


















Atlan’s Context Engineering Studio addresses hallucination at the source by delivering a governed Enterprise Data Graph, with certified lineage, canonical metric definitions, and policy-as-graph constraints, so AI agents retrieve accurate, conflict-free context before generation begins rather than catching errors after the fact.
How to choose the right hallucination detection approach: An overview of hallucination types
Permalink to “How to choose the right hallucination detection approach: An overview of hallucination types”Getting the taxonomy right matters before choosing a detection approach, because different hallucination types require different detection methods.
Intrinsic vs. extrinsic hallucinations
Permalink to “Intrinsic vs. extrinsic hallucinations”Hallucinations can be fundamentally classified as:
- Intrinsic hallucinations: The model generates an output that directly contradicts the input data. If the context says Q3 revenue was $42M and the agent reports $48M, that is intrinsic.
- Extrinsic hallucinations: Fabricates content that can’t be verified from the provided context and requires external knowledge validation. If an earnings summary mentions a planned acquisition that appears nowhere in the source documents, that is extrinsic.
Factuality vs. faithfulness hallucinations
Permalink to “Factuality vs. faithfulness hallucinations”Another way to classify hallucinations is based on what the generated output is being measured against: the real world, or the provided input.
A model can be unfaithful to its context while still being factually accurate, or factually wrong while remaining internally consistent with a flawed source. The distinction determines which detection method applies.
The Association for Computing Machinery (ACM) classifies hallucinations as factuality hallucination and faithfulness hallucination:
- Factuality hallucination: Refers to the discrepancy between generated content and verifiable real-world facts, typically manifesting as factual inconsistencies.
- Faithfulness hallucination: Captures the divergence of generated content from user input or the lack of self-consistency within the generated content.
ACM further subdivides faithfulness hallucination into:
- Instruction inconsistency: The content deviates from the user’s original instruction.
- Context inconsistency: Highlights discrepancies from the provided context.
- Logical inconsistency: Points out internal contradictions within the content.
In practice:
- Faithfulness errors are the primary target of RAG-based detection, because they involve inconsistency between the generated answer and the retrieved documents.
- Factual errors require external grounding, in the form of knowledge bases, verified datasets, or human review.
Summing up
Permalink to “Summing up”Intrinsic and extrinsic hallucinations describe where the error originates: is it a contradiction of the source, or fabrication beyond it. Factuality and faithfulness hallucinations describe what the error is measured against: verifiable real-world facts, or the given input.
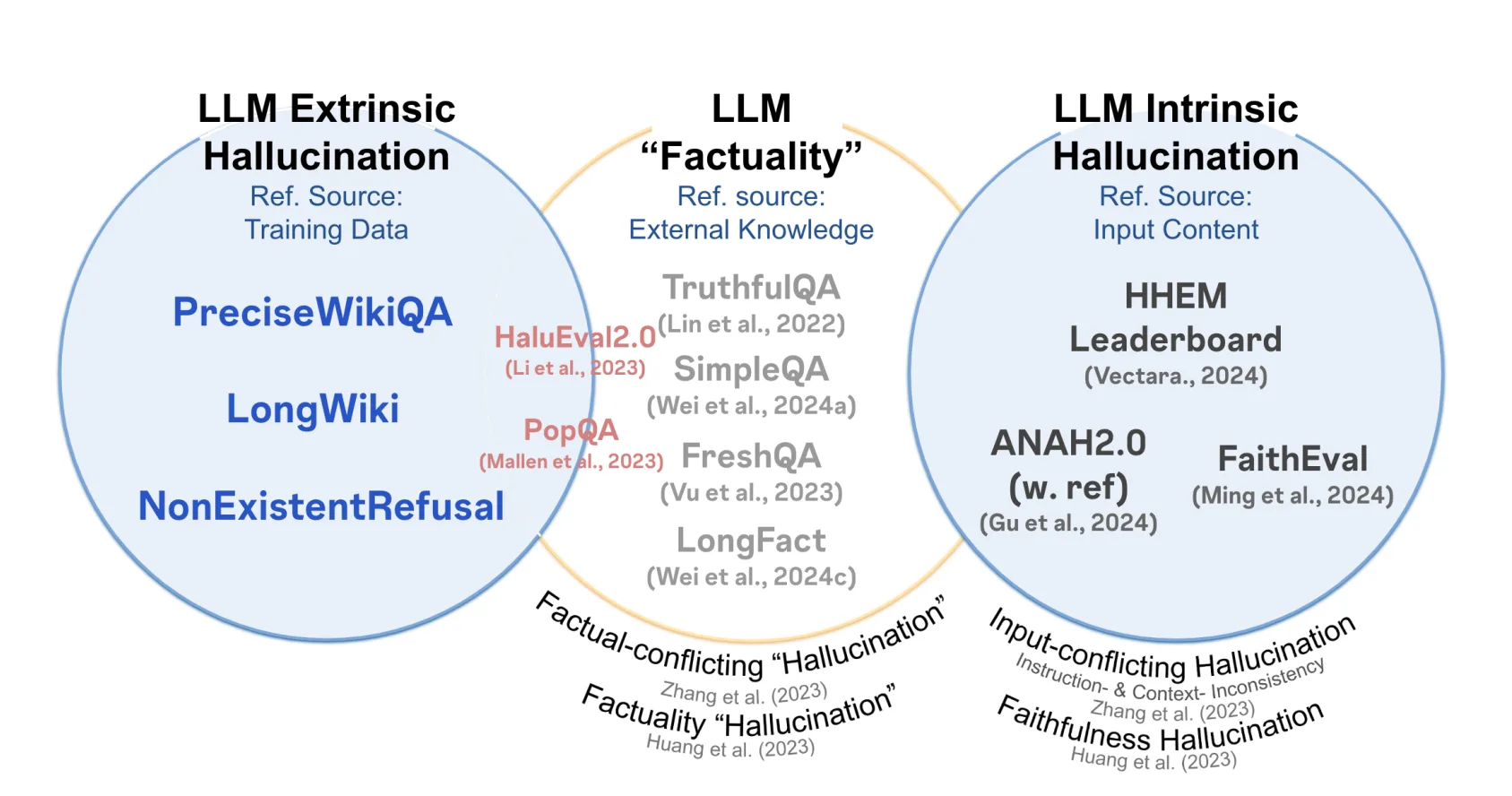
The relationship between intrinsic and extrinsic hallucination, and LLM factuality, with detection benchmarks. Source: Arxiv
Benchmarks like TruthfulQA, SimpleQA, and FreshQA test against external knowledge, making them relevant to both extrinsic and intrinsic failure modes. Faithfulness-specific benchmarks like HHEM Leaderboard, ANAH2.0, and FaithEval sit firmly in the intrinsic quadrant, evaluating consistency against the provided input rather than against the world.
What are the six primary hallucination detection methods?
Permalink to “What are the six primary hallucination detection methods?”Detection operates at three levels:
- Output-level methods: Compare the answer to external sources or retrieved context.
- Generation-level methods: Analyze uncertainty during inference.
- Model-internal methods: Examine attention and probability signals.
The following six primary methods span all three levels.
1. Self-consistency checking
Permalink to “1. Self-consistency checking”Self-consistency checking runs the same query multiple times with slight variation in phrasing or sampling temperature, then compares responses for semantic consistency. The key idea is that if a response is factual, repeated queries should give consistent responses, whereas hallucinated content would give responses with high variability.
This is an unsupervised technique that checks the reasoning abilities of LLMs. It can be question-based or answer-based. Question-based methods evaluate the consistency of answers to paraphrased versions of the same question. Answer-based methods generate multiple responses to the same query.
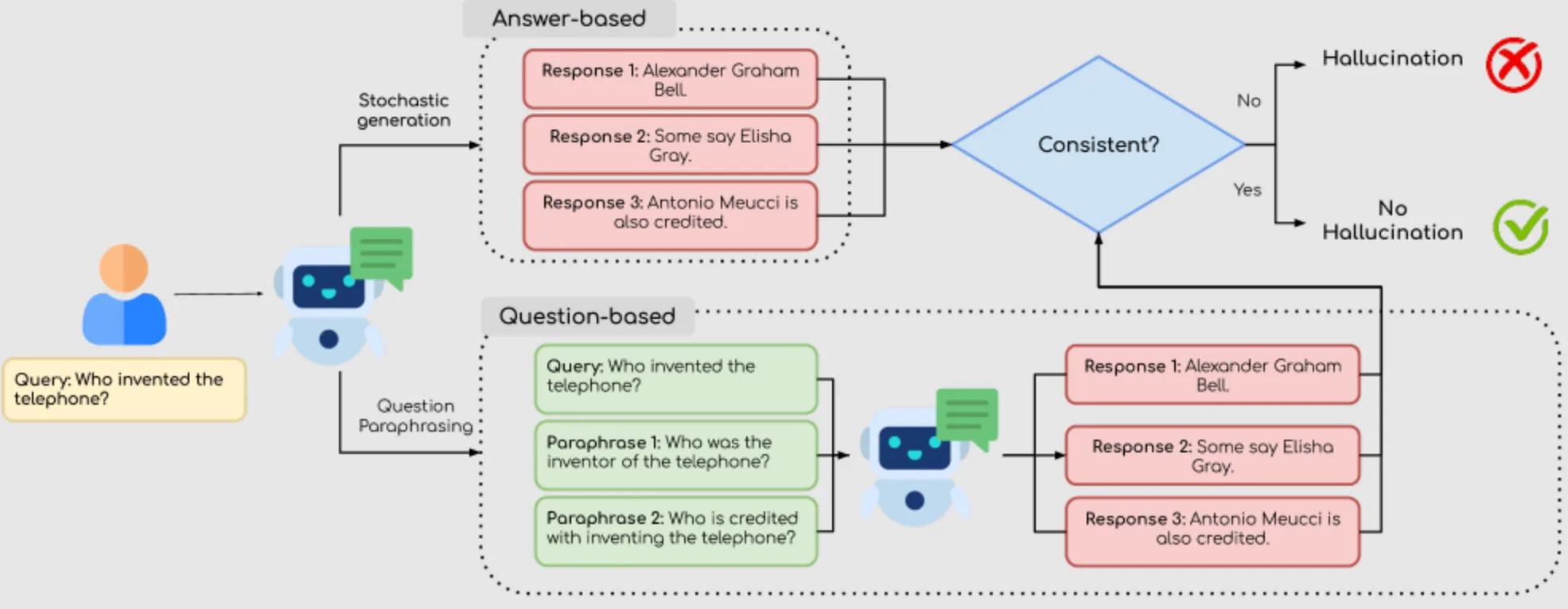
Self-consistency method and its types for hallucination detection. Source: Arxiv
Self-consistency is most effective for open-ended factual queries with a stable correct answer. To implement it: submit the same query multiple times with varied phrasing or temperature, cluster responses by semantic meaning rather than exact wording, and flag queries where responses fall into multiple distinct semantic clusters.
2. NLI-based grounding
Permalink to “2. NLI-based grounding”Natural language inference (NLI) checks whether the model’s answer logically follows from the context it retrieved.
NLI-based grounding is the strongest available method for faithfulness errors — cases where the model’s output conflicts with the retrieved context. It’s less effective for extrinsic hallucinations, where the fabricated claim does not contradict any retrieved passage.
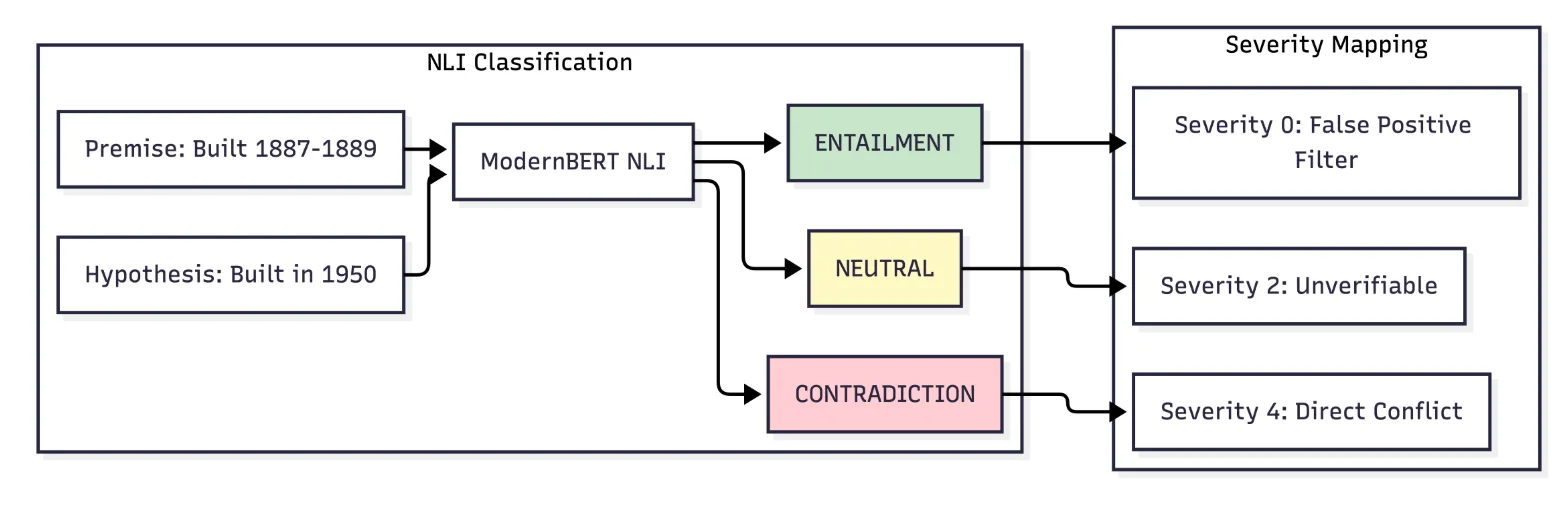
An example of NLI-based grounding workflow for hallucination detection. Source: Arxiv
To implement: retrieve the source documents the model used during generation, pass each claim in the model’s output to an NLI classifier alongside the relevant source passage, and label each claim as entailed, contradicted, or neutral relative to the source.
3. Grounding verification
Permalink to “3. Grounding verification”Grounding verification checks whether every claim in the model’s output can be traced to a specific passage in the documents retrieved during generation. Where NLI tests logic, grounding verification tests sourcing: is there a passage that could have produced this claim? If not, the claim is flagged as ungrounded.
A related concept is retrieval verification, which checks whether the retrieval step itself surfaced the right documents. Grounding verification assumes the retrieved context is correct and checks the output against it. Retrieval verification checks whether the retrieved context was sufficient to produce a grounded answer at all.
Grounding verification is the default choice for enterprise RAG pipelines where retrieved documents are the authoritative source of truth. To implement: pass the retrieved context and the model’s output to a verification layer, match each factual claim against specific source passages using semantic similarity or NLI, and surface claims with no supporting passage as likely hallucinations.
4. LLM-as-a-judge
Permalink to “4. LLM-as-a-judge”LLM-as-a-judge uses a second language model to evaluate the output of the primary model. The judge receives the original query, the retrieved context, and the generated answer, then identifies contradictions, fabrications, or unsupported claims.
LLM-as-a-judge can handle complex claims that are difficult to verify through string matching or entailment alone. It returns natural language explanations of why a specific output was flagged, and covers both faithfulness and factual errors depending on the reference material provided.
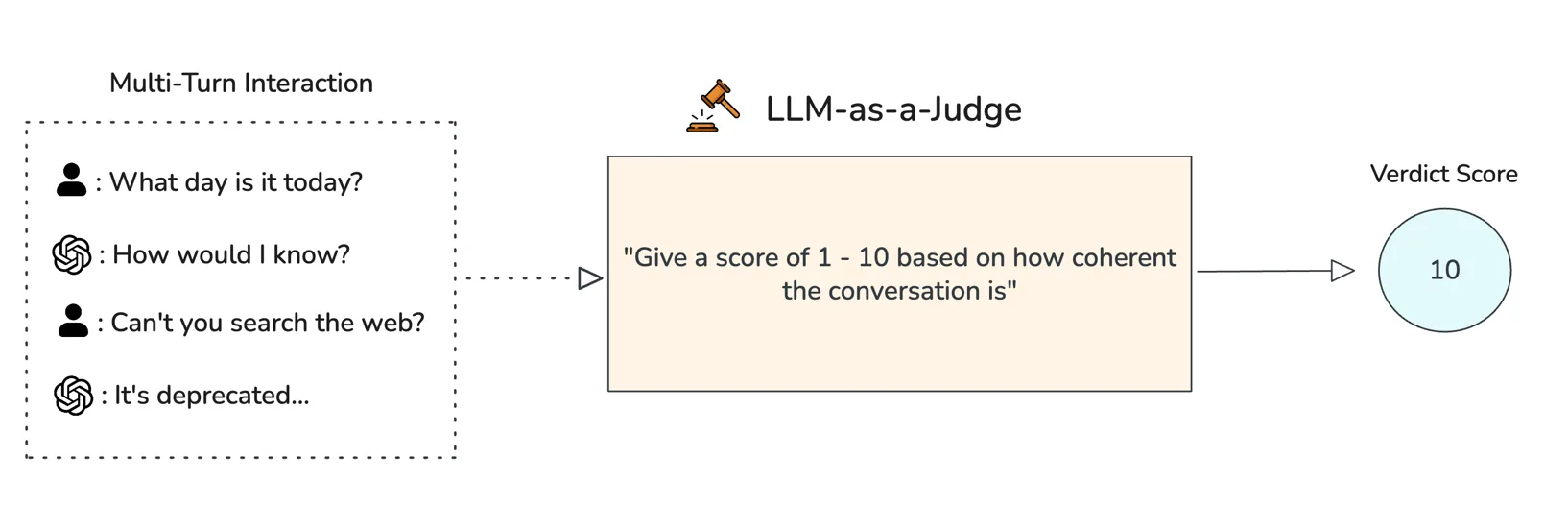
An example of LLM-as-a-judge in action. Source: Confident AI
Its primary limitation is cost and latency, since every query requires a second inference call. To implement: select a judge model that is stronger than or independently trained from the primary model, provide the judge with the original query, retrieved context, and generated answer as separate inputs, and instruct the judge to label each claim as supported, contradicted, or fabricated.
5. Confidence and uncertainty scoring
Permalink to “5. Confidence and uncertainty scoring”Confidence and uncertainty scoring estimates how certain a model is in each claim. Two distinct mechanisms are used:
- Token-level probability scoring (white-box): Accesses the model’s internal token-level probability distributions directly. Low-probability tokens within factual claims signal low model confidence and elevated hallucination risk. This requires model internals access and isn’t available through most commercial APIs.
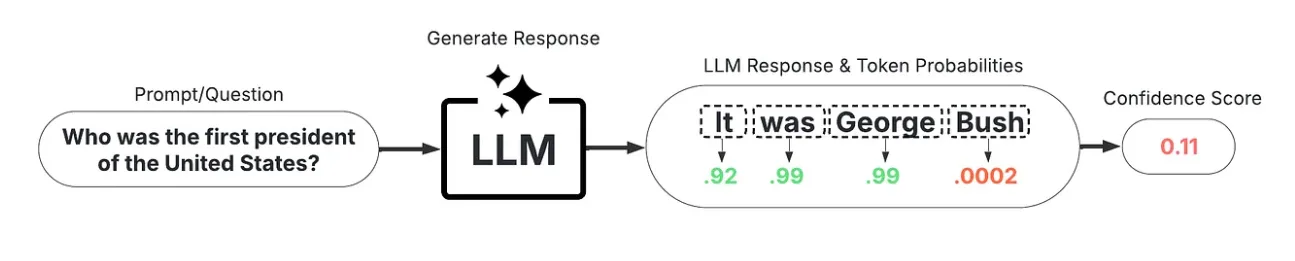
A sample white-box uncertainty scoring workflow. Source: Medium
- Semantic consistency scoring (black-box): Measures how consistently the model produces the same meaning across multiple sampled outputs without accessing internal probabilities. If the model produces semantically divergent answers across samples, confidence is low.
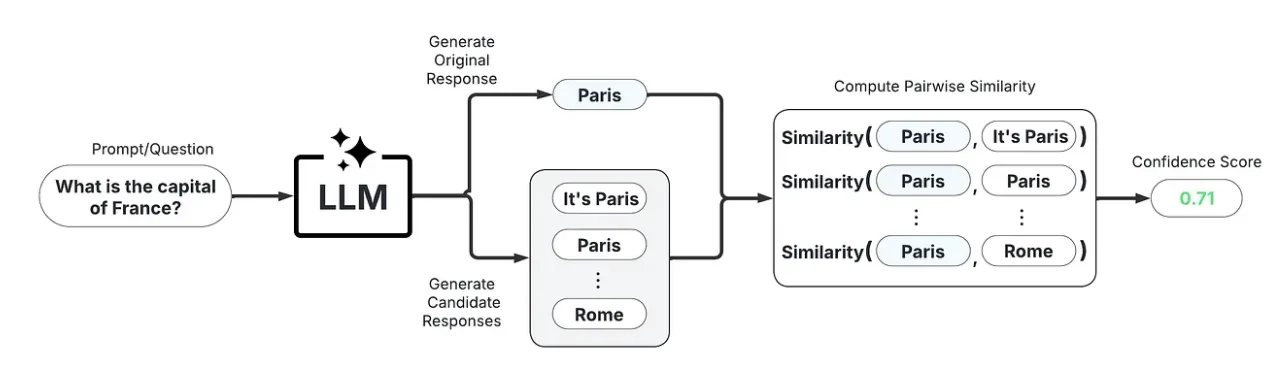
A sample black-box uncertainty scoring workflow. Source: Medium
In practice, confidence scoring works best as a triage layer: routing low-confidence outputs to more expensive evaluation methods such as LLM-as-a-judge or human review, rather than applying heavy evaluation to every query.
6. Attention map analysis
Permalink to “6. Attention map analysis”Attention map analysis looks at where the model is “paying attention” during generation, examining how attention is distributed across input tokens.
When a model generates a factual claim while attending primarily to its own prior outputs rather than to source passages, that claim carries a higher hallucination risk.
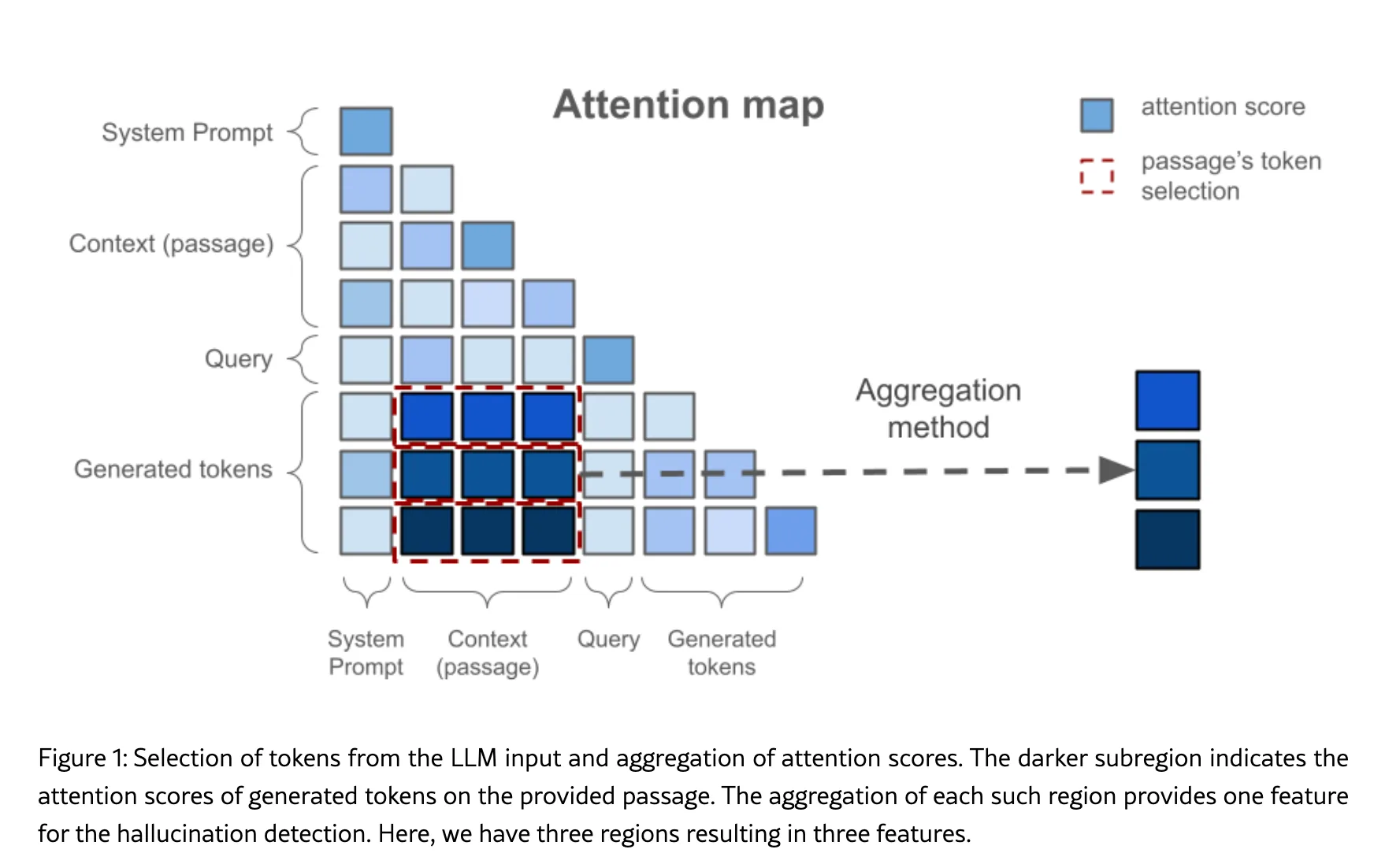
An aggregation of attention scores for an LLM input. Source: Arxiv
The intuition: if generated tokens are paying high attention to the source passage, the output is likely grounded. If attention to the passage is low relative to other regions, hallucination risk rises. Its primary limitation is access: attention map analysis requires white-box model access, which rules out commercial API deployments.
Which detection method should you use and when?
Permalink to “Which detection method should you use and when?”No single method is universally optimal. The right choice depends on four variables: whether you have access to model internals, how much latency you can tolerate, whether retrieved context is available, and how high the stakes of a wrong answer are.
- Self-consistency checking: Use for open-ended factual queries where the correct answer is stable. Effective when latency tolerance is moderate and the query set is diverse.
- NLI-based grounding: Use when you want to know not just whether a claim is wrong, but why — entailed, contradicted, or unverifiable. Best for faithfulness errors. Does not catch extrinsic hallucinations.
- Grounding verification: Use when retrieved documents are the authoritative source of truth and faithfulness to context is the primary concern. Best default for enterprise RAG pipelines.
- LLM-as-a-judge: Use for high-stakes, lower-volume queries where explainability matters and cost per query is acceptable. Well suited to sampling-based monitoring in production.
- Confidence and uncertainty scoring: Use as a triage layer. Route low-confidence outputs to heavier evaluation rather than applying expensive methods to every query.
- Attention map analysis: Use when running open-weight models on your own infrastructure and low-latency detection is the priority. Not applicable to commercial API deployments.
A summary of the primary hallucination detection methods
Permalink to “A summary of the primary hallucination detection methods”| Method | How it works | Access required | Latency impact | Best for |
|---|---|---|---|---|
| Self-consistency checking | Runs the same query multiple times and flags semantic variability across samples | API access (black-box) | High — multiple inference calls per query | Open-ended factual queries with stable correct answers |
| NLI-based grounding | Tests whether each claim logically follows from retrieved context using entailment classification | API access (black-box) | Medium — one NLI call per claim | Faithfulness errors where claim-level granularity is needed |
| Grounding verification | Traces every claim back to a specific source passage; untraced claims are flagged | API access (black-box) | Low to medium | Enterprise RAG pipelines where source traceability is required |
| LLM-as-a-judge | A second model evaluates the primary model’s output for contradictions and fabrications | API access (black-box) | High — requires a second inference call | High-stakes, lower-volume queries where explainability is required |
| Confidence and uncertainty scoring | Estimates certainty using token-level probabilities or semantic consistency across samples | White-box for token scoring; API for semantic consistency | Low to high | Triage layer to route low-confidence outputs to deeper evaluation |
| Attention map analysis | Analyzes internal attention patterns to identify claims with low grounding in source passages | White-box only | Low — no additional inference calls needed | Real-time, token-level detection on open-weight models |
Can you combine hallucination detection methods?
Permalink to “Can you combine hallucination detection methods?”Combining methods is standard practice for production pipelines handling consequential decisions. Three combination patterns work well in practice:
- Token-level detection plus NLI grounding: Token-level detection provides recall by catching potential hallucinations broadly. NLI classification adds precision by filtering false positives and categorizing why each flagged span is problematic.
- Confidence scoring plus LLM-as-a-judge: Use confidence scoring as a cheap first pass to identify low-certainty outputs, then route only those outputs to LLM-as-a-judge for deeper evaluation. This controls cost while preserving coverage on the queries most likely to contain errors.
- Self-consistency plus grounding verification: Self-consistency flags outputs where the model produces variable answers across samples. Grounding verification then checks whether any of those answers are supported by retrieved context.
The enterprise gap: Why hallucination detection methods fail without governed context
Permalink to “The enterprise gap: Why hallucination detection methods fail without governed context”Every detection method described above operates at the inference layer. They evaluate what the model produced after generation. None of them address the layer where most enterprise hallucinations originate.
The four most common organizational context failures that produce hallucinations are:
- Conflicting metric definitions: The same term is defined differently across systems. The agent retrieves one version without knowing another exists.
- Stale lineage: The data source the agent consulted was accurate months ago but has since been deprecated. No mechanism flagged the change.
- Uncertified sources: The agent retrieved from a source that was never validated against organizational standards.
- Ungoverned policies: A compliance rule that would have constrained the agent’s answer was never encoded in a form the agent could access during inference.
When an enterprise AI agent reports the wrong quarterly revenue figure, the most likely explanation is that the model reasoned correctly on bad input. While hallucination detection catches this error after the fact, governed context can prevent it before generation begins.
How Atlan addresses the context layer
Permalink to “How Atlan addresses the context layer”Atlan’s Context Engineering Studio is built around the premise that most enterprise hallucinations are a context problem, not a model problem. Its capabilities map directly to the failure modes above:
- Context graph with GraphRAG: Traverses entities, lineage, policies, and quality signals simultaneously. This provides explainable reasoning paths and automatically ensures agents inherit governance boundaries.
- MCP server integration: Agents query real-time metadata (lineage, tags, quality signals, usage metadata) as tools and don’t guess from stale or conflicting sources.
- Context Studio for bootstrapping and evaluation: Teams bootstrap context repositories from existing assets such as dashboards, SQL queries, and transformation logic.
- Policy-as-graph: Governance rules propagate as queryable nodes and edges, so agents inherit the same boundaries as humans.
- Decision traces and temporal awareness: Agents reason about what was true at a specific point in time and reuse prior resolutions. This prevents context bleed where current queries mix outdated states.
Real stories from real customers: Context governance for scaling enterprise AI meaningfully
Permalink to “Real stories from real customers: Context governance for scaling enterprise AI meaningfully”Context as Culture at Workday
Permalink to “Context as Culture at Workday”"We're excited to build the future of AI governance with Atlan. All of the work that we did to get to a shared language at Workday can be leveraged by AI via Atlan's MCP server…as part of Atlan's AI Labs, we're co-building the semantic layer that AI needs with new constructs, like context products."
Joe DosSantos
VP of Enterprise Data & Analytics, Workday
Context Readiness at DigiKey
Permalink to “Context Readiness at DigiKey”"Atlan is much more than a catalog of catalogs. It's more of a context operating system…Atlan enabled us to easily activate metadata for everything from discovery in the marketplace to AI governance to data quality to an MCP server delivering context to AI models."
Sridher Arumugham
Chief Data & Analytics Officer, DigiKey
Context for All at Virgin Media O2
Permalink to “Context for All at Virgin Media O2”"What we cared about was that part of engagement & adoption and what platform… was brave enough to work with us as a telco to go through all the hoops that we have. And Atlan from day one was that partner."
Mauro Flores
EVP of Data Democratization, Virgin Media O2
Moving forward with hallucination detection
Permalink to “Moving forward with hallucination detection”Hallucination detection is a necessary discipline for any enterprise running AI in production. The six methods described earlier each catch a different class of error. Layering them produces better coverage than any single method alone.
However, detection catches what slips through, whereas governed context reduces how much slips through in the first place. The organizations that achieve the lowest hallucination rates treat context governance as the primary investment and detection as the verification layer that confirms it is working.
Atlan’s Context Engineering Studio operationalizes that investment, giving agents accurate, governed, conflict-free organizational context before they begin reasoning.
FAQs about hallucination detection methods
Permalink to “FAQs about hallucination detection methods”1. What is hallucination detection in AI?
Permalink to “1. What is hallucination detection in AI?”Hallucination detection is the process of identifying when an AI model generates output that is factually incorrect, unverifiable, or inconsistent with the context it was given. It encompasses automated methods such as grounding verification, self-consistency checking, and semantic entropy estimation, as well as model-internal approaches like attention map analysis and human-in-the-loop review processes.
2. Which hallucination detection method is most accurate?
Permalink to “2. Which hallucination detection method is most accurate?”No single method is universally most accurate as accuracy depends on the failure type being targeted. NLI-based grounding verification is strongest for faithfulness errors against retrieved context. Semantic entropy estimation is strongest for open-ended factual queries. LLM-as-a-judge provides the most flexible and explainable evaluation across error types. Production pipelines that combine methods — for example, confidence scoring as a triage layer followed by LLM-as-a-judge for flagged outputs — consistently outperform single-method approaches.
3. Does RAG eliminate hallucination?
Permalink to “3. Does RAG eliminate hallucination?”RAG significantly reduces hallucination by grounding model responses in retrieved documents rather than parametric memory alone. It does not eliminate hallucination. The model can still misrepresent retrieved content, add information not present in retrieved documents, or retrieve from sources that are themselves inaccurate, stale, or conflicting. The quality of what is retrieved matters as much as the retrieval mechanism itself.
4. What is LLM-as-a-judge for hallucination detection?
Permalink to “4. What is LLM-as-a-judge for hallucination detection?”LLM-as-a-judge uses a second language model to evaluate the output of the primary model. The judge receives the original query, the retrieved context, and the generated answer, then identifies contradictions, fabrications, or unsupported claims. It is flexible, explainable, and handles both faithfulness and factual errors — but adds cost and latency because it requires a second inference call. It is best suited to high-stakes, lower-volume queries or sampling-based monitoring rather than per-query evaluation on high-throughput pipelines.
5. What is the difference between NLI-based grounding, grounding verification, and retrieval verification?
Permalink to “5. What is the difference between NLI-based grounding, grounding verification, and retrieval verification?”NLI-based grounding tests whether each claim logically follows from the retrieved context using entailment classification — it tells you why a claim is problematic, whether it is contradicted, unverifiable, or entailed. Grounding verification tests sourcing: can every claim be traced to a specific passage? It is faster and simpler but less explanatory. Retrieval verification goes one step earlier and asks whether the retrieval step itself surfaced the right documents in the first place. All three target faithfulness errors and none catches extrinsic hallucinations where the model adds information absent from retrieved documents.
6. What is semantic entropy in hallucination detection?
Permalink to “6. What is semantic entropy in hallucination detection?”Semantic entropy measures how much the meaning of a model’s responses varies across multiple samples of the same query. Unlike simple text comparison, it clusters responses by semantic equivalence — two responses that say the same thing differently are treated as consistent. High entropy indicates the model is uncertain about the correct answer, which correlates strongly with hallucination. Low entropy is a positive signal for factual reliability.
7. Can hallucination detection methods be combined?
Permalink to “7. Can hallucination detection methods be combined?”Yes, and in high-stakes production pipelines they routinely are. Effective combinations include token-level detection paired with NLI grounding for precision and recall, confidence scoring used as a cheap triage layer before routing flagged outputs to LLM-as-a-judge, and self-consistency combined with grounding verification to catch both model uncertainty and source unfaithfulness. The general design principle is to use a fast, broad method as the first filter and a slower, more precise method as the second pass.
8. Why do enterprise AI agents hallucinate even with good models?
Permalink to “8. Why do enterprise AI agents hallucinate even with good models?”Enterprise hallucinations most commonly trace to organizational context failures rather than model capability limitations. Agents hallucinate when they retrieve from conflicting metric definitions across systems, access stale or deprecated data sources, draw from uncertified or ungoverned data, or lack access to governance rules that should constrain their answers. No detection method compensates for a context layer that is inconsistent, stale, or ungoverned. Fixing the context — through governed definitions, accurate lineage, and canonical sources — reduces the volume of errors that detection methods need to catch.
