



















Context versioning for AI agents is the practice of treating business context for AI — business definitions, certified metrics, and governance policies — as versioned artifacts with commit history, promotion gates, and rollback capability. Without it, agents operate on stale business rules and produce wrong answers that no one can reproduce. Teams that version and govern their context layer before agents reach production see measurable results: a 38% accuracy uplift across 522 queries, compared to agents running on unversioned context (Atlan AI Labs, 2026).
This is distinct from prompt versioning, agent config versioning, and model versioning. All three are necessary; none is sufficient without context versioning. Code without version control produces deployment disasters. Context without version control produces AI production failures that no one can reproduce.
Context versioning sits within the broader context engineering discipline and the broader engineering lifecycle that governs how AI agent context is received and used.
| What it is | Treating business definitions, policies, and certified metrics as versioned artifacts that agents consume at runtime |
|---|---|
| Core problem it solves | Stale-context failures, irreproducible AI decisions, multi-agent version drift |
| Key capability | Context manifest ID per inference call + promotion pipeline (sandbox to staging to production) |
| Without it | 30%+ accuracy degradation from context rot; 10.6% benchmark loss from context collapse (arXiv:2510.04618, ICLR 2026) |
| With it | 5x AI accuracy improvement (Workday + Atlan MCP); 38% accuracy uplift across 522 queries (Atlan AI Labs, 2026) |
| Distinct from | Prompt versioning, agent config versioning, data versioning |
Inside Atlan AI Labs & The 5x Accuracy Factor
Learn how context engineering drove 5x AI accuracy in real customer systems. Explore real experiments, quantifiable results, and a repeatable playbook for closing the gap between AI demos and production-ready systems.
Download E-BookWhy AI agents fail without versioned context
Permalink to “Why AI agents fail without versioned context”Most production AI failures are stale-context failures, not model failures. The failure mode has a name: context rot. This is when business definitions, retired metrics, or changed policies remain active in the context layer after they should have been updated or invalidated. According to Chris Lema’s taxonomy of AI context failures, context rot sits alongside context staleness, context anchoring, and context poisoning as the primary categories of agent breakdown in production.
Here is a concrete scenario. Your revenue analysis agent uses last quarter’s definition of net_revenue_recognized – one that the CFO office quietly updated on March 1. The agent’s arithmetic is correct. Its definition is wrong. No one can reproduce the error because the RAG index was rebuilt overnight and the stale definition is no longer retrievable. The model passed every test. The context failed silently.
Industry data suggests that context rot causes 30%+ accuracy degradation mid-window once stale definitions accumulate in the context pipeline. According to research by arXiv:2510.04618 (ICLR 2026), structured, incremental context updates prevent the context collapse that reduces benchmark scores by 10.6% over long tool-call chains.
As Inkeep documented after deploying hundreds of enterprise agents: “Most production failures aren’t model failures – they’re context failures.”
The consequence for teams building on the enterprise context layer is direct: context drift and context rot in production are not retrieval problems or model problems. They are discipline problems. Versioning is the fix.
What context versioning means for AI agents
Permalink to “What context versioning means for AI agents”Context versioning addresses three object types that most teams leave unversioned. The first is business definitions: the canonical meaning of fields like revenue, active_user, and churn_rate. The second is governance policies: who can access what data, under which rules, and when those rules changed. The third is certified metrics: the approved formula, its lineage, and the sign-off that certifies it as the organization’s authoritative version.
This is distinct from what the current context engineering discipline typically covers. Prompt versioning tracks how the agent is instructed. Agent config versioning tracks model choice, tool selection, and parameters. Context versioning tracks what business reality the agent is reasoning from. You need all three. The field-level concrete examples matter: recognized_revenue_q4 and active_user_30d are what gets versioned, not just a system prompt that references them.
Understanding dynamic context vs static context helps clarify what versioning targets: static context (certified definitions, governance policies, approved metrics) is what context versioning manages; dynamic context (session-scoped retrieval) is what changes per inference call.
Understanding context versioning also requires distinguishing it from the memory layer for AI agents. Memory is session-scoped: what an agent learned in this conversation. Context versioning is infrastructure-level: what the organization certifies as true, promoted through governance gates and available across every conversation, every agent, every team.
What gets versioned vs. what teams typically think gets versioned
| What teams typically version | What also needs versioning |
|---|---|
| System prompt / instructions | Business definitions (e.g., net_revenue_recognized) |
| Agent config (model, tools, parameters) | Governance policies and access rules |
| Model version | Certified metrics and their lineage |
| RAG retrieval pipeline | Context promotion state (sandbox / staging / production) |
The enterprise teams that closed the accuracy gap did not do it by improving prompts or switching models. They did it by treating the context layer as versioned infrastructure – the same investment the best engineering teams made in code version control, applied to the business reality their agents consume.
How context versioning works
Permalink to “How context versioning works”Context versioning has three operational components. Each one is necessary; together they make agent decisions reproducible, auditable, and reversible.
The context manifest ID
Permalink to “The context manifest ID”Every inference call attaches a context manifest ID: a unique identifier that points to the exact set of business definitions, governance policies, and certified metrics the agent used to produce its answer. Think of it as a git commit SHA for what the agent knew at decision time.
The manifest ID is what makes AI agent observability possible at the context layer. Without it, you can log the query and the answer; you cannot log which version of active_user_30d was active when the agent counted users. The manifest ID closes that gap, enabling decision traces that are complete enough to satisfy audit requirements. According to arXiv:2510.04618 (ICLR 2026), structured, incremental context updates of this kind produce a 10.6% performance improvement on agent benchmarks. They also prevent the context collapse that degrades accuracy over long tool-call chains.
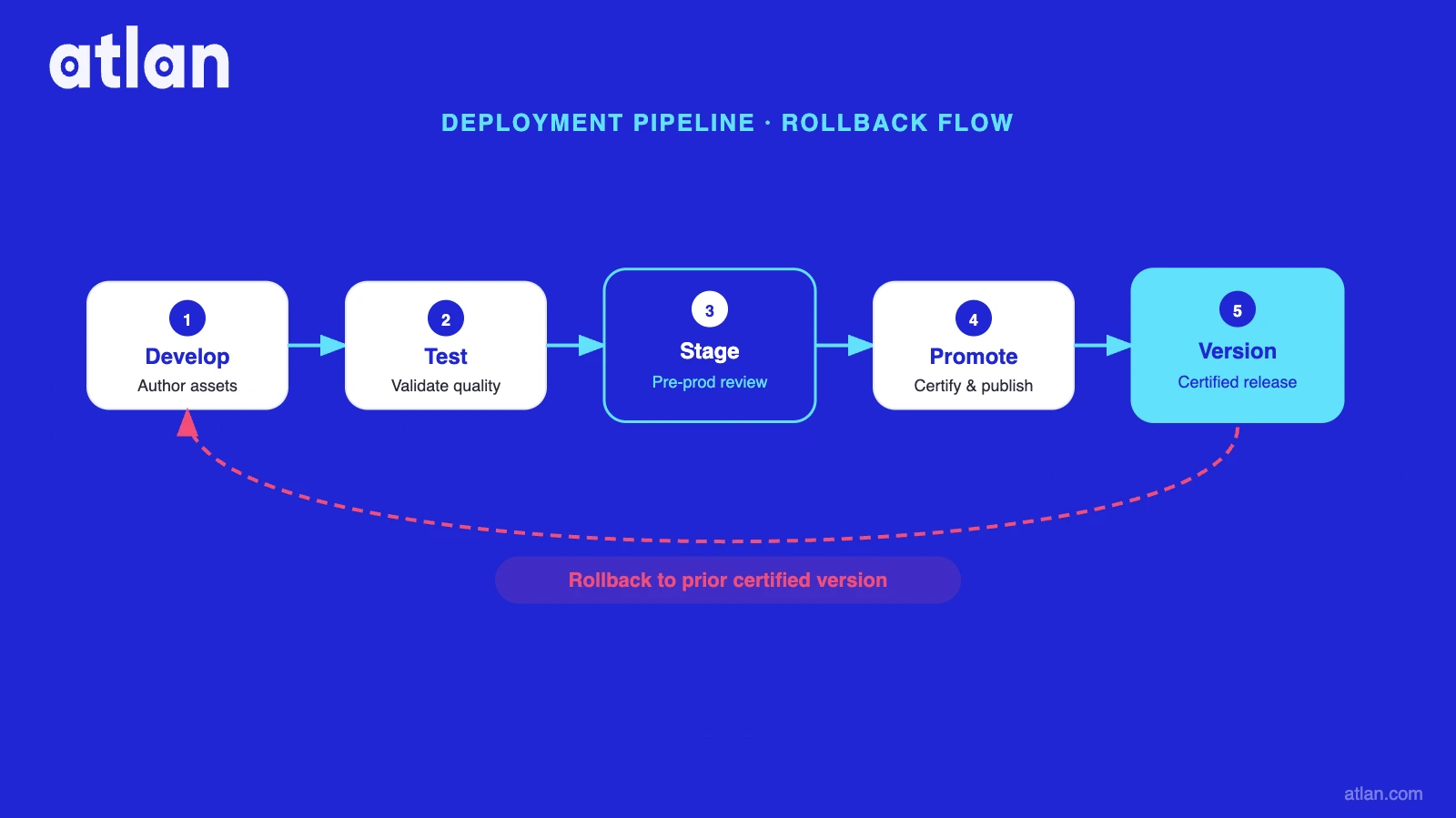
The promotion pipeline (sandbox to staging to production)
Permalink to “The promotion pipeline (sandbox to staging to production)”Context changes follow the same gates as code. A new definition of churn_rate_v2, a policy update for a new compliance requirement, a re-certified metric after a dbt model change – each flows through sandbox testing, staging validation, and a production promotion step. No context change goes live silently.
This is the part of context infrastructure that most teams skip. They update the business glossary. They don’t treat the update as a deployment event with gates, rollback points, and a log. Until they do, every definition change is a potential silent failure in every downstream agent.
Rollback capability
Permalink to “Rollback capability”When a business definition change produces wrong answers, you roll back the context version – not the model, not the prompt. Consider the dbt scenario: your active_user_30d metric is redefined when a dbt model is modified upstream. With a versioned context layer, you revert to the last certified version while the new definition is validated. Without it, you have no prior state to revert to.
Detecting and reversing context drift at the infrastructure level – rather than chasing individual prompt failures – is what separates teams that recover quickly from teams that rebuild.
Build Your AI Context Stack
Get the blueprint for implementing context graphs across your enterprise. This guide walks through the four-layer architecture -- from metadata foundation to agent orchestration -- with practical implementation steps for 2026.
Get the Stack GuideThe multi-agent version drift problem
Permalink to “The multi-agent version drift problem”Multi-agent architectures introduce a correctness problem that single-agent systems don’t face: version drift across agents that share business definitions but pull from different versions of the same certified concept. Effective context management across multi-agent systems begins with solving this drift problem at the infrastructure layer.
Here is the scenario. Your data quality agent, your reporting agent, and your compliance agent all use revenue_recognized. If each was deployed at a different time and none checks a shared context version, they may be reading from three different definitions. Their outputs disagree in ways that look like model inconsistencies – but they are version drift failures. No amount of model debugging resolves them, because the models are all doing their job correctly.
Enterprise context silos are a primary driver of this problem: when different teams maintain separate, unversioned context stores for their agents, version drift becomes structurally inevitable rather than an occasional accident.
According to Gartner’s top data and analytics predictions (June 2025), the average Fortune 500 company will have 150,000+ agents by 2028, up from fewer than 15 in 2025. Gartner estimates that only a minority of organizations believe they have the right governance in place for this scale. At 150,000 agents, unmanaged context version drift is not a minor inconvenience – it is a systemic correctness problem across the organization’s entire AI surface area.
The fix is a shared context layer for multi-agent systems with a single authoritative version promoted through governance gates. All agents query the same certified version. When the definition changes, the change flows through one promotion pipeline and every agent sees the same update at the same time.
Protocols move context efficiently between agents and tools. They do not define which version of revenue_recognized is authoritative. That is a context layer responsibility, and it must be addressed before the protocol conversation becomes meaningful. The protocol stack – MCP, A2A, or any successor – is the delivery mechanism. Versioned context is what gets delivered.
Context versioning vs data versioning: what’s the difference
Permalink to “Context versioning vs data versioning: what’s the difference”Teams building with dbt or Apache Iceberg already version data. That discipline is valuable and necessary. It is not the same as versioning context.
Data versioning tracks schema changes, table snapshots, and row-level history. Context versioning tracks what a business concept means, who certified it, which lineage it carries, and which policy governs access to it. You can have perfectly versioned data and still produce catastrophic context failures if the business definition layer is unversioned. The dbt model for active_user_30d may be version-controlled in git. The meaning of “active” – whether it counts users who logged in, users who took an action, or users who spent money – may exist only in a Confluence doc that was last edited two years ago.
| Data versioning | Context versioning | |
|---|---|---|
| What it tracks | Schema changes, snapshots, row history | Business definitions, certified metrics, governance policies |
| Who owns it | Data engineering | Data governance + business owners |
| When it’s needed | Data pipeline changes | Any time a definition or policy changes |
| Failure without it | Wrong data | Correct data, wrong interpretation |
For a fuller treatment of how data versioning and context versioning relate, see data versioning for AI – they are complementary disciplines, not alternatives.
How to implement context versioning for AI agents
Permalink to “How to implement context versioning for AI agents”These five steps take context versioning from concept to infrastructure practice. They apply regardless of the agent framework or model you use.
-
Audit what context your agents actually consume. List every business definition, policy, and metric each agent references. If it lives in a system prompt as free text, it is unversioned. If the definition changed last quarter and no one updated the prompt, the agent is operating on stale context right now.
-
Move context from prompts into a shared context store. Extract business definitions from individual prompts into a shared, versioned repository. Every agent reads from the store; no agent owns its own copy. This eliminates drift at the source. Context management strategies for enterprise AI begin here: the context store is the foundation. Applying context compression techniques ensures the versioned context delivered to agents is optimally sized — dense and relevant, not bloated with stale definitions.
-
Attach a context manifest ID to every inference call. Log the exact version of context used for every agent decision. This is the audit trail that makes reproducibility possible. Without it, post-incident debugging requires you to reconstruct what the agent knew – which is often impossible once the index has been rebuilt. Cached context strategies work best when combined with manifest IDs: cached context is versioned context, so you always know which certified version was served.
-
Establish a promotion pipeline. Any context change follows the same sandbox to staging to production gates as code. No definition update goes live silently. Test in sandbox, validate against a staging query set, promote to production with an approval gate.
-
Instrument rollback. Define what “rolling back context” means for your stack before you need it. Which business definitions can be reverted independently? What is the rollback procedure when a new certified metric produces wrong answers in production? Test the rollback path before a production incident forces you to use it under pressure.
Common mistakes in AI context management
Permalink to “Common mistakes in AI context management”These four mistakes are the most consistent failure patterns across enterprise AI teams, sourced from production context failures documented by enterprise data leaders.
-
Treating context versioning as prompt versioning only. Versioning the prompt is step one. If the business definition the prompt references is stale, a versioned prompt still produces wrong answers. The version must go all the way down to the definition layer.
-
Waiting for an incident to force it. By the time you have a stale-context failure in production, you have no audit trail. Versioning must be infrastructure-first – built before the first agent goes to production, not after the first incident exposes the gap. Context distraction — irrelevant or inconsistent definitions that fragment agent reasoning — is equally damaging and equally preventable with proper versioning discipline.
-
Storing context in individual agent prompts instead of shared infrastructure. Every agent with its own context copy is a divergence waiting to happen. One definition update now requires finding and updating every prompt that references it. One shared, versioned context store eliminates drift at the source.
-
No rollback plan for business definition changes. When the CFO updates the revenue definition, can you restore the last certified version while the new one is validated? If the answer is no, you’re operating without a safety net on the most consequential data your agents use.
How Atlan handles context versioning
Permalink to “How Atlan handles context versioning”Most enterprises building AI agents discover the context problem only after a production failure. Prompts are versioned. Models are versioned. But the business definitions, certified metrics, and governance policies agents reason from exist as unversioned free text – in individual prompts, in Confluence docs, in Slack threads. No commit history. No rollback. No shared source of truth.
Why enterprises need a context layer begins with this gap: contextual intelligence is only possible when the definitions underpinning agent reasoning are certified, versioned, and governed. Atlan addresses this with context products: versioned, governed bundles built around one business concept, packaging its canonical definition, lineage, access policies, certifications, and test cases. These live in Context Repositories – promoted through sandbox, staging, and production with versioning gates. The Atlan MCP Server delivers the current certified version to any agent that queries it – Claude, GPT-4o, Gemini, or custom – so every agent reads from the same versioned context layer infrastructure, not its own copy.
LLMOps teams operationalizing this at scale find that versioned context is the single highest-leverage investment in production AI reliability: it addresses the root cause of most failures, not just their symptoms.
As Tobi Lutke, CEO of Shopify, put it: “Context engineering is the art of providing all the context for the task to be plausibly solvable by the LLM.” Context products are what makes that context trustworthy, not just available.
The outcomes follow from the infrastructure, not from the model choice. According to Atlan AI Labs research, Workday achieved a 5x AI accuracy improvement after embedding governed context through Atlan’s MCP server. In the same research program, Atlan’s 522-query isolation study – using the Formula One dataset with metadata quality as the only variable – showed a 38% accuracy uplift (p < 0.0001) (Atlan AI Labs, 2026). The model did not change. The context did. Full methodology: How We Proved Metadata Delivers 38% Better AI Accuracy.
DigiKey’s Chief Data and Analytics Officer described the result plainly: “Atlan is much more than a catalog of catalogs. It’s more of a context operating system.” One versioned context layer; many delivery paths; no version drift between them. That is what governance-backed context produces at enterprise scale.
Real stories from real customers: context versioning in practice
Permalink to “Real stories from real customers: context versioning in practice”"We're excited to build the future of AI governance with Atlan. All of the work that we did to get to a shared language at Workday can be leveraged by AI via Atlan's MCP server...as part of Atlan's AI Labs, we're co-building the semantic layer that AI needs with new constructs, like context products."
-- Joe DosSantos, VP of Enterprise Data & Analytics, Workday
Workday built shared language – business glossary, semantic models, certified definitions – for human analysts first. That same governed, versioned context layer is now delivered to AI via Atlan’s MCP server. The context came first; the protocol was the delivery vehicle. When the context became versioned, certified, and shared, accuracy improved 5x. The model did not change. The enterprise-scale context infrastructure did.
"Atlan is much more than a catalog of catalogs. It's more of a context operating system...Atlan enabled us to easily activate metadata for everything from discovery in the marketplace to AI governance to data quality to an MCP server delivering context to AI models."
-- Sridher Arumugham, Chief Data & Analytics Officer, DigiKey
DigiKey activated metadata across every AI delivery path – discovery, governance, data quality, MCP – from one versioned context layer. No version drift across delivery paths because there is only one source of certified context. That is the promise of context versioning at scale.
Context versioning is the infrastructure that makes AI reliable
Permalink to “Context versioning is the infrastructure that makes AI reliable”The teams shipping production AI at scale share one discipline: they treated the context layer as infrastructure before the first agent reached users. They did not wait for a stale-definition failure to force the question. Research suggests up to 40% of agentic AI projects will be canceled by 2027 due to missing structured context (Gartner estimates). The difference between those projects and the ones that ship is not model choice.
One enterprise data leader described the gap plainly: “We don’t have a mature versioning system for context. We haven’t figured it out. But it’s rapidly going to become an issue as soon as we get the first one into production.” That moment has arrived. The model you choose is secondary. The context you give it is the investment.
Every team that has produced measurable accuracy gains at enterprise scale has done so by governing the context layer, not by upgrading the model. Why enterprises need a context layer begins with this argument – and context versioning is the operational mechanism that makes it real.
FAQs
Permalink to “FAQs”1. What is context versioning for AI agents?
Permalink to “1. What is context versioning for AI agents?”Context versioning for AI agents is the practice of treating business definitions, certified metrics, and governance policies as versioned artifacts with commit history, promotion states, and rollback capability. Each version carries a unique ID; agents query a declared version at inference time and that ID is logged with every decision. It is distinct from prompt versioning, which tracks agent instructions rather than the business reality agents reason from.
2. How is context versioning different from prompt versioning?
Permalink to “2. How is context versioning different from prompt versioning?”Prompt versioning tracks how the agent is instructed – the system prompt, the task framing, the few-shot examples. Context versioning tracks what business reality the agent reasons from – the definition of net_revenue_recognized, the access policy governing PII fields, the certified formula for active_user_30d. Both are needed. Prompt versioning without context versioning still produces stale-definition failures when underlying business rules change without updating the prompt.
3. What is context rot and how does versioning prevent it?
Permalink to “3. What is context rot and how does versioning prevent it?”Context rot is the accumulation of stale definitions, retired metrics, or changed policies that remain active in the context layer. It causes agents to produce answers that were correct under old business rules but are wrong under current ones. Versioning prevents context rot by attaching a version ID to every context artifact and requiring promotion through governance gates before any change goes live – making silent staleness technically impossible.
4. How do you implement context versioning for AI agents?
Permalink to “4. How do you implement context versioning for AI agents?”Five steps: audit what context each agent actually consumes; move those definitions from individual prompts into a shared context store; attach a context manifest ID to every inference call; establish a sandbox to staging to production promotion pipeline for context changes; and define and test rollback procedures before they’re needed. The key shift is treating context changes as deployment events, not documentation updates.
5. What is the multi-agent version drift problem?
Permalink to “5. What is the multi-agent version drift problem?”Multi-agent version drift occurs when multiple agents share business definitions but pull from different versions of the same certified concept – because context drift has gone unmanaged. The agents produce inconsistent answers that appear to be model errors but are versioning failures. A shared context layer with a single authoritative promoted version eliminates drift at the source; every agent reads the same certified definition at the same time.
6. What is a context manifest ID?
Permalink to “6. What is a context manifest ID?”A context manifest ID is a unique identifier attached to every agent inference call that records the exact version of business definitions, policies, and certified metrics the agent used to produce its answer. It functions like a git commit SHA for what the agent knew at decision time – enabling audit trails, reproducibility, and rollback when a context version is found to produce incorrect results.
7. When do AI agents need versioned context?
Permalink to “7. When do AI agents need versioned context?”Any time more than one agent shares business definitions, context crosses team boundaries, an AI answer must be auditable, or policy and metric definitions change over time. For regulated industries, context versioning is also the mechanism that satisfies NIST AI RMF auditability requirements and ISO/IEC 42001 AI management system standards by creating a traceable record of which certified rule each agent applied.
8. How does context versioning relate to AI governance?
Permalink to “8. How does context versioning relate to AI governance?”Context versioning is the operational backbone of AI governance: it creates the audit trail that answers “which version of which business rule did this agent apply, and who certified it?” Without versioning, governance commitments exist on paper but have no technical enforcement. With it, governance policies become production constraints – versioned, promoted, and rollback-capable like any other production artifact.
