



















Every architecture diagram of an AI agent shows the same three boxes: a reasoning core, some tools, and a memory store. Those diagrams are not wrong. They are incomplete. This page explains what each component actually does, why most enterprise agents fail before they reach the reasoning step, and what the standard diagram leaves out.
| Component | What it handles | Common implementations |
|---|---|---|
| Reasoning core | Interprets inputs, plans, decides on actions | GPT-4o, Claude Sonnet, Gemini Pro |
| Orchestration | Sequences agent steps, manages tool calls | LangChain, CrewAI, LangGraph, AutoGen |
| Tool layer | External system connections and function calls | REST APIs, SQL connectors, code executors |
| Short-term memory | Active session context and recent interactions | Context window, conversation buffer |
| Long-term memory | Persistent knowledge retrieved across sessions | Vector stores, graph databases |
| External context layer | Enterprise definitions, lineage, governance | Governed metadata platform |
Get the blueprint for implementing AI context graphs across your enterprise.
Get the Stack GuideWhat is the core architecture of an AI agent?
Permalink to “What is the core architecture of an AI agent?”Every AI agent, regardless of framework or use case, rests on three components: a reasoning core that interprets inputs and decides on actions, tool integrations that allow the agent to act on external systems, and memory that preserves context across steps. The three components work together through a repeating cycle called the perceive-reason-act loop.

Agent architecture overview — Source: Google
What does the perceive-reason-act loop actually do?
Permalink to “What does the perceive-reason-act loop actually do?”The perceive-reason-act loop is the fundamental unit of agent behavior, and understanding where it breaks in enterprise environments is the most important insight this architecture guide can offer.
Consider this: a streaming platform agent tasked with identifying the top 10 political shows to feature on the homepage. That single query requires data on views and ratings, editorial policy knowledge, the definition of “top 10” and “political,” the role of whoever is asking, and knowledge of active seasonal programming. Every step of the loop depends on the context the agent must receive from outside itself.
- Perceive is where the agent takes in all available inputs: the user’s query, outputs from previous tool calls, retrieved memories, injected context, and any system prompt constraints. The agent’s understanding of the task at this step determines everything that follows. If the perception is incomplete or incorrect, reasoning and acting compound the error rather than catching it.
- Reason is where the LLM interprets the perceived inputs, decomposes the goal into subtasks, decides which tools to call, formulates a plan, and determines stopping conditions. This step runs inside the model. The quality of reasoning depends entirely on the quality of what was perceived.
- Act is where the agent executes: calling a function, querying a database, submitting an API request, generating output. The result comes back as an observation, which feeds into the next perceive step, continuing the loop until the agent reaches a conclusion or hits a stopping condition.
A 2025 survey of 306 AI agent practitioners by Pan et al. found that reliability issues are the most common barrier to enterprise adoption, and most of those reliability issues originate at the perceive step, where agents work from incomplete or incorrect information before reasoning ever starts.
How does the LLM function as the agent’s reasoning core?
Permalink to “How does the LLM function as the agent’s reasoning core?”The LLM is the brain of the architecture, but it contributes only the reasoning capability. It has no knowledge of your business, no access to your data, and no memory between sessions beyond what you explicitly provide in the context window.
Your engineering team may assume the model’s broad training knowledge will cover enterprise-specific questions. It covers general knowledge, programming patterns, and documented public information. What it lacks is what “active customer” means in your specific business, which Snowflake table your finance team considers canonical for ARR, or what your fiscal year definition is. That knowledge must be supplied explicitly, through context, every time. This is the most frequently misunderstood aspect of how agentic AI works.
What role do tools and function calling play?
Permalink to “What role do tools and function calling play?”Tools are how agents reach outside the context window to retrieve current information and take real-world actions. When an agent needs data outside its training knowledge, it constructs a function call, pauses reasoning, executes the call, receives the result, and incorporates it before continuing.
Four common enterprise tool types: data retrieval tools (SQL queries, warehouse connectors), API connectors (CRM pulls, SaaS integrations), code executors (Python for data transformation), and agent delegators (handing tasks to specialist sub-agents in a multi-agent system).
For architects, the key point: tool call quality depends entirely on the parameters the agent passes to it. Those parameters come from the perceive step. Without knowing which table is canonical, it passes the wrong table name. Without knowing how your business defines a metric, it passes the wrong filter. The tool executes correctly and returns a wrong answer. Carnegie Mellon benchmarks in 2025 showed leading agents completing only 30 to 35% of multi-step tasks successfully, and tool-call parameter errors from insufficient context account for a significant share of those failures.
How does agent memory work?
Permalink to “How does agent memory work?”Memory in an AI agent is not a single system. Different memory types serve different time horizons and purposes. Understanding the types makes it clear why four framework-provided types are necessary but not sufficient for enterprise deployments.
What are the four types of internal agent memory?
Permalink to “What are the four types of internal agent memory?”Agent frameworks typically provide four internal memory types:
In-context memory is the agent’s working window — everything currently in the prompt. It is fast, immediately accessible, and strictly limited by the model’s context length. When the window fills, older content is compressed or dropped.
Semantic memory stores factual knowledge — definitions, entities, relationships — in a vector store. The agent retrieves relevant facts via similarity search and inserts them into context as needed. This is the layer most teams build first when moving beyond single-turn interactions.
Episodic memory stores records of past interactions and outcomes. The agent can retrieve “what happened last time a user asked about X” and use that history to inform current reasoning. It is the mechanism behind personalization and session continuity.
Procedural memory stores learned patterns and strategies — which tools to call in which sequences, which formulations tend to produce accurate results. It encodes the agent’s accumulated skill rather than its factual knowledge.
Why do the four internal memory types fall short for enterprise agents?
Permalink to “Why do the four internal memory types fall short for enterprise agents?”The four internal types handle the agent’s own knowledge and session history. They do not handle the organization’s knowledge. An agent operating inside an enterprise needs to know what “ARR” means in this company’s finance model, which data assets are certified for this regulatory context, who owns this metric, and whether this dataset has lineage that affects its trustworthiness. None of those things live in semantic, episodic, procedural, or in-context memory by default.
This is the gap that most architecture diagrams ignore. The four internal memory types provide the infrastructure for individual agent cognition. Organizational context — governed definitions, certified lineage, access policies, business glossaries — requires a separate external layer that the agent reads from and that a governance process keeps current.
For data leaders: a practical four-layer architecture from metadata foundation to agent orchestration.
Get the CIO GuideWhat is the missing layer in the standard architecture diagram?
Permalink to “What is the missing layer in the standard architecture diagram?”The standard diagram — reasoning core, tools, memory — describes the mechanics of how an agent operates. It does not describe what the agent reasons over. In enterprise settings, that omission is the primary cause of production failure.
Why do the standard internal components alone produce inconsistent results?
Permalink to “Why do the standard internal components alone produce inconsistent results?”An agent with a strong LLM, well-designed tools, and a capable memory system will still produce inconsistent results if the context it assembles is inconsistent. In any real enterprise, the same term means different things to different teams. “Revenue” in the sales model is not the same as “revenue” in the finance model. “Active user” in the product team’s definition differs from “active user” in the growth team’s definition. When an agent resolves these terms from ungoverned sources, it produces answers that different stakeholders cannot agree on — not because the agent failed to reason, but because it reasoned correctly from ambiguous inputs.
Menlo Ventures’ 2025 State of Generative AI research found that only 16% of enterprise AI deployments qualify as true agents capable of dynamic planning. The majority are fixed-sequence workflows that cannot adapt when context is incomplete or contradictory. Governance of the input context layer is what separates the 16% from the rest.
What does organizational context memory actually contain?
Permalink to “What does organizational context memory actually contain?”Organizational context memory is the external layer that agents read from at the perceive step. It contains four categories of governed enterprise knowledge:
Business definitions — certified, versioned definitions of every metric, entity, and term the agent might encounter. When an agent asks “what is ARR in this context?”, this layer provides the answer the CFO has signed off on.
Data lineage — the upstream provenance of every dataset the agent can query. Lineage tells the agent whether a dataset is trusted, what transformations it has passed through, and whether there are known quality issues that should qualify its answers.
Access policies — governed rules about which data assets are accessible in which contexts. An agent operating in a regulated environment needs to know, before querying, whether the data it is about to use is permissible for the current task.
Semantic relationships — connections between entities, synonyms, and cross-domain mappings that allow the agent to reason across the organization’s full knowledge graph rather than within a single domain silo.
Learn how context engineering drove 5x AI accuracy in real customer systems.
Download E-bookHow Atlan approaches AI agent architecture
Permalink to “How Atlan approaches AI agent architecture”Atlan’s approach to AI agent architecture adds the external context layer that standard diagrams omit. The platform builds and governs the organizational context memory that agents read from at every perceive step.
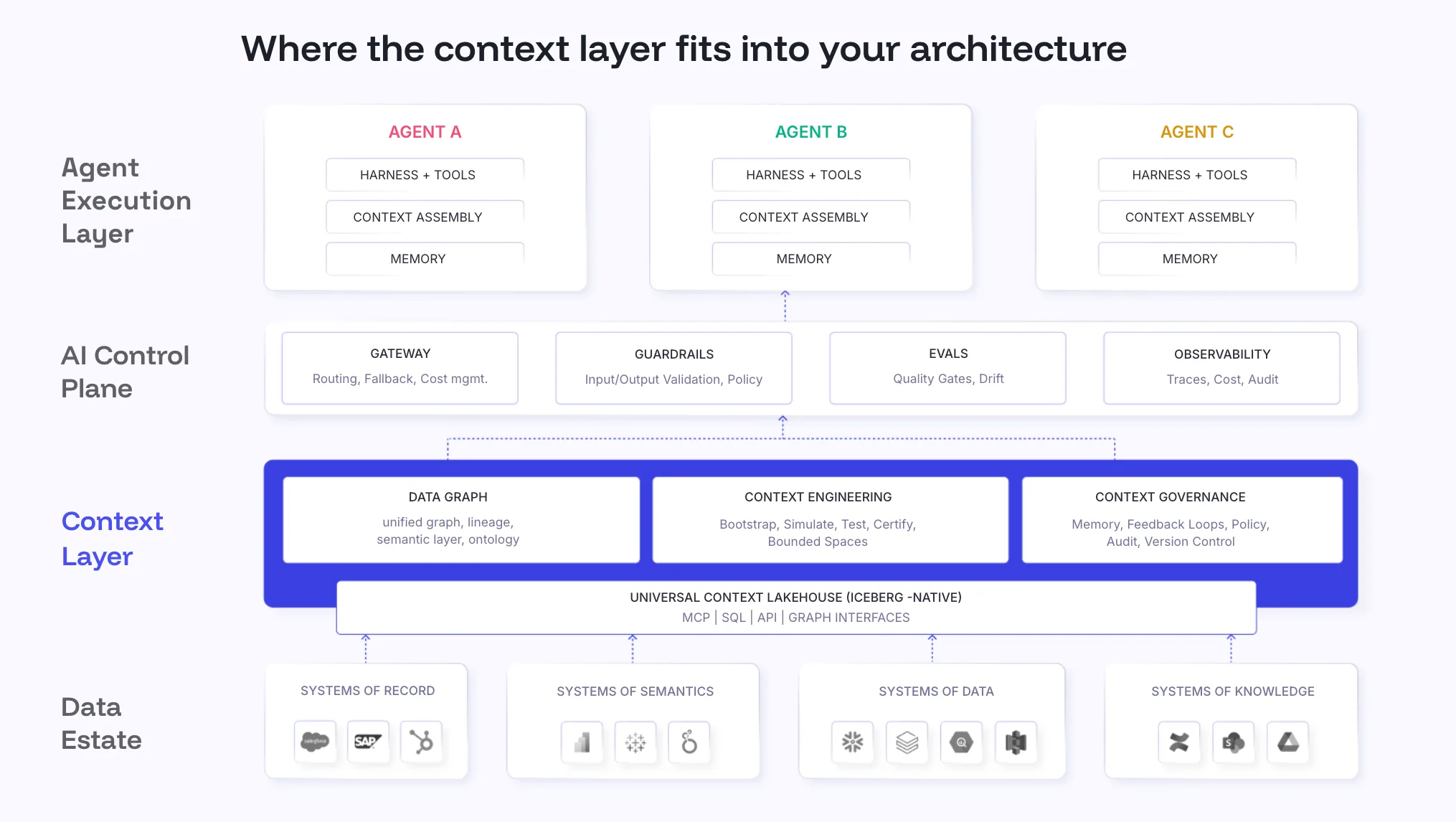
The Atlan architecture operates across four layers. The metadata foundation ingests and catalogs every data asset across the enterprise. The semantic enrichment layer applies certified definitions, lineage, and ownership to those assets. The context layer assembles agent-ready context packages — governed, versioned bundles of definitions, examples, and policies that agents consume at runtime via the Atlan MCP server. The agent orchestration layer is where the reasoning core, tools, and memory systems operate, drawing on the context layer to resolve ambiguity before it reaches the LLM.
This architecture makes accuracy a property of the system rather than a property of any individual agent. When an agent gets the definition of ARR from the governed context layer, every agent reading that layer gets the same certified answer. When a definition is updated and certified, the update propagates to every downstream agent. The accuracy compounds rather than drifts.
How enterprises built the external context layer agents depend on
Permalink to “How enterprises built the external context layer agents depend on”Workday
Permalink to “Workday”“We built a revenue analysis agent and it couldn’t answer one question. We started to realize we were missing this translation layer. All of the work that we did to get to a shared language amongst people at Workday can be leveraged by AI via Atlan’s MCP server.” — Joe DosSantos, VP Enterprise Data and Analytics, Workday
Workday built a revenue analysis agent and encountered the precise failure the architecture gap predicts: the agent could call the right functions but could not resolve business meaning at inference time. Atlan’s context layer provided the translation layer between their data estate and the agent’s inference requirements.
Mastercard
Permalink to “Mastercard”“AI initiatives require more context than ever. Atlan’s metadata lakehouse is configurable, intuitive, and able to scale to our 100M+ data assets.” — Andrew Reiskind, Chief Data Officer, Mastercard
Mastercard operates at a scale where the context supply problem is a daily operational challenge across hundreds of millions of data assets. Atlan’s metadata lakehouse scaled to meet that requirement across their full estate.
Why does the standard agent architecture need an external context layer?
Permalink to “Why does the standard agent architecture need an external context layer?”The perceive-reason-act loop is sound. The three components — reasoning core, tools, memory — are necessary. The gap is not in the loop’s mechanics. The gap is in what the agent perceives.
In a demo environment, the context is hand-curated. Definitions are clear. Data is clean. The agent reasons over a controlled input and produces a correct output. In production, the same agent encounters competing definitions, ambiguous metrics, stale metadata, and scale that makes hand-curation impossible. The agent reasons correctly from a broken input and produces a confident but wrong answer.
A 2025 survey of AI agent practitioners found that context quality — not model capability — was the primary reliability barrier reported by engineering teams across industries. Carnegie Mellon’s multi-step task benchmarks showed that error rates compound with task length: an agent that is 90% accurate at each step achieves only 35% end-to-end accuracy across ten steps. Reducing per-step error by improving context quality is geometrically more valuable than reducing it by improving the model.
The external context layer solves this by making organizational knowledge governed, versioned, and machine-readable at the point where agents assemble their inputs. It is the architectural investment that separates agents that work in demos from agents that work in production.
FAQs about how AI agents work
Permalink to “FAQs about how AI agents work”1. What is the perceive-reason-act loop in AI agents?
Permalink to “1. What is the perceive-reason-act loop in AI agents?”The perceive-reason-act loop is the core operating cycle of an AI agent. The agent perceives all available inputs — goal, tool results, memory retrievals, system instructions — reasons through the large language model to decide what action to take next, then acts by executing a tool call or generating output. The result feeds back into the next perceive step. The loop continues until the agent reaches its goal or a stopping condition. Most enterprise failures originate at the perceive step, before reasoning has begun.
2. What types of memory do AI agents use?
Permalink to “2. What types of memory do AI agents use?”AI agents use four internal memory types: in-context memory (the active working window), semantic memory (vector-stored factual knowledge), episodic memory (records of past interactions), and procedural memory (learned strategies and tool patterns). A fifth type — organizational context memory — supplies governed enterprise definitions, data lineage, access policies, and semantic relationships. The four internal types handle agent cognition. Organizational context memory handles enterprise knowledge. Both are required for production accuracy.
3. How does function calling work in AI agents?
Permalink to “3. How does function calling work in AI agents?”Function calling is the mechanism by which an agent acts on external systems. The agent receives tool definitions as JSON schemas describing each tool’s name, purpose, and parameters. When the LLM determines a tool call is needed, it generates a structured call specification with the appropriate arguments. The framework executes the call, appends the result to the agent’s context, and the reasoning continues. The agent never executes tool calls directly — it generates the specification; the framework executes it.
4. What is the difference between an AI agent and a workflow automation?
Permalink to “4. What is the difference between an AI agent and a workflow automation?”An AI agent plans and adapts dynamically. It perceives its inputs, reasons over the current state, decides on its next action, and adjusts when tool results are unexpected. A workflow automation follows a fixed sequence defined at build time — it cannot adapt when conditions deviate from the designed path. Menlo Ventures’ 2025 research found only 16% of enterprise AI deployments qualify as true agents. The majority are sophisticated automations that break when inputs fall outside the designed scenario.
5. Why do AI agents fail in production when they work in demos?
Permalink to “5. Why do AI agents fail in production when they work in demos?”Demo environments use hand-curated context and controlled inputs. Every definition is clear, every dataset is clean, and every scenario is within the designed scope. Production exposes every edge case: competing definitions across teams, stale metadata, ambiguous metrics, and scale that makes manual curation impossible. The agent reasons correctly from broken inputs and produces confident but wrong answers. The fix is governed organizational context that resolves ambiguity consistently — before it reaches the reasoning step.
6. How many steps can an AI agent reliably handle?
Permalink to “6. How many steps can an AI agent reliably handle?”Reliability degrades with step count because per-step errors compound. Carnegie Mellon’s multi-step task benchmarks show that an agent with 90% per-step accuracy achieves only 35% end-to-end accuracy across ten steps. Improving context quality at the perceive step reduces per-step error, which improves end-to-end accuracy geometrically. Agents with canonical organizational context make fewer tool calls and fewer parameter errors per step, which meaningfully extends the reliable task length for complex enterprise workflows.
Sources
Permalink to “Sources”-
Pan, R. et al. (2025). Survey of AI agent practitioners on reliability barriers, Paul Simmering
-
Menlo Ventures (2025). 2025: The State of Generative AI in the Enterprise
-
Carnegie Mellon University (2025). AI Agents Infrastructure: Multi-step task benchmarks
-
Cleanlab / MIT (2025). AI Agents in Production 2025: Enterprise Trends
