



















Tribal knowledge is the informal, undocumented know-how your organization runs on: exception rules, historical decisions, and unwritten workflows that live in people’s heads rather than in any system. When AI agents query your data, they see exactly what the schema says and nothing else: not the exception your team has handled manually for three years, not the metric definition that changed 18 months ago. The result is outputs that are technically correct but organizationally wrong, and they compound silently across every decision they touch. According to the Bureau of Labor Statistics Job Openings and Labor Turnover Survey (2023), US private sector voluntary turnover averages 22–25%, meaning a 100-person knowledge team loses roughly 22–25 people each year, each departure a tribal knowledge loss event. This guide covers what tribal knowledge is, why it now breaks AI agents, and how to capture it before the gap becomes a production failure.
For a deeper look at tribal knowledge problems specific to data teams, see tribal knowledge problems in data teams.
Context for AI Analysts: See Atlan's Context Studio in Action
Context is what gets AI analysts to production. See how teams are building production-ready AI analysts with Atlan's Context Studio.
Save your SpotHow tribal knowledge forms in organizations
Permalink to “How tribal knowledge forms in organizations”Tribal knowledge doesn’t form through a single failure of documentation. It accumulates through five organizational dynamics that compound over time.
Learning by doing
Permalink to “Learning by doing”Employees accumulate tacit know-how through direct experience that is never formalized. The data engineer who has debugged the same pipeline failure seven times develops a mental model that doesn’t exist in any runbook, and may never write it down because writing it down was never the job. The knowledge is real, it is actionable, and it belongs entirely to one person.
Social transmission
Permalink to “Social transmission”Knowledge spreads informally through Slack messages, hallway conversations, and side comments in meetings: channels that leave no persistent, structured record. At scale, this becomes the primary knowledge transfer mechanism precisely because it is faster than documentation. The problem is that it leaves no trail an agent or a new hire can follow.
Process evolution without documentation
Permalink to “Process evolution without documentation”Systems change, business rules evolve, exceptions accumulate, but documentation doesn’t keep pace. The delta between “what the docs say” and “how things actually work” grows with every quarter. This is the source of most enterprise context silos: not deliberate siloing, but documentation that simply didn’t catch up.
Organizational complexity
Permalink to “Organizational complexity”What is manageable in a 10-person team becomes a reliability risk at 1,000 people. The surface area for undocumented exceptions grows with headcount and system count. The more interconnected the systems, the more tribal knowledge is required to navigate them correctly.
Intentional opacity (rarest, most dangerous)
Permalink to “Intentional opacity (rarest, most dangerous)”Occasionally tribal knowledge is intentionally kept informal, a form of job security, or simply because the effort of documentation was never incentivized. This type is the hardest to surface because there is no accidental gap to detect; it requires organizational trust, not just better tooling.
The pattern across all five mechanisms is the same: tribal knowledge that accumulates without a structured capture process becomes institutional context debt, invisible until a departure, a failure, or an agent makes it visible.
Types of tribal knowledge (5 types with examples)
Permalink to “Types of tribal knowledge (5 types with examples)”Tribal knowledge falls into five categories: process know-how, exception context, historical decisions, relationship definitions, and interpretive heuristics. Each type creates a distinct AI failure mode when undocumented: from misfired alerts to misleading trend analyses.
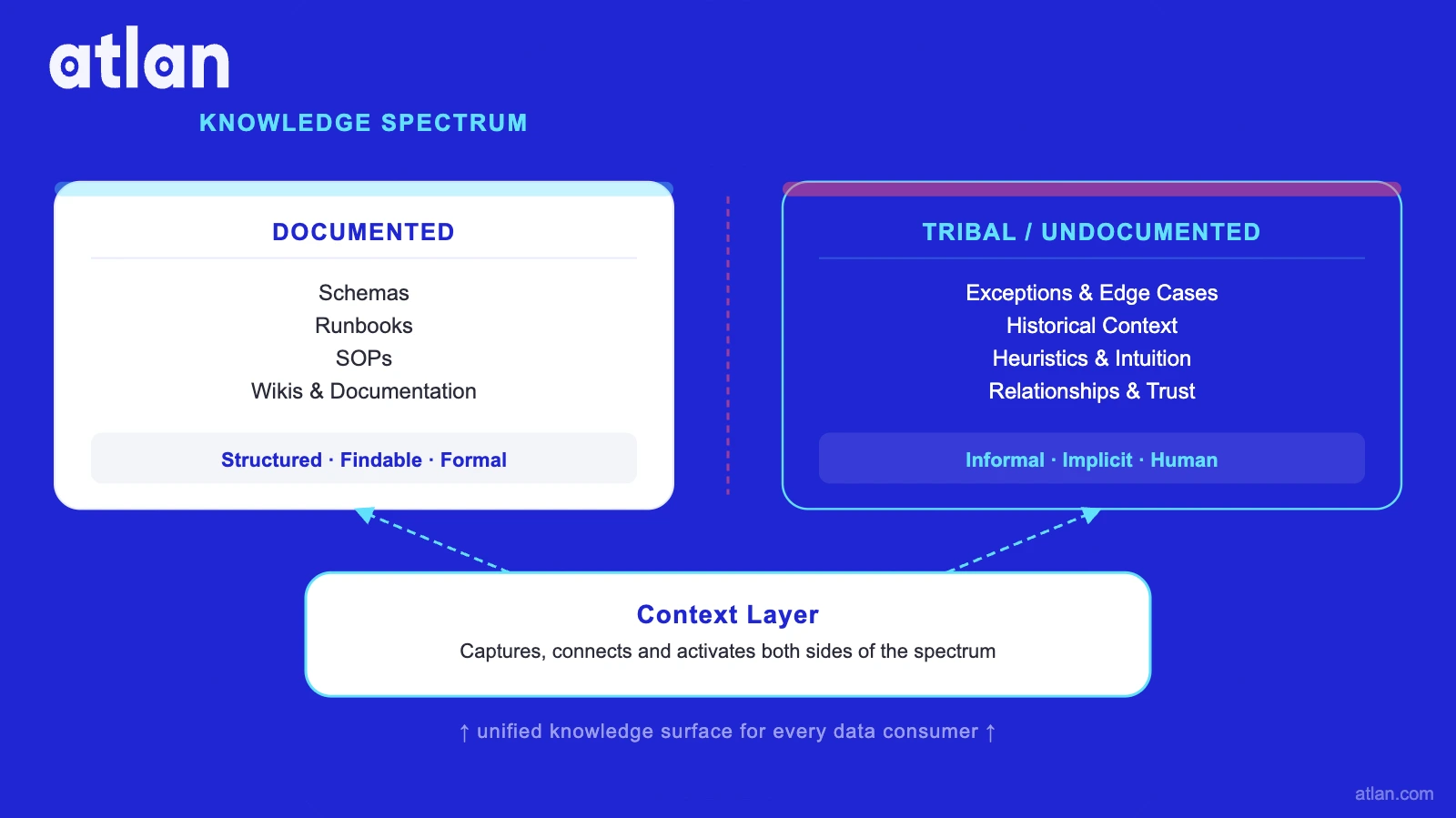
1. Process knowledge
Permalink to “1. Process knowledge”Undocumented workflow steps and operational heuristics. A common example: “We always run transformation A before transformation B, even though the pipeline doesn’t enforce the order; if you skip it, the downstream model breaks.” Agents and automated pipelines that follow official documentation will skip the undocumented steps and fail silently.
2. Exception knowledge
Permalink to “2. Exception knowledge”Context about special cases and deviations. Example: “Customer X is categorized as enterprise, but their contract is structured as mid-market; use the mid-market SLA when reporting their metrics.” Without this, an agent fires a retention alert on a healthy account. Context problems in data teams that involve agents are almost always rooted in exception knowledge that was never encoded.
3. Historical context
Permalink to “3. Historical context”Institutional memory about decisions and their rationales. Example: “The recognized_revenue_q4 calculation changed 18 months ago after a policy update. Pre- and post-change numbers aren’t comparable without a normalization factor.” Without this, AI-generated trend reports contain comparisons that look valid but reflect a data definition that no longer exists. Closing the context gap in data teams starts with capturing exactly this type of historical change record.
4. Relationship knowledge
Permalink to “4. Relationship knowledge”Understanding how teams, systems, and definitions relate to each other. Example: “Marketing’s qualified_lead and sales’ qualified_lead map to different database tables, even though they share a name in the BI layer.” Multi-agent systems are especially vulnerable here: two agents pulling from the same terminology but different definitions will produce irreconcilable outputs without ever flagging an error. Establishing context management across multi-agent systems starts with capturing exactly this relationship knowledge before agents diverge.
5. Interpretive knowledge
Permalink to “5. Interpretive knowledge”Domain expertise about how to read outputs correctly. Example: “A 20% drop in this metric is almost always a data ingestion lag, not a real business change; wait 48 hours before escalating.” Without interpretive knowledge, agents over-alert, escalate false positives, and erode trust in AI outputs faster than any model limitation could.
Each of these five types is invisible to traditional data systems. None of them live in a schema, an API response, or a table definition. They live in people, which is what makes them both valuable and fragile.
Why tribal knowledge is now an AI production problem
Permalink to “Why tribal knowledge is now an AI production problem”AI agents don’t ask follow-up questions or call the expert down the hall. When an agent queries your data, it sees exactly what the schema says, not the exception that has been handled manually for three years. Every piece of tribal knowledge that was never encoded becomes a production reliability risk the moment you deploy agents.
For decades, tribal knowledge was a human-to-human problem. Humans compensate. They escalate. They apply their own context when something looks off. AI agents cannot. They return what the data says, without the tribal filter. The result is outputs that are technically correct and organizationally wrong: the query ran without error, the numbers add up, and the decision made on that output is quietly, systematically incorrect.
According to Gartner’s Top Strategic Technology Trends for 2025: Agentic AI, 60% of AI agent production failures trace back to context quality issues: missing or stale context that makes technically accurate outputs operationally wrong. This is the tribal knowledge gap, measured.
The missing exception
Permalink to “The missing exception”An agent analyzes customer health scores. Three enterprise accounts get flagged for churn risk. All three are on non-standard contracts handled manually by two long-tenure reps. The exception was tribal knowledge. The agent didn’t know. The accounts call in confused, the account team is undermined, and a reliable AI output has just destroyed trust. This is why AI agents stuck in PoC so often stall at the production threshold: the PoC ran on clean, documented data; production runs on the full organizational reality, exceptions included.
The stale definition
Permalink to “The stale definition”An agent generates a board report on revenue growth comparing this quarter to two years prior. Tribal knowledge: the recognized_revenue_q4 calculation changed 18 months ago after a policy update. Pre- and post-change numbers aren’t comparable without a normalization factor. The factor lives in a finance analyst’s spreadsheet and her mental model. The report shows a growth trend that doesn’t exist. Nobody flags it until the board asks a follow-up question the agent cannot answer. This is the context vacuum in production: not a broken agent, not a wrong model, but a correct computation on an incorrect premise.
The relationship blind spot
Permalink to “The relationship blind spot”A multi-agent system: one agent scores leads, another forecasts pipeline. Marketing and sales define “stage 3 opportunity” differently; marketing counts web-qualified leads, sales counts human-qualified opportunities. Both agents pull from systems using the same terminology but different underlying definitions. The pipeline forecast runs 40% high. Nobody notices until the board review. Understanding business context for AI — specifically how business rules, terms, and team definitions connect — reveals that relationship knowledge is the highest-leverage input for multi-agent accuracy.
Agents operating without encoded tribal context will fail in production, not because the model is wrong, but because the organizational layer it needs was never built. The enterprise context layer is that infrastructure: the investment that separates AI systems that behave like practitioners from AI systems that behave like interns reading the documentation for the first time.
Inside Atlan AI Labs & The 5x Accuracy Factor
Learn how context engineering drove 5x AI accuracy in real customer systems. Explore real experiments, quantifiable results, and a repeatable playbook for closing the gap between AI demos and production-ready systems.
Download E-BookThe cost of tribal knowledge: what enterprises lose
Permalink to “The cost of tribal knowledge: what enterprises lose”Tribal knowledge loss has three measurable cost vectors, each compounding the others.
Departure cost. According to SHRM’s Retaining Talent toolkit, replacing a mid-level employee costs 6–9 months of salary, rising to 200%+ for senior specialists. The knowledge embedded in long-tenure employees is a primary driver of that replacement cost. According to Deloitte’s 2023 Human Capital Trends report, 47% of organizations identify key-person dependency (critical knowledge held by single individuals) as a significant operational risk, up from 34% in 2020. The knowledge isn’t in the role; it is in the person.
Onboarding drag. A new data professional takes 3–6 months to reach full productivity. Research suggests that 40–60% of that time is spent acquiring undocumented tribal context that already exists somewhere in the organization but has never been systematically captured. For the companion analysis of what this means for organizational continuity, see institutional knowledge loss.
AI accuracy degradation. Atlan’s Context Quality Testing (2025) found a 38% improvement in AI accuracy across 522 queries when governed, structured metadata (encoded tribal context) was added to agent context versus unstructured retrieval alone. This is the direct, measurable cost of the tribal knowledge gap on AI production systems. The tribal layer isn’t background context; it is the primary determinant of whether an agent’s output is organizationally usable.
How traditional knowledge management approaches fall short
Permalink to “How traditional knowledge management approaches fall short”Traditional solutions solve the human-to-human problem. They do not solve the human-to-agent problem, and the distinction matters now.
As Tom Davenport and Laurence Prusak observed in Working Knowledge (Harvard Business Press, 1998), tacit knowledge transfers through person-to-person interaction, not through documentation. That was a limitation before agents. With agents, it is a production gap: wikis are human-readable text that agents querying structured data systems through APIs do not read. The wiki doesn’t travel with the query. See context catalog for how the catalog layer evolved toward agent-consumable context — and why a traditional data dictionary is not sufficient.
| Approach | Solves human-to-human? | Solves human-to-agent? | Why it falls short for AI |
|---|---|---|---|
| Documentation sprints | Yes (at point in time) | No | Produces text, not structured context; goes stale |
| Wikis / Confluence / Notion | Yes | No | Agent-invisible without explicit integration |
| Exit interviews | Partially | No | Too late; captures what departing employee thinks to mention |
| Runbooks / SOPs | Yes (for documented exceptions) | Partially | Exception knowledge that never made it into the SOP is still missing |
| Pair programming / mentorship | Yes (high fidelity) | No | Non-scalable; knowledge stays tacit |
| Data dictionaries | Partially | Partially | Captures definitions but not exception context, historical changes, or interpretive heuristics |
A common objection here is RAG: if you index your wikis, Confluence pages, and Slack archives into a retrieval corpus, agents can theoretically surface tribal knowledge at query time. RAG retrieves what has been written down. Tribal knowledge that was never documented anywhere is invisible to retrieval; it is not in the corpus. And the tribal knowledge that IS somewhere in an old wiki page is rarely written to be found by a retrieval system; it was written for the one human who needed it at that moment, without the asset links, versioning, or structured format that context engineering provides. Context engineering starts from the data asset and structures context specifically for agent consumption at query time.
The context engineering framework is what replaces this table: not a better documentation sprint or a more comprehensive RAG corpus, but a fundamentally different approach to making organizational knowledge machine-consumable.
Traditional solutions were designed for humans who could read, ask questions, and apply judgment to incomplete information. Agents cannot. Every approach in the table above is a workaround to the same root problem: the knowledge was never structured for the consumer that now needs it most.
How to capture and preserve tribal knowledge in the AI era
Permalink to “How to capture and preserve tribal knowledge in the AI era”The gap documented in the previous section has a direct answer — but it requires a different category of solution. The AI-era approach is not better documentation; it is context engineering: structuring tribal knowledge as governed, versioned, machine-readable context products that agents consume at runtime via standardized protocols like MCP, rather than text files humans read after the fact.
Context agents. When tribal knowledge was never captured, context agents bootstrap what can be inferred, surfacing patterns from lineage, usage history, and related asset definitions, and create a structured review queue for what requires expert input. Context bootstrapping starts before the gap becomes a production failure; you don’t wait for the departing employee’s exit interview. For the full architecture picture of how this fits into an agent system, see context architecture for AI agents.
Context engineering. Context engineering is the discipline of structuring organizational knowledge specifically for agent consumption: not writing documentation for humans to read, but building context products for AI agents that agents consume at query time. Tribal knowledge captured through context engineering is linked to the specific data asset, versioned with the schema, and delivered when the agent needs it, not stored in a separate system it can’t reach. See the full context engineering framework for implementation patterns.
MCP-delivered institutional memory. The Atlan MCP Server provides a standard delivery mechanism: tribal knowledge encoded in a governed layer — asset definitions, business glossary terms, exception notes, historical change records. This context API becomes accessible to any MCP-compatible agent at runtime. The knowledge travels with the query. For the practical implementation path, see how to build context for LLMs in enterprise.
Versioned context repositories. Tribal knowledge that is captured doesn’t just get documented once; it gets versioned. Context versioning for AI agents means that when a business definition changes, the context layer records both the new definition and the change history. AI agent context — the full picture of what an agent needs to act correctly — includes not just current definitions but historical change records and exception rules. Agents can trace what the organizational understanding was at any given point in time, which is exactly what the “stale definition” failure mode above requires. A semantic layer provides dynamic context at the term level; a versioned context repository extends that to every data asset, exception, and historical change record in the organization.
Managing this at enterprise scale requires context management strategies that address both capture and governance. The question of who will own the context layer — data engineering, data governance, or a new context function — is one the most advanced teams are resolving now.
Real stories from real customers: Tribal context made agent-ready
Permalink to “Real stories from real customers: Tribal context made agent-ready”"We're excited to build the future of AI governance with Atlan. All of the work that we did to get to a shared language at Workday can be leveraged by AI via Atlan's MCP server…as part of Atlan's AI Labs, we're co-building the semantic layer that AI needs with new constructs, like context products."
— Joe DosSantos, VP of Enterprise Data & Analytics, Workday
The “shared language” DosSantos describes is operationalized tribal knowledge. Workday spent years building organizational consensus on what metrics mean, how data is structured, and what exceptions exist across their enterprise. That knowledge lived in people, processes, and scattered documentation. Atlan’s context layer structured it into governed, versioned context. Atlan’s MCP Server made it agent-accessible. Workday AI Labs reported a 5x improvement in AI accuracy when agents consumed governed context from Atlan versus unstructured data — the measurable outcome of tribal knowledge made machine-readable.
"Atlan is much more than a catalog of catalogs. It's more of a context operating system…Atlan enabled us to easily activate metadata for everything from discovery in the marketplace to AI governance to data quality to an MCP server delivering context to AI models."
— Sridher Arumugham, Chief Data & Analytics Officer, DigiKey
“Activate metadata” means making tribal context — data ownership, domain-specific quality rules, organizational knowledge about data assets — accessible across every channel that needs it: human discovery, AI governance, quality pipelines, and agent inference. One governed context layer; multiple delivery paths. For DigiKey, the tribal knowledge that was previously distributed across people and systems became a single, versioned, agent-consumable source. That’s the transformation the context layer enables.
Tribal knowledge is now an infrastructure problem, and the context layer is the fix
Permalink to “Tribal knowledge is now an infrastructure problem, and the context layer is the fix”Tribal knowledge that was never encoded becomes an AI production failure when agents deploy against it: not a documentation gap, not an HR problem, but a production infrastructure gap. Every piece of unencoded organizational context is a reliability risk that the context layer exists to close.
For 40 years, tribal knowledge was managed through human systems: documentation, mentorship, wikis, runbooks. Those systems worked because the consumer of the knowledge was human, capable of asking follow-up questions, recognizing when something looked wrong, and reaching for the phone when the output didn’t match operational reality.
AI agents cannot do any of those things.
The moment you deploy agents against enterprise data, every piece of tribal knowledge that was never encoded becomes a production reliability risk. Not a knowledge management risk. Not an HR risk. A production risk — the kind that produces confident, well-formatted, wrong outputs that compound across every decision they touch.
Contextual intelligence — the kind where AI has access to the tribal layer — behaves differently from AI that doesn’t. The difference is not the model. It’s whether the context layer exists. According to McKinsey’s State of AI (2024), 65% of enterprises use generative AI in at least one function, but only 16% have reached production scale with consistent outputs. The gap between 65% and 16% is largely a context gap, and tribal knowledge is its largest, least visible component.
The organizations building durable AI systems — not just PoC demos — are investing in the enterprise context layer before they worry about which model to use. Understanding why enterprises need a context layer is increasingly the conversation happening at the leadership level before any agent deployment decision. Measuring the context layer ROI — reduced AI errors, faster onboarding, lower key-person risk — is how organizations justify that infrastructure investment. How tribal context propagates through the organization’s full data graph, and why that matters for agent reliability at scale, is covered in detail in enterprise data graph. The infrastructure decision that determines agent reliability is not the model choice; it is whether the context layer exists.
FAQs
Permalink to “FAQs”1. What is tribal knowledge in the workplace?
Permalink to “1. What is tribal knowledge in the workplace?”Tribal knowledge in the workplace is informal expertise: process shortcuts, exception rules, historical context, and unwritten norms that employees accumulate through experience but never formally document. It transfers through conversation and observation, not systems. It is called “tribal” because, like oral knowledge in a tribe, it exists within the group and is invisible to outsiders, including new hires and AI agents.
2. What is the difference between tribal knowledge and tacit knowledge?
Permalink to “2. What is the difference between tribal knowledge and tacit knowledge?”Tacit knowledge, defined by Nonaka and Takeuchi in The Knowledge-Creating Company (1995), is implicit expertise that is difficult to articulate: intuition, physical skills, creative judgment. Tribal knowledge is the organizational subset: undocumented know-how specific to a company, team, or system. All tribal knowledge is tacit; not all tacit knowledge is tribal.
3. Why is tribal knowledge a problem for AI agents?
Permalink to “3. Why is tribal knowledge a problem for AI agents?”AI agents query what is in the data. They have no access to exception rules, historical context, or interpretive heuristics that were never encoded anywhere. The result is outputs that are technically correct but organizationally wrong: the numbers add up, the query completed successfully, and the business decision made on that output is quietly, systematically incorrect.
4. How do you capture tribal knowledge before an employee leaves?
Permalink to “4. How do you capture tribal knowledge before an employee leaves?”Start before departure: schedule structured knowledge transfer sessions, record them, and map the output to specific data assets and systems rather than writing general documentation. Use a context layer to encode the output as versioned, asset-linked context rather than a wiki page. Exit interviews are too late; continuous context capture is the goal.
5. What are examples of tribal knowledge in data teams?
Permalink to “5. What are examples of tribal knowledge in data teams?”Common examples: a field named calc_temp_v2 that only two engineers know is a deprecated staging column; a metric redefined mid-year whose old and new values are not comparable; a pipeline that fails the last Friday of every month due to an upstream maintenance window; a customer segment categorized one way in the CRM but handled differently in every downstream report.
6. How does a context layer solve the tribal knowledge problem?
Permalink to “6. How does a context layer solve the tribal knowledge problem?”A context layer converts tribal knowledge into governed, versioned, machine-readable context that agents consume at runtime via protocols like MCP. Instead of documenting exceptions for humans to read, you encode them as structured context linked to specific data assets. When a business rule changes, the context layer versions the change; agents consuming that context get the correct interpretation for that period.
7. What tools help manage tribal knowledge at scale?
Permalink to “7. What tools help manage tribal knowledge at scale?”Traditional tools such as Confluence, Notion, and Guru solve human-to-human tribal knowledge transfer. For AI-era requirements, the relevant tools are context layers: platforms that structure tribal knowledge as governed, versioned, agent-consumable context products, with asset-linked context, versioning, and MCP delivery so context reaches agents at inference time.
8. What is tribal knowledge in manufacturing?
Permalink to “8. What is tribal knowledge in manufacturing?”In manufacturing, tribal knowledge is the operational expertise machine operators develop over years — knowing which settings work best for a specific material batch, how to read early signs of equipment failure, or which quality anomalies to flag versus ignore. The challenge of encoding it is identical to the data domain: it is implicit, experiential, and rarely written down.
Sources
Permalink to “Sources”-
Bureau of Labor Statistics - Job Openings and Labor Turnover Survey 2023
-
Atlan AI Labs - Enhanced Metadata Improves Query Accuracy (2025): 38% improvement in AI accuracy across 522 queries with governed metadata vs. unstructured retrieval
-
Workday AI Labs (2025, via Atlan) - Atlan AI Labs E-Book: 5x improvement in AI accuracy with governed context from Atlan context layer
