



















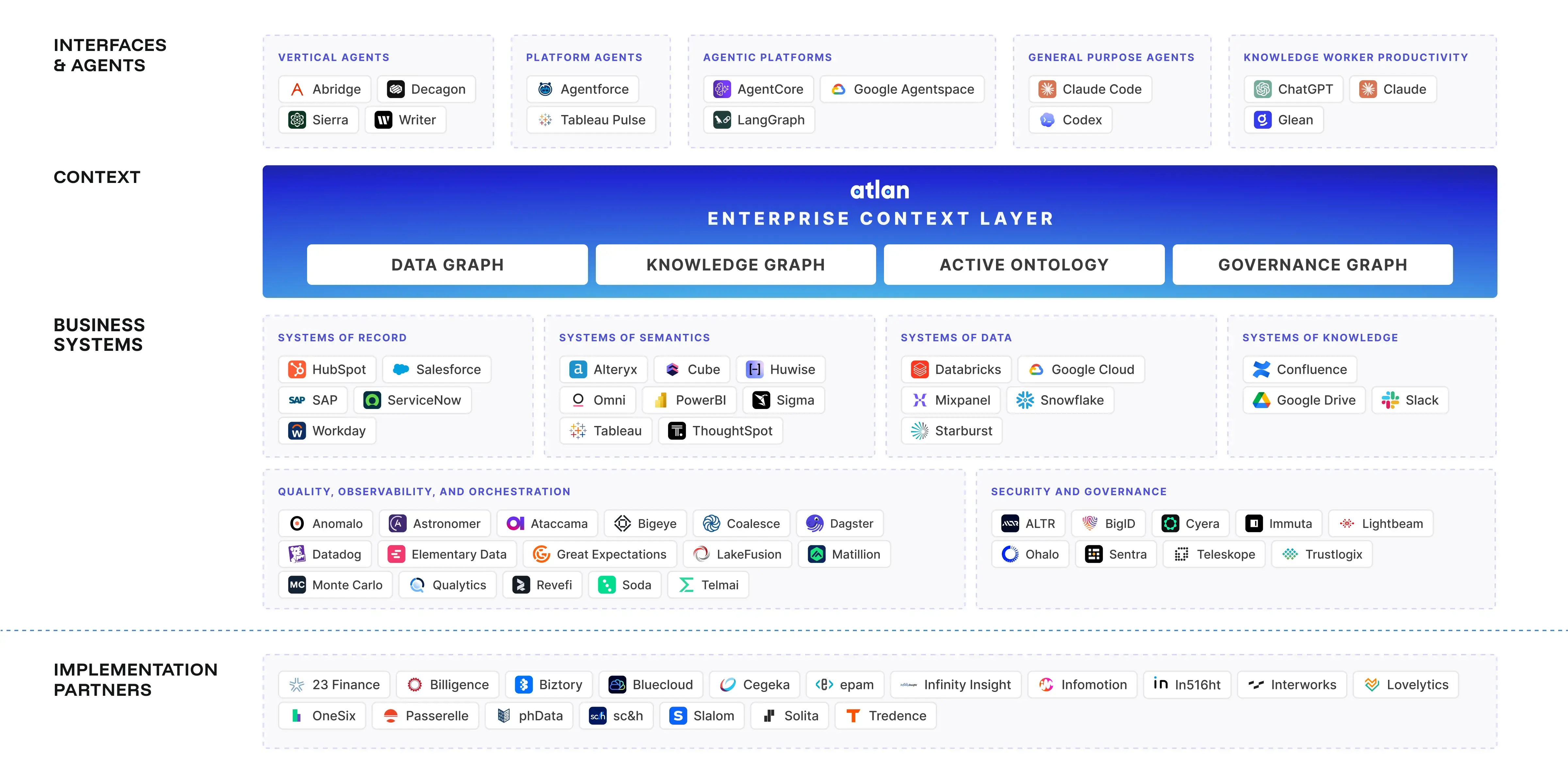
Most enterprise AI stacks have four of the five context layers. The missing one — governance — is why the others don’t work reliably.
Why the context ecosystem matters more than the model
Permalink to “Why the context ecosystem matters more than the model”The foundation model is the least differentiated part of an AI deployment. GPT-4o and Claude 3.7 Sonnet have comparable capabilities for most enterprise data tasks. What differentiates production AI systems is the quality of the context ecosystem underneath the model — what it can see, how reliably it can access it, and whether that context is governed and current.
This distinction matters because most organizations spend the majority of their AI investment on models and orchestration — the top two layers. The other three layers, especially governance, receive a fraction of the attention but determine most of the outcome.
The table below maps the five layers of the AI context ecosystem, their role, and representative tools at each layer.
| Layer | Role | Examples |
|---|---|---|
| Foundation models | Consume context, generate outputs | Claude, GPT-4o, Gemini, Llama |
| Orchestration | Manage agent workflows, tool calls | LangChain, LangGraph, CrewAI, AutoGen |
| Delivery protocols | Connect context sources to models | MCP, REST API, function calling |
| Context stores | Where context lives | Vector DBs, knowledge graphs, data catalogs, document stores |
| Governance | Determines trust, access, freshness | Data catalogs, certification systems, RBAC layers |
None of these layers is optional. An AI agent operating without context stores has nothing to retrieve. An agent with context stores but no delivery protocol has no interface. An agent with a delivery protocol but no governance returns results from uncertified, potentially stale sources. The layers depend on each other — skipping any one of them degrades everything above it.
Build Your AI Context Stack
Get the blueprint for implementing context graphs across your enterprise. This guide walks through the four-layer architecture — from metadata foundation to agent orchestration — with practical implementation steps for 2026.
Get the Stack GuideLayer 1 — Foundation models (the consumer layer)
Permalink to “Layer 1 — Foundation models (the consumer layer)”Foundation models are the consumers in the ecosystem. They receive context and generate outputs. They do not produce or govern context, and they have no memory between calls unless memory infrastructure is explicitly built into the context layer.
The choice of foundation model matters less than most teams assume. For enterprise data tasks — answering questions about metrics, traversing lineage, summarizing business definitions — GPT-4o, Claude, and Gemini all perform at similar levels when given equivalent context. The primary lever for improving output quality is context quality, not model selection.
Context window size is the one model-level characteristic that directly affects context layer design:
- Claude 3.7 Sonnet: 200K token context window
- GPT-4o: 128K token context window
- Gemini 1.5 Pro: 1M token context window (experimental)
A larger context window allows more context to be injected per agent call, which reduces the need for aggressive retrieval filtering. But context window size is a supplement to good context engineering, not a substitute. Injecting 200K tokens of ungoverned, stale context produces worse results than injecting 8K tokens of certified, current metadata.
Layer 2 — Orchestration (the agent layer)
Permalink to “Layer 2 — Orchestration (the agent layer)”The orchestration layer manages agent reasoning, tool calls, and multi-step workflows. It decides what context to fetch for each reasoning step, which tools to invoke, and how to chain outputs across steps. It is the traffic controller of the ecosystem — directing queries to the right context stores and coordinating results across multiple agents.
Key frameworks in this layer:
LangChain and LangGraph
Permalink to “LangChain and LangGraph”Graph-based agent orchestration that supports conditional logic, state management, and multi-step workflows. Well-suited for data agent workflows where the next step depends on what was found in the previous one — for example, fetching asset metadata, then traversing lineage, then querying ownership.
CrewAI
Permalink to “CrewAI”Multi-agent collaboration framework that allows specialist agents to operate in parallel and hand off to each other. Useful for workflows that span multiple domains — for example, a data quality agent and a lineage agent running in parallel and synthesizing results.
AutoGen
Permalink to “AutoGen”Microsoft’s multi-agent framework, optimized for code generation and data analysis workflows. Strong when the agent needs to generate and execute code as part of the reasoning loop.
Anthropic Agents SDK
Permalink to “Anthropic Agents SDK”Anthropic’s native agent framework. Includes direct MCP support and is optimized for Claude context handling and tool use. The most natural integration point for Atlan’s MCP server when Claude is the foundation model.
The choice of orchestration framework should match workflow complexity. Simpler workflows — a single-step retrieval or a straightforward lookup — don’t need graph orchestration. More complex workflows with conditional branching, multi-agent collaboration, or iterative refinement benefit from LangGraph or CrewAI’s structure.
Layer 3 — Delivery protocols (the interface layer)
Permalink to “Layer 3 — Delivery protocols (the interface layer)”Delivery protocols are how context sources expose themselves to AI agents. This is the infrastructure layer that determines whether agents can access context at all — and whether access is generic or structured.
MCP (Model Context Protocol)
Permalink to “MCP (Model Context Protocol)”MCP is Anthropic’s open standard for connecting data sources to AI models as callable tools. An MCP server registers a set of tools — search, query, retrieve, filter — and any MCP-compatible agent can call those tools without custom integration per source.
This is the architectural significance of MCP: it decouples the agent from the data source. Before MCP, adding a new context source meant writing custom integration code for each agent that needed to use it. With MCP, any MCP server is immediately callable by any MCP-compatible agent. The enterprise context layer becomes composable — add a new context source by spinning up an MCP server, not by rewriting agent code.
MCP is also how governed data catalogs like Atlan expose themselves to AI agents. The Atlan MCP server registers tools for searching assets, retrieving lineage, querying the business glossary, and accessing certification status — all through a standardized interface that any agent framework can call.
REST APIs and function calling
Permalink to “REST APIs and function calling”Traditional integration patterns. Still dominant for custom integrations and for data sources that haven’t adopted MCP. REST requires per-source implementation — each new context source needs its own connector and maintenance burden. Function calling (OpenAI’s pattern) is similar to MCP but OpenAI-specific. Both patterns work, but neither gives you the composability benefit that MCP provides.
The following diagram shows MCP as the protocol layer between agents and the context stores that serve different context types.
MCP sits between the agent and every context source — a universal interface that replaces per-source custom integrations.
Layer 4 — Context stores (the storage layer)
Permalink to “Layer 4 — Context stores (the storage layer)”Context stores are where different types of context live. They are not interchangeable. Each optimizes for a different context type and retrieval pattern, which is why production AI systems use multiple stores in combination rather than picking one.
Vector databases — for semantic and unstructured context
Permalink to “Vector databases — for semantic and unstructured context”Vector databases store embeddings — numeric representations of documents, code, or other text — and retrieve them by semantic similarity. If an agent asks “what’s our revenue recognition policy,” a vector store can surface the most semantically similar policy document even if the exact words don’t match.
Common vector databases: Pinecone, Weaviate, Chroma, pgvector, Qdrant.
Best for: policy documents, runbooks, product documentation, free-text knowledge, semantic search queries.
Weakness: no provenance, no governance, no relationships between context pieces. The vector store knows that document A is similar to document B — it doesn’t know who owns A, whether B is certified, or that A is upstream of B in the data flow.
Knowledge graphs — for relationship-based context
Permalink to “Knowledge graphs — for relationship-based context”Knowledge graphs store explicit entity relationships and enable multi-hop reasoning. If an agent asks “which tables are upstream of the revenue_summary view and who owns them,” a knowledge graph can traverse that relationship map directly.
Common knowledge graphs: Neo4j, Amazon Neptune, TigerGraph.
Best for: entity relationships, ontologies, multi-hop reasoning queries, understanding what connects to what.
Weakness: expensive to build, requires explicit data modeling, doesn’t handle unstructured content. Knowledge graphs encode what you’ve explicitly mapped — they don’t surface connections that weren’t modeled.
Data catalogs — for governed metadata context
Permalink to “Data catalogs — for governed metadata context”Data catalogs store structured metadata about data assets: ownership, lineage, business definitions, certification status, quality scores, and access controls. Unlike vector stores and knowledge graphs, governance is built into the data catalog — every asset has an owner, a certification state, and a freshness timestamp.
Common data catalogs: Atlan, DataHub, OpenMetadata.
The critical differentiator: a data catalog is the only context store where governance is native, not bolted on. An agent querying Atlan via MCP doesn’t just retrieve metadata — it retrieves certified, governed, access-controlled metadata. It knows whether the asset is trusted, who to contact if something looks wrong, and whether the lineage trace is complete.
For AI agents working with enterprise data, this is the distinction that matters most. The context graph vs. knowledge graph pattern Atlan uses — treating the metadata graph as a context graph — makes the catalog queryable not just for search but for governance-aware retrieval.
Document stores — for enterprise knowledge
Permalink to “Document stores — for enterprise knowledge”Document stores hold enterprise knowledge: meeting notes, runbooks, project documentation, policy documents. They’re the connective tissue of organizational context that doesn’t live in structured data systems.
Common document stores: Confluence, Notion, SharePoint, Google Drive.
Best for: process documentation, internal policies, project context, historical decision records.
Weakness: unstructured, low governance, high staleness risk. A policy document updated two years ago and never re-certified is indistinguishable from a current policy to an agent without governance signals.
The combination pattern
Permalink to “The combination pattern”Production data agent systems typically use all four: a vector store for semantic document search, a knowledge graph or lineage graph for relationship traversal, a data catalog for governed metadata, and a document store for policy and process context. The orchestration layer routes each query type to the right store — metadata queries to the catalog, semantic search to the vector store, relationship traversal to the graph.
The teams implementing enterprise context layer infrastructure early are discovering that none of these stores is self-sufficient. The stores work together, and the orchestration layer that routes between them is part of the architecture, not an afterthought.
Layer 5 — Governance (the trust layer)
Permalink to “Layer 5 — Governance (the trust layer)”Governance is the layer that determines whether the other four layers work reliably in enterprise. Without it, agents can retrieve efficiently, structure well, and stay current — but still deliver unreliable outputs from uncertified, unauthorized, or stale sources.
The governance layer answers five questions that no other layer in the ecosystem answers:
Is this context trustworthy? Certification infrastructure marks which assets are production-grade and which are exploratory, deprecated, or under review. An agent should know the difference before including a metric in an answer.
Who can see it? RBAC inherited from existing data governance policies determines which agents and which users can access which context. A financial agent should not be able to surface HR compensation data even if both are in the same catalog.
Where did it come from? Lineage tracking records the provenance of every context piece — which source systems it originated from, which transformations produced it, which teams maintain it. An agent citing a revenue metric should be able to answer “which pipeline produced this number.”
Is it still current? Staleness management detects when context has drifted from its source and flags it for refresh. A certified metric that was accurate three months ago may be misleading today if the underlying pipeline changed.
What did the agent do with it? Audit trails record which context was retrieved for which agent decision. This is the compliance and debugging infrastructure that enterprise organizations need before deploying agents into regulated workflows.
Why teams always skip this layer
Permalink to “Why teams always skip this layer”The governance layer is consistently the last thing built and the first thing blamed when production deployments fail. Three structural reasons explain this pattern:
First, governance requires existing data infrastructure. You cannot certify assets you haven’t cataloged. You cannot enforce RBAC on a metadata store that doesn’t have access policies. Teams that haven’t invested in data governance before starting AI projects have no governance layer to connect to.
Second, governance doesn’t appear in demos. In a 30-minute demo window, an agent pulling from ungoverned context looks identical to one pulling from certified sources. The failure mode only appears in production when the uncertified source returns incorrect data and no one can trace which query triggered it.
Third, governance feels like overhead before the AI system exists. Teams reason: “We’ll add governance once we know what we’re building.” What they discover instead is that without governance as a foundation, the agent system can’t scale past the demo stage.
The teams that invest in the governance layer before the agent layer are the ones who ship reliable production systems. The others rebuild.
Emerging patterns in the AI context ecosystem
Permalink to “Emerging patterns in the AI context ecosystem”Three patterns are taking shape as the ecosystem matures beyond the basic RAG + orchestration configuration most teams started with.
Context products
Permalink to “Context products”A context product is a reusable, governed bundle of context for a specific domain or use case. Instead of every agent querying raw context stores directly, a context product packages all the relevant metadata, lineage, glossary terms, and quality scores for a domain into a maintained artifact.
An HR Analytics context product, for example, would contain all HR-relevant table and column metadata, certified business definitions for HR metrics, lineage tracing HR tables to their sources, data quality scores, and RBAC policies limiting access to authorized consumers.
Once built, that context product is consumed by multiple agents without each one needing to query and assemble its own context. One team maintains it, many agents consume it. Context quality scales with product ownership rather than with the number of agents deployed.
This is the data product model applied to context. It’s how the teams that have scaled AI deployments beyond a handful of experiments handle the context maintenance problem without rebuilding for each new agent.
Bounded context spaces
Permalink to “Bounded context spaces”A bounded context space is a domain-isolated context environment. An agent operating within the Finance bounded context sees only Finance-relevant context — not HR, not Marketing, not Engineering.
The benefit isn’t just about data access policies. Cross-domain terminology conflicts are a significant source of AI agent failures. “Revenue” means different things in Finance and in Sales. “Pipeline” means something different in Data Engineering than it does in Sales. An agent without domain isolation will retrieve metadata from the wrong domain and return confident, wrong answers.
Bounded context spaces enforce domain isolation at the context layer. This makes domain-specific RBAC enforceable and terminology conflicts impossible. The bounded context spaces pattern is a direct application of domain-driven design principles to AI agent context architecture.
Context graphs
Permalink to “Context graphs”Context graphs are structured relationship maps between context pieces — not just a vector store of similar documents, but a graph that connects metadata to lineage to glossary terms to ownership to quality scores.
When an agent asks “who should I talk to about the revenue_by_region table,” a context graph can traverse: table metadata (owner: Analytics team) → lineage (sourced from: Salesforce CRM pipeline) → business glossary (defined by: Revenue Ops) → certification (certified by: Finance Analytics team, last reviewed 14 days ago). That is not a retrieval task — it is a reasoning task over a relationship graph.
Atlan’s metadata graph is the infrastructure layer that makes context graph queries possible for enterprise data assets. The connections between assets, owners, lineage nodes, and business definitions are stored as a graph that agents can traverse via MCP — not just as a flat list of metadata fields.
How Atlan fits in the AI context ecosystem
Permalink to “How Atlan fits in the AI context ecosystem”Atlan occupies the governed data layer position in the ecosystem: the layer that governs what context exists, who can access it, and whether it is trustworthy. It sits at the intersection of context stores (Layer 4) and governance (Layer 5) — and its MCP server connects those layers to the rest of the ecosystem.
Governance layer: Certified assets, business glossary, lineage graph, RBAC, active metadata policies, staleness tracking. The infrastructure that makes context reliable enough for production agent use.
Context store: The metadata lakehouse — all data assets, with owners, lineage, quality scores, and business definitions in a single governed store. Queryable by both humans and agents.
Delivery protocol: The Atlan MCP server exposes the governed catalog as agent-callable tools: search assets, get lineage, query the business glossary, check certification status, retrieve active metadata. Any MCP-compatible agent framework can call these tools without custom integration.
Context products: Context Studio is Atlan’s tooling for building and managing domain-specific context bundles — packaging governed metadata into reusable context products that teams maintain and agents consume.
Ecosystem integration: Atlan works alongside any orchestration framework. A LangChain agent, a CrewAI crew, or an Anthropic Agents SDK pipeline can all call the Atlan MCP server to retrieve governed context as part of their reasoning loop.
The how to implement enterprise context layer guide walks through how these components connect in practice — from source identification through governance to agent-ready delivery.
Real stories from real customers: Context ecosystem in enterprise AI
Permalink to “Real stories from real customers: Context ecosystem in enterprise AI”"Atlan is much more than a catalog of catalogs. It's more of a context operating system…Atlan enabled us to easily activate metadata for everything from discovery in the marketplace to AI governance to data quality to an MCP server delivering context to AI models."
— Sridher Arumugham, Chief Data & Analytics Officer, DigiKey
DigiKey’s framing captures something important about how the AI context ecosystem works in practice. They didn’t build five separate layers and connect them — they built one context operating system that spans the catalog, governance, quality, and delivery functions. The MCP server at the end of that stack isn’t a separate integration; it’s the interface layer that exposes everything already built.
That is the architectural pattern that scales: the governance layer and the context store are unified, and the delivery protocol exposes that unified, governed store to any agent that needs it.
"We're excited to build the future of AI governance with Atlan. All of the work that we did to get to a shared language at Workday can be leveraged by AI via Atlan's MCP server…as part of Atlan's AI Labs, we're co-building the semantic layer that AI needs with new constructs, like context products."
— Joe DosSantos, VP of Enterprise Data & Analytics, Workday
Workday’s experience illustrates the context products pattern in action. The “shared language” they built for human data teams — business definitions, certified metrics, agreed-upon lineage — is now the input to the AI context layer. That context layer, exposed via the MCP server, lets AI agents consume what was previously only accessible to humans through manual catalog navigation.
The ecosystem is only as strong as its governance layer
Permalink to “The ecosystem is only as strong as its governance layer”The AI context ecosystem is a layered system. Remove any layer and the layers above it degrade. But the governance layer is the one that determines whether the system is trustworthy enough to use in production, not just in a demo.
Without certification, agents retrieve metrics that haven’t been validated. Without RBAC, agents surface data to users who shouldn’t see it. Without lineage, agents can’t explain where an answer came from. Without staleness management, agents confidently return numbers from pipelines that broke weeks ago. Without audit trails, no one can investigate what the agent did when something goes wrong.
The teams that invest in Layer 5 — governance — before deploying Layer 1 through 4 into production are the ones who ship systems that survive contact with real data, real access policies, and real regulatory requirements.
The others discover the problem six months later and rebuild from the governance layer up. The ecosystem is available. The governance infrastructure is the competitive advantage.
FAQs
Permalink to “FAQs”1. What is the AI context ecosystem?
The AI context ecosystem is the full set of platforms, protocols, and infrastructure that determines what information AI agents can access, how they access it, and whether that information is trustworthy. It spans five layers: foundation models, orchestration, delivery protocols like MCP, context stores (vector DBs, knowledge graphs, data catalogs), and governance.
2. What is MCP in the AI context ecosystem?
MCP (Model Context Protocol) is Anthropic’s open standard for connecting data sources to AI models as callable tools. It sits in the delivery protocol layer — enabling agents to query context sources like data catalogs, vector stores, and document systems via a standardized interface, without custom integration per source.
3. How do vector databases, knowledge graphs, and data catalogs differ?
Vector databases store embeddings for semantic similarity search — best for unstructured text and documents. Knowledge graphs map explicit entity relationships for multi-hop reasoning. Data catalogs store governed metadata — asset ownership, lineage, certification, and business definitions. Production AI systems use all three because each handles a different context type.
4. What is a context product?
A context product is a reusable, governed bundle of context for a specific domain. An HR Analytics context product would package all HR-relevant metadata, lineage, glossary terms, and quality scores into a maintained artifact. Multiple agents consume it. One team maintains it. It applies data product thinking to context delivery.
5. What is a bounded context space for AI?
A bounded context space is a domain-isolated context environment that limits which context an agent can access. A Finance agent sees only Finance-relevant context — not HR, not Marketing. This prevents cross-domain terminology conflicts and enforces domain-specific access control at the context layer.
6. What is the governance layer in AI context infrastructure?
The governance layer determines whether context is trustworthy. It includes certification (which assets are production-grade), RBAC (who can access which context), lineage tracking (provenance of context pieces), staleness management (refreshing outdated context), and audit trails (what context was used in which decision).
7. How does a data catalog fit into the AI context ecosystem?
A data catalog occupies two positions: the context store layer (governed metadata, lineage, business glossary) and the governance layer (certification, RBAC, freshness tracking). With an MCP interface, it becomes directly queryable by AI agents — making it the only context store with governance built in.
8. What is the Model Context Protocol (MCP)?
The Model Context Protocol is an open standard from Anthropic that defines how data sources and tools expose themselves to AI models. An MCP server registers tools — search, query, retrieve, filter — via a standardized interface. Agents can call any MCP server without per-source custom integration, making the ecosystem composable.
Sources
Permalink to “Sources”- Model Context Protocol specification, Anthropic
- LangChain ecosystem documentation, LangChain
- Atlan AI context stack guide, Atlan
- Context as a Service: The CIO’s guide to context graphs, Atlan
- Andrej Karpathy on context engineering, X (formerly Twitter)
- Pinecone: What is a vector database, Pinecone
- Neo4j: Knowledge graphs for AI applications, Neo4j
