


















More than 40% of agentic AI projects will be canceled by end of 2027 (Gartner, June 2025).
In most canceled projects, the model will not be the problem. The pipeline will be. The metadata will be.
Quick facts: enterprise AI data infrastructure readiness
| Fact | Source |
|---|---|
| Unifying five levels of enterprise context achieves 94-99% AI accuracy, compared to 10-20% accuracy with schema information alone | Promethium, Context Architecture for AI Analytics Guide, 2025 |
| The enterprise metadata management market is projected to reach $12.89 billion in 2026, growing at a 21% CAGR as AI drives metadata to a core infrastructure layer | The Business Research Company, Enterprise Metadata Management Global Market Report, 2026 |
| 44% of enterprises say their AI governance process is too slow; 24% say it is overwhelming | ModelOp, AI Governance Benchmark Report, 2025 |
| Fewer than one-third of organizations have begun scaling AI across the enterprise, with governance and infrastructure bottlenecks cited as blockers | McKinsey, The State of AI 2025 |
| Prerequisites | A functioning data warehouse or lakehouse (Snowflake, BigQuery, or Databricks), a governance framework, and a data engineering team capable of maintaining pipeline SLAs are required before implementing AI-specific infrastructure layers |
| Implementation time | Organizations at L2 (centralized storage, basic catalog) require 6-9 months to reach L3 (production-agent-ready); organizations at L1 (ad hoc pipelines) require 18-24 months |
What makes data infrastructure “AI-ready”
Permalink to “What makes data infrastructure “AI-ready””AI-ready data infrastructure is the technical substrate that enables production AI agents to reliably retrieve, interpret, and act on enterprise data without human intervention. It differs from analytics infrastructure in one critical way: AI agents cannot reconcile ambiguous or inconsistent data. They need infrastructure that resolves context, enforces access policies, and delivers accurate lineage automatically at runtime.
Why does BI-era infrastructure fail AI agents?
Permalink to “Why does BI-era infrastructure fail AI agents?”Business intelligence workloads tolerate stale metadata, inconsistent definitions, and manual lineage because a human analyst can reconcile ambiguity in real time. An analyst who sees three different “revenue” figures across a dashboard knows to ask which one is the source of truth. An AI agent does not ask. It produces an answer and passes it downstream.
Consider an agent querying “revenue” across a finance system (recognized revenue), a marketing system (pipeline revenue), and an operations system (booked revenue) with inconsistent semantic definitions. The agent returns three different figures and cannot detect the discrepancy. That is not a model failure. It is an infrastructure failure. Only a semantic metadata layer can fix it.
| Infrastructure requirement | BI / analytics workload | AI agent workload |
|---|---|---|
| Metadata consistency | Tolerated if analyst reconciles manually | Required; agents cannot self-correct |
| Lineage depth | Table-level sufficient for dashboards | Column-level required for trust and auditability |
| Context delivery latency | Batch (T-1) acceptable | Real-time or near-real-time at inference |
| Access control granularity | Dataset and table level adequate | Attribute and column level required for cross-domain queries |
What are the four components of AI-ready data infrastructure?
Permalink to “What are the four components of AI-ready data infrastructure?”AI-ready data infrastructure requires four components working simultaneously. Governed pipelines without a semantic metadata layer still produce agents that return wrong answers: each component is load-bearing.
The first is data pipelines: governed with documented freshness SLAs, automated failure detection, and embedded quality validation rather than post-hoc remediation. The second is a semantic metadata layer: machine-readable definitions for every entity agents will query, consistent across all domains, accessible via API at inference time. The third is data lineage: end-to-end, column-level lineage that traces any agent output back to its source system, maintained automatically by tools like dbt and Apache Spark. The fourth is access controls: attribute-level and column-level policies enforced at inference time, with AI agent identities explicitly modeled rather than inherited from BI dashboard permissions.
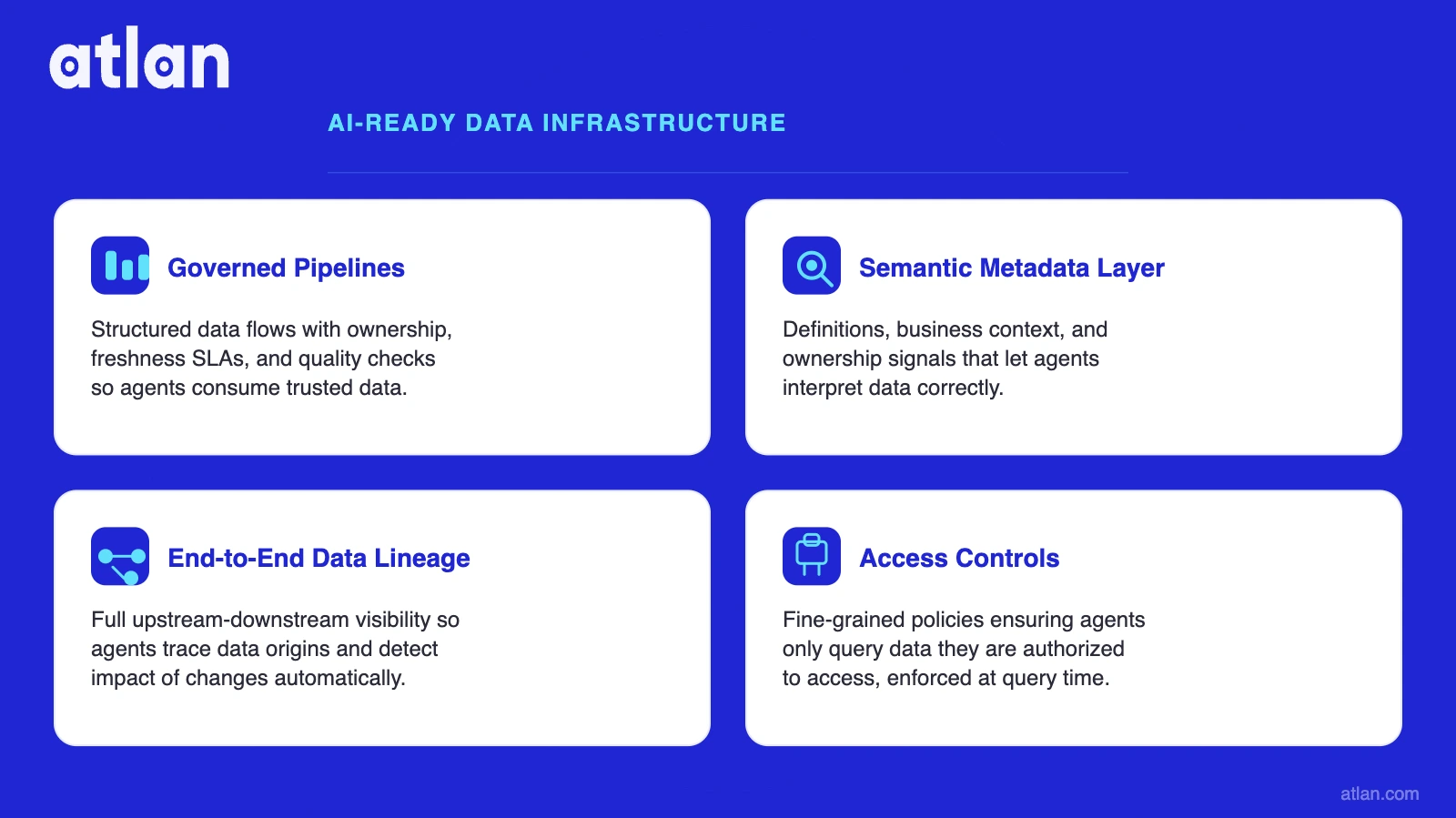
Four essential components that make data infrastructure ready for AI agents. Source: Atlan.
The L1–L5 infrastructure maturity model
Permalink to “The L1–L5 infrastructure maturity model”AI infrastructure maturity runs from L1 (ad hoc pipelines, no catalog) to L5 (federated multi-agent infrastructure with automated freshness SLAs). Production AI agents require L3 minimum: a governed metadata layer with automated lineage and semantic definitions. Most enterprises with active AI pilots are operating at L2–L3, with manual context assembly as the primary bottleneck.
| Level | Infrastructure state | AI agent capability | Key blocker |
|---|---|---|---|
| L1 | Ad hoc pipelines, no catalog, schema-on-read | Not viable; data not reliably discoverable | No data discoverability; agents cannot find data |
| L2 | Centralized storage (Snowflake, BigQuery, or Databricks), basic catalog, manual lineage | Possible with per-use-case human setup | Manual context assembly: 6–8 weeks per agent deployment |
| L3 | Governed metadata layer, automated lineage, semantic definitions | Production deployable | Context layer required; cannot deploy without it |
| L4 | Policy-aware pipelines, attribute-level access control, real-time context APIs | Autonomous operation | Policy automation and real-time context infrastructure |
| L5 | Multi-agent orchestration, federated metadata across domains, automated freshness SLAs | Enterprise-scale multi-agent systems | Federated governance and cross-domain context |
L1–L3: from foundation to production
Permalink to “L1–L3: from foundation to production”At L1, the fundamental problem is discoverability. Data exists in silos, schemas are undocumented, and pipelines run ad hoc. An agent cannot reliably find the data it needs, let alone interpret it correctly. Deploying agents at L1 produces unreliable outputs regardless of the model.
At L2, centralized storage exists but context is assembled manually by data engineers. Each new agent use case requires 6–8 weeks of manual setup: writing bespoke pipelines to serve definitions and lineage to each deployment, one at a time. L2 is the starting point. See Atlan’s AI readiness guide for what the full journey requires.
L3 is the minimum viable infrastructure state for production AI agents. It requires a governed metadata layer, automated lineage capture, and semantic definitions that agents can query at runtime without manual assembly per use case. Organizations at L3 can deploy agents in production, though manual intervention is still required for edge cases, new data domains, or policy changes.
Three things are required to reach L3:
- A semantic metadata store with machine-readable definitions for all agent-queried entities
- Automated lineage capture from dbt, Snowflake, BigQuery, or equivalent transformation tools
- Business glossary mapped to physical data assets and accessible via API
L4–L5: autonomous and federated
Permalink to “L4–L5: autonomous and federated”L4 adds policy-aware pipelines, attribute-level access control, and real-time context APIs, enabling agents to operate autonomously without human review of each output. LangGraph-based workflows, RAG pipelines backed by vector databases, and multi-step agent orchestration all require L4 infrastructure to run reliably in production.
L5 extends this to multi-agent orchestration and federated data governance across data mesh domains, so enterprise-scale AI systems can surface context inconsistencies automatically.

Five levels from siloed data to multi-agent federated governance for reliable AI. Source: Atlan.
Infrastructure readiness checklist: 5 dimensions, 25 questions
Permalink to “Infrastructure readiness checklist: 5 dimensions, 25 questions”Answer Yes or No for each question. Count your Yes answers at the end of each dimension and overall. Use the scoring guide below to identify your maturity tier and highest-priority investment areas.
Data pipelines
Permalink to “Data pipelines”- Do your data pipelines deliver updates to the AI layer within 15 minutes of source changes?
- Are pipeline failures automatically detected and routed to on-call teams within 5 minutes?
- Can your pipelines handle a 10x volume increase without architectural changes?
- Are all pipeline dependencies documented and version-controlled?
- Do you have end-to-end observability from source system to AI model input?
Semantic metadata layer
Permalink to “Semantic metadata layer”- Do AI agents have programmatic access to a unified business glossary at inference time?
- Are business metric definitions (revenue, churn, ARR) consistent across all data platforms in your stack?
- Can an AI agent query “what does
recognized_revenue_q4mean in the context of the Q3 board report” and receive a correct, current answer? - Are metadata definitions updated automatically when underlying data models change?
- Is your semantic layer versioned so agents can reason about historical definitions?
Data lineage
Permalink to “Data lineage”- Can you trace any AI output back to its source data within 10 minutes?
- Does lineage coverage extend to real-time and streaming data sources, not just batch pipelines?
- Are transformations in dbt, Apache Spark, or equivalent tools automatically captured in lineage?
- Can agents use lineage to assess data freshness before acting on a dataset?
- Is lineage coverage above 80% of the tables that AI agents actively query?
Access controls and governance
Permalink to “Access controls and governance”- Are data access policies enforced at inference time, not just at query time?
- Can you audit which data an AI agent accessed to produce a specific output?
- Do access controls extend to the semantic layer, not just the data layer?
- Are role-based access controls (RBAC) applied consistently across all data platforms in your stack?
- Can you revoke an agent’s access to a specific dataset without rebuilding the agent?
Real-time context delivery
Permalink to “Real-time context delivery”- Can AI agents retrieve fresh business context (definitions, ownership, lineage) in under 500ms?
- Is context delivery consistent across Snowflake, Databricks, and other platforms in your stack?
- Are context updates propagated to active agent sessions automatically, not requiring a restart?
- Do agents have access to relationship context (table-to-table, metric-to-business-unit) not just field-level definitions?
- Is context personalized by user role, so an analyst agent and an exec agent receive context at the appropriate abstraction level?
Scoring guide
| Score | Infrastructure maturity | Assessment |
|---|---|---|
| 20–25 | L4–L5: AI infrastructure mature | Focus on optimization: multi-agent orchestration and federated metadata governance. |
| 14–19 | L3–L4: Production-capable, scaling gaps | Agents are deployable. Priority: automate remaining manual context assembly and enforce attribute-level access controls. |
| 8–13 | L2–L3: Foundation present, coverage gaps | Agents not production-ready. Semantic metadata layer and automated lineage are required next investments. |
| 0–7 | L1–L2: Infrastructure not AI-ready | Critical gaps exist. Address pipeline governance and metadata architecture before deploying any agent to production. |
A score below 14 indicates your infrastructure has critical gaps before production AI agents can scale reliably. The dimensions with the most No answers are your highest-priority investment areas.
What breaks at each maturity level
Permalink to “What breaks at each maturity level”These failures look like model problems until you trace them. They are not.
What is context drift and why does it break production AI agents?
Permalink to “What is context drift and why does it break production AI agents?”Context drift occurs when semantic definitions stored in the metadata layer fall out of sync with the actual data being queried. Agents operating on stale definitions produce confidently wrong answers. Without data lineage, there is no mechanism to detect the divergence. This is the most common production failure mode for agents at the L2–L3 transition.
The root cause is almost always a static catalog updated manually, with metadata assigned by a data steward when a table is created, then never touched again as the underlying data evolves. The fix is automated metadata synchronization as a first-class infrastructure component, not a governance task that waits for someone to notice something is wrong.
Why do lineage gaps cause trust collapse in AI agent deployments?
Permalink to “Why do lineage gaps cause trust collapse in AI agent deployments?”Regulated industries (financial services, healthcare, insurance) cannot deploy production agents without auditable column-level lineage. When lineage is missing or manually maintained, agents cannot demonstrate data provenance for GDPR data subject access requests, SOC 2 audit trails, or model governance requirements. This is a deployment blocker, not a governance concern.
80% of enterprises have more than 50 GenAI use cases in the pipeline, yet most have only a handful in production (ModelOp, AI Governance Benchmark Report, 2025). Lineage gaps are a primary reason.
How do pipeline failures create stale context for AI agents?
Permalink to “How do pipeline failures create stale context for AI agents?”Agents designed for real-time use cases fail when the pipelines feeding them are batch-only. A customer service agent querying T-1 account status produces errors in live interactions. A fraud detection model working from yesterday’s transaction data misses patterns that developed overnight. Pipeline freshness SLAs need to be defined and monitored before agent use cases are scoped, not after.
McKinsey’s The State of AI 2025 found that fewer than one-third of organizations have begun scaling AI across the enterprise, with governance and infrastructure bottlenecks cited as blockers (McKinsey, 2025). Fragmented pipelines with no unified observability layer are the architectural root cause.
What is access sprawl and how does it break AI agent deployments?
Permalink to “What is access sprawl and how does it break AI agent deployments?”Without attribute-level access control and agent identity management, AI agents querying cross-domain data default to the broadest accessible scope. The result is either a compliance violation (over-access) or an access error that breaks the workflow (under-access). This is permission blindness, one of the six structural failure modes that break production agents. Row-level security designed for BI dashboards does not translate to agent-era workloads. Automated data quality validation at the column level is the foundation that works at inference time.
How Atlan approaches AI infrastructure
Permalink to “How Atlan approaches AI infrastructure”What production scenario shows where AI infrastructure breaks down?
Permalink to “What production scenario shows where AI infrastructure breaks down?”A large enterprise running LangGraph-based agents in production, with BigQuery as its primary data store and a fragmented catalog stack combining IBM Knowledge Catalog with Alation. The data team had AI agents functioning in demo environments and in isolated use cases. Moving to production stalled immediately.
What approaches do teams typically try before implementing a context layer?
Permalink to “What approaches do teams typically try before implementing a context layer?”The team assigned data engineers to assemble context manually for each new agent deployment: writing bespoke pipelines to serve semantic definitions, lineage, and access policies one at a time. Time to deploy each new use case: 6–8 weeks. With a growing backlog, the manual assembly process created a bottleneck that expanded faster than it could be cleared.
The fragmented catalog stack compounded the problem. IBM Knowledge Catalog held governance documentation; Alation held data discovery. Neither served machine-readable context via low-latency API to a LangGraph agent at inference time. Both required UI access and human intermediaries.
How did Atlan’s context layer resolve the deployment bottleneck?
Permalink to “How did Atlan’s context layer resolve the deployment bottleneck?”Atlan’s context layer API served semantic definitions, lineage, and access policies directly to agent frameworks at inference time, eliminating the per-use-case manual assembly step entirely. Rather than building bespoke pipelines for each deployment, the data engineering team connected once to Atlan’s API. Every subsequent agent deployment drew on that connection without additional setup.
Agent deployment time compressed from weeks to days. Atlan customers in similar deployments have reported a 5x increase in data adoption across the organization and a 75-87% POC win rate against alternatives. The active metadata layer, not a new model or a new warehouse, was what made production deployment viable. Atlan’s catalog interface gives data teams both human-facing discovery and a machine-facing context API in a single platform.
FAQs about data infrastructure for AI
Permalink to “FAQs about data infrastructure for AI”What is data infrastructure for AI, and how is it different from traditional data infrastructure?
Permalink to “What is data infrastructure for AI, and how is it different from traditional data infrastructure?”Traditional data infrastructure was designed for human analysts who can reconcile ambiguity. AI infrastructure cannot rely on that. Agents querying cross-domain data need real-time context resolution, semantic consistency across systems, column-level access control, and end-to-end lineage available at query time. These are not incremental improvements to an analytics stack. They require different architectural decisions from the start.
AI agents specifically require four components that analytics workloads often lack: a semantic metadata layer for entity resolution, governed pipelines with freshness SLAs, end-to-end lineage for trust and auditability, and attribute-level access control for cross-domain queries. Real-time context APIs that serve this metadata at inference time, rather than through batch catalog updates, tie all four together.
Why do most AI projects stall at the infrastructure layer?
Permalink to “Why do most AI projects stall at the infrastructure layer?”Most AI projects launch with models that are ready before the infrastructure underneath them is. Deployed on inconsistent metadata, manual lineage, or batch pipelines, agents produce wrong answers or require human intervention per use case, erasing the automation value. The infrastructure gap, not the model, is the production blocker. 56% of enterprises report it takes 6-18 months to move a GenAI project from intake to production, with governance and infrastructure bottlenecks, not model readiness, as the primary cause (ModelOp AI Governance Benchmark Report, 2025).
What is the difference between a data catalog and a context layer?
Permalink to “What is the difference between a data catalog and a context layer?”A data catalog is a human-facing interface for data discovery and documentation. The context layer is a machine-facing API infrastructure that resolves semantic definitions, lineage, and access policies at agent inference time. A catalog may be one component that feeds a context layer, but they are not the same thing. IBM Knowledge Catalog and Alation are catalogs; Atlan provides both a catalog interface and a context layer API.
How long does it take to build AI-ready data infrastructure?
Permalink to “How long does it take to build AI-ready data infrastructure?”Timeline depends on current maturity. Organizations at L1 (ad hoc pipelines, no catalog) typically require 18–24 months to reach L3 (production-agent-ready). Organizations at L2 with a centralized warehouse and basic catalog can reach L3 in 6–9 months by implementing a semantic metadata layer and automating lineage. The 25-question readiness assessment maps each investment step across pipeline readiness, semantic layer, lineage, access controls, and real-time delivery.
How do access controls need to change for AI agent workloads?
Permalink to “How do access controls need to change for AI agent workloads?”BI-era access controls operate at the dataset or table level. AI agents querying cross-domain data (pulling from finance, HR, and operations in a single workflow) need column-level or attribute-level policies enforced at inference time. AI agent identities (service accounts, agent IDs) must be explicitly included in the access control model, with audit logs capturing what each agent accessed and when.
From infrastructure gap to agent-ready production
Permalink to “From infrastructure gap to agent-ready production”The AI projects that reach production are not the ones with the most sophisticated models. They run on infrastructure that agents can actually trust: metadata that stays current, lineage that is complete, semantic definitions that are consistent, and governance controls that reach the inference layer. That infrastructure exists, in pieces, at almost every large enterprise. The work is assembling it.
