



















In 2024, every vendor shipped an AI analyst. In 2025, every platform added a copilot. And by 2026, all of that became table stakes.
The real question is no longer “can your AI chat with data?”. It’s “does your AI actually understand your business – and who controls the layer that makes that possible?”
At The Great Data Debate, we brought together Bob Muglia, formerly of Snowflake, Jaya Gupta of Foundation Capital, Tony Gentilcore of Glean, Karthik Ravindran of Microsoft, and Prukalpa Sankar of Atlan. Then we lit the match and backed away while they debated the most pressing questions about AI context:
Where should context for AI live? Who owns it? Where is the center of gravity? And critically, how should context layers be built?
The answers split every which way. The takes were hot. But by the end, one consensus emerged: Context is a team sport that organizations need to wrangle in order to succeed with AI.
Why context became the bottleneck
Permalink to “Why context became the bottleneck”Two years ago, the question was “can AI understand natural language?” Today, it’s “does AI understand my business?”
Prukalpa opened the debate by framing the shift: “With AI, context might be everything. The intelligence is already here. The challenge is that the intelligence is very unevenly distributed right now.”
The gap, she argued, is teaching a “super smart alien” the context of your world. And that context is complicated. It exists in three layers:
- Data: The structured foundation
- Knowledge: SOPs, tribal knowledge, real-life decisions
- Meaning: Situational interpretation that changes by role and intent
Take a seemingly simple question like “Who are our top 10 customers?” If Sales asks, it’s based on revenue. If Customer Success asks, it’s based on adoption. If Marketing asks for customers to feature on the homepage, that’s an entirely different set. Even that basic query requires layers of context that don’t exist in your data warehouse.
Jaya Gupta sharpened the point: “As the models get smarter, generic reasoning is not really the bottleneck anymore. Now the question is shifting to whether an AI system can really act correctly inside a specific organization. And that depends far less on how much data it can query and far more on whether it understands that institutional memory.”
The competitive advantage, she said, is shifting from having the best model or the best data to accumulating decision history – the decision traces that explain why choices were made, not just what happened.
Context isn’t data – and it’s not just metadata either
Permalink to “Context isn’t data – and it’s not just metadata either”Context is nothing new in the data world. But its role and how it’s stored is changing – fast.
“Context has always existed in one form or another in business,” explained Bob Muglia. “For decades, it existed primarily in people’s heads.”
Over time, business rules moved into SaaS applications. Semantic layers emerged. Dimensional BI models encoded logic. Humans, Bob noted, are “terrible at documenting this stuff.” Agents, on the other hand, excel at it.
When a customer gets a 20% discount instead of the standard 10%, that exception – and the reason for it – can now be captured, codified, and reused as context for AI. Still, Tony Gentilcore made a crucial distinction about context complexity: “We can’t paint all contexts with one brush. There’s different levels of context.”
Some context is simple – documented procedures you can look up. But piecing together context from multiple sources is a different story. And that’s where AI struggles.
“You’re reconstructing that tribal knowledge,” Tony said. “You’re getting that Slack thread that had the decision, and you’re piecing together that with the accounts and maybe what happened after that.”
This is context engineering’s core challenge: synthesizing information across structured and unstructured sources to give AI the most useful context – the “CliffsNotes,” not the whole Bible.
The core context dilemma: Who owns it?
Permalink to “The core context dilemma: Who owns it?”The panelists generally agreed on the importance and changing role of context. But that agreement came to an end when asked about who ultimately owns the context layer for AI, as four visions emerged:
System of record: Context lives at the source
Permalink to “System of record: Context lives at the source”Bob argued that context lives where transactional data originates – in hyperscalers, SaaS apps, CRMs, and ERPs.
“Every part of a business needs to have a system of record so they can track what’s happening,” he argued. “Context will emit from those places. It will be a distributed and federated world.”
But Jaya pushed back hard on this vision. Systems of record, she argued, are “optimized for current state, but they don’t know what things looked like when decisions were made.” By the time data flows downstream to warehouses, decision context is already gone.
“It’s really hard for a single incumbent to reconstruct the full decision context” when real decisions span CRM, billing, incident tools, Slack, and more, she said. This perpetuates silos that work against decision-making.
System of data: The warehouse as context repository
Permalink to “System of data: The warehouse as context repository”Bob also made the case for data platforms as the centralized repository, saying: “There needs to be a centralized repository where overall business decisions can get made, and the place where that has been established is the data lake.”
He called for an open context interchange (similar to the Open Semantic Interchange), which would create a SQL-like standard for data, but for context. Just as SQL standardized how we query data across different platforms, the context interchange would provide a shared, vendor‑neutral standard to exchange business context (semantics, rules, exceptions) across warehouses, apps, and agents.
System of agency: AI agents as context creators
Permalink to “System of agency: AI agents as context creators”Jaya offered a provocative alternative to centralized repositories: agents as context creators.
AI agents, she argued, have a structural advantage: “They’re in the execution path. Every time that Sales agent handles some objection and the human is interacting with that agent, that reasoning is getting captured.”
Agents accumulate institutional intelligence that becomes a competitive moat over time. “This is kind of why the agents have such an advantage,” Jaya continued. “They’re accumulating that context that makes them valuable over time.”
Prukalpa pushed back, asserting that while agents can capture context at the moment of decision, enterprises need that context to be durable, governed, and shared across all systems – not locked inside individual agents. That laid the groundwork for her position: the independent context layer.
Independent context layer: The platform play
Permalink to “Independent context layer: The platform play”Prukalpa made the case for a universal, customer-owned context layer. Looking to the future, she said, an independent, platform-agnostic context layer is the only way to ensure that domain-based agents don’t operate in silos that confuse the business and harm decision-making.
“My Sales agent has context. My Customer Success agent has something else,” she explained. “These things are not talking to each other. I have agent sprawl. I have context sprawl.”
If we want to learn from the mistakes of our past, we can’t repeat the data silo problem – but this time, with context.
Top-down governance, bottom-up architecture
Permalink to “Top-down governance, bottom-up architecture”On implementation, surprising consensus emerged.
For Tony, implementation should be “top-down organizationally, architecturally bottom-up.” His argument: Enterprises need centralized governance – data egress controls, permissions, cost management, auditing – to avoid “lobster bot” security incidents.
But technically, you need to “connect to absolutely everything” at the foundation, layer governance above, build knowledge graphs and retrieval systems on top of that, and finally “expose it safely to any assistant, agent, application.”
Karthik focused on the execution angle, calling context management a “federated team sport” driven by people and AI systems, and a strong change management strategy. Atlan’s own research backs this up. In conversations with dozens of companies, we found that many struggle with the human side of AI implementation – the alignment, context collection, and change management that needs to happen to make adoption real.
As for the tribal knowledge locked in people’s heads? “That’s a differentiator,” Karthik asserts. “All of that stuff is not lost. It needs to be carried forward and then augmented and scaled together with the opportunities that AI provides.”
Still, it all goes nowhere if context can’t be put into practice. Prukalpa challenged the group on that front, saying: “How do you tie this into the productionization lifecycle of AI but do it in a way that we don’t repeat the mistakes we made with data over the last 20 years?”
Her answer: bootstrap from existing business systems – SAP, Salesforce, and BI tools provide structured foundation – then integrate context engineering into workflows, build evaluation frameworks for trust, and create memory feedback loops that capture AI actions as institutional memory.
The key? “Get something 80% of the way so that the flywheel kicks in.” Don’t wait three years to figure out how to use your context layer while the world moves on.
Context engineering: The new data engineering
Permalink to “Context engineering: The new data engineering”What does all this mean for data engineering as we know it?
“The future of data engineering might be thought of as context engineering,” Bob declared. “This is the year where data engineering will start becoming agentic. Agents will do transformations.”
But Karthik cautioned against framing it too narrowly: “Context engineering is too narrow. It doesn’t capture the whole business. You need to enable business domain experts. The human plus AI loop is wider than just engineers.”
To widen the scope, Prukalpa broke the shift down to three phases:
- AI-assisted: Humans do the work using AI
- AI-augmented: AI does most of the work, asking humans for help
- Autonomous: AI does the work independently
But we’re still in the early stages. “We’re just starting to move from 1 to 2,” she noted. Still, at Atlan, she revealed engineers no longer coding – they’re tasked with teaching AI how to code instead.
Tony brought it full circle: “Knowledge management feels like a dated concept, but it’s all the rage again. You need the context engineering to do the data engineering. That loop can be much more virtuous. AI can accelerate it down to knowledge management.”
The hot take roundup
Permalink to “The hot take roundup”We closed the debate with a rapid-fire round of closing arguments. Here’s what our panelists had to say:
Tony: “The trillion-dollar question is not which model. If my model only knew what my company knows, we’d be 100 times as productive.”
Jaya: “Context graphs are your institutional memory, and you need them to win in AI. The question is whether you will own it or your vendors will own you through it.”
Karthik: “Context is way more than technology or a data structure. It is a practice. Being very intentional about the practice, focusing on the outcome of creating shared meaning for your data to be used by AI and people alike.”
Bob: “Models are not magic. In order for them to make the right decision, they need to understand your business. Fortunately, agents will be what defines that context, because people aren’t good at it.”
Prukalpa: “In a world where everyone has access to the same intelligence, what differentiates one company from another? It’s about who you are as a company. It’s about how you do business. That’s context. In this new world, context will be the IP for companies. Intelligence won’t.”
The debate retrospective: What changed?
Permalink to “The debate retrospective: What changed?”The audience poll told the story. At the start of the debate, opinions were divided across all four ownership models. By the end, preference for an independent context layer had grown by 11% – not because any single panelist won the argument, but because the debate itself revealed that context is too strategic to cede to any single vendor.
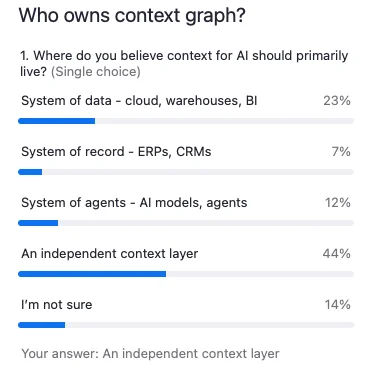
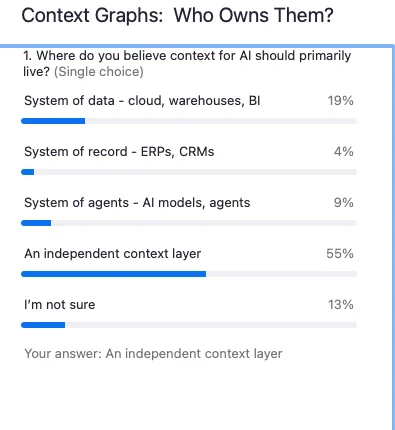
This is just the beginning of the context debate. The question isn’t whether context layers will emerge – it’s who will control them, how they’ll be built, and whether enterprises will own their institutional intelligence or rent it from their vendors.
Want to hear the full debate? Watch the recording to catch all the spicy takes, technical deep-dives, and moments where the panelists definitely didn’t agree.
Ready to see these concepts in action? Save your seat for Atlan Activate to learn from data leaders building the foundations that make AI analysts actually work in production.
The question of who owns AI context has a practical answer — see the implementation resources and governance guidance at the Enterprise Context Layer Hub.
Share this article
