



















You tested your AI agent for six weeks. Every demo worked. Then it hit production.
Within 72 hours (illustrative): the revenue dashboard showed figures 12% below what the agent reported. The PII-restricted customer segment appeared in an executive summary. Two agents querying the same pipeline returned answers that contradicted each other.
These are not bugs, they are six predictable structural failures. Every data team building AI agents eventually hits all of them.
| Dimension | Detail |
|---|---|
| What they are | Six recurring failure modes that emerge when AI agents operate without sufficient enterprise context |
| Who encounters them | Data engineers, ML engineers, AI platform teams building production agents |
| When they appear | Cold Start (initialization), Testing Hell (L3), Scale Hell (L4) |
| Primary impact | Wrong outputs, hallucinations, contradictory agent answers, compliance failures |
| Root cause | Missing or fragmented enterprise context layer |
| Solution category | Enterprise context layer with active metadata, unified definitions, permission-aware retrieval |
The failures are predictable, follow a maturity curve, and unlike model failures, they cannot be resolved by improving the model.
The 6 context failure modes every data team hits
Permalink to “The 6 context failure modes every data team hits”Enterprise AI agent failures are not random. They fall into six predictable failure modes that appear at consistent stages of agent maturity. Some surface the first time an agent is deployed. Others only appear when five agents are running in parallel against the same data warehouse. All six are structural. They are not fixed by improving the model, rewriting the prompt, or adding more compute.
The taxonomy below maps each failure mode to the maturity stage where it emerges, the system component it breaks, and the architectural fix direction. These are named because unnamed problems cannot be diagnosed. If your team cannot say which of these six you have, you cannot fix the right thing.

The failure modes data teams hit when building AI agents without a metadata layer. Source: Atlan.
Context Starvation: when agents start blind
Permalink to “Context Starvation: when agents start blind”Context Starvation occurs when an AI agent initializes without the business metadata it needs to interpret what it retrieves: definitions, ownership, lineage, and business rules. The output is technically accurate. The answer is wrong.
At runtime, the failure is quiet. An agent querying customer_lifetime_value returns a number. The SQL is clean. The table join is correct. The number is mathematically accurate. It is also wrong, because no one told the agent that the CLV definition changed in Q2 2025. The field now uses a 24-month lookback window instead of 12, and excludes trial accounts. The agent used the legacy calculation. The business report went to the board with last year’s methodology applied to this year’s data.
The failure is not in the query. It is in the initialization: the agent began work without knowing what the data means in the current business context.
A LangGraph-based agent querying BigQuery faces this by default. BigQuery knows the schema. It does not know that mau_count means product MAU for the growth team and billing MAU for finance. That knowledge lives in the metadata catalog, the business glossary, and the minds of the people who built the pipeline. Without a mechanism to surface that knowledge at agent initialization, the agent is operating blind.
Encoding definitions in the prompt is the first instinct, and it is the wrong fix. Prompts are static. Business definitions change. A prompt written in January does not know that the revenue recognition policy changed in March. It does not know that a table was recertified last week. It does not know that the field owner changed.
The correct fix: pre-warm agent context from a unified catalog before deployment. Certified definitions, ownership records, lineage graphs, and business rule flags should be injected at the retrieval layer, not hardcoded in a prompt that will be stale within weeks.
Stage: Cold Start. Appears at initialization, before any feedback loop exists.
Context Rot: when agents degrade without warning
Permalink to “Context Rot: when agents degrade without warning”Context Rot is the gradual degradation of agent accuracy as cached context becomes stale. The agent’s working knowledge diverges from the current state of the data without triggering any visible error.
In long-running sessions, the failure is invisible until it isn’t. A reporting agent refreshes weekly metrics correctly for the first three weeks of deployment. In week four, a dbt model is deprecated. The replacement model has a different grain: weekly instead of daily aggregation. The agent’s context cache was never invalidated. It continues citing the deprecated model, generating outputs against a schema that no longer exists in the same form. No error surfaces. The reports look complete.
The agent’s working knowledge has diverged from the data environment, and there is no mechanism to detect it.
Context accuracy degrades across long tool-call chains in a predictable arc. In long-running agent sessions, the first 10-15 tool calls use accurate context. By call 20-30 (an illustrative pattern based on observed production behaviors rather than a formal benchmark), the agent has accumulated context from multiple sources: a Snowflake schema version from session start, a dbt model description from a mid-session tool call, a business glossary entry from an earlier retrieval. These sources do not agree. The agent synthesizes across them without flagging the conflict. Output quality drops incrementally, not catastrophically, which means the degradation often goes undetected in review.
The fix requires active metadata with TTL policies. Each context element should carry a source timestamp and a configured expiry. When an element expires, the agent re-fetches from the live catalog rather than continuing to operate on stale context. Context management must be externalized to the context layer, not left in the agent’s working memory where there is no governance mechanism to invalidate it.
Stage: Testing Hell (L3). Common in long-running agents, invisible in single-session demos.
Context Fragmentation: when every tool has a different story
Permalink to “Context Fragmentation: when every tool has a different story”Context Fragmentation is what happens when multiple agents each maintain their own isolated context state. The underlying data is the same. The world models they build from it are not.
RAG accelerates this failure in enterprise environments. When an agent uses retrieval-augmented generation to pull context from multiple sources: the data catalog, the BI semantic layer, a dbt model description, a Slack message from the data team. Each source may describe the same asset differently. The ARR definition in Looker is contracted annual value. The ARR definition in the dbt model comment is recognized revenue. The ARR definition the analyst added to the prompt six months ago excludes renewals. The RAG system retrieves all three. The agent synthesizes a number that is wrong in three different ways simultaneously.
Without a single source of truth, the contradiction surfaces at the worst possible moment. Agent A queries recognized_revenue_q4 with the definition from Snowflake’s semantic layer. Agent B queries the same field using the definition from dbt. They return different figures to the same executive dashboard in the same board meeting. Neither agent flagged an error. Both agents completed successfully. The downstream consumer, an executive reading two contradictory revenue figures, has no mechanism to know which one is right.
The fix: one canonical source of truth enforced through the metadata catalog. Agents should have one place to query context about any given asset: one definition, one certified owner, one lineage path. Fragmentation is not resolved by improving retrieval. It is resolved by eliminating competing sources of truth.
Stage: Scale Hell (L4). Surfaces when multiple agents draw from multiple tool outputs simultaneously.
Context Collision: when agents contradict each other
Permalink to “Context Collision: when agents contradict each other”Context Collision is the failure mode where parallel agents produce divergent outputs on identical data because they were initialized with different context states, often without any agent or system detecting the contradiction.
Parallel agents without a shared context state produce results that cannot be reconciled. Two procurement agents evaluate the same supplier pool. Each agent was initialized separately. Each pulled from a different version of the vendor risk catalog: one from Monday’s scheduled sync, one from a manual update pushed Tuesday morning. The risk scores differ by vendor. The agents recommend different suppliers. Neither agent knows the other exists. The downstream procurement system receives two contradictory recommendations with no reconciliation mechanism.
It is not a logic error in either agent. It is an initialization architecture failure: parallel agents with no shared context store, no version lock on the context state, and no collision detection at instantiation.
In financial services, the business risk is concrete. A regulatory reporting agent uses prior-quarter definitions locked for compliance. An operational agent uses current-quarter definitions updated daily. Both query the same revenue table in BigQuery. Both complete successfully. Their outputs differ by 8% (illustrative). An analyst spends four hours diagnosing a discrepancy that was architectural from the start.
Context versioning is not optional at Scale Hell. Parallel agents must read from a shared context store with explicit version locking for time-sensitive definition windows. RBAC must be enforced at the context layer and inherited by each agent, not replicated per-agent with no coordination mechanism. Every agent that does not inherit from a shared context state is a contradiction waiting to surface downstream.
Stage: Scale Hell (L4). Only appears once multi-agent orchestration is in place.
Permission Blindness: when agents retrieve what they shouldn’t
Permalink to “Permission Blindness: when agents retrieve what they shouldn’t”Permission Blindness is a retrieval architecture failure. The agent uses service account credentials rather than the end user’s actual access rights, so it either surfaces data the user is not authorized to see, or denies data the user legitimately holds.
Service accounts are the most common source. A finance agent runs on a service account with broad read permissions across the data warehouse. An analyst in the US region asks the agent to summarize regional revenue performance. The agent retrieves data from all regions, including EMEA revenue figures the analyst is not authorized to see. The report surfaces EMEA data in an output delivered to a US-only stakeholder. No error was raised. No access denial log was generated. The agent completed successfully, and the permission violation was invisible until an audit.
The failure is architectural: the retrieval layer uses service account credentials rather than the end user’s scoped access rights. The agent has no mechanism to know the difference.
The inverse failure is equally common and equally invisible. Agents running under overly restrictive service account policies cannot access data the end user legitimately holds permissions for. The agent returns “I do not have access to that data,” even though the user asking the question has full access. The agent is not using the user’s credentials. It is using its own.
The fix: user identity and role context must propagate through the entire retrieval chain. Retrieval calls must use row-level security tokens scoped to the end user’s actual permissions, not service accounts. The context layer must carry permission provenance alongside data context. This is not an application-layer check applied after retrieval. It must be enforced at the retrieval layer itself, before data reaches the model.
Stage: Testing Hell (L3) and Scale Hell (L4). Frequently invisible in dev environments where all tables are accessible; surfaces in production when real RBAC is enforced.
Scope Overload: when context becomes noise
Permalink to “Scope Overload: when context becomes noise”Scope Overload is a retrieval scoping failure. When the context window fills with irrelevant tokens: broad schema dumps, unfocused metadata, verbose business glossary entries. The signal-to-noise ratio collapses. The context window rarely fills in a technical sense. The relevant signal gets buried.
More context is not always better. An agent asked “what was our Q3 churn rate in EMEA” receives a context payload containing the full business glossary (hundreds of metric definitions in a typical enterprise) because the retrieval layer has no semantic scope filter. The relevant answer is present. It is buried under 846 irrelevant definitions (illustrative). The model’s attention mechanism cannot reliably locate it. The agent begins synthesizing across adjacent definitions: Q2 churn, Q3 churn globally, EMEA retention rate. It produces a plausible but incorrect number.
A data engineering team building a dbt documentation agent injects the complete database schema (1,200 columns across 80 tables), the full dbt project DAG (340 models), and the last 90 days of Slack messages from the data team. For the first 10 models, output quality is high. By model 40, descriptions become generic. By model 60, the agent begins confusing column names across tables. The context window was never full in a technical sense. The signal-to-noise ratio simply collapsed.
Full-schema injection degrades agent reasoning as volume grows, and Scale Hell amplifies the problem. As more agents run, more metadata accumulates, and retrieval systems with no scope filter return increasingly bloated payloads.
The fix: semantic scoping at retrieval, progressive context loading, and relevance ranking before injection. The agent should receive the context relevant to the specific query at the moment of retrieval, not a snapshot of everything stored in the retrieval layer. The retrieval layer is responsible for scope management. The model should not be expected to self-filter.
Stage: Scale Hell (L4). Worsens as context library grows.
Taxonomy summary
Permalink to “Taxonomy summary”| Problem | Stage | What breaks | Fix direction |
|---|---|---|---|
| Context Starvation | Cold Start | Agent answers with stale/missing definitions | Pre-warm from unified catalog |
| Context Rot | Testing Hell (L3) | Agent cache diverges from live data silently | Active metadata with TTL invalidation |
| Context Fragmentation | Scale Hell (L4) | Multiple agents produce different answers | Shared context layer |
| Context Collision | Scale Hell (L4) | Parallel agents contradict each other | Context sync with collision detection |
| Permission Blindness | L3 + L4 | Agent surfaces restricted data | Permission-aware retrieval |
| Scope Overload | Scale Hell (L4) | Reasoning degrades under irrelevant context | Semantic scoping at retrieval |
Why context problems follow a maturity curve
Permalink to “Why context problems follow a maturity curve”The six failure modes — Context Starvation, Context Rot, Context Fragmentation, Context Collision, Permission Blindness, and Scope Overload — are not randomly distributed across agent deployments. They appear at predictable maturity stages. Understanding the stage tells you which class of problem to diagnose first. It prevents teams from investing in Scale Hell solutions when they are actually stuck in Testing Hell.
Testing Hell: why demos succeed and production fails
Permalink to “Testing Hell: why demos succeed and production fails”Testing Hell is the stage where an agent performs correctly in isolation and fails in production. The conditions that made the demo work — the developer’s own access credentials, manually curated schema descriptions in the prompt, a single user with full table permissions, a static data state — do not transfer to the production environment.
A 2025 ModelOp benchmark found that 58% of enterprises cite fragmented governance systems as the top obstacle to AI deployment at scale. Testing Hell is where most of those failures originate. The agent worked in the demo. It did not work in the hands of real users with real RBAC, real schema drift, and real metric conflicts. Testing Hell is the most common production manifestation of the context vacuum problem.
Context Starvation, Context Rot, and Permission Blindness are Testing Hell problems. They appear when the manually assembled context that worked during development encounters the production environment where context is not manually assembled. It either exists as governed infrastructure or it does not exist at all.
The enterprise-scale version of Testing Hell looks like this: LangGraph agents deployed in production, context manually built per use case across BigQuery, Databricks, IBM, Google Cloud, and Alation. Every new use case requires a new context pipeline built by the team that knows that domain. Every new agent is a new manual context assembly project. There is no shared infrastructure. The team is not in Scale Hell yet. They are in Testing Hell at enterprise scale, and the path to Scale Hell runs through an unbuilt context layer.
Scale Hell: when multi-agent deployments break
Permalink to “Scale Hell: when multi-agent deployments break”Scale Hell is the stage where one agent becomes five, five becomes twenty, and the absence of shared context infrastructure becomes a maintenance crisis. Each agent was built by a different team. Each has its own context assembly logic. Definitions diverge across agents. Permission models are replicated per agent rather than inherited from a central authority. A change to the revenue definition requires updating fourteen agents. No one knows which ones have been updated.
Context Fragmentation, Context Collision, and Scope Overload are Scale Hell problems. They do not appear in single-agent testing and are invisible in Testing Hell scenarios. They emerge when parallel agents operate against the same data without a shared context state. Their contradictions surface downstream where no one can explain them.
Scale Hell is not a scaling problem. It is a context management architecture problem that looks like a scaling problem from the outside.
Cold Start failures precede both Testing Hell and Scale Hell. They are the reason Context Starvation is the first failure mode on the taxonomy. Cold Start is not a maturity failure. It is an initialization failure. Every new agent deployment faces it: no history, no memory, no pre-loaded business context. The fix is not experience or iteration. It is a context layer that initializes agents with certified, current context before the first query runs, sourced from the metadata catalog, scoped to the agent’s domain, and versioned so the agent knows how fresh its context is.
How to address context problems systematically
Permalink to “How to address context problems systematically”Context is not a prompt problem. It is an infrastructure problem: definitions, permissions, and lineage must live in a governed, queryable layer, not assembled ad hoc before each deployment. The same infrastructure gaps that cause data governance failures in analytics cause context failures in AI agents.
Three architectural requirements apply across all six problems:
Single context authority per asset type
Permalink to “Single context authority per asset type”Context Fragmentation and Context Collision are both caused by the absence of a single authoritative source. Every data asset needs one canonical definition, one certified owner, one lineage path, queryable through one API. Multiple competing sources of context truth is the architectural condition that produces contradictory agent outputs.
Permission-aware context propagation
Permalink to “Permission-aware context propagation”Permission Blindness is caused by permission context not traveling with data context through the retrieval chain. User identity and role context must be propagated from the identity layer through retrieval to the model. This cannot be enforced at the application layer after retrieval has already occurred. Both the NIST AI Risk Management Framework and ISO/IEC 42001:2023 require access controls to be applied as close to the data source as possible, not as a post-retrieval filter.
Context versioning with TTLs
Permalink to “Context versioning with TTLs”Context Rot occurs when agents operate on stale context with no mechanism for invalidation. Every context element must carry a source timestamp and a configurable TTL. When context expires, agents re-fetch from the live catalog rather than operating on cached data that may no longer reflect the current state of the system.
These three requirements describe a context layer: not a new application, but a governed abstraction over existing metadata, lineage, and permission systems that makes that information consistently accessible to agents.
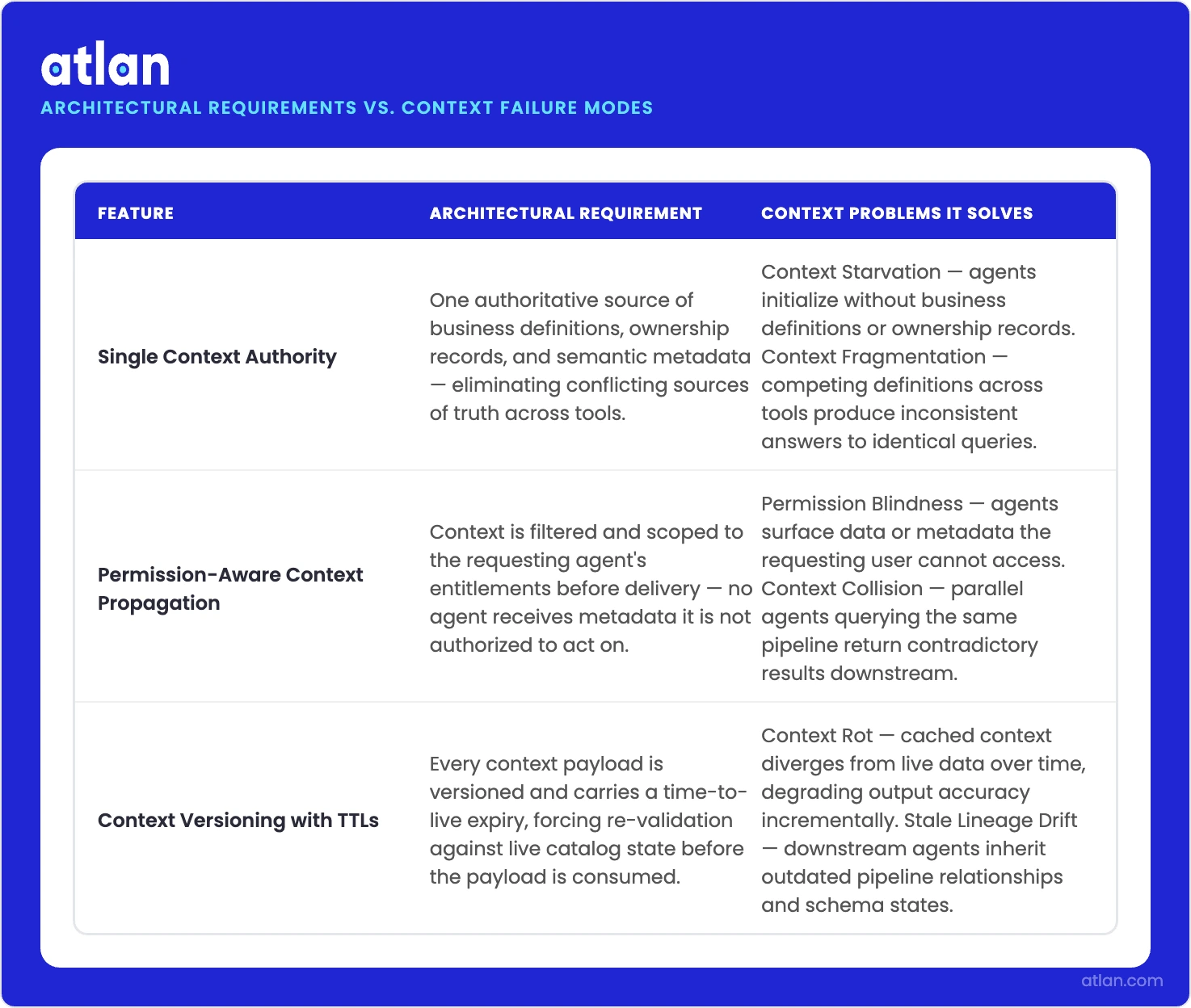
How three design requirements map to the six context problems AI data agents face. Source: Atlan.
How Atlan resolves context problems for data teams building agents
Permalink to “How Atlan resolves context problems for data teams building agents”A large enterprise data team, 40+ engineers across three product lines, deployed LangGraph agents against their Snowflake and BigQuery environments. Their first wave of agents handled routine reporting and anomaly detection. Those worked. The second wave added cross-domain data products, and that’s when things broke in ways they couldn’t explain.
Two agents querying the same revenue table returned figures that diverged by 6% within the same dashboard. The team eventually traced the discrepancy to Context Fragmentation: one agent pulled its arr definition from the dbt semantic layer, the other from a Looker LookML file that hadn’t been updated since a pricing model change in Q3. Both definitions were “official.” Neither was wrong in isolation. The combination was a contradiction.
At the same time, an agent summarizing customer health scores began surfacing EMEA churn data in reports delivered to US-only stakeholders. This was Permission Blindness: the agent ran on a service account with warehouse-wide read access, with no mechanism to scope retrieval to the requesting user’s actual permissions. The violation was invisible in dev, where every engineer had full access, and silent in production until a compliance review flagged it six weeks later.
The team had tried to solve both problems the manual way: separate context pipelines per agent, hardcoded definitions in system prompts, custom permission checks bolted onto each retrieval call. It worked for three agents. By agent eleven, no one knew which context pipeline was current.
When they connected their agent fleet to Atlan’s context layer API, the architecture changed at the retrieval layer, not at the agent level.
The fragmentation problem resolved first. Rather than each agent sourcing its own definition of arr, recognized_revenue, or mau_count, agents queried Atlan for the canonical definition of each asset by URN before operating on it. One definition per asset, period. The dbt comment and the Looker LookML were reconciled into a single authoritative record. Revenue discrepancies across the dashboard dropped to zero.
Permission Blindness resolved without any changes to the agent code. Atlan’s retrieval API is RBAC-aware. When an agent queries on behalf of a user, the retrieval call carries that user’s identity token and returns only assets the user is authorized to see, not the service account’s broader permissions. The EMEA data that had been surfacing in US-stakeholder outputs stopped appearing.
The same infrastructure addressed the other four failure modes: Context Starvation was handled through catalog-initialized context at agent startup rather than prompt-hardcoded definitions; Context Rot through TTL-governed metadata that expired and re-fetched rather than accumulating silently; Context Collision through a shared context store with version locking available for quarterly close periods; Scope Overload through relevance-filtered retrieval scoped by asset URN and domain rather than free-text search across the full catalog.
Atlan integrates with LangGraph, LangChain, CrewAI, AutoGen, MetaGPT, and other orchestration frameworks through an API-first architecture. For teams adopting MCP-based agent protocols, Atlan’s context API exposes asset metadata, lineage, and permission state as structured context that MCP-compatible agents can query at call time. Context is queryable by asset URN and by semantic relationship: upstream lineage, downstream consumers, certified definitions, and classification tags, so agents retrieve exactly the context required for a given task.
See how Atlan resolves context failures in production agent deployments.
Book a demoFAQs about context problems for AI agents
Permalink to “FAQs about context problems for AI agents”What is the most common reason AI agents fail in production?
Permalink to “What is the most common reason AI agents fail in production?”Context failure, not model failure. Enterprise AI agents almost universally fail because they lack access to the business metadata, permissions, and definitions that make data meaningful. A model that returns the right number for the wrong metric definition is not a model problem. It is a context architecture problem. The fix requires externalizing context into governed infrastructure, not improving the model.
What are the most common context failure modes?
Permalink to “What are the most common context failure modes?”Context Starvation and Scope Overload represent the two ends of the same spectrum. Context Starvation is when an agent is initialized without the business metadata it needs to interpret the data it retrieves, producing outputs that are technically accurate at the database level but wrong at the business level. Scope Overload is the opposite failure: too much context injected without semantic filtering, causing the model’s attention mechanism to degrade as signal-to-noise collapses. Both are retrieval layer problems, not model limitations.
What is the difference between Context Rot and Context Fragmentation?
Permalink to “What is the difference between Context Rot and Context Fragmentation?”Context Rot is a temporal problem: a single agent’s context degrades over a session as cached data becomes stale or contradictory. Context Fragmentation is a structural problem: multiple source systems describe the same asset differently, so any agent consulting more than one source builds a contradictory world model from the start. One is a runtime failure; the other is an architecture failure.
What is Context Collision and when does it appear?
Permalink to “What is Context Collision and when does it appear?”Context Collision occurs in multi-agent architectures when two or more agents query the same data simultaneously using different context states: different definitions, different schema versions, or different permission scopes. It produces results that cannot be reconciled downstream. Context Collision is a Scale Hell problem: it only appears once multi-agent orchestration is in place and is invisible in single-agent Testing Hell scenarios.
How does Permission Blindness differ from a standard access control misconfiguration?
Permalink to “How does Permission Blindness differ from a standard access control misconfiguration?”A standard misconfiguration is visible. Access is denied and an error is raised. Permission Blindness is silent: the agent retrieves data using a service account with broader permissions than the end user holds, returns unauthorized data with no error, and the compliance violation is invisible until an audit. The fix is architectural: RBAC context must propagate through the retrieval layer, not just the application layer.
What infrastructure is needed to move past Testing Hell?
Permalink to “What infrastructure is needed to move past Testing Hell?”Testing Hell (L3) is where an agent passes every demo but fails in production with real data, real permissions, and real users. Context problems are the cause: manually assembled context does not scale or persist. Context Starvation, Context Rot, and Permission Blindness all peak here. Moving past Testing Hell requires a governed context layer, not just a metadata catalog. A catalog alone solves Context Starvation and reduces Context Fragmentation, but it does not address Context Rot (requires TTL and versioning), Context Collision (shared state), Permission Blindness (RBAC propagation), or Scope Overload (relevance filtering). The governance infrastructure that makes production viable does not exist in development environments, and it cannot be built from prompts alone.
Name the right failure mode or you fix the wrong thing
Permalink to “Name the right failure mode or you fix the wrong thing”Every week an agent runs without governed context infrastructure is a week of silent failures, unauthorized retrievals, and engineering time spent manually patching context that should be infrastructure.
The six failure modes in this taxonomy — Context Starvation, Context Rot, Context Fragmentation, Context Collision, Permission Blindness, Scope Overload — are not edge cases. They are the predictable consequence of building agents on top of data environments where context has not been treated as infrastructure. Every data team building agents will encounter at least three of these. Most will encounter all six.
You can now name which problem you have. Context Rot is different from Context Fragmentation. Permission Blindness is different from Context Collision. Each has a different fix. Name the right one or you fix the wrong thing.
The longer-term consequence matters more. Agents operating in production without a context layer are not just producing wrong outputs today. They are accumulating technical debt in the form of per-agent context pipelines, manual definition patches, and service account architectures that will require full rewrites to fix at Scale Hell. The AI teams moving toward agents-as-teammates — agents that operate autonomously within enterprise data environments and are trusted by the people who depend on their outputs — will not get there on manually assembled context. They will get there when context is infrastructure.
