


















It should have been a straightforward deployment. Workday’s financial reporting agent was built on a capable model, pointed at clean data, and tested carefully before launch. Then it went live.
“We started to realize that we were missing this translation layer,” explained Joe DosSantos, Vice President of Enterprise Data and Analytics at Workday. “We had no way to interpret the human language against the structure of the data.” The agent “couldn’t answer a single question it was asked, no matter how straightforward.”
The first response for most teams in this situation is to add more context: metadata, descriptions, and documentation. It’s a seemingly intuitive fix, but one that becomes a scaling nightmare and ultimately makes AI agents less reliable. This is one of the central tensions in context engineering: the discipline is still young enough that most teams haven’t hit the ceiling yet.
The instinct to add more context is right, but only once
Permalink to “The instinct to add more context is right, but only once”Adding context does improve agent accuracy. The first 20% of context enrichment covers most of the obvious failure modes. When an agent doesn’t know what “ARR” means in your organization, or can’t distinguish between “closed” as a deal stage versus “closed” as an account status, more context is necessary. But it’s also relatively straightforward.
What teams don’t anticipate is the ceiling. Norman Paulsen’s research found that effective context on complex tasks can be up to 99% lower than the advertised context window size. And Chroma Research showed that when models lose accuracy on content positioned mid-window, accuracy drops by up to 30% across 18 frontier models. GPT-4o fell from 99.3% to 69.7% accuracy in some configurations.
The more context you add, the more you’re asking the model to find signals inside noise. That’s betting on AI to find the needle in a haystack.
The context debt problem
Permalink to “The context debt problem”There’s a name for what accumulates on the other side of that bet: context debt. It’s created each time an agent fails and teams add context reactively. Documentation grows without ownership, so the same entity gets defined differently by the analytics team, the sales ops team, and the finance team. The agent reads all three definitions and picks one. Nobody knows which it belongs to because nobody built the infrastructure to track it down.
In production, context debt creates a proliferation of information with no guardrails. Atlan’s 2025 State of Enterprise Data and AI Report found that 97% of organizations have context gaps, stemming from a lack of shared definitions and ownership, poor data quality, and unreliable outputs that undermine trust. The symptom is wrong answers, but the cause is context that’s gone unchecked.
The problem compounds because the instinct to add more context makes the underlying issue harder to see. More context means more potential sources of conflict, more outdated entries, more definitions the agent might reach for. You’re not closing the gap. You’re widening the surface area of the problem.
“What’s missing?” is the wrong response to agent failures
Permalink to ““What’s missing?” is the wrong response to agent failures”When an agent fails, the standard response is to find what it didn’t know and add that knowledge. This works often enough in the first few months, and eventually becomes a habit.
But it stops working when the data estate grows. By then, the agent stops failing because context is absent, and starts failing because the context it has is wrong, stale, or in conflict with something else.
The question “what’s missing?” sends teams in the wrong direction. It focuses attention on coverage when the real variable is precision. The context exists somewhere. The problem is that it’s global where it should be specific, stale where it should be current, or untraceable where it should be verifiable. Those three failure modes each require a different fix.
A 3-axis framework for context sufficiency
Permalink to “A 3-axis framework for context sufficiency”To gauge how much context is enough, think about it in three parts:
Specificity. Is the context scoped to this use case, or is it global? A financial analyst agent and a customer support agent should draw from different context objects, not a shared repository of everything the organization knows. Global context is expensive to maintain and often introduces noise that narrows accuracy rather than expanding it.
Freshness. When was this context last verified? Stale context is dangerous because the agent doesn’t know it’s stale. A definition of “churn rate” agreed on in Q1 2024 will produce wrong outputs if the business changed how it calculates churn in Q3. The agent answers with the same confidence regardless.
Verifiability. Can you trace why the agent used a specific piece of context? Without that trace, evaluation is a guess. You can measure whether the output was correct, but you can’t determine whether the context was the cause or the fix. That makes iteration slow and improvement fragile.
A context object that scores well on all three axes is narrow enough to be maintained, recent enough to be trusted, and traceable enough to be improved. That’s the bar for context sufficiency.
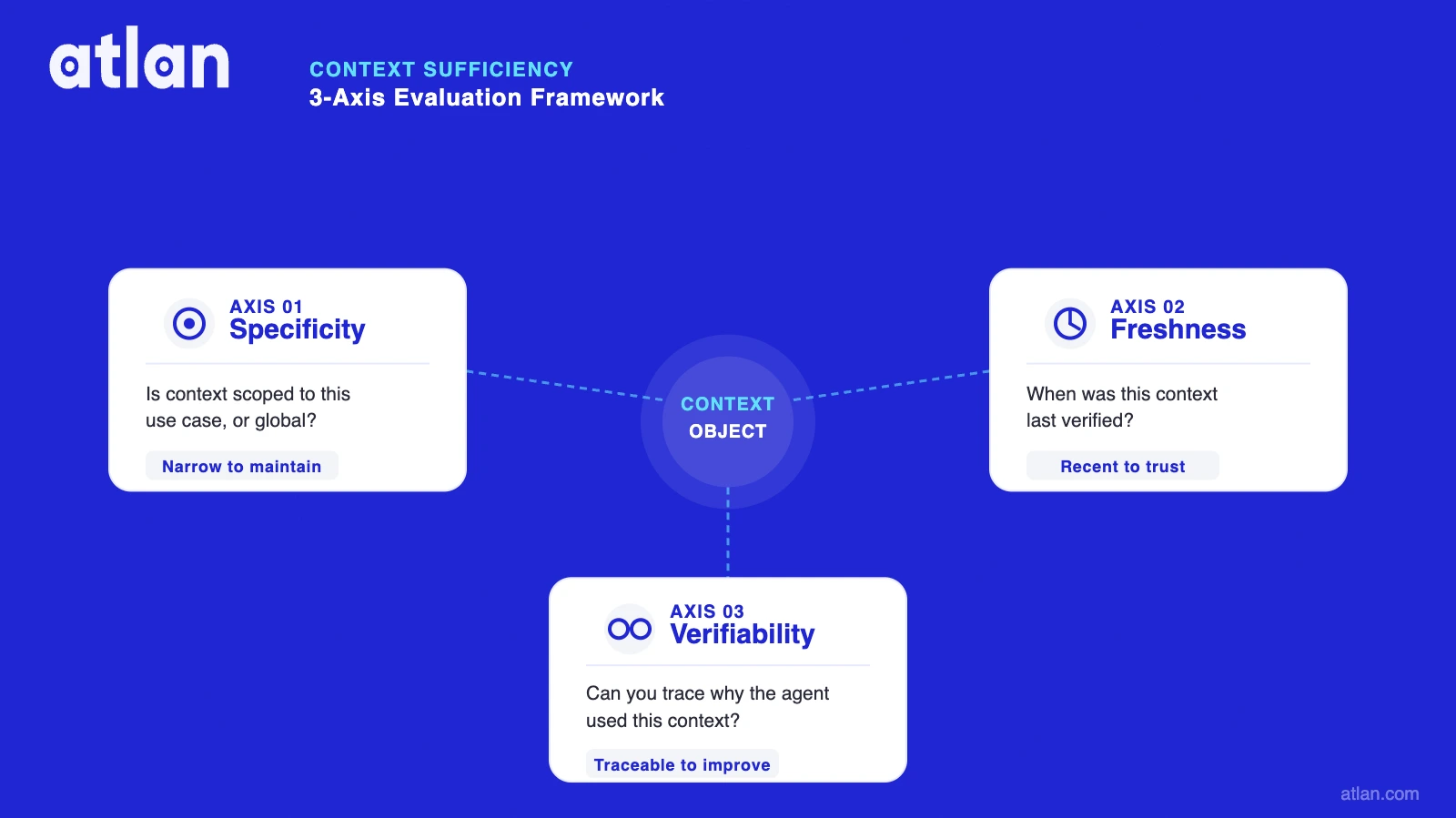
Context sufficiency across three axes: specificity (scoped to the use case), freshness (recently verified), and verifiability (traceable to output). Source: Atlan.
Why eval doesn’t answer the context sufficiency question
Permalink to “Why eval doesn’t answer the context sufficiency question”Evaluation-based validation is the standard approach to catching bad outputs. Teams run the agent, score the answers, and fix what fails. This works at launch, but it rarely holds as scale increases. ReliabilityBench found that pass@1 scores overestimate production reliability by 20–40%, and that’s before context has had a chance to drift.
Think of it like unit testing a live production database. The tests pass at merge time, but six months later, the data has drifted. As new products, rebranded customers, and revised definitions emerge, the tests still pass but the answers are wrong.
Eval tells you whether the agent was right today. But what about next quarter, when the context it’s reading has changed without anyone noticing?
This is how the context lifecycle problem gets mistaken for an evaluation problem. Teams invest in eval tooling to catch output failures and don’t build the infrastructure to prevent context rot. The tests keep passing, but the agent keeps drifting. Downstream, this becomes an expensive mess to clean up.
How to resolve context conflicts
Permalink to “How to resolve context conflicts”Beneath all of this is a data governance for AI problem. It’s the one question most technical teams want to avoid: what happens when two teams have conflicting context for the same entity?
Finance says “revenue” means recognized revenue. Sales says it means booked revenue. The analytics team has a third definition that blends both. All three are in the context layer, but the business can’t tell which an agent is using.
No model choice or retrieval architecture resolves a definitional conflict between two business owners. The resolution requires a human decision, a record of that decision, and a mechanism to retire the old definition. This is governance, applied to a new class of asset.
Most organizations haven’t built it for context yet, because context management is new enough that the discipline hasn’t caught up. But it’s quickly emerging as a non-negotiable for enterprise context layers.
Signals that you have enough context
Permalink to “Signals that you have enough context”There are three key signals that a context layer is performing, not just present:
- Consistent outputs across runs. Not identical, but within expected variance for the same class of query. High variance on similar questions suggests the agent is hunting for a signal in a noisy context space.
- Traceable reasoning paths. The agent can surface which context object informed its answer. Without this, improvement is a guessing game.
- Declining rate of human corrections over time. If humans are correcting agent outputs at a flat or increasing rate after several months, the context isn’t improving. A well-managed context layer should reduce corrections as definitions get verified, versioned, and scoped more precisely.
These aren’t metrics to report upward, but they are important diagnostic signals: the earliest signs for practitioners to know whether the system is stabilizing or drifting.
Governing context like it’s code
Permalink to “Governing context like it’s code”Scalable context management requires the same infrastructure as code: ownership, version history, and retirement policies. Every context object should have a named owner. Definitions should be versioned when they change, not silently replaced. Old versions should be retired with a record of when and why, so that the organization can trace which definition was live when a specific decision was made.
The teams building this capability are treating context as a first-class governed asset, placing it alongside their data contracts, metadata management, and observability stack. In teams that manage context with the same discipline they apply to the data underneath it, that’s where the declining-correction-rate signal starts to appear.
The infrastructure that enables this, context ownership at the asset layer, version-controlled definitions, and traceable lineage between context and output, is the foundation the field is converging toward.
See what governed context looks like for your stack:
Book a DemoThe real question
Permalink to “The real question”Joe DosSantos and the Workday team found their fix. It wasn’t more context; it was a working context layer with discipline behind it: explicit context objects, scoped to specific query types, with clear ownership of the definitions that powered them.
Your competitors aren’t building bigger context windows. The ones moving fastest are building smaller, sharper, better-governed ones. Don’t worry about how much context your agents have. Worry about whether the context you do have will still be accurate in six months, and whether you’ll know if it isn’t.
