouses, BI tools, SaaS, and operational systems. The same context layer serves any model or runtime over MCP.
Sridher Arumugham, Chief Data and Analytics Officer at DigiKey, described how this shows up in a builder’s stack during his Atlan Re:Govern keynote: “Atlan enabled us to easily activate metadata for everything from discovery in the marketplace to AI governance to data quality to an MCP server delivering context to AI models. It’s not about documenting data after the fact. It’s about unifying, collaborating on, and activating context wherever it’s needed using Atlan.”
The accuracy gains are measurable in production. In the controlled study referenced earlier, enriched metadata produced a 38% relative improvement in AI SQL accuracy (p < 0.0001), with a 2.15x lift on medium-complexity queries. Across separate Atlan AI Labs experiments using bounded, scoped context layers, results showed up to a 5x improvement in AI analyst accuracy compared to the baseline. The decision builders are making is not “do we add context?” It is “do we govern it.”
Ready to ground your agents? See how Atlan delivers governed context to any agent over MCP. Book a demo.
FAQs about why AI agents need an enterprise context layer
Permalink to “FAQs about why AI agents need an enterprise context layer”When should I suspect a context problem versus a model problem?
Permalink to “When should I suspect a context problem versus a model problem?”Model problems show up in reasoning. The agent picks a clearly wrong approach, misreads a prompt, or fails to chain steps that any competent human would chain. Context problems show up in the answer. The reasoning is sound, the SQL is clean, the tool calls execute, and the output is still wrong.
Can I build a context layer in-house?
Permalink to “Can I build a context layer in-house?”You can, and many teams start by trying. The work is straightforward in scope and hard in maintenance. A context layer is not a project that finishes. The business will keep changing, definitions will evolve, new systems will land, new agents will need new slices of context. The engineering cost of keeping the layer current is what most teams underestimate, not the cost of building the first version.
How does this work with my existing dbt semantic models?
Permalink to “How does this work with my existing dbt semantic models?”A dbt semantic layer governs metrics for analytics within its perimeter. A context layer extends beyond it to include cross-system identity resolution, governance policies enforced at the agent boundary, lineage spanning systems above and below dbt, and decision memory. The dbt models become one input to the context layer, not a substitute for it. The semantic models you already have are reusable, not redundant.
What is the runtime cost of querying a context layer at inference?
Permalink to “What is the runtime cost of querying a context layer at inference?”Latency depends on the architecture. A well-designed context layer serves at inference speed in milliseconds because the heavy work, ontology resolution, lineage tracking, policy evaluation, has already happened upstream. Agents query a precomputed, continuously updated graph rather than reasoning over raw metadata at request time. Snowflake’s published numbers show end-to-end latency dropping by 20% when the agent queries an ontology rather than raw data, in part because the agent makes 39% fewer tool calls.
Does a context layer help with unstructured data?
Permalink to “Does a context layer help with unstructured data?”Yes, but indirectly. Unstructured data still flows through retrieval mechanisms like vector search. The context layer governs what those mechanisms surface. It enforces which documents an agent can access, attaches lineage to the retrieved content, and maps unstructured assets to the same canonical entities used for structured queries. RAG within a governed context layer is a useful pattern. RAG without one tends to amplify any inconsistencies already present in the corpus.
Why isn’t a stronger model enough?
Permalink to “Why isn’t a stronger model enough?”Because the failure modes are architectural rather than cognitive. A stronger model will join on the wrong key faster. Hallucinations of right-sounding metric definitions become more convincing, not less. Confidently wrong answers survive human review longer because they read as authoritative. The cost of bad context goes up with model strength, not down. This is the central reason why governance becomes more urgent as model capability grows.
Can platform-native context like Cortex or Unity Catalog replace a cross-platform context layer?
Permalink to “Can platform-native context like Cortex or Unity Catalog replace a cross-platform context layer?”Not for an enterprise. Most enterprises run three to five data platforms plus BI, SaaS, and operational systems. Platform-native context covers only its own perimeter, which leaves agents blind to most of where the business actually lives. Cross-system questions are where production agents earn their keep, and those are exactly the questions a single-platform context layer cannot answer.
If we already serve metadata over MCP, do we still need a context layer?
Permalink to “If we already serve metadata over MCP, do we still need a context layer?”Yes. MCP is the wire that carries context to your agents. It does not produce, govern, or version the context itself. A context layer is what travels over the wire. Without governed definitions, identity resolution, and policy enforcement underneath, an MCP server returns whatever metadata happens to exist in the source systems, including stale definitions, unresolved entity IDs, and ungoverned access.
Next steps for your stack
Permalink to “Next steps for your stack”The agent in the opening of this article is not unusual. It is what happens when production reasoning runs over an architecture built for human consumers and never updated for machine consumers. The next agent your team ships will hit the same wall unless the layer beneath it is governed.
Two paths forward exist for builders. The first is to keep the current pattern, where each new agent ships with its own system prompt, its own brittle joins, its own copy of the same definitions, and its own debugging cycle when production diverges from staging. The second is to invest once in a substrate that every agent reads from, where definitions get certified once and reused everywhere, and where adding the next agent is a configuration step instead of a re-implementation.
The second path is where the compounding returns live. A context layer your team builds for the agent shipping today is the same layer the agent shipping next quarter inherits, and the agent after that, and every agent across the enterprise that follows.
Sources
Permalink to “Sources”- Rise of Agentic AI Report (Web Version), Capgemini Research Institute (July 2025)
- State of AI Engineering 2026, Datadog
- Agent Context Layer for Trustworthy Data Agents, Snowflake Blog
- Effective Context Engineering for AI Agents, Anthropic Engineering
- Re:Govern Opening Keynote — Joe DosSantos, Workday, on building machine-readable meaning, Atlan Re:Govern Watch Center
