


















Why does multi-agent orchestration matter?
Permalink to “Why does multi-agent orchestration matter?”Multi-agent system orchestration is the discipline of coordinating two or more AI agents to complete complex tasks that no single agent can accomplish reliably on its own.
Complex enterprise workflows require more than one agent to deliver reliable outcomes. A financial reporting workflow might involve one agent querying transaction data, a second applying regulatory classification, a third checking policy compliance, and a fourth producing a formatted output. Each step depends on prior outputs, and each step requires different tooling and domain context.
Multi-agent orchestration is the engineering pattern that makes agentic AI extensible at enterprise scale. Understanding multi-agent coordination patterns is key to choosing the right architecture. Without it, agents operate as isolated tools. Close to three-quarters of companies plan to deploy agentic AI within two years, yet only 21% report having a mature model for agent governance. That gap is an orchestration architecture problem, and it compounds as agent networks grow.
Key components of multi-agent orchestration include task decomposition, agent routing, state management, result aggregation, and error handling and escalation.
What are the three most common orchestration patterns for multi-agent systems?
Permalink to “What are the three most common orchestration patterns for multi-agent systems?”Orchestration is a family of coordination approaches, each suited to different task structures. The three foundational structural patterns are supervisor/worker, peer-to-peer, and hierarchical orchestration. The A2A protocol defines how agents communicate across all three. Each carries different tradeoffs in speed, accuracy, and coordination overhead.
1. Supervisor/worker orchestration
Permalink to “1. Supervisor/worker orchestration”A central supervisor agent receives the goal, breaks it into subtasks, routes each subtask to a specialist worker agent, and synthesizes the results. Worker agents don’t communicate with each other directly.
Use this pattern when you have clear routing logic, a need for easier debugging (all coordination passes through a single node), or sequential task chains where the output of one worker feeds the supervisor’s next routing decision. Note that Map-Reduce is a common execution variant within this pattern.
The primary risk is supervisor bottleneck: if the supervisor agent fails, the entire workflow stalls.
2. Peer-to-peer orchestration
Permalink to “2. Peer-to-peer orchestration”In peer-to-peer orchestration, agents communicate and collaborate directly with each other without a central supervisor routing between them. Any agent can initiate a task, delegate to another agent, or request input from a peer.
This pattern is well-suited for collaborative tasks, flexible task assignment, and distributed resilience (no single coordinator creates a single point of failure).
The tradeoff is traceability: because interactions are distributed across agent pairs rather than logged through a central hub, reconstructing the full reasoning chain after the fact is significantly harder. Without a shared context layer capturing every agent interaction, peer-to-peer systems are difficult to audit — AI observability infrastructure is essential for tracking cross-agent reasoning.
3. Hierarchical orchestration
Permalink to “3. Hierarchical orchestration”Hierarchical orchestration extends the supervisor/worker pattern across multiple levels. A top-level supervisor delegates to mid-level supervisor agents, each of which manages its own pool of specialist workers. This creates a tree structure where authority and context flow downward and results flow upward.
This pattern is well-suited for complex, multi-domain problems, large agent networks, and organizational alignment (the hierarchy can mirror the enterprise’s domain structure).
The critical risk is context inconsistency propagating through levels. If a mid-level supervisor operates from a different definition of a key concept than its peer supervisors, that inconsistency cascades into every worker agent beneath it.
Orchestration frameworks including LangGraph, CrewAI, and Microsoft’s AutoGen support all three patterns with varying levels of state management and tool integration.
How does multi-agent orchestration work?
Permalink to “How does multi-agent orchestration work?”Orchestration operates across three simultaneous layers: the communication protocol that lets agents exchange tasks and results, the state management system that tracks what each agent has established, and the governance layer that controls what agents are permitted to do.
1. Agent-to-agent communication with A2A
Permalink to “1. Agent-to-agent communication with A2A”The Agent2Agent (A2A) protocol is an open communication protocol for AI agents, initially introduced by Google in April 2025, and designed for agent interoperability across vendors and frameworks. At its core, A2A enables communication between a “client” agent and a “remote” agent.
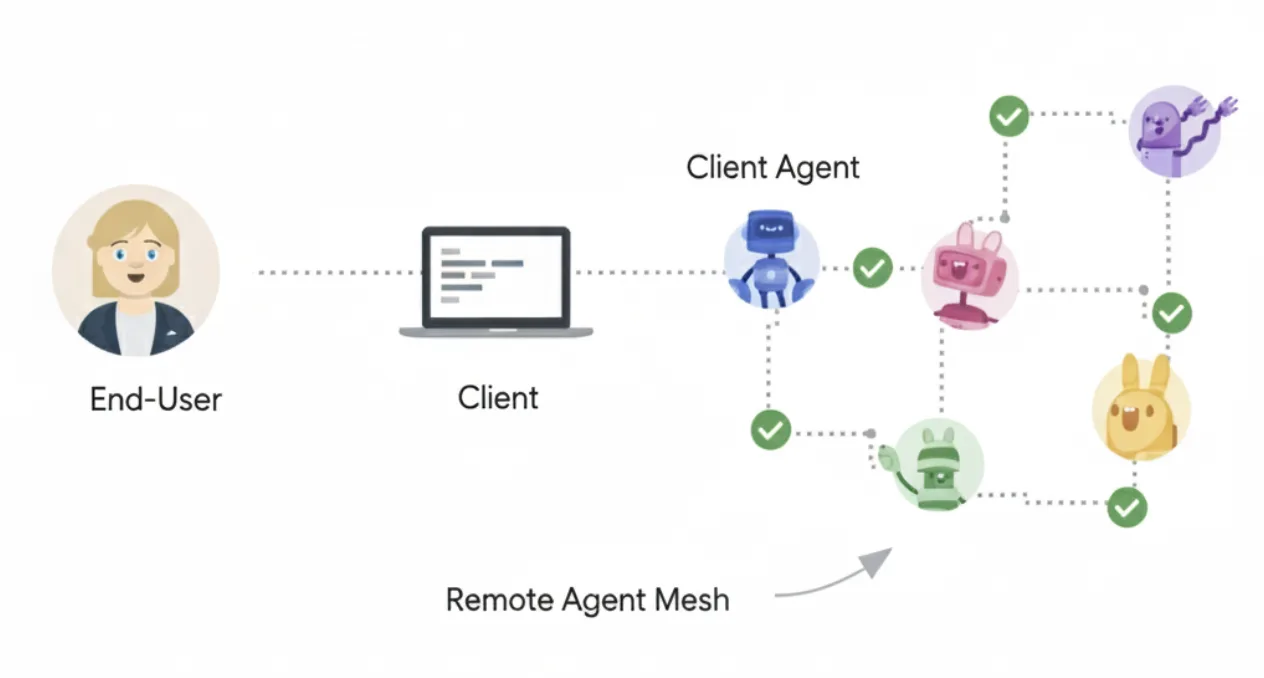
How A2A works. Source: A2A Protocol
A2A addresses the interoperability problem that every proprietary orchestration framework leaves open: how do agents built by different teams, running on different platforms, delegate work to each other without bespoke integration code for every pairing? The protocol is built on five fundamental communication elements: Agent Card (discovery), Task (unit of work), Message (single-turn communication), Part (unit of content), and Artifact (tangible deliverable).
2. How does A2A work with MCP?
Permalink to “2. How does A2A work with MCP?”MCP provides agent-to-tool communication and A2A provides agent-to-agent communication — the two protocols are complementary standards for building robust agentic applications. MCP handles what an agent can access. A2A handles how agents coordinate with each other.
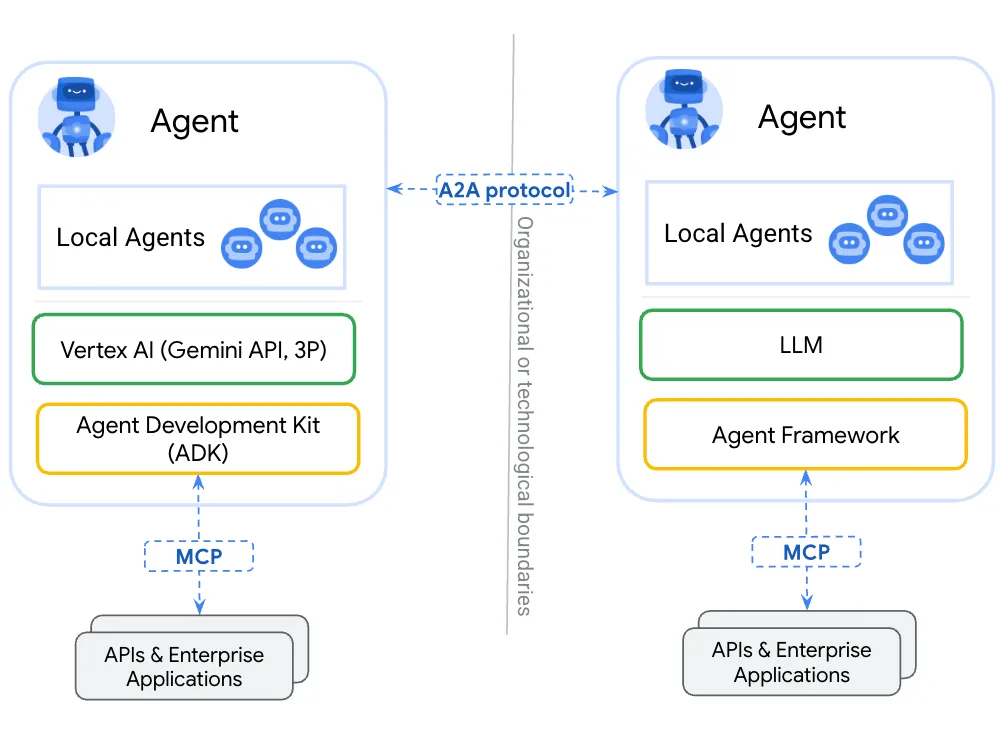
A2A and MCP are complementary standards. Source: A2A Protocol
Where does multi-agent orchestration break down at scale?
Permalink to “Where does multi-agent orchestration break down at scale?”Orchestration patterns work reliably in demos and small deployments. At scale, they break on a single structural problem: context inconsistency across agent memory stores.
Consider a supervisor agent routing a financial query to a Finance specialist and a Compliance specialist in parallel. The supervisor expects two aligned answers it can synthesize. What it receives are two answers derived from different definitions of “revenue,” held in two isolated memory stores. The supervisor has no mechanism to resolve the conflict on principled grounds.
The five multi-agent memory silo failures
Permalink to “The five multi-agent memory silo failures”Without proper AI governance, organizations end up with five multi-agent memory silo failures:
- Fragmentation: Definitions, business rules, and domain knowledge that should be shared across agents are held separately by each agent.
- Definition conflicts: Two specialist agents operating on different versions of the same business concept produce contradictory results.
- Scale explosion: Each new agent requires its own context provisioning, growing operational overhead as the number of agents grows.
- Ownership ambiguity: When a definition needs updating, no clear owner is responsible for propagating that update across all agent memory stores.
- Succession gaps: When a subject-matter expert leaves, their domain knowledge evaporates from the agent system — with no shared context layer to catch the drift.
Why the fix is architectural, not orchestration-level
Permalink to “Why the fix is architectural, not orchestration-level”Adding a smarter supervisor agent does not fix definition conflicts between specialists. Adding retry logic does not fix fragmentation. These are symptoms of the wrong architecture.
The fix is a shared, governed context layer for all agents: the same business glossary, the same lineage graph, the same governance policies — available to every agent in the system, maintained by human domain experts and enriched continuously by AI stewards. This is an infrastructure decision to be made before agents are deployed.
How does a shared context layer fix orchestration at scale?
Permalink to “How does a shared context layer fix orchestration at scale?”When all agents read from the same governed business context layer:
- Definition conflicts are resolved at the source: A Finance agent and a Compliance agent both operate from the same certified definition of “revenue.”
- State persists across the pipeline: When agent 3 in a five-agent workflow needs what agent 1 established, it queries the shared context layer rather than agent 1’s transient session.
- Updates propagate automatically: When a business definition changes, the update is made once in the context layer and all agents retrieve the current version on their next query.
- Governance is enforceable at scale: Because all agents read from the same context layer, governance policies applied at that layer apply to all agents simultaneously.
- Audit trails are complete: Every agent query to the context layer is logged with a timestamp, the requesting agent’s identity, and the version of the definition returned.
Atlan’s Context Engineering Studio provides the engineering environment for building, testing, and maintaining this shared context layer. The Context Lakehouse is the knowledge architecture underneath it. Atlan’s MCP server is how that context reaches every agent in the orchestration stack — any MCP-compatible agent, whether a general-purpose model like Claude or a platform agent like Snowflake Cortex, can query Atlan via MCP to retrieve definitions, traverse lineage, and check governance policies at inference time.
Real stories from real customers building enterprise context layers to scale agentic AI
Permalink to “Real stories from real customers building enterprise context layers to scale agentic AI”"Atlan captures Workday's shared language to be leveraged by AI via its MCP server. As part of Atlan's AI labs, we're co-building the semantic layer that AI needs."
Joe DosSantos, VP Enterprise Data & Analytics
Workday
Workday: Context as Culture
Watch Now"Atlan is our context operating system to cover every type of context in every system including our operational systems. For the first time we have a single source of truth for context."
Sridher Arumugham, Chief Data Analytics Officer
DigiKey
DigiKey: Context Operating System
Watch NowMoving forward with multi-agent system orchestration
Permalink to “Moving forward with multi-agent system orchestration”Enterprises scaling agentic AI will encounter the boundary where orchestration patterns stop working. That boundary is defined by the moment when two agents operating from different definitions produce a conflict no supervisor can resolve on principled grounds.
The path forward is to treat the context layer as infrastructure. Build the shared business glossary before deploying specialist agents that depend on it. Instrument the context layer with lineage and ownership data before agents begin writing back to it. Establish governance policies at the context level so that every agent reading from that layer inherits them automatically.
Atlan’s Context Engineering Studio is built for this transition: from isolated agent deployments to governed multi-agent systems where shared context is the prerequisite, not the afterthought.
FAQs about multi-agent system orchestration
Permalink to “FAQs about multi-agent system orchestration”1. What is the difference between multi-agent orchestration and prompt chaining?
Permalink to “1. What is the difference between multi-agent orchestration and prompt chaining?”Prompt chaining routes the output of one model call into the input of the next in a fixed linear sequence. Multi-agent orchestration coordinates agents that may work in parallel, maintain persistent state across sessions, call different tools, and communicate with each other through structured protocols like A2A. Prompt chaining is a pattern that can appear within orchestration. Orchestration is the broader engineering discipline that encompasses chaining, routing, state management, and governance.
2. What is the Agent2Agent (A2A) protocol?
Permalink to “2. What is the Agent2Agent (A2A) protocol?”A2A is an open communication protocol designed for multi-agent systems, allowing interoperability between AI agents from different providers or built using different frameworks. Originally developed by Google and launched in April 2025, it is now maintained by the Linux Foundation as an open-source project focused on security, extensibility, and real-world usability across industries.
3. What is the difference between A2A and MCP?
Permalink to “3. What is the difference between A2A and MCP?”The Model Context Protocol (MCP) standardizes how a single agent accesses tools, data sources, and APIs. A2A standardizes how agents communicate with each other as peers and delegate tasks across organizational or vendor boundaries. In a multi-agent system, an agent might use MCP to query a data catalog and A2A to send its findings to a peer agent for further reasoning. MCP handles agent-to-tool connections; A2A handles agent-to-agent collaboration.
4. What causes definition conflicts in multi-agent systems?
Permalink to “4. What causes definition conflicts in multi-agent systems?”Definition conflicts arise when two or more agents hold different versions of the same business concept in their isolated memory stores. A Finance agent might define “revenue” as recognized revenue under GAAP, while a Sales agent uses booked revenue. The conflict is not a logic error in either agent, but an architecture failure: no shared organizational context ensures that both agents operate from the same certified definition.
5. How do agents maintain shared state across a multi-step workflow?
Permalink to “5. How do agents maintain shared state across a multi-step workflow?”Shared state in a multi-agent pipeline is maintained by a persistent, governed context layer that all agents can read from and write to. When an agent establishes a fact, it writes that fact to the shared layer. When a downstream agent needs that fact, it queries the context layer rather than the upstream agent’s transient session memory — keeping state durable across workflow steps and making the full reasoning chain queryable for audit purposes.
6. What orchestration frameworks are most commonly used in enterprise deployments?
Permalink to “6. What orchestration frameworks are most commonly used in enterprise deployments?”The most widely adopted open-source frameworks include LangGraph (stateful, graph-based agent workflows), CrewAI (role-based multi-agent collaboration), and Microsoft’s AutoGen (conversational multi-agent orchestration with strong human-in-the-loop support). Commercial platforms including Google’s Vertex AI Agent Builder and AWS Bedrock Agents provide managed orchestration infrastructure with native cloud integrations.
7. What is the first step toward reliable multi-agent orchestration at scale?
Permalink to “7. What is the first step toward reliable multi-agent orchestration at scale?”The first step is establishing the shared context layer before deploying multiple specialist agents that depend on it. This means building a governed business glossary with certified definitions, connecting lineage data that maps where each definition originates, assigning ownership to each definition so that updates have a responsible party, and instrumenting the layer so that all agent interactions are logged.
