



















Build Your AI Context Stack
Get the blueprint for implementing context graphs across your enterprise. This guide walks through the four-layer architecture—from metadata foundation to agent orchestration—with practical implementation steps for 2026.
Get the Stack GuideWhy connect context graph and agent memory?
Permalink to “Why connect context graph and agent memory?”AI agents used in real enterprise workflows need two things: continuity across sessions and tasks, and access to governed enterprise truth. Agent memory provides the first. A context graph provides the second. Without connecting them, most enterprise agents will fail in production.
Here’s the problem each one solves, and why neither is sufficient on its own.
What agent memory solves: Without memory, an agent forgets. Every session starts from scratch. The agent cannot recall user preferences, previous task outcomes, or what it learned in an earlier run. For multi-step and multi-session workflows, this breaks continuity and forces repetitive context loading into every prompt.
What a context graph solves: Without a context graph, an agent lacks ground truth. It cannot look up what “net revenue” means in Finance versus Sales, trace a metric back to its certified source, or check whether an action is allowed under the current compliance policy. The agent must guess, and guesses compound into hallucinations at machine speed.
Why both matter together: An agent that has memory but no context graph accumulates private, ungoverned impressions that drift from enterprise reality as definitions change. An agent that has a context graph but no memory cannot remember what it did three tasks ago or adapt to a user’s working preferences. The integration creates a production-grade agent: one with continuity, access to governed context, and the ability to improve over time.
What are the types of agent memory?
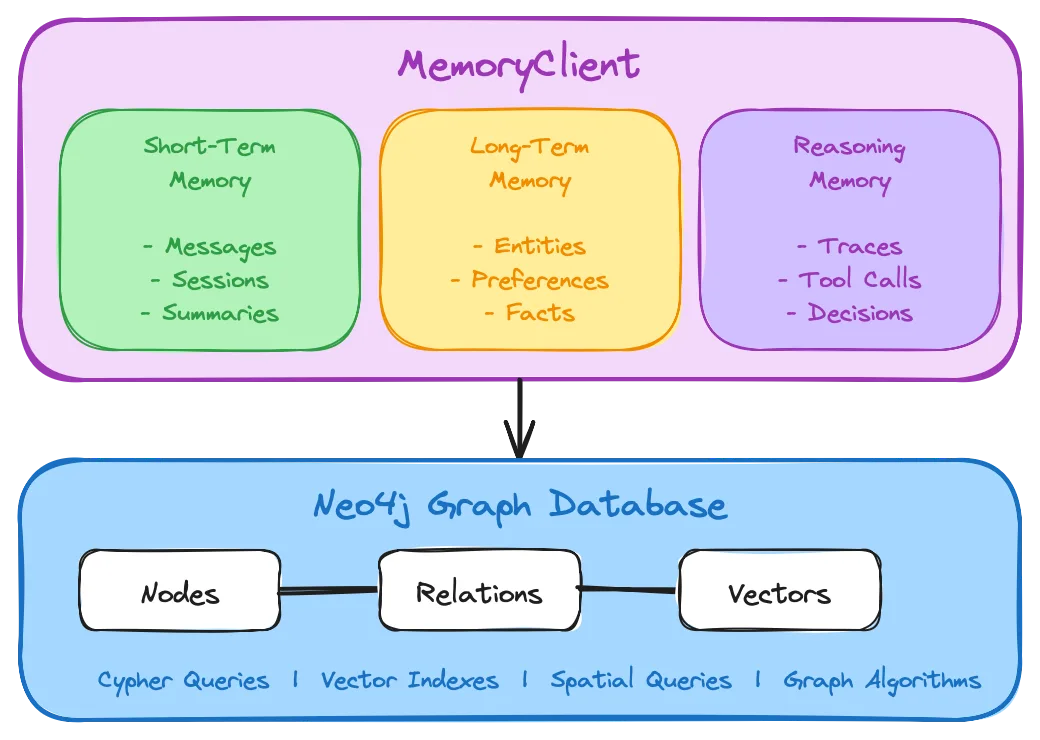
Permalink to “What are the types of agent memory?”Agent memory divides first into short-term and long-term, with a third category, reasoning memory, capturing how the agent actually reasoned. Each plays a different role, and each connects to a context graph in its own way.
| Memory type | What it stores | Lifespan | Relevance to context graph |
|---|---|---|---|
| In-context | Current session reasoning, tool outputs, conversation | Until context window closes | Context graph outputs land here during a run |
| External short-term | Task-scoped state, intermediate results | Task or session duration | Feeds the agent between steps; context graph data is cached here |
| External long-term | User preferences, agent learnings, historical decisions | Cross-session, persistent | Can become stale without context graph refresh; write-back target |
| Episodic | Records of past interactions and outcomes | Persistent, queryable | Pairs with context graph decision traces for audit and precedent |
| Semantic | Factual knowledge the agent has internalized | Persistent | Must be refreshed from context graph as enterprise definitions change |
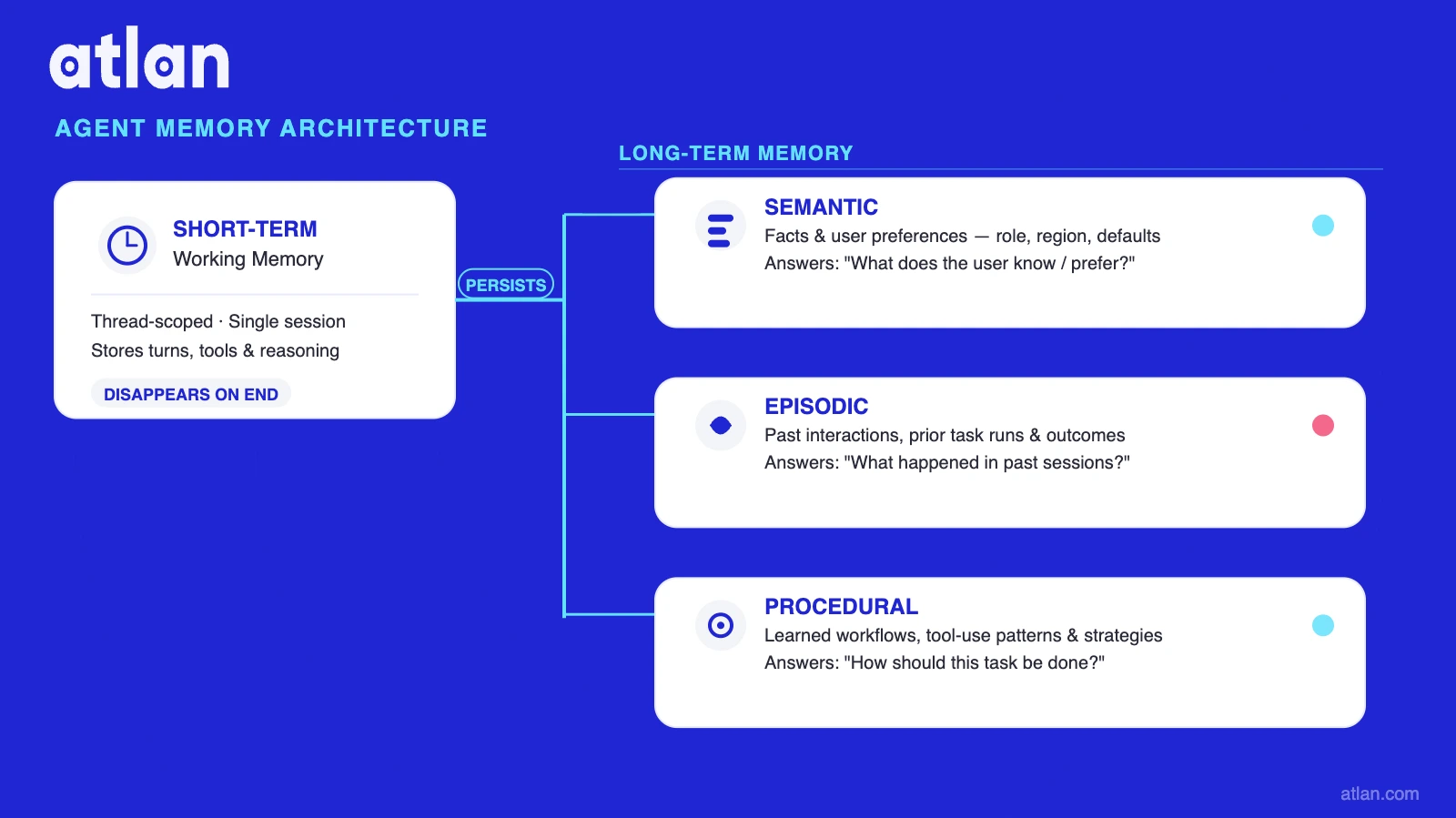
Caption: How AI agents store, recall, and apply knowledge across sessions and systems. Image by Atlan
The context graph is most directly relevant to external long-term and semantic memory, because those are the types that accumulate knowledge about the enterprise over time and can drift most severely when not grounded in governed, current context.
For Data Leaders Evaluating Where to Start
Atlan's CIO guide to context graphs walks through a practical four-layer architecture from metadata foundation to agent orchestration.
Get the CIO GuideHow to connect context graph to agent memory: The integration pattern
Permalink to “How to connect context graph to agent memory: The integration pattern”The integration is not a one-time setup. It is a runtime loop that happens on every agent run.
Step 1: Register session context in agent memory
Permalink to “Step 1: Register session context in agent memory”At the start of each task, the agent loads its working state into memory: task scope, user preferences from prior sessions, and the working set of assets it will operate on. This is the memory layer’s job, handled by frameworks like Mem0 for long-term memory or LangGraph state for task-scoped memory.
Step 2: Read from both at inference time
Permalink to “Step 2: Read from both at inference time”When the agent needs to act on a business concept, it queries two sources simultaneously:
- From agent memory: Session context, user preferences, recent decisions from the current task.
- From the context graph: Governed definitions, lineage, policies, certification status, ownership, and historical decisions from other agents.
The context graph query typically runs through the MCP or an API, returning a governed subgraph the agent grounds its reasoning on. The memory query runs through the memory framework’s retrieval interface.
Step 3: Write back to both under approval rules
Permalink to “Step 3: Write back to both under approval rules”After the agent acts, it writes observations and decisions to both layers:
- To agent memory: Session outcome, user preference signals, intermediate state for the next step.
- To the context graph: Governed write-back of decisions, corrections, and quality observations, under the approval rules and audit log required by the context graph’s governance model.
The distinction matters: agent memory writes are typically agent-private and session-scoped, while context graph writes are shared and governed. Not every agent observation deserves to become shared enterprise truth, so the governance gate on context graph write-back is critical.
What memory frameworks are compatible with a context graph?
Permalink to “What memory frameworks are compatible with a context graph?”Any agent memory framework can be integrated with a context graph because the integration happens at the tool-calling layer, not through framework-specific bindings. The most commonly used frameworks:
Mem0: A managed long-term memory service that stores agent learnings and user preferences across sessions. Compatible with any context graph accessible through an API or MCP because the agent calls both sources independently and merges the results in its reasoning.
LangGraph state: Task-scoped memory built into the LangGraph workflow framework. State is passed between nodes in the graph and can include context graph query results cached earlier in the workflow. See the companion guide on implementing a context layer in LangGraph.
Custom vector or key-value stores: Teams with specific requirements often build their own memory layer. Integration follows the same pattern: the agent calls both the memory store and the context graph as separate tools and grounds its reasoning on both results.
The key architectural principle is to keep the memory store and the context graph as separate layers with clear interfaces rather than merging them into one store. Each optimizes for different things: the memory store for agent-specific, fast retrieval; the context graph for governed, traversable, shared enterprise truth.
What are the common failure modes in connecting these systems?
Permalink to “What are the common failure modes in connecting these systems?”Understanding what goes wrong helps teams avoid it.
Memory drift without context graph refresh: An agent’s long-term memory stores a definition of “revenue” learned in Q3. By Q1 the following year, Finance has updated the definition, but the agent’s memory has not been refreshed. The agent answers confidently from a stale impression. The fix is to treat context graph data as the authoritative source and validate long-term memory against it on a schedule.
Context graph queries without memory context: An agent queries the context graph for the “standard revenue metric” without knowing from memory that the user’s team uses a non-standard fiscal year variant. The query returns the global definition, which is technically correct but wrong for the context. The fix is to include relevant memory signals in the query parameters before calling the context graph.
Ungoverned write-back to the context graph: An agent writes an observation directly to the context graph without an approval rule in place. If the observation is wrong or based on stale session data, it contaminates the shared graph. The fix is to enforce approval rules on every context graph write, starting with human-in-the-loop approval, then expanding as trust is established.
Siloed memory stores per agent: Each agent maintains its own memory that never influences shared context. Corrections and decisions do not compound. The fix is to design memory architecture with shared write-back to the context graph for observations that represent organizational learning, not just agent-specific state.
How does Atlan support context graph and memory integration?
Permalink to “How does Atlan support context graph and memory integration?”Atlan is designed to serve as the governed context graph layer in this architecture. Through its MCP server, agents running on any framework can call Atlan at inference time to retrieve certified definitions, lineage, quality signals, and policy context. Through its AI Governance layer, agent write-back is logged, attributed, and made auditable.
What Atlan adds to the integration:
- Governed context graph queries: The MCP server exposes tools for asset search, lineage traversal, glossary resolution, and policy checks. These integrate with memory frameworks through the same tool-calling pattern the agent uses for any external tool.
- Decision traces: Every context graph query and write-back is logged with attribution, creating an auditable record of what the agent used and what it changed.
- Context refresh signals: As definitions, policies, and certifications change in Atlan, the context graph reflects those updates in real time. Memory frameworks can validate stored knowledge against the current context graph to detect and resolve drift.
- Bidirectional write-back: Atlan supports governed agent write-back through its MCP tools, so agents can update descriptions, tags, quality annotations, and metadata under approval rules, and those updates become part of the shared context graph.
The result is an architecture where memory gives agents continuity, the context graph gives them governed enterprise truth, and both compound over time through governed write-back.
Inside Atlan AI Labs & The 5x Accuracy Factor
Learn how context engineering drove 5x AI accuracy in real customer systems. Explore real experiments, quantifiable results, and a repeatable playbook for closing the gap between AI demos and production-ready systems.
Download E-bookReal stories from real customers building enterprise context layers
Permalink to “Real stories from real customers building enterprise context layers”How Workday is building an AI-ready semantic layer
Permalink to “How Workday is building an AI-ready semantic layer”"Atlan captures Workday's shared language to be leveraged by AI via its MCP server. As part of Atlan's AI labs, we're co-building the semantic layer that AI needs."
- Joe DosSantos, VP Enterprise Data & Analytics, Workday
How DigiKey built a unified, sovereign context layer for its data and AI estate
Permalink to “How DigiKey built a unified, sovereign context layer for its data and AI estate”"Atlan is our context operating system to cover every type of context in every system including our operational systems. For the first time we have a single source of truth for context."
- Sridher Arumugham, Chief Data Analytics Officer, DigiKey
Moving forward with connecting context graph to agent memory
Permalink to “Moving forward with connecting context graph to agent memory”Memory without governed context drifts. Context without memory ignores what came before. The integration is the architecture.
The operational pattern is consistent: read from both at inference time, write back to both under approval rules, and let each layer compound the other over time. Agent memory stores what happened in this session; the context graph stores what the organization has learned and decided. Together, they give agents the continuity and ground truth needed to operate reliably across enterprise workflows.
Start with a single high-value workflow. Instrument the read-from-both pattern. Add governed write-back. Then measure whether the agent’s second run on a similar task is better informed than the first.
FAQs about connecting context graph to agent memory
Permalink to “FAQs about connecting context graph to agent memory”1. What is agent memory?
Permalink to “1. What is agent memory?”Agent memory is the mechanism that gives an AI agent continuity between sessions and across multi-step tasks. It stores task state, user preferences, in-session reasoning, and observations the agent has made. Unlike context graph data, which is governed and shared, agent memory is typically agent-specific and session-scoped, though it can be persisted and shared when designed for that purpose.
2. What is the difference between agent memory and a context graph?
Permalink to “2. What is the difference between agent memory and a context graph?”Agent memory is the agent’s working notebook — task state, session context, preferences, and short-term observations. A context graph is the organization’s governed reference library — entities, relationships, policies, lineage, and certified definitions. Memory gives continuity; the context graph gives ground truth. Both are necessary, and they do different jobs.
3. What memory frameworks are compatible with a context graph?
Permalink to “3. What memory frameworks are compatible with a context graph?”The most commonly used frameworks are Mem0, which offers long-term, cross-session memory for agents; LangGraph state, which provides task-scoped memory inside a workflow graph; and custom key-value or vector stores for teams with specific requirements. All of these can be integrated with a context graph because the integration is through the agent’s tool-calling layer, not through framework-specific bindings.
4. Can agent memory replace a context graph?
Permalink to “4. Can agent memory replace a context graph?”No. Agent memory and context graphs solve different problems and cannot replace each other. Memory gives agents continuity and stores agent-specific learning. A context graph provides governed, shared enterprise truth: certified definitions, lineage, policies, and organizational decisions. An agent relying only on memory will drift from enterprise ground truth over time as definitions change and policies update.
5. What is agent write-back in the context of memory?
Permalink to “5. What is agent write-back in the context of memory?”Agent write-back is when an agent logs what it learned, decided, or corrected back to a persistent store after completing a task. For agent memory, this means storing session outcomes, preferences, and observations so future sessions are more informed. For the context graph, it means logging decisions and corrections back as governed event nodes so the shared graph improves over time. Both types of write-back compound the agent’s value across interactions.
6. How are approvals handled when an agent writes back to the context graph?
Permalink to “6. How are approvals handled when an agent writes back to the context graph?”Write-back to the context graph is rule-bound and logged. The operating principle is that only information that passes defined approval criteria becomes part of the shared graph, and every write is attributed to the agent and timestamped. This prevents unreviewed agent output from polluting the shared context while still allowing the graph to improve with each agent interaction. In practice, many teams start with human-in-the-loop approval for context graph writes before expanding to more automated governance.
