



















When employees leave, they take more than their skills — they take the accumulated context that makes your organization run. Institutional knowledge loss costs U.S. companies $1.3 trillion annually (Deloitte, 2024), and the average knowledge worker tenure is just 4.1 years. This guide covers causes, hidden costs, why AI agents are now the hardest-hit victims, and how to prevent it.
| Fact | Detail |
|---|---|
| Annual U.S. cost | $1.3 trillion from knowledge worker turnover (Deloitte, 2024) |
| Average tenure | 4.1 years for U.S. knowledge workers (BLS, 2024) |
| Replacement cost | 50–200% of annual salary per departing knowledge worker (SHRM, 2023) |
| Time to full productivity | 8–12 months for replacements in knowledge-intensive roles (SHRM, 2023) |
| Hours lost weekly | 19% of working hours spent searching for information workers should already have (McKinsey Global Institute) |
| AI accuracy impact | 38% improvement in AI query accuracy when governed institutional context is provided (Atlan AI Labs) |
| Enterprise knowledge gap | 70–80% of enterprise knowledge is tacit — never written down (Gartner, 2024) |
Build Your AI Context Stack
Get the blueprint for implementing context graphs across your enterprise. This guide walks through the four-layer architecture—from metadata foundation to agent orchestration—with practical implementation steps for 2026.
Get the Stack GuideWhat causes institutional knowledge loss
Permalink to “What causes institutional knowledge loss”Institutional knowledge loss has seven root causes: voluntary turnover (average tenure just 4.1 years), retirements, reorganizations, M&A (50–70% turnover in acquired companies within 3 years), system migrations, documentation debt, and — in the AI era — deploying agents into environments where institutional context was never captured in machine-readable form.
-
Voluntary turnover — The average U.S. knowledge worker tenure is 4.1 years (BLS, 2024). At that rate, organizations cycle through their entire knowledge workforce approximately every four years. Each departure takes unique context that was never written down.
-
Retirements — 10,000 Americans turn 65 daily through approximately 2030 (AARP, 2023). In data and analytics roles specifically, retiring engineers carry decades of exception history, data lineage knowledge, and system architecture rationale that has no formal home.
-
Reorganizations — When teams dissolve, the shared mental models and team-specific processes dissolve with them. The institutional knowledge that lived in group context does not survive a reorg into written form.
-
M&A — Harvard Business Review research documents 50–70% voluntary turnover in acquired companies within three years. The institutional knowledge of the acquired organization — its data definitions, process rationale, and decision history — is rarely preserved in the acquirer’s systems. The enterprise context silos that result become permanent.
-
System and tool migrations — When a data warehouse is replaced, the institutional knowledge embedded in the old system — data models, business rules, exception handling logic — is often discarded rather than migrated. The new system has the data; the context behind it is gone.
-
Documentation debt — Gartner estimates that 70–80% of enterprise knowledge is tacit, meaning it has never been written down in any retrievable form (Gartner, 2024). This creates a structural context gap that no documentation effort can fully close.
-
AI-era congenital gap — Not a loss event but a structural absence: organizations deploy AI agents into data environments where institutional context was never captured in machine-readable form. The agents were born into a context vacuum. The knowledge was never there for them to access.
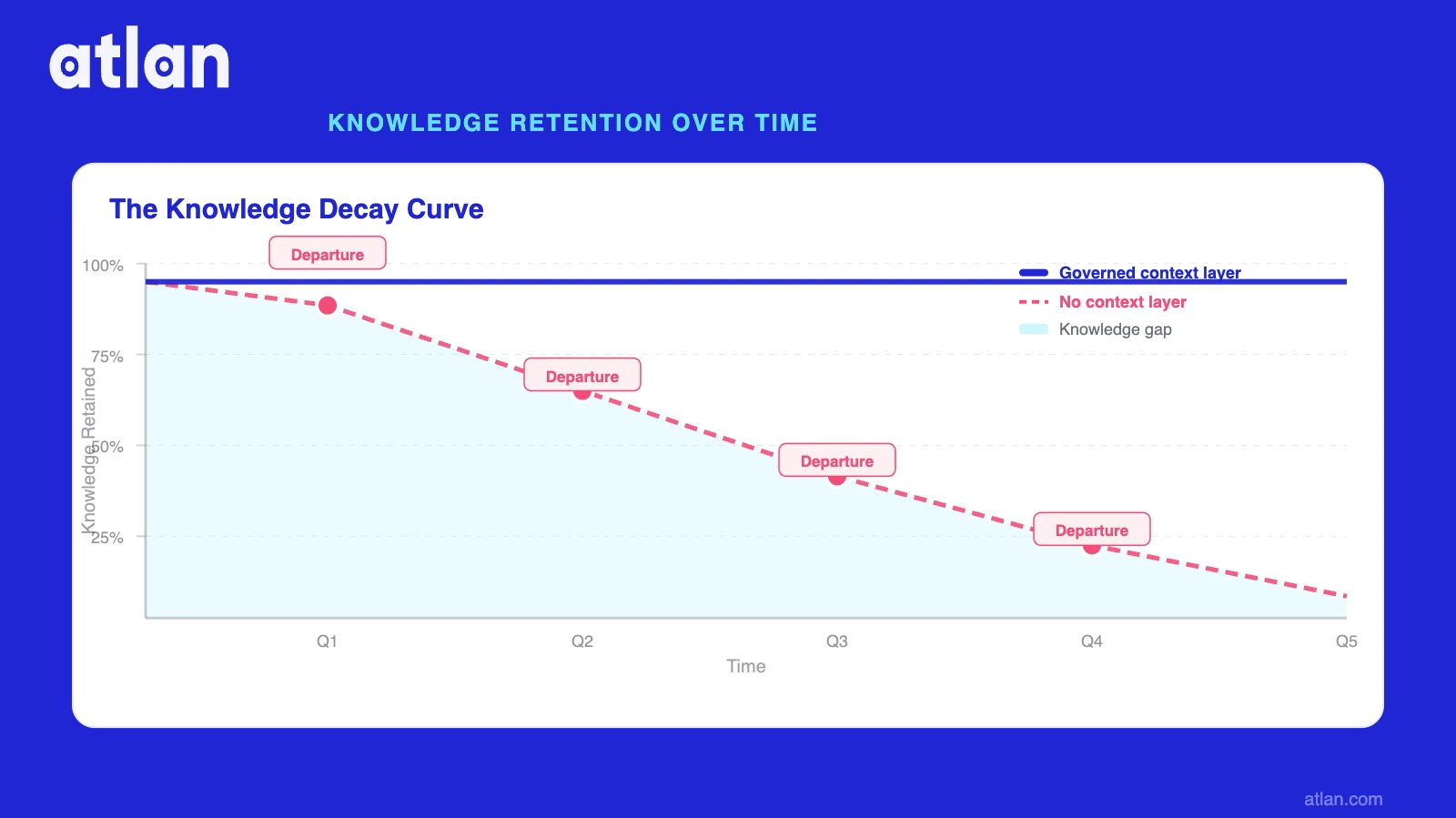
The hidden cost of institutional knowledge loss (quantified)
Permalink to “The hidden cost of institutional knowledge loss (quantified)”The visible cost is replacement: 50–200% of annual salary per departing knowledge worker. The hidden cost is productivity: new hires take 8–12 months to reach full output, and knowledge workers spend 19% of their working hours searching for information they should already have. The newest cost is AI accuracy: Atlan AI Labs documented a 38% improvement in accuracy when governed institutional context is provided to agents — the inverse of what enterprises experience when that context is absent.
The HR replacement invoice
Permalink to “The HR replacement invoice”The Society for Human Resource Management estimates the fully loaded cost of replacing a knowledge worker at 50–200% of annual salary, inclusive of recruiting, onboarding, lost productivity, and training (SHRM, 2023). For a $100,000/year data engineer, that is $50,000 to $200,000 per departure.
Deloitte’s Human Capital Trends report frames the macro picture: $1.3 trillion annually in the United States from voluntary turnover among knowledge workers, with knowledge loss — not just replacement hiring — representing the largest share (Deloitte, 2024). New hires in knowledge-intensive roles take an average of 8–12 months to reach full productivity. The primary friction is not skill. It is institutional context: understanding why systems are built the way they are, which processes have known exceptions, which stakeholders have which unwritten preferences.
The productivity tax
Permalink to “The productivity tax”McKinsey Global Institute research documents a persistent drag: knowledge workers spend 19% of their working hours searching for information they should already have access to. This is not a search technology problem. It is a consequence of institutional knowledge that exists in someone’s memory, or a Slack thread from 2022, or nowhere at all.
Peter Senge’s “learning disabilities” framework from “The Fifth Discipline” identifies what happens over time: organizations that fail to preserve institutional memory repeat the errors that memory would have prevented. The 38% improvement in AI query accuracy that Atlan AI Labs documented when governed context was provided to agents illustrates the mechanism precisely: the same infrastructure that makes AI agents accurate when institutional context is present makes them unreliable when it is not. See: why enterprises need a context layer.
The AI accuracy invoice — the one no one is measuring yet
Permalink to “The AI accuracy invoice — the one no one is measuring yet”This is the second invoice. Most enterprises are not tracking it yet.
Atlan AI Labs ran 522 queries across a Formula One dataset, isolating the effect of governed context (business definitions, lineage, certified metrics) versus schema-only prompts. The result: 38% improvement in AI query accuracy when institutional context was provided (Atlan AI Labs, 522-query study). When that governed institutional context is absent, accuracy falls proportionally — which is what enterprises are experiencing every time an agent queries data without the context layer behind it.
Workday demonstrated a 5x improvement in AI accuracy when institutional context was delivered to agents via Atlan’s MCP server. Gartner projects that 40% of agentic AI projects will be canceled by 2027 due to missing structured context (Gartner, 2025). Research cited in Atlan AI Labs eBook finds that 95% of enterprise AI pilots fail in production — the primary cause attributed is missing context, not model weakness.
The context layer ROI of getting this right is measurable: more accurate agents, fewer hallucinations, and faster time-to-insight across every team that touches data.
“The organization that treats its institutional knowledge as governed infrastructure — versioned, certified, machine-readable, and portable — is the one whose AI agents work when everyone else’s break.”
How institutional knowledge loss affects AI agents
Permalink to “How institutional knowledge loss affects AI agents”AI agents derive answers from context. When institutional knowledge — the business definitions, exception history, certified metrics, and decision rationale that experienced employees carry — is absent from an agent’s context layer, accuracy degrades immediately. Workday saw a 5x AI accuracy improvement when institutional context was delivered via Atlan’s MCP server. Without it, agents fill the gap with LLM hallucinations.
This is a new cost center that did not exist before AI deployment. Every existing framing of institutional knowledge loss treats it as a human problem with human solutions. The AI-era dimension is different: when the data expert who knew which metrics are reliable, which pipeline has known exceptions, and which business context definitions changed in Q3 2023 walks out the door, their knowledge does not just slow down new employees. It breaks the agents.
Five ways agents break without institutional context
Permalink to “Five ways agents break without institutional context”1. Stale definitions. If active_user was redefined in Q2 2024 but the old definition still lives in a legacy table, agents use whichever definition they encounter first. Without the institutional context of the change — the date, the rationale, the authoritative version — the agent produces metrics that contradict the CFO’s dashboard. No hallucination. Just the wrong answer, stated with confidence.
2. Exception blindness. Every enterprise data estate has approved workarounds and known anomalies. This exception knowledge is institutional. When the expert who carried it leaves, agents treat exceptions as valid signal and produce corrupted analysis. The institutional context that explains why the anomaly exists — and why it should be excluded — is gone.
3. Incomplete decision traces. Decision traces are only as complete as the institutional context available at inference time. When institutional knowledge is lost, decision traces have gaps that auditors cannot reconstruct — creating regulatory exposure in jurisdictions with AI transparency requirements.
4. Context vacuum hallucination. When agents lack institutional context, they fill the gap with training data — generic, not organization-specific. The agent invents plausible-sounding business rules and definitions that are indistinguishable from accurate answers without the institutional context to verify against. This is the context vacuum: the gap that forms when institutional knowledge was never captured in a form agents can access.
5. Compounding degradation. Unlike human employees, agents do not ask around. A new hire can say “I don’t know why this field is always null on Fridays — let me ask.” An agent without institutional context either ignores the anomaly or incorporates it as noise. Effective context management across multi-agent systems requires that institutional knowledge be delivered at inference time through a governed agent context layer.
Andrew Reiskind, CDO at Mastercard: “AI initiatives require more context than ever. The more capable AI becomes, the more institutional context it needs to be trustworthy.”
Inside Atlan AI Labs & The 5x Accuracy Factor
Learn how context engineering drove 5x AI accuracy in real customer systems. Explore real experiments, quantifiable results, and a repeatable playbook for closing the gap between AI demos and production-ready systems.
Download E-BookTraditional approaches and why they fall short
Permalink to “Traditional approaches and why they fall short”Documentation, knowledge management systems, wikis, succession planning, and exit interviews all address the human side of institutional knowledge loss — and all fail the same way: they capture static snapshots that decay, are written for humans rather than machines, and disconnect context from the data it describes. In the AI era, these failures are no longer just productivity costs — they are AI accuracy failures.
| Approach | What it does | Why it fails in the AI era |
|---|---|---|
| Documentation / wikis | Captures knowledge at a point in time | Decays; unstructured prose; agents cannot query reliably |
| KM systems (Confluence, Notion) | Organizes knowledge by topic | Siloed from data; no governance; outdated looks identical to current |
| Succession planning | Transfers knowledge before departure | Captures a fraction; tacit knowledge resists articulation under time pressure |
| SOPs / runbooks | Codifies process steps | Static; misses exceptions and decision rationale |
| Exit interviews | Last-minute extraction | Too late; too shallow; 70–80% of institutional knowledge is never surfaced |
The five approaches above share a single structural flaw: they treat institutional knowledge as something you extract from people and store in documents. The storage is passive. It cannot stay current as the underlying reality changes. It is readable by humans but not by machines. And in data-centric organizations, the most critical institutional knowledge — what a field means, which metrics are certified, which pipelines have known exceptions — lives disconnected from the data assets it describes.
When an AI agent queries that data, the knowledge it needs is one system away. Usually unreachable. This is the difference between a passive context catalog and an active context layer — the contrast that business definitions and metric certifications in a governed context layer are designed to close. See also: knowledge fragmented across silos and data catalog for AI.
How to prevent and recover from institutional knowledge loss
Permalink to “How to prevent and recover from institutional knowledge loss”Prevention requires treating institutional knowledge as governed infrastructure — not documentation. That means versioned context repositories, dynamic context that stays current as the data environment changes, context agents that capture tacit knowledge proactively, and a delivery mechanism (MCP) that makes preserved institutional context queryable by AI agents at inference time — not just searchable by humans.
Five prevention strategies, ranked by impact
Permalink to “Five prevention strategies, ranked by impact”1. Context repositories with versioning. Treat institutional knowledge about data — definitions, business rules, exception history, decision rationale — as versioned artifacts with commit history, ownership, and certification status. Not wikis. Governed infrastructure. When a definition changes, the old version is preserved with a date and author. Agents can access the current certified version. Auditors can reconstruct what was true at any point in time. See: versioned context.
2. Active metadata. A mechanism that keeps institutional context current as the underlying data environment changes. When a schema changes or a business definition is updated, the active metadata layer captures the change and propagates it to all contexts that reference it. This is the solution to the “documentation decays” problem — context that updates itself rather than requiring manual maintenance. See: business definitions and metric certifications.
3. Context agents for proactive capture. AI agents that observe how humans interact with data assets, surface undocumented business rules, and convert tacit expert knowledge into governed context artifacts before it disappears. Designed for the 70–80% of institutional knowledge that has never been written down. These context agents that proactively capture tacit knowledge address the cause, not just the symptom.
4. Enterprise Data Graph. A graph representation of your data estate that includes not just the data assets themselves, but the institutional context attached to them: certification status, definition history, lineage, and known exceptions. The Enterprise Data Graph makes institutional knowledge queryable, not just stored. An agent querying a metric can traverse the graph to find when the definition changed, who certified it, and which downstream assets depend on it.
5. MCP delivery to agents. Once institutional knowledge is governed, it needs to reach agents at inference time. The context API layer and the Atlan MCP server make preserved context queryable by any AI agent stack in the same call as the data query. The agent does not just get the data — it gets the institutional context about the data, with the same governance guarantees. This is what Workday’s DosSantos described: the shared language built over years, now delivered to agents through a single protocol call.
For organizations where institutional knowledge has already been lost, context bootstrapping — using AI to reconstruct context from behavioral patterns, query history, and existing artifacts — is the starting point. Not blank-page documentation but inference from what the organization’s behavior reveals about what it once knew. See also: the governed context layer as infrastructure for what prevention produces.
Institutional knowledge vs. tribal knowledge: what is the difference
Permalink to “Institutional knowledge vs. tribal knowledge: what is the difference”Tribal knowledge is informal, undocumented, and person-specific — the one engineer who knows why the ETL job runs at 2 AM. Institutional knowledge is broader: the organizational understanding of why decisions were made, what business rules mean, and which exceptions exist. All tribal knowledge contributes to institutional knowledge. Not all institutional knowledge is tribal.
| Dimension | Tribal Knowledge | Institutional Knowledge |
|---|---|---|
| Scope | Individual or small group | Organizational |
| Documentation status | Deliberately undocumented | Partially documented, often incompletely |
| What it covers | Personal know-how, shortcuts, workarounds | Processes, rules, rationale, history, data context |
| Primary risk | One person leaves | Team or system transition |
| AI impact | Agent loses one expert’s context | Agent loses the organization’s operational logic |
The overlap matters in practice. When a senior data engineer carries the context about why orders_v3_final_REAL exists, that starts as tribal knowledge. If it was never formalized, it becomes institutional knowledge loss when they leave. The governance distinction is the point: institutional knowledge should be governed infrastructure. Tribal knowledge, by definition, has not yet been. The goal is to move institutional knowledge out of the tribal category before it walks out the door.
Real stories from real customers: when context is the differentiator
Permalink to “Real stories from real customers: when context is the differentiator”Workday — building shared language that agents can use
Permalink to “Workday — building shared language that agents can use”Joe DosSantos, VP Enterprise Data and Analytics at Workday:
“We’re excited to build the future of AI governance with Atlan. All of the work that we did to get to a shared language at Workday can be leveraged by AI via Atlan’s MCP server.”
Workday built institutional context — shared business language, certified definitions, governed metadata — for humans first, over years of deliberate effort. The result was an organization where the meaning of data was settled, not contested. Without Atlan’s MCP server, that institutional knowledge would have remained accessible only to humans. By delivering it to agents through the context layer, Workday achieved a 5x improvement in AI accuracy. The institutional knowledge had always existed. The infrastructure to deliver it to agents was the gap.
Mastercard — institutional context at 100M+ asset scale
Permalink to “Mastercard — institutional context at 100M+ asset scale”Andrew Reiskind, CDO at Mastercard, on the organizational stakes of AI context:
“AI initiatives require more context than ever. The more capable AI becomes, the more institutional context it needs to be trustworthy.”
At Mastercard’s scale — hundreds of millions of data assets — institutional knowledge cannot be preserved through documentation culture. Manual curation is not a strategy at that scale; it is a bottleneck. Infrastructure is the only answer: configurable, governed, and able to scale to the full surface area of the data estate. The lesson from Mastercard is that the organizations that benefit most from AI are not the ones that bought the best model. They are the ones that built the context layer that model can actually use.
Both stories share the same underlying structure: institutional knowledge built for humans first, now delivered to agents as durable enterprise infrastructure.
Context is the company’s IP
Permalink to “Context is the company’s IP”The traditional framing of institutional knowledge loss is a talent and productivity problem. The more accurate framing is this: institutional knowledge is the company’s competitive moat — and in an AI-first organization, it is the primary determinant of whether your agents work better or worse than competitors’.
Contextual intelligence — the ability for AI systems to reason with organizational context, not just data — is what separates enterprises whose agents produce accurate answers from those whose agents hallucinate. You cannot buy ten years of your organization’s accumulated understanding of your data, your customers, your processes, and your decisions. That is yours. Or it was — if it was preserved.
Vendor-locked KM systems create a new version of institutional knowledge loss: context trapped in a proprietary platform, inaccessible to agents unless you use that vendor’s connectors, irrecoverable if you change tools. The Context Lakehouse model — open format (Iceberg), open protocol (MCP), governed externally — means institutional knowledge is genuinely owned by the enterprise. It is portable. It persists through tool migrations, vendor changes, and model upgrades. This is what separates context-native enterprises from knowledge-fragile ones: who owns the context layer determines who controls the AI advantage.
The enterprise that governs its institutional knowledge as infrastructure builds institutional memory that does not walk out the door. It survives model generations because the context does not belong to any model. It survives employee turnover because the knowledge does not live in any employee. It survives vendor changes because the format is open. The CDO responsibility for institutional knowledge has shifted from documentation oversight to infrastructure stewardship. The building of enterprise LLM context is the technical implementation of that shift.
Context is the company’s IP. Treat it accordingly.
FAQs about institutional knowledge loss
Permalink to “FAQs about institutional knowledge loss”1. What is institutional knowledge loss?
Permalink to “1. What is institutional knowledge loss?”Institutional knowledge loss is the erosion of the accumulated understanding, processes, relationships, and decision rationale that an organization builds over time — when that knowledge leaves with departing employees, system migrations, or reorganizations and is not recaptured. It includes data context (metric definitions, quality issues, lineage), process knowledge (workarounds, exceptions), and historical rationale (why decisions were made). It is invisible until something breaks.
2. What is the cost of institutional knowledge loss?
Permalink to “2. What is the cost of institutional knowledge loss?”The direct replacement cost is 50–200% of annual salary per departing knowledge worker (SHRM, 2023). Across the U.S. economy, voluntary turnover among knowledge workers costs $1.3 trillion annually, with knowledge loss representing the largest share (Deloitte, 2024). A newer, less-tracked cost: AI accuracy improvement of up to 38% when agents operate with governed institutional context (Atlan AI Labs) — meaning organizations without that context are paying for models that cannot reach their full potential. Most organizations are paying this second invoice without knowing it.
3. What causes institutional knowledge loss?
Permalink to “3. What causes institutional knowledge loss?”Seven primary causes: voluntary turnover (average U.S. knowledge worker tenure is 4.1 years), retirement waves (10,000 Americans turn 65 daily through 2030), reorganizations, M&A (50–70% turnover in acquired companies within 3 years), system migrations that discard embedded business rules, documentation debt (70–80% of enterprise knowledge is tacit and never written down), and — in the AI era — deploying agents into data environments where institutional context was never captured in machine-readable form.
4. How do you prevent institutional knowledge loss?
Permalink to “4. How do you prevent institutional knowledge loss?”Prevention requires moving from documentation culture to governed context infrastructure. That means: versioned context repositories that capture business definitions, exception history, and decision rationale as governed artifacts; active metadata that stays current as the data environment changes; context agents that proactively extract tacit expert knowledge before it leaves; and a delivery layer (such as an MCP server) that makes preserved institutional context queryable by AI agents at inference time — not just searchable by humans.
5. What is the difference between institutional knowledge and tribal knowledge?
Permalink to “5. What is the difference between institutional knowledge and tribal knowledge?”Tribal knowledge is informal, person-specific, and deliberately undocumented — the engineer who knows why the batch job runs at 2 AM. Institutional knowledge is broader: the organizational understanding of why decisions were made, how processes evolved, and what data means. All tribal knowledge contributes to institutional knowledge. The governance goal is to formalize institutional knowledge into governed infrastructure before it remains only tribal — and disappears when people leave.
6. How does institutional knowledge loss affect AI agents?
Permalink to “6. How does institutional knowledge loss affect AI agents?”When institutional knowledge is absent from an agent’s context layer — because it was never documented, is stale, or lives in a wiki the agent cannot query — the agent operates without it. Consequences: stale metric definitions produce contradictory outputs, exception blindness leads to corrupted analysis, decision traces have compliance gaps, and agents fill missing context with hallucination. Workday measured a 5x AI accuracy improvement when institutional context was delivered to agents via a governed context layer.
7. What is the difference between institutional knowledge and tacit knowledge?
Permalink to “7. What is the difference between institutional knowledge and tacit knowledge?”Tacit knowledge is personal, embodied know-how — the expertise a skilled professional builds through experience that is hard to articulate or transfer. Institutional knowledge is organizational — it spans processes, history, data context, and decision rationale that the organization as a whole has accumulated. Tacit knowledge is one input to institutional knowledge. When institutional knowledge is lost, it is often because tacit knowledge was never converted into an organizational artifact that survives beyond the individual.
Sources
Permalink to “Sources”- Deloitte Human Capital Trends 2024 - $1.3T annual cost of knowledge worker turnover
- McKinsey Global Institute - 19% of hours lost searching; 42% cite knowledge transfer as top challenge
- Bureau of Labor Statistics JOLTS 2024 - 4.1-year average knowledge worker tenure
- AARP Retirement Watch 2023 - 10,000 Americans turn 65 daily through 2030
- Gartner Enterprise Knowledge Management Research 2024 - 70–80% of enterprise knowledge is tacit
- Gartner Top Data and Analytics Predictions June 2025 - 40% of agentic AI projects canceled by 2027 due to missing structured context
- Atlan AI Labs - “How We Proved Metadata Delivers 38% Better AI Accuracy” - 522-query F1 study; 38% accuracy improvement
- Atlan AI Labs eBook - Context Layer for AI - Workday 5x accuracy; 95% pilot failure rate
- Snowflake - “Agent Context Layer for Trustworthy Data Agents” - +20% accuracy, -39% tool calls
- Senge, P. - “The Fifth Discipline” (1990) - learning disabilities; institutional memory
- Nonaka, I. & Takeuchi, H. - “The Knowledge-Creating Company” (1995) - tacit vs. explicit knowledge; organizations document outcomes not reasoning
