



















Context graph tools for AI agents are software systems that store, connect, and serve enterprise context as a structured, traversable graph, enabling agents to retrieve not just similar content but trusted, related, and historically validated facts. They form the delivery layer (Layer 2) in the 3-layer context infrastructure that separates AI projects that ship from those that stall.
What are context graph tools for AI agents?
Permalink to “What are context graph tools for AI agents?”Software systems purpose-built for agent context retrieval, context graph tools implement context graphs as queryable, agent-accessible systems. The term “context graph tool” refers to the implementation system — the software that builds, maintains, and serves the graph — as distinct from the context graph itself, which is the structured knowledge artifact. A context graph tool builds and exposes the graph; the graph is what the agent queries.
Three capabilities distinguish context graph tools from general knowledge graph tools or vector databases. First, they maintain temporal validity, tracking not just what is known, but when it was known and whether it is still current. Second, they structure relationships as first-class graph elements, enabling multi-hop traversal across data owners, lineage paths, policy constraints, and metric definitions. Third, they expose context through agent-native APIs, most commonly via Model Context Protocol (MCP) servers, so agents receive structured context with confidence scores and provenance rather than raw document chunks.
The category emerged in response to a specific production failure pattern. According to Cleanlab (2025), only 11% of organizations have AI agents actively in production despite 79% claiming some adoption. The gap traces to context infrastructure, not model quality. The context engineering frameworks that address this gap all point to the same foundational requirement: structured, traversable context that agents can query with confidence.
The five architectural components that define a production-grade context graph tool are:
- Graph storage: nodes, edges, and properties; not flat embeddings
- Ontology or semantic grounding: a structured domain model that constrains entity types and relationships
- Temporal awareness: bi-temporal data model tracking event time (when a fact was true) and ingestion time (when the agent learned it)
- Hybrid retrieval: semantic similarity, keyword matching, and graph traversal used in combination
- Agent-native delivery: MCP server or equivalent API that passes structured context with governance metadata
No single open-source tool currently implements all five components equally well; each of the three primary tools has distinct strengths, as the comparison table in a later section shows. But the presence of all five, in some combination, is what separates a production-grade context graph stack from a general-purpose graph database adapted for AI use.
For a deeper treatment of what context graphs are as artifacts, separate from the tools that build them, see Atlan’s definition page.
How context graph tools work: the 5-component architecture
Permalink to “How context graph tools work: the 5-component architecture”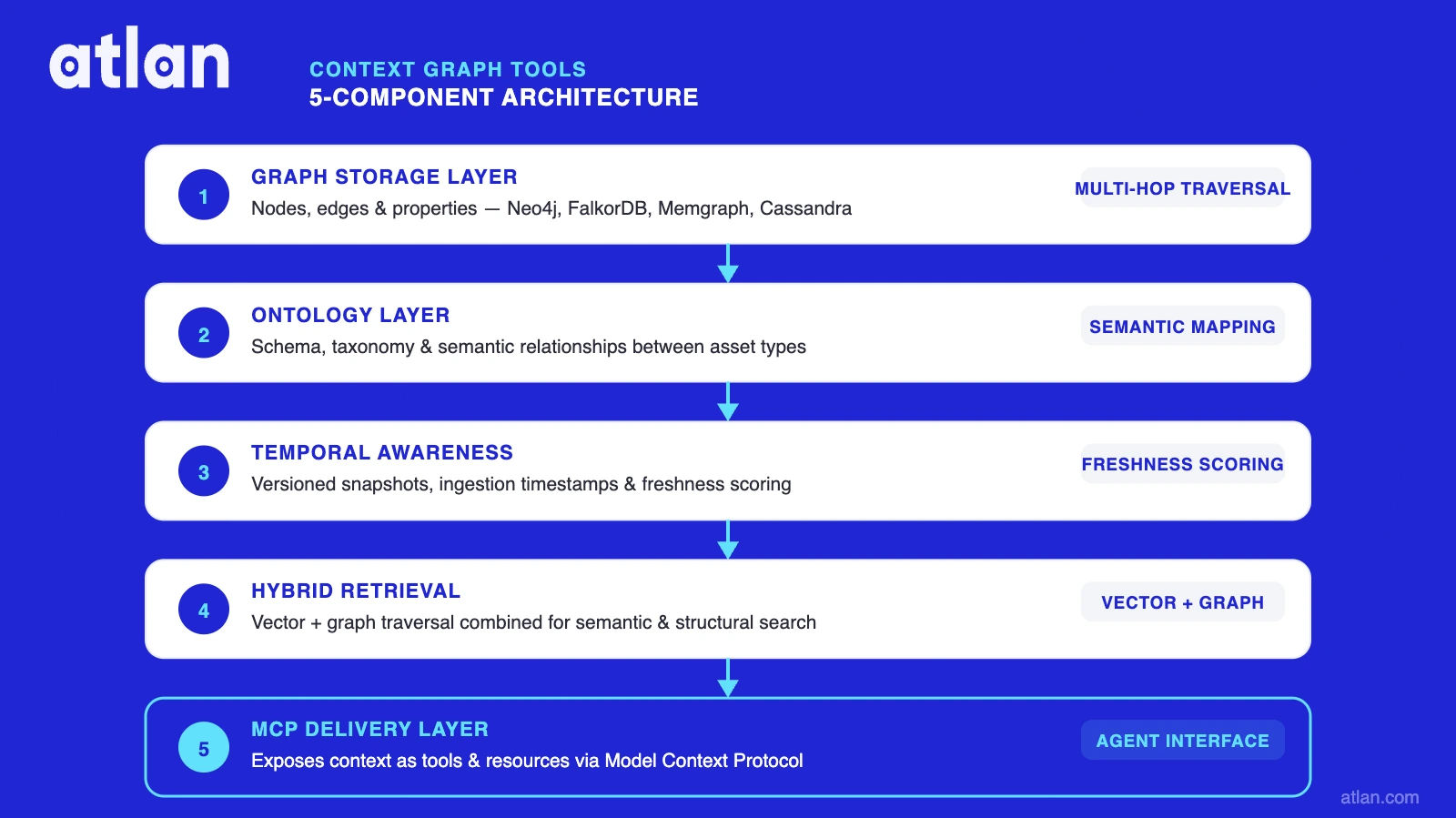
Every production-grade context graph tool implements five architectural components, each doing a distinct job that no other layer in the agent stack handles. The mechanism is: ingest enterprise data, extract entities and relationships, apply ontological structure, maintain temporal validity, and serve via hybrid retrieval over MCP. According to the Graphiti ArXiv paper (2501.13956), this architecture achieves 300ms P95 retrieval latency at production scale.
Graph storage layer
Permalink to “Graph storage layer”The graph storage layer holds nodes (data assets, people, policies, metrics), edges (relationships with governance metadata), and properties (confidence score, certification status, ingestion timestamp). Most context graph tools use Neo4j, FalkorDB, Memgraph, or Cassandra as the graph backend. The structural property that matters for agents is multi-hop traversal: agents can follow chains of relationships from a metric, to its owner, to the certification policy that governs its use, rather than retrieving isolated document chunks.
Ontology and semantic grounding
Permalink to “Ontology and semantic grounding”The ontology layer provides a formal domain model that categorizes entities and constrains the relationships that can exist between them. TrustGraph’s OntologyRAG methodology uses this ontology at the extraction stage itself: each entity is classified against the domain schema before being stored in the graph, preventing noise from entering the structure. TrustGraph’s Context Cores, versioned packaged context units, make ontology artifacts portable and reusable across deployments. Ontological constraint prevents hallucination at the knowledge-extraction stage, not just at retrieval time.
Temporal awareness and fact invalidation
Permalink to “Temporal awareness and fact invalidation”Graphiti introduced the bi-temporal data model to context graph tools: every fact carries both an event time (when the fact was true in the world) and an ingestion time (when the agent learned it). This enables real-time incremental updates without batch recomputation: when a data asset is deprecated or a metric definition changes, the graph reflects this immediately through fact invalidation rather than requiring a full rebuild. According to Graphiti’s benchmark results (ArXiv 2501.13956), this architecture achieves 94.8% DMR benchmark accuracy and an 18.5% improvement on LongMemEval.
Hybrid retrieval
Permalink to “Hybrid retrieval”Context graph tools combine three retrieval modes: semantic similarity (embedding search for conceptual relevance), keyword matching via BM25 (exact term precision), and graph traversal (relationship-following for connected context). Semantic retrieval alone misses governance policy context; graph traversal alone misses semantic relevance. According to MEGA-RAG research published in PMC (2025), graph-enhanced retrieval achieves hallucination rate reductions of more than 40% compared to traditional RAG approaches. The combination is what makes context graph tools meaningfully more accurate than vector-only systems.
MCP / API delivery to agents
Permalink to “MCP / API delivery to agents”Model Context Protocol (MCP) exposes context graph tools as callable tools to AI agents. All three primary open-source context graph tools (TrustGraph, Graphiti, and Neo4j GraphRAG) have MCP server implementations. When an agent calls a context graph tool via MCP, it receives a structured context chunk that includes the retrieved facts, a confidence score, provenance metadata, and governance status. This structured response is what allows downstream reasoning to be auditable, not just fast. For more on MCP-based context delivery, see Atlan’s MCP-connected data catalog overview.
| Aspect | Traditional RAG | Context graph tool |
|---|---|---|
| Retrieval unit | Text chunks | Nodes + relationships |
| Relationship traversal | None | Multi-hop graph queries |
| Temporal awareness | None | Bi-temporal data model |
| Governance at query time | None | Certification status queryable |
| Hallucination rate | Baseline | 40%+ reduction (MEGA-RAG) |
| Update model | Batch re-index | Real-time incremental |
The architecture makes clear why context graph tools sit in their own category. Traditional RAG retrieves; context graph tools structure, govern, and traverse. In the 3-layer context infrastructure model, these five components collectively define what Layer 2 (the delivery layer) is responsible for.
Where context graph tools sit in context infrastructure
Permalink to “Where context graph tools sit in context infrastructure”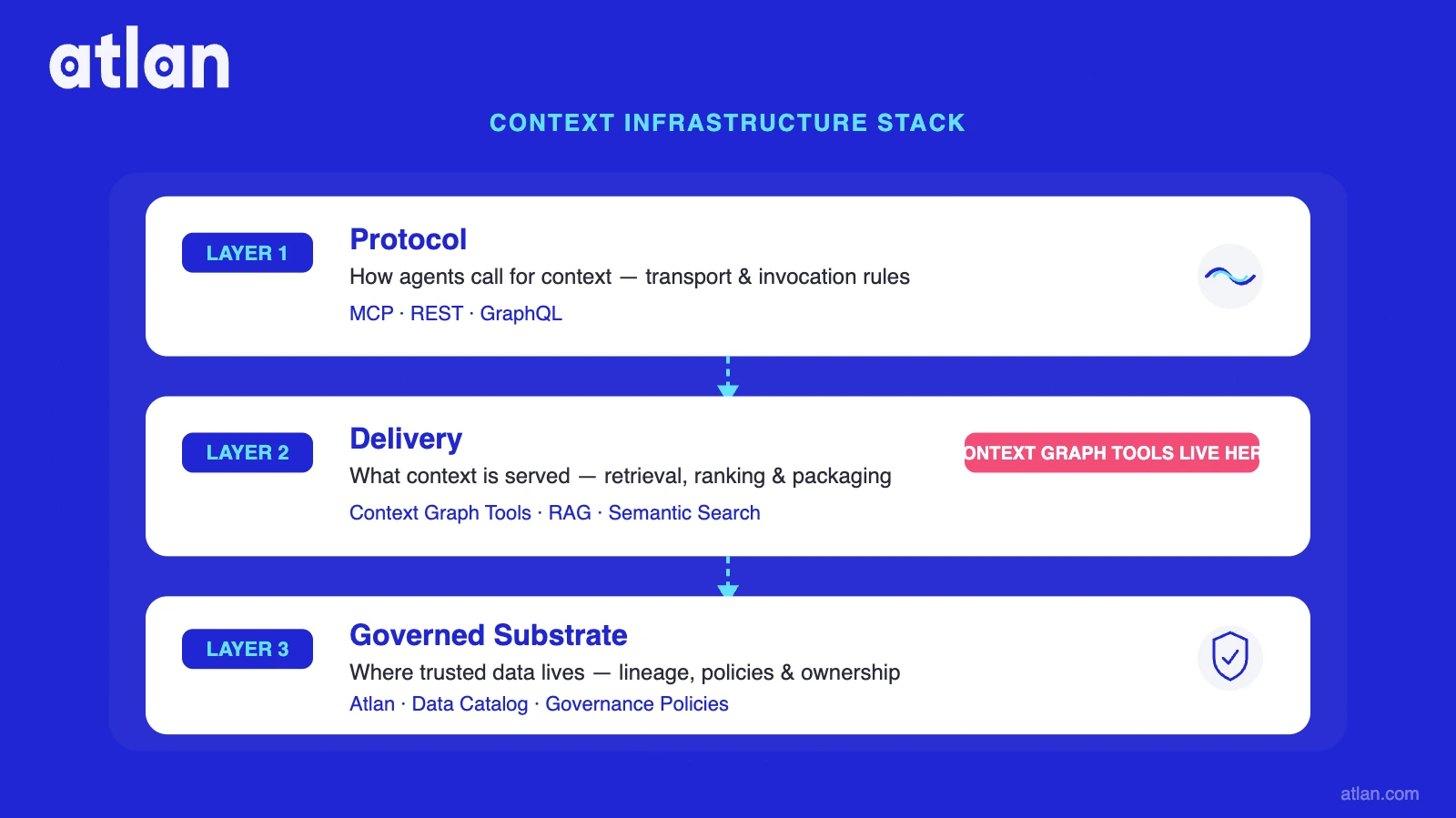
Context graph tools occupy a specific layer in the 3-layer context infrastructure stack; they are not the whole stack, and understanding where they end determines what you still need to build.
| Layer | Name | Role | Examples |
|---|---|---|---|
| Layer 1 | Protocol | How agents call context | MCP, REST APIs |
| Layer 2 | Delivery | How context is retrieved and structured | TrustGraph, Graphiti, Neo4j GraphRAG |
| Layer 3 | Governed substrate | What the context is built on | Atlan Enterprise Data Graph |
Context graph tools are Layer 2, the active retrieval and structuring mechanism. They receive agent queries, traverse the graph, apply retrieval logic, and return structured context chunks. What they do not decide: which data is certified as the single source of truth, which metrics are approved for AI use, which lineage paths are validated for governance purposes, or which policies apply to a specific retrieval context. Those decisions belong to Layer 3.
This distinction exposes the Governance Gap. Efficient delivery of ungoverned data is still a failure mode; it just fails faster and at larger scale. A context graph tool retrieves whatever is in the graph. If the graph substrate is built on uncertified, stale, or ungoverned data, the tool faithfully delivers untrustworthy facts with high confidence and low latency. According to Deloitte/Kamiwaza research cited by Cloudraft (2024), 47% of enterprise AI users made major business decisions based on hallucinated content in 2024. That did not occur because retrieval was slow; it occurred because the substrate was ungoverned.
The interaction between layers: the agent sends a query, the MCP protocol (Layer 1) routes it to the context graph tool (Layer 2), the tool traverses the governed substrate (Layer 3), and the result returns to the agent with provenance and certification status embedded. Each layer has a distinct responsibility. Teams that conflate Layer 2 and Layer 3, treating the retrieval tool as the full solution, consistently hit governance failures at the 3-month mark of production deployments.
For the full treatment of how these layers compose and interact, the context infrastructure for AI agents page covers the 3-layer model in detail.
The three primary open-source context graph tools
Permalink to “The three primary open-source context graph tools”Three open-source projects define what a production-grade context graph tool looks like in 2026: TrustGraph, Graphiti, and Neo4j GraphRAG, and they solve meaningfully different retrieval problems. Graphiti leads on temporal awareness with 94.8% DMR accuracy; TrustGraph leads on ontology-driven extraction with OntologyRAG; Neo4j GraphRAG leads on enterprise scale with three memory types and multi-hop reasoning across billions of nodes.
Note that no single tool implements all five architectural components equally well; the comparison below reflects each tool’s current strengths.
TrustGraph: ontology-driven extraction
Permalink to “TrustGraph: ontology-driven extraction”TrustGraph positions itself as a “Context Operating System for AI,” a system where the formal ontology defines the entire knowledge extraction schema, not just the storage structure. Its OntologyRAG methodology guides entity classification at extraction time rather than as a post-processing step: each entity is classified against the domain schema before storage, which prevents ontology drift as the graph grows. Context Cores, versioned packaged context units, function similarly to versioned data contracts, enabling consistent context across deployments. TrustGraph supports 40+ LLM providers and multiple graph backends (Neo4j, Cassandra, Memgraph, FalkorDB, Qdrant, Pinecone). It is Apache 2.0 licensed and MCP-compatible. Best for organizations that need custom domain ontologies, multi-cloud deployment, or explainable extraction pipelines.
Graphiti: temporal context for dynamic agents
Permalink to “Graphiti: temporal context for dynamic agents”Graphiti (by Zep) is built around the bi-temporal data model: every fact in the graph carries an event time (when the fact was true in the world) and an ingestion time (when the agent learned it). This enables real-time incremental updates without batch recomputation; agents always see current context without waiting for scheduled rebuilds. According to Graphiti’s ArXiv paper (2501.13956), the architecture achieves 94.8% DMR benchmark accuracy, 300ms P95 retrieval latency, and an 18.5% improvement on LongMemEval. With 26,300+ GitHub stars and 2,600+ forks as of May 2026, Graphiti has the highest GitHub star count among the three primary open-source context graph tools. Best for agent memory with temporal awareness, dynamic or frequently-updated datasets, and low-latency real-time retrieval.
Neo4j GraphRAG / agent-memory: enterprise graph database
Permalink to “Neo4j GraphRAG / agent-memory: enterprise graph database”Neo4j brings mature enterprise graph database infrastructure to AI retrieval and agent memory. The neo4j-agent-memory library implements three memory types: short-term memory (conversation history), long-term memory (entities and relationships via the POLE+O model), and reasoning memory (decision traces). Its entity extraction pipeline uses a graduated latency/accuracy tradeoff: spaCy at approximately 5ms, GLiNER2 at approximately 50ms, and LLM fallback at approximately 500ms, a tiered architecture documented in the Neo4j agent memory blog post. Neo4j released a “Create Context Graph” scaffolding tool in May 2026, and GraphAcademy offers free courses for graph-based AI development. The library is framework-agnostic, integrating with LangChain, LlamaIndex, CrewAI, OpenAI Agents, and Pydantic AI. Best for enterprise-grade multi-hop reasoning, deployments at billions-of-nodes scale, and auditability requirements.
| Tool | License | Core Concept | Temporal Awareness | MCP Support | Best For |
|---|---|---|---|---|---|
| TrustGraph | Apache 2.0 | OntologyRAG: ontology-guided extraction | Partial | Yes | Custom domain ontologies, multi-cloud |
| Graphiti | Apache 2.0 | Bi-temporal context graph | Full (bi-temporal) | Full implementation | Dynamic datasets, agent memory |
| Neo4j GraphRAG | Apache 2.0 | Enterprise graph DB + 3 memory types | Partial | Yes (neo4j MCP server) | Enterprise scale, multi-hop reasoning |
Beyond the Big Three, the broader tool landscape splits into two tiers based on scope and governance depth.
Context graph tool directory: all tiers
Permalink to “Context graph tool directory: all tiers”Tier 1 — Graph memory frameworks
Permalink to “Tier 1 — Graph memory frameworks”Purpose-built for agent context retrieval: these tools build, maintain, and serve structured context graphs to AI agents via MCP or equivalent APIs. See the full best AI agent memory frameworks comparison for benchmarks across this tier.
| Tool | License | MCP Support | Core Strength | Best For |
|---|---|---|---|---|
| TrustGraph | Apache 2.0 | Yes | OntologyRAG: ontology-guided entity extraction | Custom domain ontologies, multi-cloud |
| Graphiti (Zep) | Apache 2.0 | Yes | Bi-temporal data model, 94.8% DMR accuracy | Dynamic datasets, real-time agent memory |
| Neo4j GraphRAG | Apache 2.0 | Yes | Enterprise graph DB + 3 memory types | Multi-hop reasoning, enterprise scale |
| Mem0 | Apache 2.0 | Yes | Graph-plus-vector hybrid, cross-session persistence | Long-running agent sessions, multi-agent systems |
| Cognee | Apache 2.0 | Yes | Knowledge graph construction from unstructured text | Document-heavy domains, research assistants |
| Letta | Apache 2.0 | Yes | Stateful memory blocks, memory-as-OS model | Persistent stateful agents, long-horizon tasks |
Tier 2 — Enterprise context platforms
Permalink to “Tier 2 — Enterprise context platforms”Full-stack platforms with governance, connectors, and context management built in — designed for enterprise production, not just retrieval mechanics.
| Tool | License | MCP Support | Core Strength | Best For |
|---|---|---|---|---|
| Atlan | Commercial | Yes (native) | Enterprise Data Graph, 80+ connectors, certification workflows | Governed enterprise AI context |
| Microsoft GraphRAG | MIT | No | Large-scale graph community summarization | Document corpus analysis at scale |
| OriginTrail DKG | Mixed | Partial | Cryptographic provenance, decentralized knowledge graph | Verifiable knowledge provenance |
| Glean | Commercial | No native | Enterprise search + workplace context | Unstructured enterprise content |
Note on hosted graph databases: Neo4j AuraDB, Amazon Neptune, TigerGraph, and Stardog are graph database infrastructure layers that can back a context graph, but they are not purpose-built for agent context retrieval. Using them as a context graph tool requires custom agent integration — you build the ontology layer, temporal awareness, hybrid retrieval, and MCP delivery yourself.
For a full side-by-side comparison including scoring on governance depth, MCP completeness, and benchmark accuracy, see context graph tools compared.
Inside Atlan AI Labs & The 5x Accuracy Factor
Learn how context engineering drove 5x AI accuracy in real customer systems. Explore real experiments, quantifiable results, and a repeatable playbook for closing the gap between AI demos and production-ready systems.
Download E-BookContext graph tools vs. related technologies: what’s the real difference?
Permalink to “Context graph tools vs. related technologies: what’s the real difference?”The most common mistake teams make when evaluating context graph tools is treating them as a replacement for something they already have. Context graph tools solve a different problem than vector databases, RAG pipelines, or knowledge graph tools. Each technology answers a different agent question, and production AI agent systems increasingly use two or more in combination.
| Technology | Answers the Question | Strength for Agents | Limitation for Agents |
|---|---|---|---|
| Vector database | “What is semantically similar?” | Fast semantic recall | No relationship traversal; no governance |
| RAG pipeline | “Which documents are relevant?” | Broad coverage, simple | No graph structure; chunks lack provenance |
| Knowledge graph | “What are the static domain relationships?” | Rich semantics | No temporal awareness; not agent-optimized |
| Context graph tool | “What is trusted, related, and validated?” | Relationship traversal + governance + temporal | Trustworthiness depends on quality of the underlying substrate |
| Context store (JSON/flat) | “What did we last record?” | Simple, fast | No relationships; no traversal; no governance |
Context graph tools vs. vector databases
Vector databases and context graph tools are complementary, not competitive. A vector database answers “what is semantically similar?” with fast embedding-based recall. A context graph tool answers “what is related, trusted, and validated?” with multi-hop relationship traversal and governance enforcement. Production systems increasingly deploy both: vector databases for semantic recall over unstructured content, context graph tools for relationship traversal and governance. The key structural difference: vector databases store embeddings; context graph tools store nodes, edges, and governance metadata. For a full breakdown, see context graph vs. vector database.
Context graph tools vs. knowledge graph tools
The most common objection is what researchers call the Rebranding Objection: “Isn’t this just Neo4j with a new name?” Knowledge graphs represent static domain relationships, are batch-updated, and are not optimized for agent retrieval workloads. Context graph tools add architectural capabilities that are non-trivial: temporal validity as a first-class graph property, execution traces and decision provenance as queryable graph elements, governance policies structurally enforced rather than documented, and agent-native retrieval via MCP with confidence scoring. The additions change what agents can query and trust. For the full disambiguation, see context graph vs. knowledge graph.
Context graph tools vs. RAG pipelines
RAG retrieves context; context graph tools structure it. Without graph structure, agents cannot traverse the relationship chains that matter for enterprise AI: who owns this data, what depends on this metric, what changed upstream, which policy governs this retrieval. RAG and context graph tools are complementary: RAG improves retrieval relevance over large document corpora; context graphs improve retrieval trustworthiness and enable relationship reasoning. According to MEGA-RAG research (PMC, 2025), combining graph-enhanced retrieval with traditional RAG cuts hallucination rates by more than 40%.
How to choose a context graph tool for your agent stack
Permalink to “How to choose a context graph tool for your agent stack”
Choosing a context graph tool requires matching four architecture decisions to your specific agent requirements: temporal awareness depth, ontology complexity, scale, and governance enforcement model. Most enterprise production systems combine tools; for example, Neo4j as the graph database backbone with Graphiti providing the temporal layer for agent memory.
Use-case categorization
Permalink to “Use-case categorization”| Use Case | Tier | Go-To Tools | Key Requirement |
|---|---|---|---|
| Agent long-term memory across sessions | Tier 1 | Graphiti, Mem0, Letta | Bi-temporal model, cross-session persistence |
| Ontology-driven knowledge extraction | Tier 1 | TrustGraph | OntologyRAG, custom domain schema |
| Enterprise graph reasoning at scale | Tier 1 | Neo4j GraphRAG | Multi-hop traversal, distributed backends |
| Document-heavy knowledge bases | Tier 1 | Cognee, TrustGraph | Unstructured text → graph extraction |
| Governed metadata context for enterprise AI | Tier 2 | Atlan | 80+ connectors, certification workflows |
| Verifiable provenance for AI decisions | Tier 2 | OriginTrail DKG | Cryptographic provenance |
| Workplace search + unstructured context | Tier 2 | Glean | Enterprise search, document retrieval |
| Large-scale document corpus summarization | Tier 2 | Microsoft GraphRAG | Community detection, global graph summarization |
Evaluation criteria
Permalink to “Evaluation criteria”| Criterion | Why It Matters | What to Look For |
|---|---|---|
| Temporal awareness | Agents need current facts, not stale snapshots | Bi-temporal model (event time + ingestion time); real-time incremental update |
| Ontology depth | Determines extraction quality and relationship precision | Custom domain ontology support; OntologyRAG or equivalent |
| Scale requirements | Enterprise graph data can reach billions of nodes | Distributed backends (Cassandra, Neo4j enterprise); query latency at scale |
| MCP / API support | Agents call tools via MCP; lack of native MCP adds integration cost | Native MCP server; tool schema coverage |
| Governance integration | Retrieval trust depends on substrate certification | Can the tool query a governed substrate? Does it expose certification status? |
| Hosting model | Affects ops burden and data residency | Self-hosted (open-source) vs. managed cloud vs. SaaS enterprise |
| Graph backend flexibility | Determines what storage layer you can use | Neo4j, FalkorDB, Cassandra, Memgraph, Qdrant — or locked to one backend |
| Latency benchmarks | Production agents have strict latency budgets | Published P95 benchmarks; Graphiti: 300ms P95 at production scale |
| Open-source vs. managed | Build vs. buy tradeoff | Apache 2.0 license availability; commercial support options |
Three production architecture patterns have emerged from enterprise deployments:
- Pattern 1: Neo4j (graph database backbone) + Graphiti (temporal layer for agent memory), for low-latency, temporally-aware agent memory at enterprise scale
- Pattern 2: TrustGraph (ontology engineering and extraction) + Neo4j (storage and querying), for organizations with complex domain ontologies requiring explainable extraction
- Pattern 3: Any open-source tool + Atlan Enterprise Data Graph as governed substrate, the recommended enterprise pattern for teams that need retrieval mechanics plus governance
The decision framework by requirement: if your data changes frequently (live pipelines, evolving metrics), start with Graphiti for temporal awareness. If your domain requires complex custom ontologies, start with TrustGraph for OntologyRAG. If enterprise graph scale, multi-hop reasoning, and auditability are the primary requirements, Neo4j GraphRAG provides the most mature foundation. If you need all of the above plus enterprise governance, 80+ connector coverage, and human-in-the-loop certification, the answer is an open-source tool plus a governed substrate underneath it.
Why open-source context graph tools alone aren’t enough for enterprise AI
Permalink to “Why open-source context graph tools alone aren’t enough for enterprise AI”Open-source context graph tools solve the retrieval mechanics problem well. TrustGraph, Graphiti, and Neo4j GraphRAG are effective at traversing graphs and serving context. But retrieval mechanics are not the same as governance. The infrastructure gap is not in the tools; it is in the substrate they query.
Open-source tools provide graph traversal, temporal awareness, hybrid retrieval, and MCP delivery. What they do not provide: column-level lineage across 80+ enterprise connectors, human-in-the-loop certification workflows that mark specific data as trusted for AI use, policies as queryable graph elements that agents can inspect at retrieval time, and continuous substrate enrichment as enterprise data changes. The 47% figure from Deloitte/Kamiwaza research cited by Cloudraft (2024) — showing that nearly half of enterprise AI users made major decisions based on hallucinated content — traces back to substrate quality, not retrieval speed.
Atlan’s Enterprise Data Graph is the governed Layer 3 substrate that context graph tools should query. It is a unified, living graph across 80+ connectors; metadata, lineage, business semantics, policies, and decision traces are all queryable as graph elements. Atlan’s Context Engineering Studio and Context Agents auto-generate semantic enrichment, term links, and metric definitions, while human-in-the-loop certification closes the trust loop before context reaches the agent. Atlan’s MCP Server exposes only certified, governed context to AI agents; agents cannot accidentally retrieve uncertified data, because the substrate enforces certification at the query layer. Atlan AI Labs has measured a 5x improvement in AI response accuracy for agents deployed with a shared, governed context layer.
The architecture that works in production: open-source context graph tool (Layer 2) querying Atlan’s Enterprise Data Graph (Layer 3) means retrieval mechanics plus governance combined. Gartner recognizes Atlan as a Leader in Metadata Management and Data Analytics Governance, and has featured Atlan in the Hype Cycle for Agentic AI under Context Graphs. For a deeper look at how the Enterprise Data Graph functions as the governed substrate, see the enterprise data graph overview.
Getting started: implementation timeline and common pitfalls
Permalink to “Getting started: implementation timeline and common pitfalls”Most teams underestimate how long it takes to move from a working context graph prototype to a production-ready system that agents actually trust. The POC phase (4 to 8 weeks with 2 to 3 data sources) is independently achievable with any of the three primary open-source tools. The extended 3 to 6 month production timeline reflects the additional work of ontology design, retrieval validation, MCP delivery, and governance integration; the last step is consistently the most underestimated. According to Cloudraft’s implementation guide (2024), this timeline holds across diverse enterprise deployments. For a step-by-step walkthrough of each phase, see how to build a context graph for enterprise AI.
| Phase | Timeline | Key Activities | Milestone |
|---|---|---|---|
| Proof of concept | 4–8 weeks | Select tool, connect 2–3 data sources, basic graph traversal demo | Agents retrieving structured context reliably |
| Ontology and schema design | 2–4 weeks | Map domain entities, define relationships, configure extraction | Domain ontology validated against real agent queries |
| Graph construction and quality | 4–6 weeks | Ingest all data sources, validate entity extraction, calibrate retrieval | Graph coverage 80%+ of target domain |
| Retrieval validation | 2–3 weeks | Benchmark retrieval accuracy, tune hybrid weighting, test multi-hop | Accuracy target met (e.g., 90%+ DMR) |
| MCP delivery and agent integration | 2–4 weeks | Deploy MCP server, integrate with agent framework, test tool calls | Agents calling context graph via MCP |
| Governance integration | 4–8 weeks | Connect governed substrate, certification workflows, lineage verification | Context served is certified and auditable |
| Total | 3–6 months | Production-ready system |
Four common pitfalls account for most failed implementations:
-
Building the graph before defining the ontology. Retrofitting ontology on an unstructured graph typically costs two to three times the original build time. Design entity types and relationships before ingestion, using OntologyRAG or equivalent schema-first approaches.
-
Ignoring temporal data from the start. Adding temporal awareness as a retrofit requires schema redesign. Choose a tool with native bi-temporal support from day one if your domain involves frequently-changing data.
-
Treating the context graph tool as the full solution. Plan the governed substrate layer (Layer 3) before the POC. A context graph tool that queries ungoverned data will fail in production review, usually at the 3-month mark when governance reviewers evaluate what the agents are actually retrieving.
-
Single-tool assumption. Most production systems combine tools. Design for composability from the start: ontology tool plus graph database backend plus agent memory layer plus governed substrate.
Build Your AI Context Stack
Get the blueprint for implementing context graphs across your enterprise. This guide walks through the four-layer architecture, from metadata foundation to agent orchestration, with practical implementation steps for 2026.
Get the Stack GuideReal stories from real customers: context graphs powering enterprise AI
Permalink to “Real stories from real customers: context graphs powering enterprise AI”Enterprise teams that have moved from ungoverned context delivery to governed context infrastructure describe the shift in consistent terms: the bottleneck was not the retrieval tool, it was the substrate underneath it. Here is how two enterprise organizations have approached the Layer 2 + Layer 3 combination in practice.
"We're excited to build the future of AI governance with Atlan. All of the work that we did to get to a shared language at Workday can be leveraged by AI via Atlan's MCP server…as part of Atlan's AI Labs, we're co-building the semantic layer that AI needs with new constructs, like context products."
— Joe DosSantos, VP of Enterprise Data & Analytics, Workday
"Atlan is much more than a catalog of catalogs. It's more of a context operating system…Atlan enabled us to easily activate metadata for everything from discovery in the marketplace to AI governance to data quality to an MCP server delivering context to AI models."
— Sridher Arumugham, Chief Data & Analytics Officer, DigiKey
What separates AI agent stacks that ship from those that stall
Permalink to “What separates AI agent stacks that ship from those that stall”Context graph tools are not optional add-ons; they are the delivery layer that determines whether AI agents succeed or fail in production. The three primary open-source tools (TrustGraph, Graphiti, Neo4j GraphRAG) solve the retrieval mechanics problem well, each with distinct strengths: ontology-driven extraction, temporal awareness, or enterprise-scale graph reasoning. Most production systems combine two or more of these tools rather than choosing one.
The real architectural challenge is not choosing among the tools; it is treating them as Layer 2 of a three-layer stack and investing in the governed substrate (Layer 3) that makes retrieved context trustworthy, certified, and auditable. Efficient delivery of ungoverned data is still a failure mode. The organizations succeeding with production AI agents understand that distinction, and they have built the substrate before they deployed the tools.
The CIO guide to context graphs covers the enterprise architecture decision in detail, including how to assess context maturity and sequence the infrastructure investment.
FAQs about context graph tools for AI agents
Permalink to “FAQs about context graph tools for AI agents”1. What are context graph tools for AI agents?
Permalink to “1. What are context graph tools for AI agents?”Context graph tools for AI agents are software systems that store enterprise knowledge as a structured, traversable graph and expose it to AI agents through agent-native APIs like MCP. Unlike vector databases (which store embeddings for similarity search) or knowledge graphs (which store static domain relationships), context graph tools add temporal awareness, governance metadata, and multi-hop relationship traversal specifically optimized for agent retrieval workloads.
2. How do context graph tools differ from knowledge graph tools?
Permalink to “2. How do context graph tools differ from knowledge graph tools?”Knowledge graph tools store static domain relationships in a semantic model, useful for search and data integration but not optimized for AI agent retrieval. Context graph tools add temporal validity (bi-temporal data models tracking when facts were true), execution traces, decision provenance, governance policies as queryable graph elements, and agent-native retrieval via MCP. The additions are architectural, not cosmetic; they change what agents can query and trust.
3. How do TrustGraph, Graphiti, and Neo4j compare for context graphs?
Permalink to “3. How do TrustGraph, Graphiti, and Neo4j compare for context graphs?”TrustGraph excels at ontology-driven extraction (OntologyRAG) for organizations that need custom domain schemas, best for knowledge engineering at scale. Graphiti leads on temporal awareness with a bi-temporal data model and 94.8% DMR benchmark accuracy, best for dynamic datasets and agent memory. Neo4j GraphRAG brings enterprise graph database maturity with three memory types and multi-hop reasoning at scale, best for auditability and large-scale deployments.
4. Do I need a context graph tool or just a vector database?
Permalink to “4. Do I need a context graph tool or just a vector database?”You likely need both. Vector databases answer “what is semantically similar?” and excel at retrieving relevant document chunks. Context graph tools answer “what is related, trusted, and validated?” and enable multi-hop reasoning across relationships, temporal queries about evolving facts, and governance enforcement at retrieval time. Production AI agent systems increasingly use vector databases for semantic recall and context graph tools for relationship traversal and governance.
5. How long does it take to implement a context graph tool?
Permalink to “5. How long does it take to implement a context graph tool?”A proof of concept with 2 to 3 data sources typically takes 4 to 8 weeks, from tool selection through basic graph traversal working reliably. A production-ready system with full data source coverage, ontology design, retrieval validation, MCP delivery, and governance integration typically takes 3 to 6 months. The most common timeline slip is governance integration; teams underestimate how long it takes to certify the substrate that context graph tools query.
6. Are context graph tools open source?
Permalink to “6. Are context graph tools open source?”The three primary context graph tools (TrustGraph, Graphiti, and Neo4j GraphRAG) are all open source under Apache 2.0 licenses. Graphiti has over 26,300 GitHub stars and 2,600 forks as of May 2026. However, open-source tools handle retrieval mechanics only; they do not include enterprise governance features like certification workflows, column-level lineage across 80+ connectors, or human-in-the-loop context validation; those require a governed substrate layer.
Sources
Permalink to “Sources”- 47% of enterprise AI users made major business decisions based on hallucinated content in 2024, Cloudraft
- Only 11% of organizations have AI agents in production, Cleanlab AI Agents in Production 2025
- Graphiti: 94.8% DMR accuracy, 300ms P95 latency, ArXiv paper 2501.13956
- MEGA-RAG: graph-enhanced retrieval achieves 40%+ hallucination reduction, PMC
- Graphiti GitHub: 26,300+ stars, 2,600+ forks, May 2026
- Neo4j agent memory: spaCy/GLiNER2/LLM extraction pipeline, Neo4j blog
- Open source context graph tools comprehensive guide 2026, contextgraph.tech
