



















Only 7% of enterprises say their data is completely ready for AI (Cloudera and Harvard Business Review Analytic Services, March 2026). A context layer for AI agents closes that gap. It sits between your enterprise data systems and any AI agent that queries them, translating raw metadata into governed business meaning the agent needs to answer correctly. That meaning includes metric definitions, cross-system entity identity, policy enforcement, and provenance trails, making every answer auditable. Atlan’s Enterprise Data Graph connects 80+ native connectors into a continuously updated, governed substrate, and Atlan’s MCP server delivers that context to agents at runtime across environments like Cursor, Databricks, Snowflake Cortex, VS Code, and other MCP-compatible runtimes.
Let’s consider a scenario. Your AI agent nailed the demo. It answered revenue questions instantly, impressed the CFO, and earned a green light for production. Then it went live and told the finance team that Q4 revenue was $12M. The actual figure was $8.4M.
The model was not bad at math. It pulled revenue_recognized instead of revenue_net_of_returns because no one told it which field carried the authoritative definition. The agent had access to the data. It did not have access to the meaning behind the data.
A context layer for AI agents is the infrastructure that closes that gap.
Quick facts about the context layer for AI agents
| Attribute | Detail |
|---|---|
| Also called | Enterprise context layer, AI context infrastructure, agent context layer |
| Primary purpose | Give AI agents enterprise-accurate context, not just data access |
| Core components | Semantic layer, ontology, governance policies, lineage, decision memory |
| Open standards | Model Context Protocol (MCP), Open Semantic Interchange (OSI), Apache Iceberg |
| Who builds it | Data engineering and platform teams, maintained through context engineering |
| Key distinction | Platform-native covers one system; cross-platform spans the full estate |
| Maturity signal | Agents answer correctly across domains without custom prompts per source |
AI agents do not have the business context human analysts carry implicitly. They cannot tell which ‘revenue’ metric is certified, which customer entity is canonical, or which definitions have changed since last quarter. Atlan’s Context Engineering Studio gives an agent a single Context Repository: soul.md for identity, Skills files for capabilities, Semantic models for which metric maps to which question. That is the context layer for AI agents, and it is the difference between a quick Cortex Analyst demo and a production agent the business actually trusts.
Why AI agents fail without a context layer
Permalink to “Why AI agents fail without a context layer”AI agents fail in production because they lack the business context that human analysts carry implicitly. Four failure modes account for most enterprise agent errors: meaning fragments across systems, business definitions live as tribal knowledge, entity identity resolves differently in every database, and answers cannot be traced to their source. Each failure mode is a context problem, not a model problem.
DataHub’s State of Context Management Report 2026 sharpens the picture: 88% of enterprises claim their context is operational, but 61% still delay AI initiatives because the context isn’t usable in practice. The model can be brilliant. The data underneath can still be fragmented, ungoverned, and unfit for an agent to query.

Why enterprise AI agents fail — four root causes, all context problems. Image by Atlan.
Meaning fragments across systems
Permalink to “Meaning fragments across systems”“Customer” in your CRM is not the same as “Customer” in billing. It is not the same as “Customer” in support. Your agent confidently joins three tables and produces a number that looks right but is off.
This happens because customer_id in Salesforce, account_id in Stripe, and org_id in Zendesk all refer to the same company but use different identifiers, with no mapping between them. The model alone cannot infer the mapping, no matter how strong it is.
Why do agents hallucinate when business definitions are missing?
Permalink to “Why do agents hallucinate when business definitions are missing?”Stronger models make hallucinations more convincing, not less common. According to the Capgemini Research Institute’s Rise of Agentic AI report, trust in fully autonomous AI agents dropped from 43% to 27% in a single year, and 80% of organizations lack mature AI infrastructure. The decline in trust is not a model problem. It is a context problem.
When the underlying business definitions are missing, the agent fills the gap. It generates a plausible answer using what it can see. The result reads as authoritative even when it is wrong, and the cost of that confident wrongness only grows as agents take on higher-stakes work.
Unresolved entity identity
Permalink to “Unresolved entity identity”Cross-domain questions require the same real-world entity to be linked across systems using different identifiers. A question like “Why did this customer’s support tickets spike after renewal?” requires CRM account data joined to support tickets joined to billing events.
No single system holds that complete mapping. Without an ontology that resolves identity across systems, the agent either returns partial answers or silently joins on the wrong key. Both outcomes erode trust.
Why can’t agents explain their answers without lineage?
Permalink to “Why can’t agents explain their answers without lineage?”Your agent says, “NRR is 112%.” The VP of Finance asks where that number came from. Without data lineage, the agent cannot point to source tables, transformations, or freshness timestamps. It cannot explain why its number differs from the board deck.
One unverifiable answer is enough to collapse trust. Provenance turns an agent from a black box into an auditable system, and auditability is the price of admission for production-grade agentic AI.
How a context layer for AI agents works
Permalink to “How a context layer for AI agents works”A context layer for AI agents is built from five architectural components that work together. Each addresses a distinct failure mode that no model can solve on its own. The five layers are a semantic layer for governed metrics, an ontology for entity relationships, operational playbooks for routing, lineage for provenance, and active metadata for decision memory.
This architecture is not theoretical. In January 2026, OpenAI’s engineering team published the design behind their internal data agent, which now serves roughly 4,000 of OpenAI’s 5,000 employees daily. The team built six explicit layers of context, and the time to answer a complex business question dropped from over 22 minutes without memory to 1 minute and 22 seconds with the full context stack in place. The pattern matches the architecture below almost exactly.
| Layer | What it provides | Enterprise example |
|---|---|---|
| Semantic layer | Governed metric definitions, dimensions, and filters mapped to physical data | net_revenue = Closed Won, net of returns, USD normalized. One definition, every agent. |
| Ontology and identity | Canonical entities, typed relationships, and cross-system ID resolution | Customer = CRM account_id + billing org_id + support tenant_id. One resolved identity. |
| Operational playbooks | Routing rules, disambiguation steps, and authoritative source selection | Pricing questions must use certified_pricing_v3; draft_pricing is disallowed. |
| Lineage and provenance | Source tracking, transformation history, freshness timestamps, conflict resolution | Agent traces NRR through 4 dbt models to 2 Snowflake source tables. |
| Active metadata | Event trails, approval history, and decision memory linked to business entities | Agent knows the metric definition changed on Jan 15 because finance requested a restatement. |
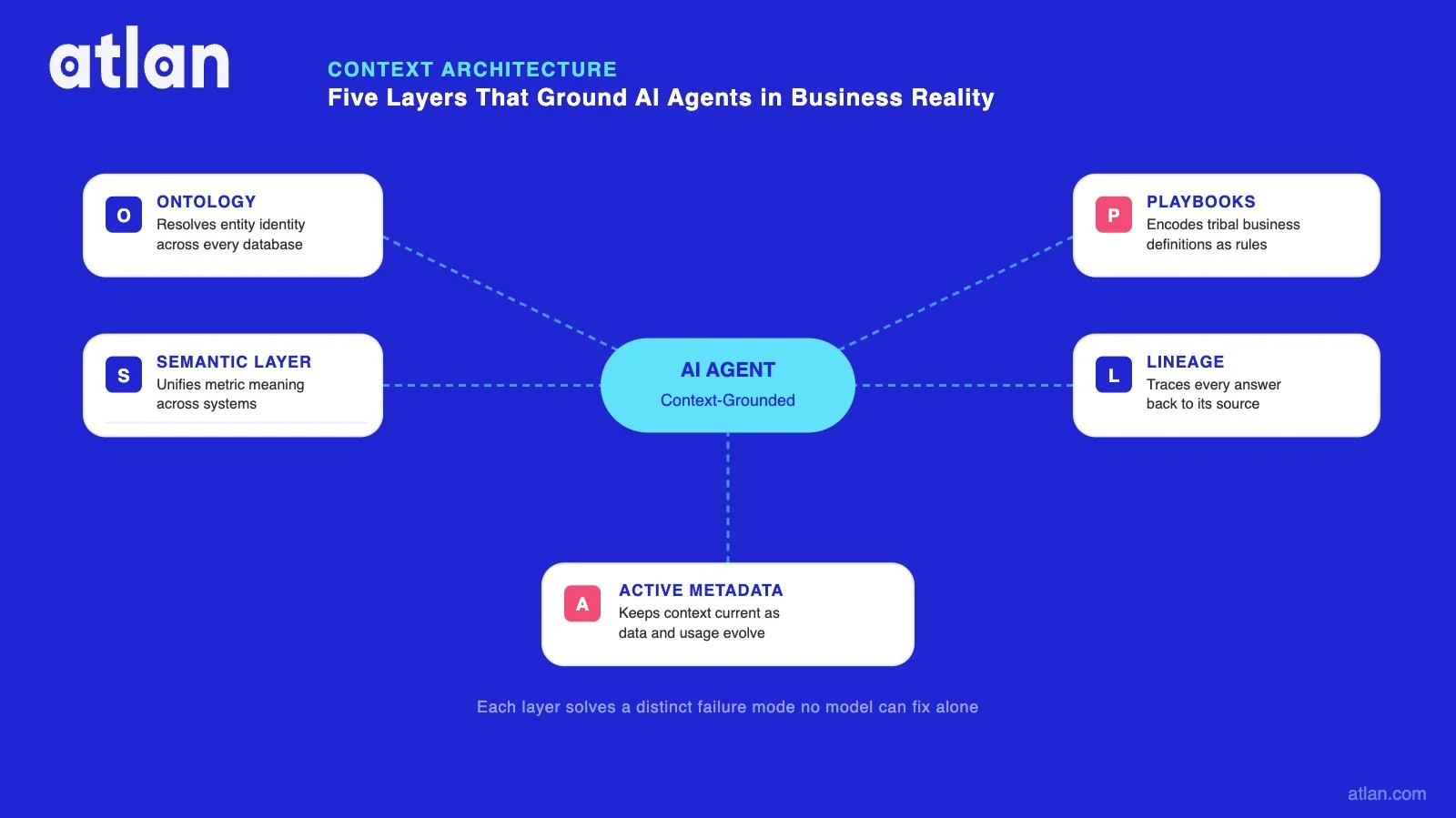
How five context layers solve the four AI agent failure modes in enterprise data. Image by Atlan.
The guide to the core components of a context layer goes deeper on each of these.
The semantic layer governs metrics
Permalink to “The semantic layer governs metrics”The semantic layer maps metric definitions, dimensions, and filters to the underlying physical data. When an agent receives a revenue question, the semantic layer resolves it into a specific calculation with the appropriate filters, time windows, and grain. Fourteen conflicting definitions collapse into one.
This is also where the line between a semantic layer and a context layer gets drawn. The semantic layer governs metrics within a domain. The full context layer spans domains, enforces policies, tracks provenance, and remembers decisions.
The breakdown of the context layer vs. semantic layer covers the distinction in detail.
Ontology resolves identity across systems
Permalink to “Ontology resolves identity across systems”The ontology defines canonical entities, the typed relationships between them, and the bindings into the physical data. It handles synonym resolution, where “client,” “customer,” and “account” all map to the same thing. It handles identity resolution, where a single customer has five different IDs across systems.
This is what makes cross-domain questions safe to ask. Without it, the agent guesses, and guesses join wrongly.
Operational playbooks route the agent
Permalink to “Operational playbooks route the agent”Playbooks are managed instructions that tell the agent how to handle specific intents. They route the agent to authoritative sources. They require disambiguation steps when intent is ambiguous. They block certified data from mixing with draft data.
Playbooks ensure consistent agent behavior across users and channels. The same question through a chat agent, a BI assistant, or an embedded application returns the same answer because the playbook governs the path, not the surface.
Lineage makes every answer explainable
Permalink to “Lineage makes every answer explainable”Lineage gives every agent an inspectable record. For example, the semantic objects an agent selects. The filters it applies. The joins executed, and how fresh the underlying data is.
You’re not struck by a black box when any stakeholder questions how the agent arrived at a number. You get a traceable path through specific sources and transformations. Without lineage, every disputed number becomes a manual investigation. With it, the agent becomes an auditable system.
Active metadata holds decision memory
Permalink to “Active metadata holds decision memory”Active metadata captures event trails and decision artifacts linked to business entities. Approval histories, incident timelines, metric definition changes, and the discussion threads behind them all persist in a live, continuously updated store.
This matters because most “why” questions need institutional history, not just the current state. When an agent explains that revenue dropped in February, decision memory surfaces that the calculation methodology changed on January 15 at the request of the finance team. The current state alone would miss that entirely.
What does a context layer replace in an AI agent architecture?
Permalink to “What does a context layer replace in an AI agent architecture?”Most enterprises do not start by building a context layer. They start by trying something cheaper, ship it, watch it break at scale, and then realize they need an architectural answer rather than another patch.
Four prior approaches show up in nearly every team’s history. Here’s a brief overview:
| Were using | Core problem at enterprise scale | What a context layer provides instead |
|---|---|---|
| RAG alone | Vector search returns documents that look relevant; agents drift on structured data, hallucinate definitions, and burn tokens without grounding | Governed, versioned semantic context with policy enforcement and lineage at query time |
| Semantic layer alone (BI-first) | Designed for human analysts in BI tools; not agent-queryable, not real-time, missing identity resolution, and provenance | Agent-ready, machine-readable context with cross-system ontology and active metadata |
| Memory middleware | Session-scoped, fragmented across agent frameworks, ungoverned; useful for personalization, insufficient for enterprise truth | Unified, persistent, auditable context shared across every agent and every use case |
| Prompt engineering patches | Brittle and manual; system prompts grow until they swallow the context window, and the same fixes get rewritten for every new agent | An architectural and self-updating context that compounds across agents instead of being rebuilt for each one |
RAG was designed to address a specific problem: finding the relevant passage in unstructured text and passing it to the model. That is not the problem most enterprise agents are solving.
Enterprise questions tend to be computational rather than retrieval-shaped. They span structured systems. They depend on definitions that live in nobody’s document. RAG handles none of that natively, and the cost of trying to make it work shows up in the token economy of production.
Datadog’s 2026 State of AI Engineering report found that 69% of all input tokens in customer LLM traces are spent on system prompts: instructions, policies, and tool descriptions repeated on every call. Even when the underlying model supports prompt caching, only 28% of LLM calls take advantage of it. Stack RAG retrieval on top of that, and you get more retrieved context, mostly ungoverned and unversioned, often duplicating what a properly governed semantic layer would have encoded once.
Atlan’s deeper comparison of AI memory systems versus RAG walks through where each pattern actually fits.

How a context layer solves what RAG, semantic layers, memory middleware, and prompt patches cannot. Image by Atlan.
Semantic layers were not built for agents
Permalink to “Semantic layers were not built for agents”A semantic layer is one of the most important inputs into a context layer. It is not the same thing as one.
Semantic layers were built for BI consumption. Looker, Tableau, and Power BI all have their own. They standardize metrics for human analysts working inside a single tool, which is exactly what they were designed to do, and exactly why they fall short for agents. They do not include cross-system identity resolution. They do not enforce policies at runtime. They do not track lineage across the systems above and below them. Treating a semantic layer as a complete context layer is how teams end up with agents that get the metric right and the join wrong.
Joe DosSantos, VP of Enterprise Data and Analytics at Workday, framed the limitation directly during his Atlan Re:Govern keynote.
“Semantics shouldn’t be for a particular use case,” he said. “It just exists for everyone. Definitions have to sit at the crossroads of all of this in the semantic layer so that contextual meaning can be understood by everyone who’s calling it from different tools.”
The point is structural. If semantics live inside one tool, agents that cross tools cannot share them, and the same definition fragments back into the silos the semantic layer was supposed to eliminate.
Memory middleware is scoped to the agent, not the business
Permalink to “Memory middleware is scoped to the agent, not the business”Memory middleware does something useful, just not the thing enterprises usually need. It maintains session state. It holds working memory across turns. It makes a single agent feel coherent within a single conversation. None of that gives the agent enterprise-accurate definitions, cross-system identity, or governed policies.
Memory is scoped to the agent. A context layer is scoped to the business. Atlan’s breakdown of AI memory vs. RAG vs. knowledge graph lays out where each fits in the stack.
The short version: memory makes one agent smarter for one user in one conversation, and a context layer makes every agent in your enterprise correct over time.
Prompt engineering patches do not survive contact with production
Permalink to “Prompt engineering patches do not survive contact with production”Most teams’ first context strategy lives in the system prompt. Tell the agent which table to use. Spell out the metric definition. Add a rule to disambiguate ARR from MRR. Repeat for the next agent, and the next. The system prompt grows until it competes with the user’s actual question for the model’s attention.
New agents copy fragments of it. Definitions diverge between teams. Within a quarter, the patches contradict each other, and the original problem is back. Anthropic’s engineering team has framed the way out as a generational shift: from prompt engineering, which is per-call and brittle, to context engineering, which configures the entire set of tokens an LLM sees at inference time and treats that as a system rather than a workaround.
Context engineering is a discipline, not a one-time setup
Permalink to “Context engineering is a discipline, not a one-time setup”A context layer is not a project that finishes. The business will keep changing. Definitions will evolve. New systems will land. New agents will need new slices of context. Context engineering is what keeps the layer alive after the initial build.
Anthropic frames it as the configuration of working context, session memory, long-term memory, and tool context for every LLM call. That definition is correct at the runtime layer. The enterprise version of context engineering operates one level higher: building and maintaining the durable substrate every runtime draws from in the first place.
The wire that carries context matters less than what travels over it. Anthropic launched the Model Context Protocol in November 2024 and donated it to the Linux Foundation’s Agentic AI Foundation in December 2025. It is now the de facto standard for connecting agents to tools. None of that, on its own, gives you governed meaning.
Speaking at the Gartner Data and Analytics Summit 2026, analyst Andres Garcia-Rodeja predicted that 60% of agentic analytics projects that rely solely on MCP will fail by 2028 due to the lack of a consistent semantic layer underneath. MCP moves context. It does not produce it.
A practical context engineering workflow tends to look like this:
- Start with what you already have. Metric definitions in your semantic layer, table metadata in your catalog, and query history in your warehouse. Mining this is faster and more accurate than greenfield documentation.
- Layer in everything else. Glossaries, ontologies from past MDM projects, operational playbooks, pipeline code, and the institutional knowledge that lives outside the warehouse.
- Use AI to propose, humans to approve. Context agents can suggest synonyms, recommend joins, flag stale definitions, and generate descriptions at scale. Domain experts certify what ships.
- Watch what breaks and fix that first. Track the context gaps that produce real agent errors. Prioritize by business impact rather than completeness.
- Treat context as a system. The minute you treat it as a document, it goes stale.
Why platform-native context layers fall short for enterprise agents
Permalink to “Why platform-native context layers fall short for enterprise agents”Snowflake, Databricks, and Palantir have each invested heavily in context-layer functionality within their own platforms. Each does real work for customers running on a single platform. None of them solves the problem that most enterprises actually face.
Most enterprises run three to five data platforms, not one. Customer data sits in one warehouse. Product telemetry is generated somewhere else. Operational systems run on a third platform. BI sits across the top of all of it. SaaS applications hold business logic that never enters any warehouse. An agent that understands context only within a single platform is blind to most of where the business actually lives.
The accuracy gains from cross-platform context are measurable. Atlan AI Labs ran a 174-query, 522-evaluation benchmark across 13 tables and 94 columns, comparing AI-generated SQL with and without enriched semantic metadata. Adding context delivered a 38% relative improvement in accuracy with a p-value below 0.0001. Customers running Atlan AI Labs workshops have reported up to a 5x improvement in query accuracy after layering context onto their existing data. At enterprise scale, that context foundation has generated 1.7M+ descriptions and saved 209,000+ hours of manual work across 50+ enterprises.
| Dimension | Platform-native context | Cross-platform context layer |
|---|---|---|
| Scope | Single warehouse or lakehouse | All data systems, BI tools, and operational apps |
| Identity resolution | Within one platform’s namespace | Across CRM, ERP, billing, support, and warehouse |
| Governance policies | Platform-specific access controls | Unified policies enforced across all systems |
| Lineage | Transformations within the platform | End-to-end, column-level across the full stack |
| Agent interoperability | Agents built on that platform’s SDK | Any agent via MCP or open standards |
| AI query accuracy | Bounded by a single platform’s metadata | +38% relative SQL accuracy when agents receive governed cross-platform context (174-query / 522-evaluation Atlan AI Labs benchmark) |
This is not a product gap that the platform vendors will eventually close. It is a market structure that they are commercially incentivized not to close. A vendor that depends on customers consolidating onto its platform will always build a context layer that works best when consolidation is total. That is not where most enterprises will land.
The Open Semantic Interchange initiative is itself a tell. Even the platform vendors are now backing the case for cross-system interoperability. The remaining question is who is positioned to deliver it without owning the platforms underneath.
Learn more about why AI agents need an enterprise context layer.
How Atlan delivers a cross-platform context layer for AI agents
Permalink to “How Atlan delivers a cross-platform context layer for AI agents”Atlan is the cross-platform context layer for AI. The platform sits between any data source you run and any agent framework your teams choose to use, providing governed semantics, lineage, policy enforcement, and provenance regardless of where the underlying data lives.
Four product capabilities do the work:
- Enterprise Data Graph: More than 100 native connectors knit warehouses, BI tools, SaaS apps, and operational systems into one continuously updated graph. That graph is the substrate every layer above it draws from.
- Context Agents: AI teammates that read existing SQL, pipeline code, and BI semantics, then propose descriptions, metrics, joins, and ontologies. Most of the initial context layer can be bootstrapped this way before humans get involved.
- Context Engineering Studio: A purpose-built workspace where domain experts certify, version, and ship reusable context products. The same surface serves analysts in catalogs and agents in MCP-enabled tools, so context built for one audience compounds for the other.
- Context Lakehouse: An Iceberg-native, open-format store engineered specifically for AI consumption. Context runs on your compute, moves with you across clouds, and stays portable across agent frameworks.
The proof shows up in production.
Speaking at Atlan Re:Govern, Kiran Panja, Managing Director at CME Group, described the result of the firm’s first year on Atlan:
“We cataloged over 18 million assets, defined more than 1300 glossary terms, and we were tackling new use cases every quarter.”
Lineage now spans on-prem Oracle, BigQuery, and Looker at the world’s largest derivatives exchange. The work is reusable across the company.
Workday is co-building AI-ready semantic layers with Atlan. As Joe DosSantos, VP of Enterprise Data and Analytics, described it: “All of the work that we did to get to a shared language amongst people at Workday can be leveraged by AI via Atlan’s MCP server.” Context built for humans is now consumed directly by agents through the same governed surface.
Independent analysts are arriving at the same conclusion. Atlan was named a Leader in the 2026 Gartner Magic Quadrant for Data and Analytics Governance Platforms, where Gartner observed that Atlan “stands out in its focus to deliver AI-native governance through context (metadata)-based ecosystem partnerships, agentic stewardship and orchestration of enterprise agentic systems.”
The deeper pattern underneath all of this is worth naming. Model intelligence is commoditizing. Better models are available to every competitor you have, and they will be available to your competitors next year too. The advantage in agentic AI no longer comes from the model. It comes from how completely your enterprise has encoded its own meaning into a layer that any agent can draw from. That layer is your IP. Atlan’s job is to keep it open, portable, and yours.
FAQs about context layers for AI agents
Permalink to “FAQs about context layers for AI agents”What is a context layer for AI?
Permalink to “What is a context layer for AI?”A context layer for AI is the infrastructure that translates raw enterprise data and metadata into the business meaning AI agents need to answer correctly. It combines a semantic layer, ontology, governance policies, lineage, and active metadata into a single governed surface that any AI agent can query at runtime.
Why do AI agents fail without a context layer?
Permalink to “Why do AI agents fail without a context layer?”Agents fail without a context layer because enterprise data is fragmented, ambiguous, and governed by tribal knowledge that no model has access to. Without governed definitions, identity resolution, and provenance, agents pick whichever definition surfaces first, join on the wrong keys, or return answers they cannot explain. The model is rarely the problem. The missing context almost always is.
How does a context layer differ from RAG?
Permalink to “How does a context layer differ from RAG?”RAG retrieves relevant text passages from a vector store and inserts them into the model’s context window. A context layer governs the structured business meaning, identity, and policies that agents need before retrieval even happens. RAG is good at finding documents. A context layer is built to deliver verified business truth across structured systems.
What does a context layer replace in an AI agent architecture?
Permalink to “What does a context layer replace in an AI agent architecture?”A context layer replaces four common workarounds: RAG used alone for structured data, BI-first semantic layers that agents cannot query at runtime, agent memory middleware that is session-scoped and ungoverned, and prompt engineering patches that grow brittle as agents scale. Each was a reasonable starting point. None of them survives at enterprise scale.
What is context engineering for AI agents?
Permalink to “What is context engineering for AI agents?”Context engineering is the discipline of building, curating, and maintaining the context layer that AI agents consume. It covers ontology design, business glossary governance, context graph construction, and active metadata pipelines. Anthropic frames it as the natural progression beyond prompt engineering, focused on configuring the entire set of tokens an LLM sees at inference rather than crafting individual prompts.
How do you build a context layer for AI agents?
Permalink to “How do you build a context layer for AI agents?”Begin with the governed assets you already have: metric definitions, table metadata, and query history. Layer in business glossary terms, lineage, and governance policies. Use context agents to propose missing relationships, synonyms, and join paths, and keep humans in the approval loop. Treat the layer as a living system that evolves with the business, not a documentation project that finishes.
What is the difference between a context layer and a semantic layer?
Permalink to “What is the difference between a context layer and a semantic layer?”A semantic layer standardizes metric definitions, dimensions, and filters within a single analytics domain. A context layer is broader. It includes the semantic layer, plus cross-domain ontology, governance policies, lineage, and decision memory. The semantic layer is one component of the full context layer. Both are necessary. Neither is sufficient on its own.
Can you automate context feeding into AI agents?
Permalink to “Can you automate context feeding into AI agents?”Partly. Context agents can generate descriptions, propose joins, suggest synonyms, and flag stale definitions automatically by reading existing SQL, pipelines, and BI semantics. Most of the initial layer can be bootstrapped this way. The certification step, where humans resolve conflicts and approve definitions, has to remain human. Automated context that is wrong is more dangerous than no context at all.
What is the agent context layer for trustworthy data agents?
Permalink to “What is the agent context layer for trustworthy data agents?”A trustworthy data agent is one whose answers can be governed, audited, and reproduced. The agent context layer is the infrastructure that makes that trust possible. It enforces business definitions, resolves entities across systems, applies access policies at query time, and traces every answer through lineage. Without it, “trustworthy” is a marketing claim. With it, trustworthy becomes verifiable.
How does the Model Context Protocol relate to a context layer?
Permalink to “How does the Model Context Protocol relate to a context layer?”The Model Context Protocol is the open standard for connecting AI agents to tools and data sources. It is the wire. A context layer is what travels over the wire. MCP solves the connectivity problem. The context layer solves the meaning problem. Both are necessary, and projects relying on MCP without a governed semantic substrate underneath are predicted to underperform.
What does your next agent inherit?
Permalink to “What does your next agent inherit?”Every agent your team will deploy in the next twelve months will inherit the same disadvantage as the agent in the opening of this article, unless the context underneath them changes. The gap between the demo and production will not close on its own.
The choice facing most data and AI leaders is structural. You can keep patching system prompts and training one-off agents per use case, and accept that each new agent rebuilds context from scratch. Or you can invest in a context layer that compounds: one substrate that every agent reads from, that gets better as the business defines more, and that does not need to be relitigated for every new model release.
Atlan was built for the second path.
Sources
Permalink to “Sources”- Only 7% of Enterprises Say Their Data Is Completely Ready for AI, Cloudera + Harvard Business Review Analytic Services (March 2026)
- State of Context Management Report 2026, DataHub
- Effective Context Engineering for AI Agents, Anthropic Engineering
- Rise of Agentic AI, Capgemini Research Institute (July 2025)
- State of AI Engineering 2026, Datadog
- Gartner D&A 2026: Where the Context Layer Became a Budget Line Item, Metadata Weekly
- Open Semantic Interchange: An AI Standard for Semantic Layers, Snowflake Blog
- Inside Our In-House Data Agent, OpenAI
- Model Context Protocol, Wikipedia (Linux Foundation donation, December 2025)
