



















A context engineering framework is a structured system for building, governing, and delivering context to AI agents. Most teams treat context as a prompt engineering problem. It is an infrastructure problem: the quality of what agents know at inference time depends on how the underlying metadata layer is built, governed, and kept current. A framework gives that infrastructure a repeatable shape. Atlan’s Context Engineering Studio is where this framework is built: an IDE where AI builders design context repositories, define Skills files, run simulated test scenarios against real business questions, and ship agents that are grounded in governed organizational knowledge before they go live. Atlan’s Context Engineering Studio operationalizes this framework with four named components: a metadata IDE for designing context repositories, Skills file tooling for defining agent knowledge boundaries, a simulation harness for testing agents against real business questions before launch, and a governed MCP server that delivers context to production agents at inference time.
Context engineering framework: overview table
Permalink to “Context engineering framework: overview table”| Attribute | Detail |
|---|---|
| What it is | A 5-phase system for building, governing, and delivering context to AI agents |
| Phases | Phase 0: Inventory • Phase 1: Integration architecture • Phase 2: Context products • Phase 3: Orchestration • Phase 4: Governance and lifecycle |
| Best for | Enterprise data teams deploying AI analysts, copilots, or autonomous agents against governed data |
| Implementation time | 4 to 16 weeks, depending on existing metadata maturity and integration surface area |
| Who owns it | Data engineering and data platform teams, with governance co-owned by data governance or the CDO office |
| Complementary tools | Data catalog, business glossary, MCP-compatible connectors, context orchestration layer, metadata lakehouse |
A context engineering framework treats context as a first-class data product with versioning and tests, which separates it cleanly from prompt engineering.
Enterprise adoption is running ahead of most data teams’ awareness. In a keynote speech at Atlan’s Re: Govern 2025, Prukalpa Sankar, Co-founder of Atlan, mentioned, “83% of organizations are actively experimenting with AI, yet only 17% are able to drive value. Data quality, governance, and disconnected systems act as a major barrier.”
Context engineering solves it. If you’re new to the discipline, Context layer 101 is a good starting point.
Why enterprise AI agents fail without a context engineering framework
Permalink to “Why enterprise AI agents fail without a context engineering framework”Enterprise AI agents fail because of a trust gap, not a model gap. Semantic layers define metrics but cannot verify them at runtime. Teams then pay a translation tax moving tribal knowledge into agent-ready context, and the missing infrastructure shows up as attention-budget waste, metadata staleness, and broken reuse.
A context engineering framework attacks the problem at the architecture layer.
A new discipline, named by practitioners
Permalink to “A new discipline, named by practitioners”The shift from prompt engineering to context engineering did not come from a vendor marketing team. It came from practitioners shipping production systems. Shopify CEO Tobi Lütke described it as “the art of providing all the context for the task to be plausibly solvable by the LLM.”
Talk to any data team running agents in production, and you hear the same pattern. The model looks fine on its own. Paste the same query into Claude or GPT-4 directly, and you get a reasonable answer. Wire it up to the company’s data, and the agent starts hallucinating metrics, confusing entities, and answering confidently about questions it has no business answering. Your team spends a week tuning prompts, only to find the problem is upstream.
The trust gap: clean data is not trustworthy data
Permalink to “The trust gap: clean data is not trustworthy data”The underlying issue is a trust gap. Most enterprises have clean data, but not trustworthy data. A semantic layer can tell you that “Revenue = Sales − Refunds,” but it cannot tell you whether to trust that number today, whether the upstream pipeline broke last night, or whether the dashboard pulls from a deprecated table.
Your AI agent needs more than definitions. It needs to know who owns the data, how up-to-date it is, and whether it contains PII. Skip this judgment infrastructure, and agents produce fluent, confident, wrong answers. It leads to the failure of enterprise AI when there’s no context layer.
Related: Why you need context and a semantic layer for enterprise AI
Mastercard’s “Starbucks example” makes the gap concrete. A credit card statement might include a transaction string such as TST * STBKS 767. An AI agent treating that as gibberish does nothing useful with it. Attach context and the same string resolves cleanly: TST means Toast (the payment facilitator), STBKS means Starbucks, and 767 identifies a specific Seattle store. Same model. Different context layer.
The translation tax and shadow context layers
Permalink to “The translation tax and shadow context layers”Teams without a framework pay what’s sometimes called a translation tax. AI teams spend continuous effort manually translating human-focused metadata into the operational context models need: does this metric lag by 30 days, did the calculation method change recently, are there customer segments where the data is systematically unreliable? That information rarely lives in the catalog. It lives in Slack threads, meeting notes, and senior engineers’ memories, and every new AI project restarts the hunt.
Teams that try to route around the tax build shadow context layers: feature stores, model cards, internal wikis. Those parallel systems eventually contradict the data team’s catalog, so stakeholders get different answers about whether the same AI recommendation is trustworthy depending on which system they consult.
Find out why enterprise AI fails without a context layer.
Attention budget, metadata staleness, and context reuse
Permalink to “Attention budget, metadata staleness, and context reuse”Anthropic calls the model-layer version of this an attention budget problem.
Adding a token to the context pulls weight away from every other token, and transformer models pay closer attention to what sits at the start and end of the window than to material buried in the middle. Context is a limited resource, and effective context engineering is the discipline of using it well, as their engineering team puts it. Stuff the window with raw documents, and you spend the budget on noise.
Metadata staleness makes all of this worse month by month. Source systems change, schemas drift, owners move teams, and business definitions change during quarterly close. Skip active metadata management, and your context products keep serving the pre-change version, which means your agent keeps producing wrong answers that everyone logs as model hallucinations.
Reuse is the third failure. Without a framework, every new agent kicks off a fresh context build with no shared versioning, no test suite, and no governance gate. Stanford and SambaNova’s ACE (Agentic Context Engineering) framework identified two specific failure modes that follow from this: brevity bias and context collapse, in which iterative rewrites slowly erode the detail that made the context useful to begin with.
As Phil Schmid summarized the research, ACE’s structured approach uses a Generator, Reflector, and Curator to build context as accumulated knowledge rather than rewriting prompts from scratch. That structured approach delivered a 10.6% gain on agent benchmarks, 8.6% on financial reasoning, and reduced adaptation latency by 86.9% compared to methods that rewrite full prompts.
The latency number matters for your Phase 2 design choices. Delta updates beat rewrites at scale, which is exactly what versioned context products enable.
The enterprise stakes
Permalink to “The enterprise stakes”MIT’s NANDA study of 300 enterprise AI deployments found 95% of GenAI pilots delivered no measurable P&L impact, with contextual learning and integration identified as the missing ingredient.
Box CEO Aaron Levie names the mechanism behind those numbers more directly. He has called context engineering “the long pole in the tent for AI Agents adoption in most organizations”, arguing that the race to deliver the right context for any given workflow is what separates the winners from the losers in enterprise AI. His diagnosis maps onto the failure modes above: fragmented enterprise data, misaligned access controls, and poor decisions about what belongs inside the context window versus what should sit behind retrieval.
A framework attacks the problem at the architecture layer, where the problem truly lives. For a deeper view of the underlying layer that a framework activates, see the enterprise context layer.
The 5-phase enterprise context engineering framework
Permalink to “The 5-phase enterprise context engineering framework”The framework gives data teams a repeatable path from raw metadata to agent-ready, governed context products. Where it starts matters. Most published frameworks begin at the integration or orchestration layer, but this one begins at Phase 0, inside the data catalog, because your agent needs institutional data definitions before any model sees the query.
Each phase produces a discrete output, and the phases themselves stay testable, auditable, and implementation-agnostic.
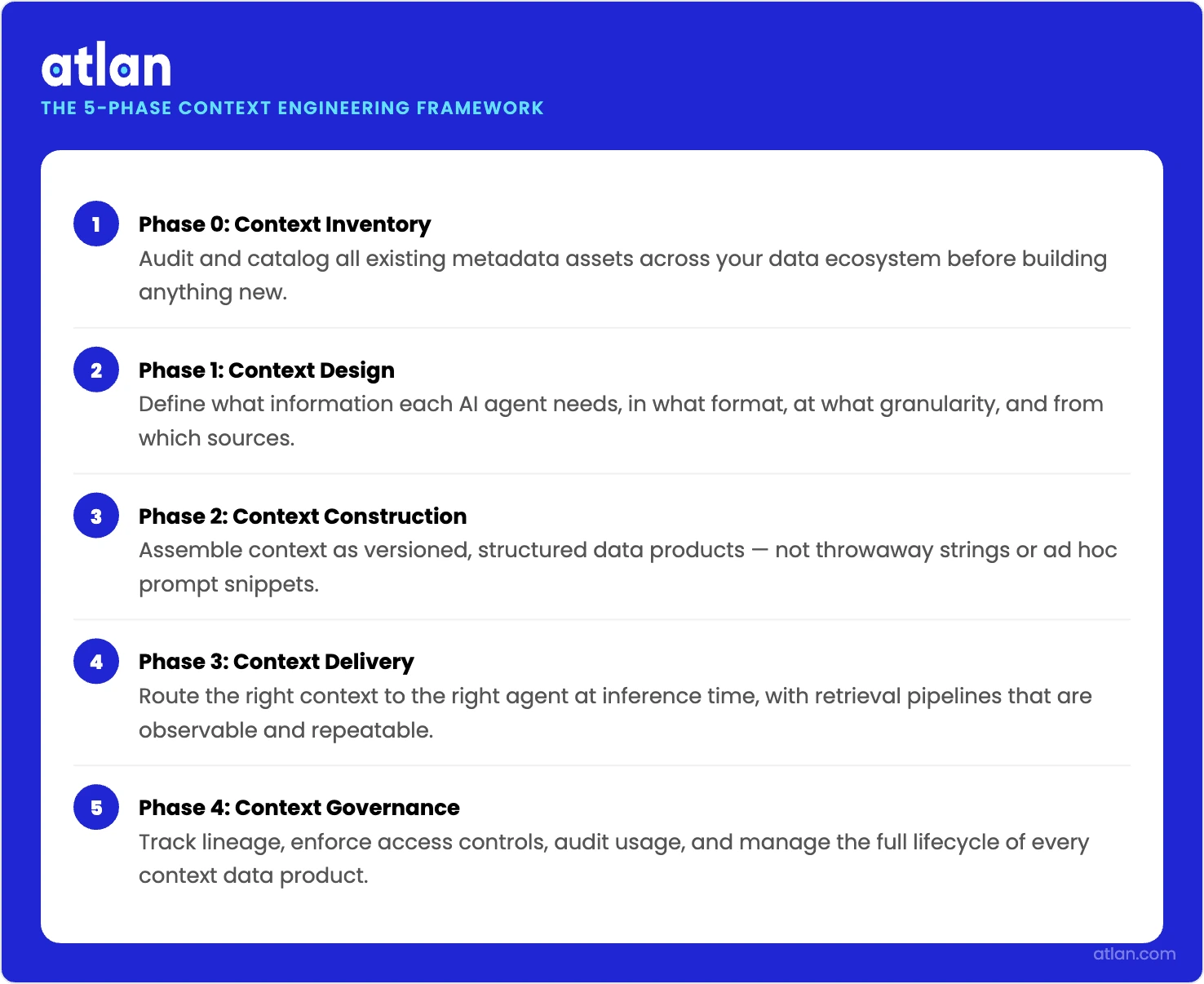
How enterprise teams govern what AI agents see before they reason. Source: Atlan.
Phase 0: Context inventory, starting in your data catalog
Permalink to “Phase 0: Context inventory, starting in your data catalog”Phase 0 is where you map every metadata asset an AI agent could reasonably use. It includes business glossary terms, column-level lineage graphs, data quality rules, ownership records, and certified dataset labels. Most enterprise teams already have 60 to 80 percent of this sitting in their catalog.
The gap is not discovery. Nobody has packaged any of it for an AI agent to consume yet.
What to do:
- Export every active business glossary term with its definition, owner, and related asset links.
- Pull column-level lineage graphs for your top 20 analytical entities: revenue metrics, customer identifiers, product taxonomies.
- Document the data quality rules attached to each certified dataset.
- Tag assets by domain and consumption tier: trusted, experimental, or deprecated.
- Produce a single context asset inventory covering term name, definition, source table or column, owner, and certification status.
Who owns it: The data catalog engineer or metadata engineer runs Phase 0, with the data governance lead reviewing before sign-off.
| Example: Business glossary term: recognized_revenue_q4definition: “Revenue recognized in Q4 per ASC 606, excluding deferred and contingent items” source_column: finance_reporting.revenue_facts.recognized_amountowner: “Finance Data Team” certification_status: “certified” related_terms: [ arr, mrr, deferred_revenue] |
|---|
Once that term ships as context, an AI analyst fielding a Q4 revenue question already knows the accounting definition before it starts reasoning.
Output artifact: A cataloged, prioritized list of business glossary terms, lineage-linked columns, and quality rules ready for context packaging.
Column-level lineage earns its spot because it answers two questions at once: what a field means and where the field came from. Quality rules on those assets tell the agent which data to trust and which to flag. Certification status serves as a weight of trust at inference time.
For the structural view of how these assets connect, see the context graph.
Phase 1: Context integration architecture
Permalink to “Phase 1: Context integration architecture”Phase 1 sets up how metadata assets move from their sources into the context layer. The work covers API design, connector configuration, and pipeline schemas. Your goal: extract glossary terms, lineage graphs, and quality rules, normalize them to a single schema, and land them somewhere agents can query at inference time.
What to do:
- Define the canonical context schema: the standard representation of a context object covering term, definition, source, owner, version, and expiry.
- Configure connectors for each metadata source: the data catalog API, BI tool metadata, the dbt semantic layer, and any other upstream systems that produce context.
- Design extraction pipelines with a defined refresh cadence: Event-driven beats batch. Daily is the minimum if you have to go in batches.
- Stand up the context registry: A queryable index of every context object by type and domain.
- Validate that the connector output: Match the canonical schema before you promote anything to Phase 2.
Who owns it: The data platform engineer or integration architect builds Phase 1, with the data engineering lead reviewing connector configurations.
# Example connector configuration
connector:
source: atlan_catalog
endpoint: "https://your-tenant.atlan.com/api/meta/v2/entity/bulk"
auth: bearer_token
extract:
entity_types: [GlossaryTerm, Column, Table]
filters:
certification_status: [VERIFIED, DEPRECATED]
domain: [finance, customer, product]
output_schema:
term_id: string
term_name: string
definition: string
source_qualified_name: string
owner: string
version: semver
last_updated: timestamp
refresh_cadence: event_driven
fallback_cadence: "0 2 * * *" # daily at 2am UTC
Output artifact: A context integration spec with documented connectors, pipeline schedules, canonical schema definitions, and a populated context registry carrying the initial load.
The Model Context Protocol (MCP) is fast becoming the standard transport layer for this work. Event-driven refresh incurs an extra engineering cost because metadata staleness compounds in Phases 2 and 3. Connector output schemas need versioning too. An upstream schema change will otherwise break Phase 2 packaging the moment someone ships a new context product.
A mental model from LangChain makes the next few phases easier to reason about. Context at runtime pulls from three distinct layers:
- Durable state holds the persistent record of what the agent knows across sessions.
- A long-term store keeps reusable knowledge, such as glossary terms and lineage graphs.
- Per-call runtime context is the specific information your system injects for the current query.
Phase 1 populates the store. Phase 3 decides what moves from the store into runtime. Keeping the three layers separate is what makes the framework debuggable when something breaks in production. Phil Schmid frames context engineering as carefully constructing the information environment, and Phase 1 is where you do that construction work.
For the product layer that automates most of this, see Context Engineering Studio.
Phase 2: Context products, packaging context as governed artifacts
Permalink to “Phase 2: Context products, packaging context as governed artifacts”A context product is a versioned, tested, governed bundle of context. A raw metadata export is not one. Phase 2 takes the registry built in Phase 1 and assembles bundles aimed at specific query patterns. Your finance context product might carry recognized_revenue_q4 along with its lineage columns and quality thresholds.
Every bundle earns a version and passes certification before any agent touches it.
What to do:
- Define context product schemas by domain — finance, customer, product, operations, and so on.
- Pick the glossary terms, lineage paths, and quality rules that belong in each bundle.
- Write unit tests: does the product answer its target query type correctly?
- Assign a version like
finance_glossary_v3and a named owner to every product. - Publish certified products to the context lakehouse with metadata tags.
Who owns it: The domain’s data product owner runs Phase 2. The data engineering lead signs off on publication. Data governance reviews certification.
# Example Context Product: finance_glossary_v3
version: 3.1.2
domain: finance
terms: [recognized_revenue_q4, arr, deferred_revenue, net_revenue_retention]
lineage_refs: [finance_reporting.revenue_facts.*, finance_reporting.arr_daily.*]
quality_rules: [revenue_completeness_check, arr_reconciliation_rule]
owner: finance-data-team
certification: VERIFIED
expiry: 2026-07-01
test_coverage: 94%
Output artifact: A context product catalog — a versioned library of certified, domain-specific bundles stored in the metadata lakehouse, ready for Phase 3 routing.
Context products are reusable across agents. The same finance_glossary_v3 can serve the AI analyst, the CFO copilot, and the audit agent without anyone rebuilding it three times. Versioning lets your agents pin to a specific release for reproducibility. Treat a target like 80% test coverage as a gate to keep ungoverned context out of production. Expiry dates force review cycles so stale content does not pile up.
It improves response accuracy when you move from ad hoc prompt injection to governed context products.
Phase 3: Context orchestration, routing the right context at inference time
Permalink to “Phase 3: Context orchestration, routing the right context at inference time”Orchestration is the runtime layer. A query comes in, the orchestrator classifies the intent, and the matching context product loads before the model reasons. Skip this layer, and your agents end up with either too much context (wasting the attention budget) or too little (producing hallucinations).
Good orchestration makes context selection dynamic, domain-aware, and token-efficient.
What to do:
- Build a query classification layer that identifies domain intent from an incoming query.
- Map intent categories to context product IDs in a routing table.
- Implement a retrieval-augmented generation (RAG) step that pulls the matched product from the lakehouse.
- Prune context before injection, stripping sections not relevant to this query.
- Log every routing decision for the audit trail and Phase 4 lifecycle feedback.
Who owns it: The data platform or AI infrastructure engineer owns Phase 3. Domain data product owners review the routing rules.
# Example routing logic
def route_context(query: str, context_registry: ContextRegistry) -> ContextProduct:
"""
Classify query intent and retrieve matching context product.
"""
intent = classify_query_intent(query)
# Example: query = "What was recognized revenue in Q4?"
# intent.entities = ["revenue", "q4"]
# intent.domain = "finance"
if "revenue" in intent.entities and intent.domain == "finance":
return context_registry.get(
product_id="finance_glossary_v3",
version="latest_certified"
)
elif intent.domain == "customer":
return context_registry.get(
product_id="customer_context_v2",
version="latest_certified"
)
else:
return context_registry.get_default(domain=intent.domain)
When the query maps to the revenue entity in the finance domain, orchestration pulls finance_glossary_v3, which already carries recognized_revenue_q4 and its lineage. All of that loads before the model sees the question.
Output artifact: A deployed classification and retrieval service that selects and injects context products into the agent pipeline at runtime, plus a routing log that makes every decision auditable.
Orchestration unlocks multi-hop reasoning across the context graph downstream. An agent handling “What was last month’s revenue in EMEA?” does not guess which table to query. It walks relationships. The agent starts at the “revenue” glossary term for the canonical definition, hops to entity mappings that translate “EMEA” into a specific region filter, then traverses to the certified tables linked to that term. Shadow and test assets drop out of the path automatically.
Before generating an answer, the agent runs trust checks. It verifies freshness edges, reviews quality signals, and traces lineage through DBT models to confirm how the metric was derived. The agent also checks classification edges against user permissions, and PII tags propagated through lineage dictate which columns the agent can expose. What comes back is SQL that is accurate, not just syntactically clean.
Why does orchestration carry this much weight? The mechanics sit at the transformer level. Attention scales quadratically, meaning n tokens in context generate roughly n² pairwise relationships, and every new token dilutes attention across all the others. Position bias makes things worse. Models weigh content at the start and end of the window more heavily than anything buried mid-context.
Practitioners now have a name for this degradation: context rot. Chroma’s 2025 research on 18 frontier models found the degradation is not gradual either. Quality drops sharply well before advertised window limits.
Phase 3 orchestration is the architectural answer to context rot. The layer routes in only the certified context product the query needs, rather than filling the window with raw documents that the agent has to fight through.
Good orchestration pushes back on transformer-level limits. It respects token budgets, front-loads the most relevant content, prunes deprecated or off-domain material, and retrieves structured products rather than raw document chunks.
Phase 4: Context governance and lifecycle
Permalink to “Phase 4: Context governance and lifecycle”Phase 4 closes the loop. Your context products move through a defined lifecycle: tested, promoted, deprecated, and eventually retired. A product with an expired business rule or a renamed source column becomes a liability the moment it ships. The product then injects wrong information at scale into every agent consuming it.
Lifecycle governance keeps production agents running on a context that matches current data definitions.
What to do:
- Set expiry dates and review cadences on every certified product; quarterly review is the floor.
- Build an automated staleness detection that flags products when source columns or glossary terms change upstream.
- Define a promotion pipeline: draft, reviewed, certified, deprecated, retired.
- Run context product tests on CI/CD; break the pipeline when a product fails its suite.
- Maintain an audit log capturing which agents consumed which product version at which timestamp.
Who owns it: The data governance and data engineering leads co-own Phase 4. Automated monitoring is handled by the data platform team.
# Example lifecycle policy
context_product_lifecycle:
product_id: finance_glossary_v3
current_version: 3.1.2
status: CERTIFIED
review_date: 2026-07-01
staleness_triggers:
- source: "finance_reporting.revenue_facts.recognized_amount"
change_type: [column_rename, schema_change, definition_update]
action: auto_flag_for_review
promotion_history:
- "version: 3.0.0 → 3.1.0: added net_revenue_retention term (2026-02-14)"
- "version: 3.1.0 → 3.1.2: updated recognized_revenue_q4 ASC 606 definition (2026-03-01)"
deprecation_policy: "No agent may consume a context product version older than 90 days without re-certification"
Output artifact: A context governance policy plus an automated lifecycle pipeline, which together form a documented, enforced process for versioning, testing, and deprecation with a full audit trail.
Active metadata management automatically runs Phase 4 instead of relying on manual review cycles. Teams that skip this phase watch their context products rack up technical debt faster than almost any other data asset. Agents silently consume stale context, and the error compounds across every downstream agent.
Who owns context engineering in an enterprise data team?
Permalink to “Who owns context engineering in an enterprise data team?”Context engineering sits between data engineering and AI deployment, and ownership gets messy in almost every organization that tries to stand it up. Data engineering owns the infrastructure and pipelines. The data governance office or CDO owns business definitions and certification standards. AI and ML engineers own the agent-side consumption layer. Nothing ships unless the three of them coordinate, and nothing stays reliable in production unless they keep coordinating.
In practice, the data engineering leader usually ends up as the primary owner of the framework infrastructure. At organizations with a CDO, governance of context products typically reports to that office. Smaller teams consolidate Phases 0 through 3 under a single context engineer or AI platform engineer role. AI and ML engineers often own Phase 3 orchestration even when data engineering owns the underlying registry. Misaligned ownership at Phase 4 is the single most common reason context products go stale in production.
A quick overview of who owns context engineering in an enterprise data team:
| Phase | Data engineering | Data governance | AI/ML engineering | Data product owner |
|---|---|---|---|---|
| Phase 0: Context inventory | Accountable | Responsible | Consulted | Informed |
| Phase 1: Integration architecture | Responsible | Consulted | Consulted | Informed |
| Phase 2: Context products | Accountable | Responsible (certification) | Consulted | Responsible (domain) |
| Phase 3: Orchestration | Responsible | Informed | Accountable | Informed |
| Phase 4: Governance and lifecycle | Consulted | Accountable | Informed | Responsible |
How Atlan automates the context engineering framework
Permalink to “How Atlan automates the context engineering framework”Most enterprise teams run context engineering by hand at first. They export CSVs from the catalog, paste definitions into prompts, and find out that the context has broken when agents start returning wrong answers to executives. Atlan helps automate all five phases end-to-end, with humans governing definitions, tests, and promotions.
| Activity | Manual process | Atlan-automated process |
|---|---|---|
| Phase 0: Context inventory | Data engineers export glossary terms and lineage screenshots to spreadsheets. Definitions drift within weeks. | Atlan catalog continuously maintains glossary terms, column-level lineage, and certification status, all queryable by the Context Engineering Studio. |
| Phase 1: Integration architecture | Custom scripts per data source. Breaks when schemas change. No standard output format. | Atlan connectors output to a canonical context schema. Event-driven refresh via active metadata management. |
| Phase 2: Context products | Ad hoc prompt files in Git or Notion. No versioning, tests, or expiry. | Context Engineering Studio bootstraps products from catalog metadata. Stores them in the Context Lakehouse with version control, and lifecycle controls like versioning and expiry policies. |
| Phase 3: Orchestration | Hardcoded routing logic per agent. Every new agent needs custom integration work. | Atlan’s context routing layer classifies query intent and retrieves certified products. MCP-compatible, so it can plug into modern agent frameworks (including your own). |
| Phase 4: Governance and lifecycle | Manual review cycles. Teams discover stale context only when agents start producing wrong outputs. | Active metadata management can automatically surface and flag changes in source definitions so teams can update affected context products. CI/CD enforces certification before promotion. |
Atlan’s Context Engineering Studio bootstraps Phase 0 directly from the catalog. It reads existing glossary terms, column-level lineage, and certification status without a manual export step.
The Context Lakehouse stores and versions products, enforcing test coverage requirements before certification. Active metadata management continuously monitors upstream systems. When the recognized_revenue_q4 definition in the glossary changes, Atlan can flag downstream products for re-certification so teams can update context before agents continue consuming stale versions.
The payoff shows up in engineer-hours.
FAQs about context engineering frameworks
Permalink to “FAQs about context engineering frameworks”What are the components of a context engineering framework?
Permalink to “What are the components of a context engineering framework?”A context engineering framework has five operational components: a context inventory (catalogued metadata including glossary terms, lineage, and quality rules), a context integration architecture (connectors and pipelines), context products (versioned, tested, governed bundles), a context orchestration layer (runtime routing at inference time), and a context governance and lifecycle process (versioning, testing, promotion, deprecation).
How do you build a context engineering framework for AI agents?
Permalink to “How do you build a context engineering framework for AI agents?”Start with Phase 0 by inventorying existing metadata in your catalog: business glossary terms, column-level lineage, and quality rules. Build integration pipelines that normalize these into a context registry (Phase 1). Package them into versioned products by domain (Phase 2). Deploy query-intent routing to inject the right product at inference time (Phase 3). Add governance and lifecycle management to keep every product current (Phase 4).
What is context window management?
Permalink to “What is context window management?”Context window management is the practice of selecting, prioritizing, and pruning the information injected into an AI model’s context window before it makes a decision. Because windows stay finite, effective management means including only the context relevant to each query. Orchestration routes domain-specific context products rather than dumping entire knowledge bases in, which preserves the attention budget for reasoning.
What does Anthropic say about context engineering?
Permalink to “What does Anthropic say about context engineering?”Anthropic’s engineering team defines context engineering as the discipline of deciding what to include, what to exclude, and how to structure information inside the context window. Their guidance emphasizes that context is a limited resource, and that production AI agents need systematic context selection rather than well-written prompts alone.
What role does a data catalog play in context engineering?
Permalink to “What role does a data catalog play in context engineering?”A data catalog is the starting point for any enterprise context engineering framework. It holds the business glossary terms, column-level lineage, certification status, and quality rules, capturing institutional knowledge. Rather than recreating that knowledge for AI agents, a framework packages catalog assets into governed context products, making the catalog the authoritative source of context for every agent in the enterprise.
How is context engineering different from data engineering?
Permalink to “How is context engineering different from data engineering?”Data engineering builds and maintains the pipelines, warehouses, and infrastructure that move and store raw data. Context engineering selects, packages, and governs the specific information an AI agent needs to reason over that data. Data engineering is a prerequisite, creating the metadata assets (lineage, quality rules, semantic definitions) that context engineering organizes into agent-ready products. The two are complementary and increasingly co-owned by the same team.
What is a context engineering framework for enterprise AI?
Permalink to “What is a context engineering framework for enterprise AI?”An enterprise context engineering framework is a structured, repeatable system for managing AI agent context across multiple agents, domains, teams, and governance requirements. It treats context as a versioned data product with defined owners, test coverage requirements, and lifecycle policies. Enterprise frameworks require governance, auditability, cross-team context reuse, and integration with existing metadata infrastructure such as data catalogs and business glossaries.
Context engineering turns your existing metadata into a reliable agent infrastructure
Permalink to “Context engineering turns your existing metadata into a reliable agent infrastructure”A context engineering framework activates the metadata infrastructure your enterprise already has. Your data catalog, your business glossary, column-level lineage, quality rules: that’s the raw material, already sitting in the stack.
The 5-phase framework adds an operational path from those assets to a reliable, governed, agent-ready context. That path moves AI reliability from a model problem to an infrastructure problem, which is a shift that data engineering teams already know how to handle.
For teams ready to move from pilot to production, the next practical step is to audit Phase 0 maturity. How complete is your business glossary? Is lineage tracked at the column level for your top 20 analytical entities? The inventory becomes the foundation for everything in Phases 1 through 4.
See how Atlan’s Context Engineering Studio bootstraps the process.
