


















Atlan’s Context Engineering Studio captures production traces of every agent interaction, question, retrieved context, and generated response, and surfaces schema staleness, lineage breaks, and ownership gaps as leading-indicator alerts before bad outputs reach users.
What does AI agent monitoring cover?
Permalink to “What does AI agent monitoring cover?”AI agent monitoring involves exploring the complete trajectory of an agent’s actions by tracing inputs, thought processes, tool calls, and outputs. This helps you understand why an agent made a decision with a transparent, auditable trail.
AI agent monitoring is distinct from pre-deployment evaluation in one critical way: production exposes failure modes that staging cannot replicate, because production data changes continuously.
Practically, AI agent monitoring spans two distinct layers:
- Inference-layer monitoring: What the agent produced, how fast, at what cost, with what error rate and output quality score.
- Context-layer monitoring: Whether the metadata the agent reasons over — definitions, schemas, lineage paths, ownership records — is still accurate.
What is inference-layer monitoring? What metrics should you track?
Permalink to “What is inference-layer monitoring? What metrics should you track?”Inference-layer monitoring observes what happens during and after an agent’s reasoning: how fast it responded, how much it cost, whether it errored, and whether its output was any good. This is where most teams start, and the tooling is mature enough to handle it.
The core metrics to track include:
- Latency: Time to first token and end-to-end response time. Latency spikes signal retrieval bottlenecks, model routing changes, or tool call failures before they become user-visible errors.
- Token cost: Per-query and aggregate token consumption across input and output. Without cost tracking, agents can enter recursive loops or unexpectedly verbose retrieval patterns that are invisible to users but destructive to budgets.
- Error rates: Failed tool calls, retrieval timeouts, guardrail rejections, and model API errors. Error rates are the most direct signal that something in the agent’s execution path has broken.
- Tool call success rates: In multi-step agents, individual tool calls can succeed while the overall task fails. Tracking success rates at the tool level pinpoints exactly where execution breaks down in a complex pipeline.
- Output quality scores: Faithfulness (does the response reflect the retrieved context?) and answer relevance (does the response address what was asked?) measured through automated evaluators running in production.
Traditional APM tools track infrastructure metrics like latency and error rates. AI observability adds a critical quality dimension: was the response accurate, safe, and useful? Getting both dimensions covered is the baseline for any production deployment.
What are the best tools for AI agent inference monitoring?
Permalink to “What are the best tools for AI agent inference monitoring?”The four most widely deployed tools for inference-layer monitoring are:
- LangSmith: Built by the LangChain team, LangSmith provides end-to-end visibility into agent behavior through tracing, real-time monitoring, and alerting across token usage, latency, error rates, and costs. It is the natural choice for teams building on LangChain or LangGraph.
- Arize AI: Arize AI offers visibility into how LLMs and agents behave, from individual spans within a trace to full multi-turn sessions. Its AX platform adds continuous performance monitoring, guardrails, and cluster analysis for production deployments at scale.
- Langfuse: Langfuse is purpose-built for LLM applications for traces, evals, prompt management, and metrics. It is open source under the MIT license and supports self-hosting for teams with data residency requirements.
- WhyLabs (community project): WhyLabs, Inc. discontinued operations and open-sourced its entire platform, including whylogs and LangKit. The platform is available under the Apache 2.0 license for teams that want to run it on their own infrastructure. Note: there is no active commercial backing or ongoing feature development, so teams adopting it should treat it as a self-hosted community resource.
What is context-layer monitoring? What signals should you track?
Permalink to “What is context-layer monitoring? What signals should you track?”Here is the failure that inference monitoring cannot catch: an agent returns a well-formed, on-time, low-cost response with a faithfulness score of 0.94, and the response is factually wrong.
The output is wrong because the metric definition it retrieved was last updated eight months ago and no longer reflects how the finance team calculates revenue. Even though the agent passed every inference metric, the context the agent consumed was wrong.
Overcoming failure at the context layer requires monitoring the context layer directly — the metadata, definitions, lineage paths, and governance records that agents query before they reason.
Setting up context layer monitoring involves tracking drift across three compounding layers:
- The schema: Tables renamed, columns deprecated, or data types changed upstream without the agent’s retrieval layer being updated.
- Semantic layer: Business definitions evolved — such as how “active customer” is calculated — but the glossary the agent reads was not updated.
- Accumulated staleness: Context staleness builds across the schema and semantic layers over time. A schema definition that has not been validated in months, a glossary term with no active owner, or a lineage path that has not been traversed since a pipeline change all accumulate staleness quietly.
Four signals provide reliable early warning of drift:
- Schema version staleness: How long since this schema was validated against upstream changes? A schema unvalidated for 60 or more days while the upstream system has had recent changes is a drift risk.
- Glossary definition age: When was this business term last reviewed, and does it have an active owner? Terms older than a defined review threshold are candidates for staleness drift.
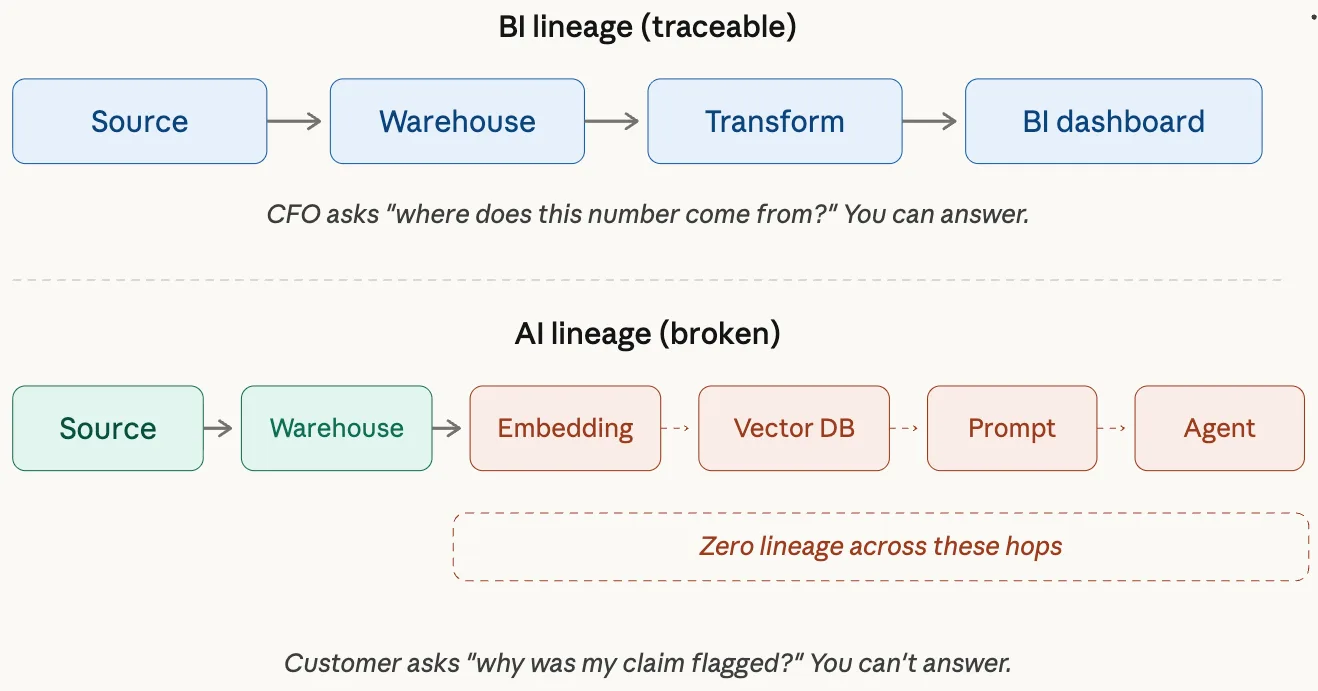
- Lineage completeness: Are the lineage paths from agent-consumed data to canonical source systems intact and traversable? Broken lineage means the agent cannot verify the provenance of what it retrieves.
- Ownership freshness: Is each definition assigned to an active stakeholder? Unowned definitions are the strongest leading indicator of future agent failure, stronger than any low faithfulness score.
How do you track context-layer signals?
Permalink to “How do you track context-layer signals?”Tracking context-layer signals requires instrumentation at the metadata layer, not the model layer. The four signals map to four concrete monitoring actions:
- Schema version staleness: Connect your monitoring setup to upstream schema registries or data catalogs. Any schema change in a source system should trigger a validation check against the agent’s retrieval configuration.
- Glossary definition age: Set review thresholds on business terms that agents query frequently. Usage metadata identifies which definitions are being retrieved most often in production, so review priority is driven by actual agent behavior. A high-usage term with no review event in 90 days and no assigned owner is a higher remediation priority than a low-usage term in the same state.
- Lineage completeness: Run continuous lineage traversal checks from agent-consumed assets back to canonical source systems. A broken lineage path is an immediate signal that the agent’s retrieval context is operating without provenance verification.
Monitoring lineage completeness as a context-layer signal for AI agents. Source: Metadata Weekly
- Ownership freshness: Monitor ownership assignment as an active signal. When a definition owner is deactivated, leaves the organization, or has not interacted with an asset within a defined window, that definition should be automatically flagged for reassignment. Unowned definitions in active agent context are the highest-priority remediation target.
Atlan’s Context Engineering Studio provides the operational surface for tracking these signals. Production traces capture every agent interaction — the question, the retrieved context, the generated response — giving teams full visibility into what agents are actually querying.
What is the role of feedback loops in AI agent monitoring?
Permalink to “What is the role of feedback loops in AI agent monitoring?”Every user correction of an agent output is a monitoring signal. A user who flags a wrong revenue figure, overrides a recommendation, or edits an agent-generated summary has identified a gap — either in inference or in the context layer below it.
Most monitoring systems log these corrections. However, logging isn’t enough. The correction needs to be routed to the right layer:
- If the agent’s reasoning was sound but its retrieved information was stale, the correction belongs in the context layer. The definition or schema that fed the bad retrieval needs to be updated and re-validated.
- If the agent’s reasoning was flawed despite accurate context, the correction belongs in the inference stack. The prompt, retrieval strategy, or output evaluator needs adjustment.
The distinction matters because most teams treat all corrections as model problems and address them at the prompt or fine-tuning layer. Corrections that trace to context drift will keep recurring regardless of how much prompt engineering is applied, because the root cause has not been addressed. Routing corrections to the right layer converts monitoring from alerting into systematic improvement.
How does a sovereign context layer help with AI agent monitoring?
Permalink to “How does a sovereign context layer help with AI agent monitoring?”Inference observability tools are good at telling you an agent is slow, expensive, or producing low-faithfulness outputs. They are not built to tell you why.
A sovereign context layer solves this by maintaining a continuously validated, governed source of the knowledge agents retrieve. Rather than treating metadata as static documentation, it treats context as active infrastructure: versioned, owned, and tested before it reaches production.
Atlan provides this context-layer surface across interconnected capabilities:
- Context Lakehouse: The knowledge architecture underneath the context layer. It combines a knowledge graph for relationships and meaning, Iceberg-native file storage, vector-native search, and full time travel for compliance and audit. When an agent makes a mistake, teams can reconstruct exactly what context the agent saw at the time it ran.
- Context Engineering Studio: The operational workspace where teams bootstrap, test, and ship the context agents consume. Every agent interaction in production is captured. When a user marks a response as wrong, the studio generates a suggested context update and routes it back to the shared context repo, so every agent reading from that repo benefits from the fix.
- Data lineage: Atlan tracks column-level lineage from source through transformation to consumption. For AI agent monitoring, lineage lets teams trace a wrong agent output back to the specific upstream asset or transformation where the context broke down.
- AI Governance: Atlan’s AI Governance provides a centralized registry for AI models and applications, with automatic discovery and cataloging of AI assets. Teams can create automated policies for model drift and other risks that continuously monitor for non-compliance, with traceable oversight integrated into Jira and ServiceNow.
- Data Quality Studio: Atlan’s Data Quality Studio lets teams define, schedule, and monitor quality rules against the data assets agents consume. The AI Guardrails capability pairs Data Quality Studio with AI Governance to ensure only high-quality data trains and feeds production models.
- MCP server: Atlan’s MCP server provides a consistent way for large language models and automation frameworks to retrieve the context they need to generate accurate and reliable results.
The practical effect is a monitoring setup where inference alerts tell you something is wrong now, and context-layer alerts tell you something is about to go wrong.
Real stories from real customers
Permalink to “Real stories from real customers”How Workday is building an AI-ready semantic layer
Permalink to “How Workday is building an AI-ready semantic layer”"Atlan captures Workday's shared language to be leveraged by AI via its MCP server. As part of Atlan's AI labs, we're co-building the semantic layer that AI needs."
Joe DosSantos
VP Enterprise Data & Analytics, Workday
How DigiKey built a unified, sovereign context layer for its data and AI estate
Permalink to “How DigiKey built a unified, sovereign context layer for its data and AI estate”"Atlan is our context operating system to cover every type of context in every system including our operational systems. For the first time we have a single source of truth for context."
Sridher Arumugham
Chief Data Analytics Officer, DigiKey
Moving forward with AI agent monitoring
Permalink to “Moving forward with AI agent monitoring”Traditional AI agent monitoring covers approximately half the problem: instrument your traces, watch your latency, set alert thresholds. It is the half that is most visible, most tooled, and most documented.
The other half lives in the context layer, which provides information on whether the knowledge the agent operates on is still accurate, still owned, still traversable. That is where the failures that inference metrics cannot catch will accumulate silently, surfacing only when a business decision built on a stale definition turns out to be wrong.
A complete monitoring strategy instruments both layers, routes user corrections to the right place, and treats context signals as the leading indicators they are. Atlan’s Context Engineering Studio provides the context-layer coverage that inference tools leave uncovered, so your monitoring setup catches both classes of failure before they reach the business.
FAQs about AI agent monitoring
Permalink to “FAQs about AI agent monitoring”1. What is AI agent monitoring?
Permalink to “1. What is AI agent monitoring?”AI agent monitoring is the practice of tracking an AI agent’s behavior in production across two layers: the inference layer (latency, token cost, error rate, output quality) and the context layer (whether the knowledge the agent retrieves is still accurate, current, and governed). Both layers require distinct signals and distinct tooling.
2. What is the difference between AI agent monitoring and LLM observability?
Permalink to “2. What is the difference between AI agent monitoring and LLM observability?”LLM observability focuses on the model’s behavior during inference — what it generated, at what cost, with what quality. AI agent monitoring is broader: it includes observability of tool calls, multi-step execution paths, retrieval quality, and the context layer the agent consumes before it generates anything. Agents can pass all LLM observability checks while failing at the context layer.
3. Which tools are used for AI agent monitoring?
Permalink to “3. Which tools are used for AI agent monitoring?”The most widely used inference-layer tools are LangSmith, Arize AI, Langfuse, and WhyLabs. LangSmith is the natural choice for LangChain-based stacks. Arize is strongest for teams with existing MLOps infrastructure. Langfuse is the leading open-source option. Context-layer monitoring requires additional tooling focused on metadata governance, schema validation, and lineage tracking.
4. What metrics should I track for AI agents in production?
Permalink to “4. What metrics should I track for AI agents in production?”At the inference layer, track latency, token cost per query, error rates, tool call success rates, and output quality scores (faithfulness, answer relevance). At the context layer, monitor schema version staleness, glossary definition age, lineage completeness, and ownership freshness.
5. What is context drift in AI agent monitoring?
Permalink to “5. What is context drift in AI agent monitoring?”Context drift is the gradual degradation of the metadata and knowledge that an AI agent retrieves and reasons over. It occurs in three compounding layers: schema drift (structural changes to upstream data that the agent’s retrieval layer has not absorbed), semantic drift (business definitions that have changed but whose glossary entries have not been updated), and staleness drift (definitions not reviewed or re-validated within an appropriate window). ML observability tools do not detect context drift because they observe inference, not context.
6. How do I set up alerting for AI agents?
Permalink to “6. How do I set up alerting for AI agents?”Set tiered alerts across both monitoring layers. For inference, alert on latency spikes (2x baseline), sustained error rate breaches (2-5% threshold depending on criticality), and output quality score degradation over a rolling query window. For context, alert when high-usage definitions breach their review threshold, when ownership becomes unassigned on frequently queried terms, and when lineage paths to canonical sources break. Context-layer alerts are leading indicators — they fire before bad outputs reach users.
7. What is the feedback loop in AI agent monitoring?
Permalink to “7. What is the feedback loop in AI agent monitoring?”Every user correction of an agent output is a monitoring signal. An effective feedback loop routes that correction to the right layer: if the agent reasoned correctly but on stale information, the fix belongs in the context layer. If the agent’s reasoning was flawed despite accurate context, the fix belongs in the inference stack. Logging corrections without routing them produces a monitoring system that alerts but does not improve.
