



















What value does context engineering add to RAG agents?
Permalink to “What value does context engineering add to RAG agents?”RAG answers a runtime question: what should this agent fetch right now? Context engineering answers the underlying system question: which knowledge is safe, current, relevant, and sufficiently governed to become agent context?
That matters when a RAG agent moves from demo to production. A retrieval-augmented generation pipeline can search documents, then use chunks to answer a question or package them as context for an agent task. It does not know if a definition is certified, whether a column is deprecated, whether a policy blocks a field, or whether Finance and Sales disagree on a metric.
This is where context engineering becomes useful for enterprises, as it determines which definitions, policies, lineage, and freshness signals should accompany the answer.
Anthropic describes context engineering as the work of curating and maintaining the information that enters an agent’s context during inference, including tools, external data, message history, and MCP. Gartner’s July 2025 summary uses the same direction of travel: leaders need context-aware architectures and dynamic data, not prompt tweaks alone.
For RAG builders, the message is simple. Do not throw RAG away. Upgrade what surrounds it.
A context-engineered RAG agent adds:
- Governed sources: Glossary definitions, policies, quality signals, owners, certifications, and freshness checks that tell the agent which sources are fit to use.
- Semantic structure: A semantic layer and entity model that clarifies what “customer,” “ARR,” or “active account” means in the enterprise.
- Graph context: Relationships across terms, tables, dashboards, people, policies, and decisions, often through a context graph.
- Policy-aware retrieval: Governance filters that enforce access, classification, purpose, and regional rules before context reaches the agent.
- Evaluation loops: Golden questions, persona tests, trace review, and drift detection that catch stale, unsafe, or conflicting context before users do.
The result is not “better RAG” in the narrow sense. It is RAG connected to a context layer that makes retrieval dependable.
This is also why larger context windows do not solve the production problem on their own. A larger window can hold more text, but it cannot decide which ARR definition is certified, which regional policy applies, or which stale dashboard should be excluded. The goal is a minimum viable governed context: the smallest set of definitions, policies, lineage, sources, and trust signals that can bring out an answer that is grounded and up-to-date.
Build Your AI Context Stack
Get the blueprint for implementing context graphs across your enterprise. This guide walks through the four-layer architecture — from metadata foundation to agent orchestration — with practical implementation steps for 2026.
Get the Stack GuideWhat does the architecture look like?
Permalink to “What does the architecture look like?”A context-engineered RAG agent has one extra architectural layer that basic RAG setups often leave implicit: the context layer between the data warehouse and agent execution.
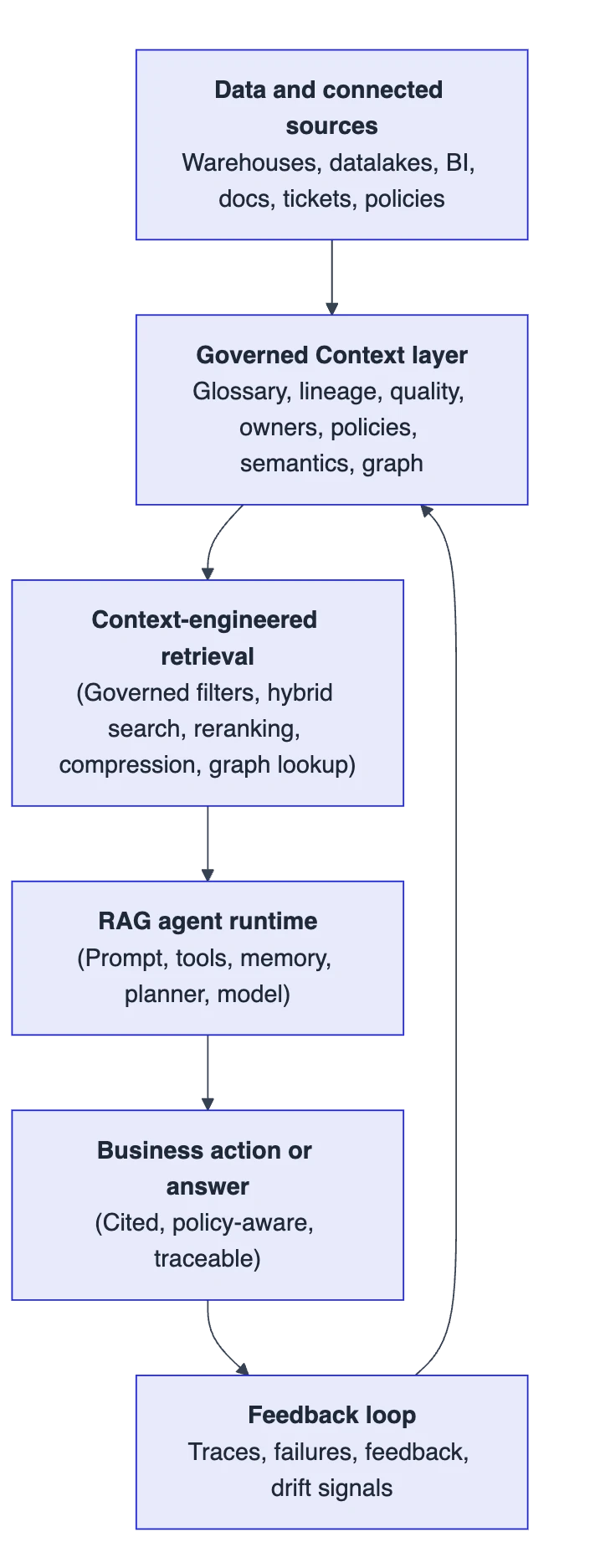
In basic RAG, the retrieval index often sits directly beside the agent. Documents go in, chunks come out, and the model generates an answer.
In context-engineered RAG, the retrieval path is mediated by shared infrastructure. The context layer for enterprise AI sits between the data warehouse, connected sources, and the agent execution layer. It determines what the agent can know, how that knowledge is represented, and which governance signals accompany it.
That layer can still feed a vector database and support hybrid search. It can also support graph-based retrieval, in which the agent follows relationships among terms, tables, dashboards, policies, and owners rather than relying solely on similar text chunks. GraphRAG is a more advanced form of RAG that uses those relationships to improve retrieval.
The point is that the index is no longer a pile of chunks. It becomes a governed view of the enterprise.
Microsoft Research describes GraphRAG as a combination of text extraction, network analysis, prompting, and summarization. That is a useful pattern for RAG agents that need a multi-hop context. But graph retrieval still depends on graph quality. If the relationships are stale or policy-blind, the agent inherits those flaws.
The architectural shift is from treating retrieval as a standalone pipeline to treating it as a consumer of governed context.
The upgrade starts by changing the operating model, not the agent framework. A naive RAG system trusts the index. A context-engineered RAG system treats retrieval as one step in a governed context path.
| RAG step | Naive RAG pattern | Context-engineered pattern |
|---|---|---|
| Source selection | Retrieve from indexed documents | Retrieve from certified, owned, policy-aware sources |
| User context | Treat most questions the same way | Apply role, region, purpose, and domain constraints |
| Ranking | Prioritize semantic similarity | Combine similarity with freshness, quality, lineage, and usage signals |
| Business meaning | Depend on nearby text chunks | Add glossary terms, semantic rules, metrics, owners, and relationships |
| Context packaging | Send the top chunks to the model | Compress, order, deduplicate, and annotate the smallest useful payload |
| Traceability | Log the final answer | Log sources, policies, rankings, context versions, and user feedback |
The important changes are system responsibilities:
- Before retrieval: Source eligibility is checked against ownership, certification, access, purpose, and domain.
- During retrieval: Chunks are filtered and ranked using freshness, quality, and lineage, not semantic similarity alone.
- Alongside retrieval: Graph context supplies the relationships that a flat chunk search misses.
- Before generation: Compression preserves the fields that make enterprise answers auditable.
- After generation: The trace returns to the context layer so failures can improve the next version.
Here is the same idea in a simple Python-style example. Imagine a finance analyst asks, “What drove ARR changes this quarter?”
Naive RAG example
Permalink to “Naive RAG example”In naive RAG, the system searches the vector index, takes the top chunks, and sends them to the model.
def naive_rag(question, vector_index, llm):
retrieved_chunks = vector_index.search(question, top_k=8)
answer_prompt = build_answer_prompt(
question=question,
context=retrieved_chunks,
instruction="Answer using only the retrieved context.",
)
answer = llm.generate(answer_prompt)
return answer
That pattern is useful, but it assumes the retrieved chunks are trustworthy. The prompt can tell the model how to use the chunks, but the pipeline still does not check whether the ARR definition is certified, whether the source is fresh, whether the user can see the underlying data, or whether the answer should include lineage and policy notes.
Context-engineered RAG example
Permalink to “Context-engineered RAG example”Context-engineered RAG adds those checks before and after retrieval. The retriever asks the context layer which sources, definitions, and rules are safe to use before the model answers.
def context_engineered_rag(question, user, context_layer, vector_index, llm):
task_context = {
"domain": "finance",
"purpose": "financial_analysis",
"user_role": user.role,
"region": user.region,
}
eligible_sources = context_layer.find_eligible_sources(
question=question,
domain=task_context["domain"],
required_status="certified",
user_role=task_context["user_role"],
region=task_context["region"],
purpose=task_context["purpose"],
)
business_context = context_layer.lookup_graph(
terms=["ARR", "customer", "renewal"],
include=["definitions", "owners", "lineage", "policies"],
)
retrieved_chunks = vector_index.search(
question,
top_k=20,
filters={
"source_id": [source.id for source in eligible_sources],
"restricted": False,
},
)
ranked_chunks = context_layer.rerank(
question=question,
chunks=retrieved_chunks,
signals=context_layer.get_ranking_signals(
retrieved_chunks,
include=["freshness_score", "quality_score", "certification", "usage_count"],
),
)
governed_context = context_layer.compress(
items=[business_context, *ranked_chunks[:6]],
keep=["definition", "source", "owner", "lineage", "policy"],
token_budget=1800,
)
answer_prompt = build_governed_answer_prompt(
question=question,
context=governed_context,
instruction="Cite sources, flag stale context, and respect policies.",
)
answer = llm.generate(answer_prompt)
context_layer.record_trace(question, user, governed_context, answer)
return answer
Read the upgraded version from top to bottom. It starts with the user’s role, region, domain, and purpose, then asks the context layer which finance sources are eligible. It pulls graph context for the business terms, filters restricted material, reranks with quality signals, compresses the payload, builds a governed answer prompt, and records what happened for later review.
The same pattern can be exposed through the Model Context Protocol, which standardizes how LLM applications connect to external resources, prompts, and tools. In enterprise systems, that matters because context should not be rebuilt separately for every agent.
For Data Leaders Evaluating Where to Start
Atlan's CIO guide to context graphs walks through a practical four-layer architecture from metadata foundation to agent orchestration.
Get the CIO GuideWhat is the build sequence for context-engineered RAG?
Permalink to “What is the build sequence for context-engineered RAG?”Teams usually do not need a full rebuild. They need a disciplined migration path from “retrieve from an index” to “retrieve from governed context.”
Bootstrap the context layer
Permalink to “Bootstrap the context layer”Start with the material your RAG agent already depends on, then add the missing governance signals around it.
Useful context bootstrap inputs include:
- Documents and schemas: Source docs, tables, columns, dashboards, and APIs already used by the RAG system.
- Business meaning: Glossary terms, metric definitions, semantic models, and domain vocabularies.
- Operational metadata: Query history, BI usage, owners, freshness, quality scores, and data lineage.
- Governance metadata: Classifications, access policies, retention rules, consent constraints, and regional boundaries.
- Agent traces: Failed answers, disputed definitions, missing citations, and repeated user corrections.
The output is not a bigger index. It is an initial context model: what concepts exist, where they come from, who owns them, how they relate, and what rules govern them.
Test the context before the agent uses it
Permalink to “Test the context before the agent uses it”RAG evaluation usually asks whether the retrieval found relevant chunks. Context evaluation asks whether the chunks were allowed, current, coherent, and enough for the task.
Test suites should include:
- Golden questions: Common business questions with approved answers and required sources.
- Persona tests: Same query from Finance, Sales, Legal, and Support to confirm permissions and interpretation.
- Freshness tests: Queries that should fail or warn when definitions, schemas, or policies are stale.
- Conflict tests: Terms with known ambiguity, such as “customer,” “revenue,” or “active account.”
- Policy tests: Attempts to retrieve restricted data, cross-region data, or context outside the user’s purpose.
This is where many RAG systems change most. You stop asking only “did the retriever find something similar?” You start asking, “Did the agent receive the right context for this user, this task, and this moment?”
Deploy context as a reusable product
Permalink to “Deploy context as a reusable product”Once a context bundle passes tests, deploy it as a reusable unit. That unit can feed a RAG service, an agent framework, a BI copilot, or a custom app.
Atlan calls these reusable units context repos. The broader pattern is what matters: context should be versioned, portable, and policy-embedded. When the definition of ARR in the finance function changes, every subscribing agent should know which version they are using and when to update.
For agent delivery, teams usually choose one of three paths:
| Delivery path | Best fit | Watch-out |
|---|---|---|
| API retrieval | Custom RAG services with mature platform teams | Teams must maintain auth, schema contracts, and versioning |
| MCP server | Agents and tools that need a standard context interface | Tool descriptions and resource access need a security review |
| Context repo | Multiple agents using the same business context | Requires clear ownership and release controls |
Observe traces and context drift
Permalink to “Observe traces and context drift”Production context changes every day. Tables are renamed, dashboards are retired, policies shift, owners leave, and users correct the agent in chat. Teams need context drift detection to catch those changes before stale context shapes the next answer.
Observation should track:
- Which sources did the agent use?
- Which definitions did it rely on?
- Whether it cited a certified or stale context.
- Which user role asked the question?
- Which policy filters were run?
- Which answer was accepted, edited, escalated, or rejected?
Those traces become the maintenance loop for context engineering. The goal is not a perfect launch. The goal is a system that gets safer and more accurate as it is used.
Which RAG upgrades matter most?
Permalink to “Which RAG upgrades matter most?”RAG teams have a long menu of upgrades. Context engineering helps put them in the right order.
| Upgrade | What it improves | What it will not fix |
|---|---|---|
| Hybrid search | Finds content across vector and keyword signals | Stale or conflicting source knowledge |
| Reranking | Improves the ordering of retrieved candidates | Missing policies, owners, and lineage |
| Graph lookup | Adds relationships across entities, terms, and decisions | Poor graph modeling or outdated edges |
| Compression | Fits more useful context into the model window | Loss of important exceptions if rules are weak |
| Governed filters | Keeps restricted or uncertified context out | Bad context that is incorrectly marked as certified |
| MCP delivery | Standardizes agent access to context and tools | Weak source governance behind the interface |
| Evaluation harnesses | Finds failures before deployment | Undefined ownership for fixing failed context |
The pattern is consistent. Retrieval upgrades help most when the underlying context is already trustworthy. If the source layer is wrong, every upgrade makes the wrong answer faster, cleaner, or more confident.
How does Atlan support context engineering for RAG agents?
Permalink to “How does Atlan support context engineering for RAG agents?”In an enterprise RAG stack, Atlan sits between the data estate and the agent execution layer. It turns metadata, glossary definitions, lineage, policies, quality signals, and usage history into machine-readable context that agents can consume through APIs, repos, or MCP.
Core capabilities include:
- Context Engineering Studio: A workspace to bootstrap context, run simulations and diagnostics, refine semantic models, deploy context repos, and observe traces and drift.
- Context Lakehouse: A context store for open, graph-aware, AI-ready context across the data estate.
- Enterprise Data Graph: A connected map of assets, lineage, usage, owners, quality, and governance signals.
- Active Ontology: A living model of business entities and relationships, so agents retrieve canonical meaning rather than disconnected chunks.
- Active metadata: Freshness and usage signals that keep context from becoming static documentation.
- Atlan MCP Server: A way to expose governed context to AI tools and agents through a standard interface.
That matters because production RAG is rarely one agent. It becomes a portfolio of agents: a finance analyst, a support copilot, a compliance reviewer, a data steward assistant, and an executive briefing agent. Each one should not rebuild its own meaning of “customer,” “revenue,” or “policy exception.”
Shared context infrastructure lets every agent retrieve from the same governed foundation while still shaping context for its own task.
Wrapping Up
Permalink to “Wrapping Up”If your RAG agent works in demos but breaks in production, audit the context before retuning retrieval.
Ask four questions:
- Which sources are allowed to be part of the agent context?
- Which definitions are certified, owned, and up to date?
- Which policy and lineage signals travel with retrieved content?
- Which traces feed back into the context layer after deployment?
That audit usually shows the real work. RAG retrieves what you have. Context engineering makes sure what you have is worth retrieving.
Read the RAG vs. context engineering guide for the conceptual distinction, then use Atlan’s context engineering framework to turn the upgrade path into a build plan.
Book a demo to see how Atlan helps teams build governed context for production AI agents.
FAQs about context engineering for RAG agents
Permalink to “FAQs about context engineering for RAG agents”Does context engineering replace RAG?
Permalink to “Does context engineering replace RAG?”No. Context engineering makes RAG more reliable by improving the context that RAG retrieves from and the rules that shape retrieval. RAG remains the runtime pattern for fetching relevant information. Context engineering adds the governance, semantic structure, testing, and feedback loops that production agents need.
Can I use context engineering without changing my RAG framework?
Permalink to “Can I use context engineering without changing my RAG framework?”Yes. Context engineering sits upstream of the RAG pipeline. Whether you use LangChain, LlamaIndex, Haystack, or a custom stack, you can treat the context layer as a governed source that feeds better input into your existing retrieval system.
What is the difference between a context layer and a vector database?
Permalink to “What is the difference between a context layer and a vector database?”A vector database stores embeddings and performs similarity search. A context layer is the governance, semantic, and operational infrastructure that decides which knowledge should be vectorized, who can access it, whether it is current, and how it should be used. Many teams use both: the context layer supplies governed, fresh, policy-aware content, and the vector database makes it fast to retrieve.
How do I know if my RAG system needs context engineering?
Permalink to “How do I know if my RAG system needs context engineering?”Ask these questions: Does your agent sometimes cite deprecated definitions? Do Finance and Sales get different answers to the same question? Can you explain which policy or lineage signal shaped the last answer? If any of those are unclear, context engineering can help.
What is the first step in upgrading RAG with context engineering?
Permalink to “What is the first step in upgrading RAG with context engineering?”Start with a context audit. Map the sources your RAG system already uses, identify who owns each definition, check which ones are certified, and find out which policies should filter retrieval. That audit usually reveals the gaps before any new tooling is needed.
