



















LangGraph memory vs Mem0: Overview
Permalink to “LangGraph memory vs Mem0: Overview”LangGraph memory and Mem0 solve the same problem (cross-session recall) through opposite architectural philosophies. LangGraph’s memory is native and coupled: LangMem integrates directly into the LangGraph runtime, requires no external API calls, and gives you procedural memory at the cost of a 59.82s p95 latency. Mem0 is portable and managed: a REST service that works with any agent framework, with sub-second latency, automatic LLM-based extraction, and managed infrastructure.
The practical decision for most LangGraph engineers:
- If you are already using LangGraph and do not want to add an external service, LangMem is the default choice.
- If you are building interactive agents where memory retrieval is on the critical path, Mem0’s 300x latency advantage is the deciding factor.
- If you need the same memory layer to work across LangGraph, CrewAI, and OpenAI SDK, only Mem0 offers that portability.
| Dimension | LangGraph checkpointer | LangMem | Mem0 |
|---|---|---|---|
| Memory scope | In-thread (thread_id only) |
Cross-session (user_id namespaced) |
Cross-session (user_id) |
| p95 latency | Synchronous graph state | ~59.82 seconds | ~0.200 seconds |
| Token reduction | None (full conversation state) | Extraction-based (varies) | ~72% vs full-context per query |
| Portability | LangGraph only | LangGraph ecosystem | Any framework via REST API |
| Managed hosting | No (self-managed) | No (bring your own PostgresStore) | Yes (managed cloud) |
| Cost | Free (infra only) | Free (infra only) | Free tier to $249/mo |
| GitHub stars | ~100K (LangGraph repo) | ~1,500 | ~56,000+ |
For a broader view of where LangMem and Mem0 rank among all agent memory tools, see best AI agent memory frameworks 2026.
Build Your AI Context Stack
Get the blueprint for implementing context graphs across your enterprise. This guide walks through the four-layer architecture — from metadata foundation to agent orchestration — with practical implementation steps for 2026.
Get the Stack GuideLangGraph memory vs Mem0: What is the difference?
Permalink to “LangGraph memory vs Mem0: What is the difference?”LangGraph’s stateful orchestration couples memory tightly to the LangGraph runtime; Mem0 is a standalone REST service any framework can call. The practical difference: LangMem is free and native; Mem0 adds sub-second latency at the cost of an external dependency.
The thread_id vs user_id distinction
Permalink to “The thread_id vs user_id distinction”The most common confusion is that MemorySaver appears to “persist” data. It does, but only within a single thread_id. This is why AI agents forget between sessions: the fix is adding LangMem (via a store) or Mem0 (via REST API) as a cross-session layer.
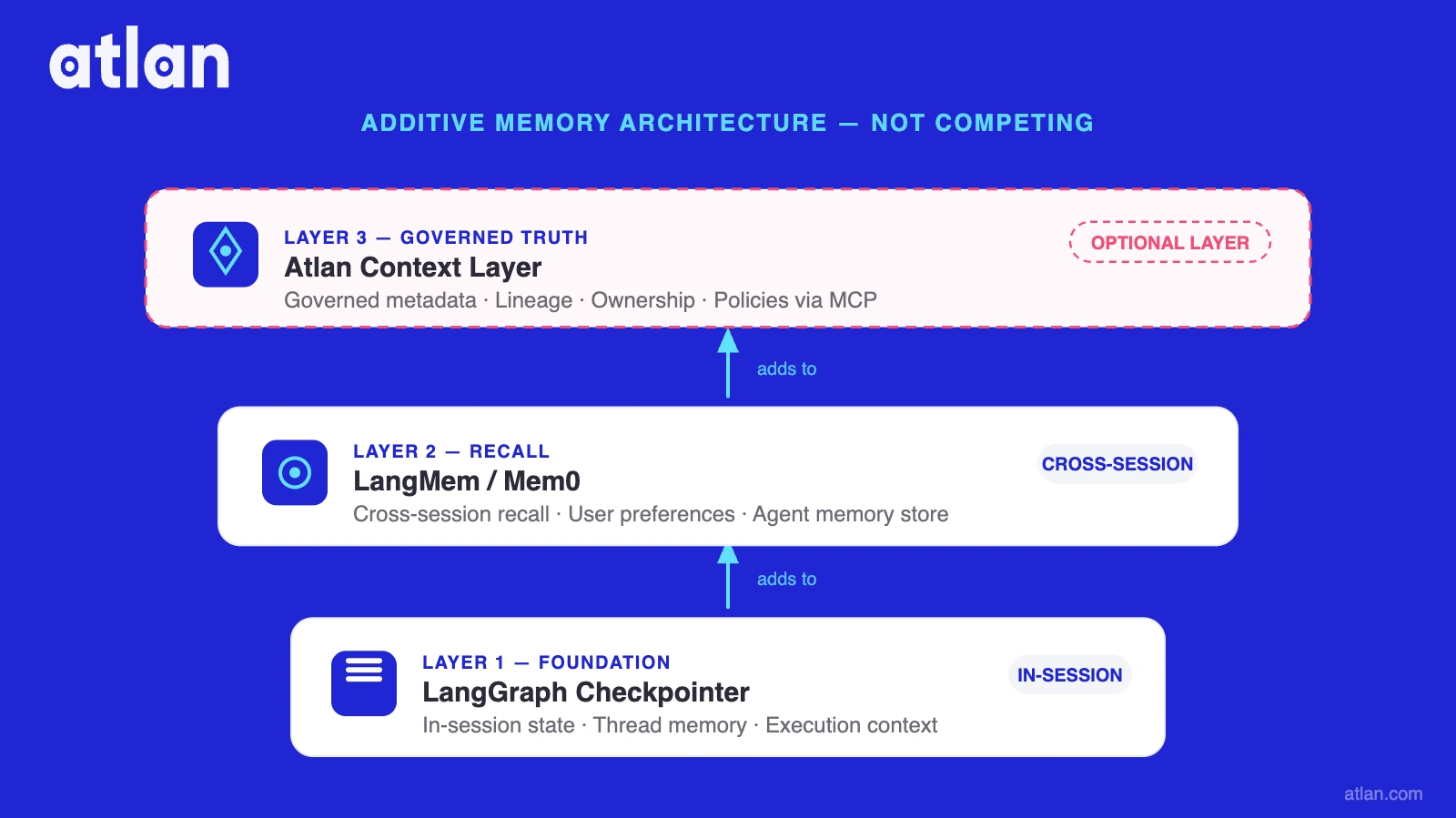
Three architectural tiers, not two
Permalink to “Three architectural tiers, not two”This comparison is actually three layers with distinct responsibilities: the LangGraph checkpointer (in-thread state, time-travel, conversation replay); LangMem or Mem0 (cross-session user memory via user_id); and the Atlan context layer (enterprise truth: certified definitions, lineage, ownership, policy enforcement). For agent memory taxonomy and LangChain vs LangGraph architecture, see the dedicated guides. For a survey of agent memory architectures and the tradeoffs between each approach, see the architectural overview.
What is LangGraph memory? (checkpointer + LangMem)
Permalink to “What is LangGraph memory? (checkpointer + LangMem)”LangGraph ships with two memory primitives: the checkpointer (MemorySaver for development, PostgresSaver for production) for in-thread conversation state scoped to a thread_id, and LangMem for cross-session long-term memory via a user_id-namespaced store. LangMem supports three memory types: semantic (user facts), episodic (interaction summaries), and procedural (agent’s own system instructions).
LangGraph checkpointer (MemorySaver vs PostgresSaver)
Permalink to “LangGraph checkpointer (MemorySaver vs PostgresSaver)”The checkpointer persists the full conversation state within a thread_id. MemorySaver is an in-process Python dict for development only; PostgresSaver is required for production. A new thread_id has zero access to any prior thread’s state. Use cases best suited to the checkpointer alone: time-travel debugging, conversation replay, and branching agent workflows where cross-session user memory is not required. For patterns on building long-term memory for LangChain agents, see the dedicated guide.
LangMem: episodic, semantic, and procedural memory types
Permalink to “LangMem: episodic, semantic, and procedural memory types”LangMem extends the LangGraph store interface with three memory types: semantic (facts and user preferences), episodic (past interaction summaries), and procedural (the agent’s own system instructions, which the agent can rewrite based on feedback, LangMem’s unique differentiator). Tools are create_manage_memory_tool and create_search_memory_tool, scoped via ("memories", "{user_id}") namespace. Production requires PostgresStore; InMemoryStore resets on restart. For semantic memory vs procedural memory in AI agents, see the detailed comparison.
Latency callout: LangMem’s p95 search latency is 59.82 seconds (arXiv:2504.19413). This is not a typo. For background memory consolidation: suitable. For interactive agents where users wait for a response: not viable. The LOCOMO J score for LangMem is approximately 58.10% versus Mem0’s 67.13% on the same benchmark.
LangMem has approximately 1,500 GitHub stars (langchain-ai/langmem), is fully open-source (MIT license), and is maintained by the official LangChain team.
What is Mem0?
Permalink to “What is Mem0?”Mem0 is a standalone managed memory service for agentic AI systems: a REST API any framework can call to store and retrieve user facts across sessions. It combines vector search, graph memory (Neo4j or Kuzu), and key-value storage, automatically extracting structured facts from conversation history via LLM pipeline, reducing per-query token usage by ~72% at 0.200s p95 latency (arXiv:2504.19413). For comparisons, see Mem0 alternatives and Mem0 vs Zep.
Core components of Mem0
Permalink to “Core components of Mem0”Mem0’s internal architecture combines four storage and retrieval mechanisms:
- Memory extraction pipeline: LLM-based extraction of structured facts from raw conversation turns. Compresses approximately 26,000 tokens of conversation history by over 90% in memory footprint (arXiv:2504.19413).
- Vector store: Embedding-based semantic search over extracted facts. Powers relevance-ranked retrieval. This is conceptually different from retrieval-augmented generation — where RAG retrieves documents at query time, Mem0 retrieves compressed user-specific facts extracted from prior sessions.
- Graph store (optional): Entity relationships via Neo4j or Kuzu. Enabling graph memory boosts the LOCOMO J score from 67.13% to 68.44%.
- Key-value store: Structured metadata for fast exact-match lookups.
- REST API + SDKs: Python and Node.js; framework-agnostic. Works with LangGraph, CrewAI, OpenAI SDK, Flowise, or any agent stack.
- Managed cloud: No infrastructure to provision; SOC 2 Type I certified (Type II audit in progress); HIPAA BAA available at Enterprise tier.
For context on the distinction between memory vs vector database in agent architectures, see the dedicated comparison. For patterns that combine memory retrieval with advanced RAG techniques for richer context injection, see the RAG guide.
| Metric | Value | Source |
|---|---|---|
| LOCOMO J score | 67.13% (base) / 68.44% (with graph) | arXiv:2504.19413 |
| p95 latency | 0.200s | Mem0 research |
| Token reduction (per-query) | ~72% vs full-context | arXiv:2504.19413 |
| GitHub stars | 56,000+ | GitHub |
| Funding | $24M Series A (October 2025) | Multiple sources |
| Free tier | 10,000 memories + 1,000 retrievals/month | mem0.ai/pricing |
Mem0 is the default choice when multi-framework portability, production-safe latency, managed infrastructure, or enterprise compliance (SOC 2, HIPAA BAA) are requirements.
LangGraph memory vs Mem0: The same task in three ways
Permalink to “LangGraph memory vs Mem0: The same task in three ways”The clearest way to understand the difference is to implement the same task (a conversational agent that remembers user preferences across sessions) using all three approaches. All three use LangGraph; the difference is where memory lives. For background on how LLM memory extraction works, see the dedicated guide.
Option 1: LangGraph checkpointer (MemorySaver / PostgresSaver)
Use when: in-session memory only; no need for cross-session recall; debugging with time-travel.
## Source: docs.langchain.com/oss/python/langgraph/persistence
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import StateGraph, MessagesState
memory = MemorySaver() # Development only — resets on restart
# For production:
# from langgraph.checkpoint.postgres import PostgresSaver
# memory = PostgresSaver.from_conn_string("postgresql://...")
def call_model(state: MessagesState):
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini")
response = llm.invoke(state["messages"])
return {"messages": response}
builder = StateGraph(MessagesState)
builder.add_node("call_model", call_model)
builder.set_entry_point("call_model")
builder.set_finish_point("call_model")
graph = builder.compile(checkpointer=memory)
config = {"configurable": {"thread_id": "user-alice-session-1"}}
result = graph.invoke({"messages": [{"role": "user", "content": "I prefer dark mode"}]}, config)
# ✅ Same thread_id = remembers within session
# ❌ New thread_id → all memory is gone
Option 2: LangMem cross-session memory
Use when: LangGraph-native stack; cross-session recall; procedural memory needed; budget-constrained.
# Source: langchain-ai.github.io/langmem/
# pip install -U langmem langchain langgraph langchain-openai
from langgraph.prebuilt import create_react_agent
from langgraph.store.memory import InMemoryStore # Dev only
from langmem import create_manage_memory_tool, create_search_memory_tool
store = InMemoryStore(
index={"dims": 1536, "embed": "openai:text-embedding-3-small"}
)
# Production: PostgresStore.from_conn_string("postgresql://...")
manage_memory = create_manage_memory_tool(
namespace=("memories", "{user_id}"),
instructions="Store stable user facts and preferences.",
)
search_memory = create_search_memory_tool(
namespace=("memories", "{user_id}"),
instructions="Search memory first when questions depend on prior info.",
)
agent = create_react_agent(
model="gpt-4o-mini",
tools=[manage_memory, search_memory],
store=store,
)
config = {"configurable": {"user_id": "alice", "thread_id": "session-1"}}
result = agent.invoke(
{"messages": [{"role": "user", "content": "I prefer dark mode"}]},
config=config,
)
# New thread, same user_id → ✅ memory persists across sessions
# ⚠️ p95 latency ~59.82s — not suitable for interactive agents
Option 3: Mem0 managed memory with LangGraph
Use when: interactive agents; multi-framework portability; managed infrastructure.
# Source: digitalocean.com/community/tutorials/langgraph-mem0-integration-long-term-ai-memory
# pip install langgraph langchain-openai mem0ai
from typing import Annotated, TypedDict, List
from langgraph.graph import StateGraph, START
from langgraph.graph.message import add_messages
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
from mem0 import MemoryClient
class State(TypedDict):
messages: Annotated[List[HumanMessage | AIMessage], add_messages]
mem0_user_id: str
llm = ChatOpenAI(model="gpt-4o")
mem0 = MemoryClient() # Requires MEM0_API_KEY env var
def chatbot(state: State):
messages = state["messages"]
user_id = state["mem0_user_id"]
try:
memories = mem0.search(messages[-1].content, filters={"user_id": user_id}, version="v2")
context = "Relevant memories:\n" + "\n".join(
f"- {m['memory']}" for m in memories.get('results', [])
)
system_message = SystemMessage(content=f"You are helpful.\n{context}")
response = llm.invoke([system_message] + messages)
mem0.add([
{"role": "user", "content": messages[-1].content},
{"role": "assistant", "content": response.content},
], filters={"user_id": user_id})
return {"messages": [response]}
except Exception:
# Graceful degradation — agent continues without memory
return {"messages": [llm.invoke(messages)]}
graph = StateGraph(State)
graph.add_node("chatbot", chatbot)
graph.add_edge(START, "chatbot")
compiled = graph.compile()
# ✅ 0.200s p95 — production-safe for interactive agents
Note the mandatory try/except in Option 3: if Mem0 is unavailable, the agent degrades gracefully. This pattern is absent from most integration tutorials and is the most common production failure on first deployment.
Inside Atlan AI Labs and The 5x Accuracy Factor
Learn how context engineering drove 5x AI accuracy in real customer systems. Explore real experiments, quantifiable results, and a repeatable playbook for closing the gap between AI demos and production-ready systems.
Download E-BookLangGraph memory vs Mem0: Head-to-head
Permalink to “LangGraph memory vs Mem0: Head-to-head”LangMem leads on LangGraph integration depth and is the only tool with procedural memory. Mem0 leads on latency (0.200s vs 59.82s), portability, and community scale (56,000+ stars vs 1,500). Atlan’s context layer operates in a different category, not recall, but governed enterprise truth via MCP. For AI memory system architecture, see the dedicated guide. For teams assessing AI agent risks and guardrails around memory — particularly when agents may recall outdated or unvalidated data — see the guardrails guide.
| Dimension | LangGraph checkpointer | LangMem | Mem0 | Atlan context layer |
|---|---|---|---|---|
| Memory scope | In-thread (thread_id only) |
Cross-session (user_id) |
Cross-session (user_id) |
Enterprise-wide (all agents, all sessions) |
| Memory types | Conversation history snapshot | Semantic + Episodic + Procedural | Semantic + Episodic + Graph | Governed metadata: definitions, lineage, ownership, policy |
| p95 latency | Synchronous | ~59.82s | ~0.200s | Sub-second (read-only) |
| Token reduction | None | Extraction-based (varies) | ~72% vs full-context | N/A (context injection) |
| Portability | LangGraph only | LangGraph ecosystem | Any framework (REST API) | Any agent via MCP |
| Procedural memory | No | Yes | No | No (but governs valid instructions) |
| Enterprise governance | No | No | SOC 2 Type I | Yes: certified definitions, sensitivity labels, access control |
| Data lineage | No | No | No | Yes: column-level lineage traversal |
| Managed hosting | No | No | Yes | Yes (Atlan platform) |
| Cost | Free (infra) | Free (infra) | Free to $249/mo | Atlan platform pricing |
Real-world scenario: the same question, four different answers
Permalink to “Real-world scenario: the same question, four different answers”An enterprise agent is asked: “What was our quarterly revenue last quarter?”
- Checkpointer only: Recalls the conversation turn where the user mentioned revenue, but only if this is the same thread. New session: asks from scratch.
- LangMem: Recalls that “the user works in finance and prefers numbers in millions” from prior sessions. Generates an answer based on whatever the LLM produces. No validation of whether the revenue figure is certified or which table it sources from.
- Mem0: Same recall capability as LangMem, faster for interactive use. Still no validation of whether “revenue” is the certified metric definition.
- Atlan context layer: Identifies the certified “Quarterly Revenue” metric in the business glossary, retrieves its lineage (which table, which transformation), and confirms whether the underlying data is fresh before the LLM generates the answer.
“Choose LangMem if you’re on LangGraph and don’t want external dependencies. Choose Mem0 if you need portability or production-safe latency. Add Atlan’s context layer if agents need to be right, not just remembered.”
For context on enterprise memory requirements and why these requirements differ from consumer-grade agent memory, see the dedicated analysis. For practical guidance on implementing this in production, see how to implement long-term memory for AI agents and scaling AI agents in production.
How do you migrate between memory approaches?
Permalink to “How do you migrate between memory approaches?”Most LangGraph teams start with MemorySaver, hit the cross-session wall, and choose between LangMem (native, free, slower) and Mem0 (external, managed, faster). In all three paths below, the LangGraph checkpointer stays in place; only the long-term memory layer changes. For related patterns, see cross-session memory for LangChain agents and memory ingestion patterns.
Checkpointer to LangMem
Permalink to “Checkpointer to LangMem”When to migrate: users lose preferences when sessions change; staying in the LangGraph ecosystem; no external dependency budget.
Keep the existing checkpointer, add a PostgresStore alongside it, and attach create_manage_memory_tool and create_search_memory_tool to the agent’s tool list. Migrate any user preference data from PostgresSaver snapshots to the new store if applicable.
Critical gotcha: MemorySaver resets on process restart. If used in production, there is no data to migrate. Production agents require PostgresSaver before this migration matters.
Checkpointer to Mem0
Permalink to “Checkpointer to Mem0”When to migrate: need cross-session memory with managed infrastructure and sub-second latency; willing to add an external service.
Install mem0ai, add mem0_user_id to your LangGraph state TypedDict, call mem0.search() before each LLM invocation and mem0.add() after the response. The checkpointer and Mem0 coexist without conflict.
Critical gotcha: Wrap all Mem0 calls in try/except. If the Mem0 service is unavailable, the agent must degrade gracefully. Option 3 in the code section above shows the correct pattern.
LangMem to Mem0
Permalink to “LangMem to Mem0”When to migrate: LangMem’s 59.82s p95 latency is breaking UX for interactive agents.
Extract stored memories via store.search(namespace=("memories", user_id)), bulk-import into Mem0 via mem0.add(memories, user_id=user_id), then replace the LangMem tools with the Mem0 search-and-add pattern in your agent node. The LangGraph checkpointer is unaffected.
Critical gotcha: Verify user_id namespace mapping matches across both systems before bulk import.
| Migration | Gotcha | Fix |
|---|---|---|
| Checkpointer to LangMem | MemorySaver has no data after restart |
Switch to PostgresSaver before migrating |
| Checkpointer to Mem0 | No graceful degradation by default | Wrap all Mem0 calls in try/except |
| LangMem to Mem0 | user_id namespace mapping may differ |
Verify user_id matches across both systems before bulk import |
| Any to Mem0 | Free tier: 1,000 retrievals/month cap | Plan upgrade to Starter ($19/mo) at 1,000+ calls/month |
When neither is enough: Atlan as the enterprise-scale third option
Permalink to “When neither is enough: Atlan as the enterprise-scale third option”LangMem and Mem0 solve the recall problem (agents that remember what users said before). They do not solve the accuracy problem (agents that know whether what they are saying is correct). The distinction between memory layer vs context layer — recall versus governed accuracy — is the central architectural decision for enterprise teams.
Atlan’s context layer is a third architectural tier that neither LangMem nor Mem0 occupies. It exposes governed enterprise metadata (certified metric definitions, entity resolution across systems, column-level lineage, and policy enforcement) to AI agents via a standardized MCP server. One MCP interface connects any agent (LangGraph, Claude, Cursor, Gemini) to authoritative data truth. For background on Atlan’s context layer and the broader context layer for AI agents, see the dedicated guides.
The recall-vs-truth gap
Permalink to “The recall-vs-truth gap”LangMem and Mem0 solve recall: user preferences, past interaction summaries, procedural rules. Neither can answer whether “quarterly revenue” is the certified metric or a draft, whether “customer” in the CRM matches “account” in the warehouse, whether the underlying table is fresh, or whether the agent has permission to surface the data. Those require governed metadata, a business glossary, entity resolution, active lineage, and access policy enforcement. This is where AI agent governance and data quality for AI agent harnesses become essential — without them, recall accuracy is meaningless.
Atlan’s MCP server: the USB-C port for enterprise context
Permalink to “Atlan’s MCP server: the USB-C port for enterprise context”Atlan’s MCP server is the standardized socket any agent plugs into to access governed enterprise context. The way USB-C is a standardized connector that works across device manufacturers, Model Context Protocol is a standardized protocol that connects AI models to tools and data sources regardless of vendor. Atlan’s MCP server is that standard socket: one interface, any agent framework.
Four tools exposed via Atlan’s MCP server:
search_assets: locate data assets by name, type, tags, or domain.get_assets_by_dsl: retrieve assets via Atlan’s DSL query language.traverse_lineage: explore upstream and downstream data lineage at the column level.update_assets: write back descriptions, certification status, and readme fields.
The additive architecture
Permalink to “The additive architecture”Atlan is not a replacement for LangMem or Mem0. The recommended production architecture is:
LangGraph agent
├── Checkpointer → in-thread conversation state
├── LangMem / Mem0 → cross-session user facts
└── Atlan MCP → enterprise truth: definitions, lineage, policy
Adding Atlan’s MCP server alongside a memory layer lets agents call search_assets to retrieve certified metric definitions and traverse_lineage to confirm underlying table provenance before generating an answer. Internal research from Atlan AI Labs shows a 20% accuracy improvement and 39% reduction in tool calls versus memory-only approaches. The difference is not recall quality; it is access to ground truth. For teams scaling this pattern, AI agent observability is essential for tracking memory retrieval quality and context injection accuracy in production.
Which memory approach should you use? The conviction
Permalink to “Which memory approach should you use? The conviction”LangMem is the right default for LangGraph teams who want zero external dependencies, need procedural memory, and are not building real-time interactive agents. Mem0 is the right choice when latency matters, portability across frameworks is required, or managed infrastructure is preferred. The 300x p95 latency gap is the primary architectural decision for consumer-facing agents.
The most common failure mode in enterprise AI is not poor recall. It is producing confident answers from uncertified sources. An agent that perfectly remembers user preferences but returns the wrong revenue figure because it cannot distinguish a certified metric from a draft has the recall problem solved and the accuracy problem untouched. This is an AI agent hallucination problem at the data layer — one that memory tools alone cannot fix. The third tier (Atlan’s MCP server) operates at a different layer: governed definitions, column-level lineage, and shared corrections that propagate across all agents the moment they are made. Decision sequence: (1) does your agent need cross-session recall? Choose LangMem or Mem0. (2) Does it need to answer questions about enterprise data correctly? Add Atlan. Most enterprise teams eventually discover they need both.
“Memory tools make agents remember. Atlan’s context layer makes them right. Recall and truth are not the same thing — and in enterprise AI, the difference costs you.”
Frequently asked questions about LangGraph memory vs Mem0
Permalink to “Frequently asked questions about LangGraph memory vs Mem0”1. What is the difference between LangGraph memory and Mem0?
Permalink to “1. What is the difference between LangGraph memory and Mem0?”LangGraph memory uses the checkpointer (in-thread state scoped to thread_id) and LangMem (cross-session store scoped to user_id). Both require LangGraph. Mem0 is a standalone managed service with a REST API that works with LangGraph, CrewAI, OpenAI SDK, or any agent framework. The core difference: native-coupled versus portable-managed, with a 300x p95 latency gap that drives most production decisions.
2. Should I use LangMem or Mem0 for my LangGraph agent?
Permalink to “2. Should I use LangMem or Mem0 for my LangGraph agent?”Use LangMem if you want zero external dependencies and are comfortable managing your own PostgresStore. Use Mem0 if you need production-safe latency (0.200s p95 versus LangMem’s 59.82s) or plan to run the same memory layer across multiple agent frameworks. Budget-wise: LangMem is free; Mem0 starts free (10,000 memories/month) and scales to $19/month for most production workloads.
3. What is LangMem in LangGraph?
Permalink to “3. What is LangMem in LangGraph?”LangMem is LangChain’s official open-source SDK for long-term agent memory, built for the LangGraph ecosystem. It provides semantic memory (user facts), episodic memory (interaction summaries), and procedural memory (agents rewriting their own system instructions). It requires a LangGraph store backend and has a p95 search latency of approximately 59.82 seconds, suitable for background processing but not for interactive agents.
4. Does Mem0 reduce token usage?
Permalink to “4. Does Mem0 reduce token usage?”Yes, significantly. Per arXiv:2504.19413, Mem0 compresses approximately 26,000 tokens of conversation history by over 90% in memory footprint. At retrieval time, average per-query token usage is approximately 6,956 versus 25,000+ for full-context methods, roughly a 72% reduction per query.
Sources
Permalink to “Sources”- Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory, Mem0 Research Team
- LangMem SDK official documentation, LangChain team
- LangGraph persistence and checkpointing documentation, LangChain team
- Pricing and tier details, Mem0
- Research and benchmarks, Mem0
- Building Long-Term Memory in AI Agents with LangGraph and Mem0, DigitalOcean
- Getting Started with the LangMem SDK for Agent Long-Term Memory, DigitalOcean
- Official LangGraph integration guide, Mem0
- LangMem SDK Launch, LangChain team
- Agent Memory at Scale 2026: Letta, Zep, Mem0, and LangMem Compared, AgentMarketCap
