



















Context graph tools give AI agents governed, relationship-aware access to enterprise knowledge. Eight tools on the market take fundamentally different architectural paths to get there. We evaluated TrustGraph, Graphiti, Neo4j GraphRAG, Microsoft GraphRAG, Cognee, OriginTrail DKG, Glean, and Atlan across five axes: MCP support, temporal awareness, lineage, enterprise scale, and governance readiness — plus two columns most comparison pages omit entirely: governance scoring and portability. The honest summary before you read anything else: Neo4j wins on developer ecosystem. Atlan wins on enterprise governance. Everything else is context.
A context graph tool builds and serves a graph-structured knowledge layer that AI agents query at runtime, connecting entities, relationships, history, and policy in a single traversable structure. Unlike vector databases, which retrieve semantically similar chunks, context graph tools preserve the relational depth and temporal history that agents need to reason, not just retrieve.
The tools in this category range from open-source developer libraries (Graphiti, TrustGraph, Cognee) to enterprise-grade governed platforms (Atlan, Glean) to research-origin systems (Microsoft GraphRAG, OriginTrail DKG). They do not all replace each other; they serve different points in the agent stack.
Quick Facts at a glance:
| TrustGraph | Graphiti | Neo4j | MS GraphRAG | Cognee | OriginTrail DKG | Glean | Atlan | |
|---|---|---|---|---|---|---|---|---|
| License | Apache 2.0 | Apache 2.0 | Community/Enterprise | Apache 2.0 | OSS + paid | OSS (DKG v9) | SaaS only | Enterprise |
| GitHub stars | — | 26K+ | 31.6K+ | 31.6K+ | 17.1K | — | — | — |
| MCP support | Yes (v1.1+) | Yes (native) | Yes (official) | No | Yes (native) | Partial | No | Yes (native) |
| Best retrieval | OntologyRAG + vector | Hybrid (semantic + BM25 + graph) | Multi-hop Cypher + vector | Community summarization | Ontology + vector | Decentralized graph | Hybrid enterprise | MCP-exposed metadata graph |
| Starting cost | Free (self-host) | Free (self-host) | Free (community) | Free (index: $50–200/corpus) | Free / $35/mo | Free (blockchain overhead) | Enterprise only | Enterprise only |
Inside Atlan AI Labs & The 5x Accuracy Factor
Learn how context engineering drove 5x AI accuracy in real customer systems. Explore real experiments, quantifiable results, and a repeatable playbook for closing the gap between AI demos and production-ready systems.
Download E-BookAtlan's CIO's Guide to Context Graphs covers how context graphs differ from knowledge graphs, a five-stage maturity model, and how leaders move AI from pilots into production with decisions they can trace.
What makes the best context graph tool?
Permalink to “What makes the best context graph tool?”The best context graph tools do more than retrieve related chunks; they preserve temporal history, enforce governance policies, and expose context to agents through standard interfaces like MCP. Evaluating them only on latency or open-source status misses the dimension that determines whether agent outputs are auditable in production: governance readiness.
We evaluated all 8 tools against six criteria:
Criterion 1: MCP support and agent interoperability
Permalink to “Criterion 1: MCP support and agent interoperability”Model Context Protocol (MCP) is the emerging standard for how agents consume external context. Tools without a native MCP server require bespoke integration wiring that multiplies maintenance cost as the agent fleet grows. We looked for native MCP server support (not just community integrations), STDIO and HTTP transport, and official maintenance and versioning.
Criterion 2: Temporal awareness and incremental updates
Permalink to “Criterion 2: Temporal awareness and incremental updates”Facts change. A context graph that cannot track when a relationship became invalid will serve stale, incorrect context to agents. Bi-temporal models, tracking both event time and ingestion time, are the gold standard; most tools in this comparison offer none. We looked for bi-temporal data models, incremental graph updates without full recomputation, and fact invalidation with validity windows.
Criterion 3: Lineage and governance
Permalink to “Criterion 3: Lineage and governance”In regulated enterprises, “trust me it’s relevant” is not an acceptable context delivery model. Agents need to know where context came from, whether it is certified, and what changed downstream when a source asset was deprecated. We looked for column-level or asset-level lineage, certification status propagation, data classification (PII, sensitivity), and audit trails for agent-consumed context.
Criterion 4: Enterprise scale and multi-tenant architecture
Permalink to “Criterion 4: Enterprise scale and multi-tenant architecture”Developer demos do not predict production behavior. Tools that work for one agent with one developer’s data often buckle under 50 concurrent agents querying shared context. We looked for multi-tenant isolation with RBAC, SSO integration, horizontal scalability, and a 50+ source connector ecosystem.
Criterion 5: Multi-agent coordination design
Permalink to “Criterion 5: Multi-agent coordination design”Single-agent context tools do not translate to multi-agent architectures. When agents share a context graph, consistency guarantees, concurrent write handling, and conflict resolution matter. We looked for shared context layer design, concurrent read/write handling, and swarm coordination features.
Criterion 6: Open source vs. enterprise tradeoff
Permalink to “Criterion 6: Open source vs. enterprise tradeoff”Open source means flexibility and cost control. Enterprise-first means managed governance, SLA, and connectors. The right choice depends on your team’s capacity to operate infrastructure versus your need for auditable enterprise data governance. This criterion captures license type, self-hosting options, and community versus vendor support model.
The enterprise teams that get AI to production fastest are not the ones who chose the highest-starred GitHub repository; they are the ones who matched their context tool selection to their actual governance requirements before they started.
The 8 context graph tools at a glance
Permalink to “The 8 context graph tools at a glance”| Tool | Best For | Key Differentiator | License / Pricing | MCP Support |
|---|---|---|---|---|
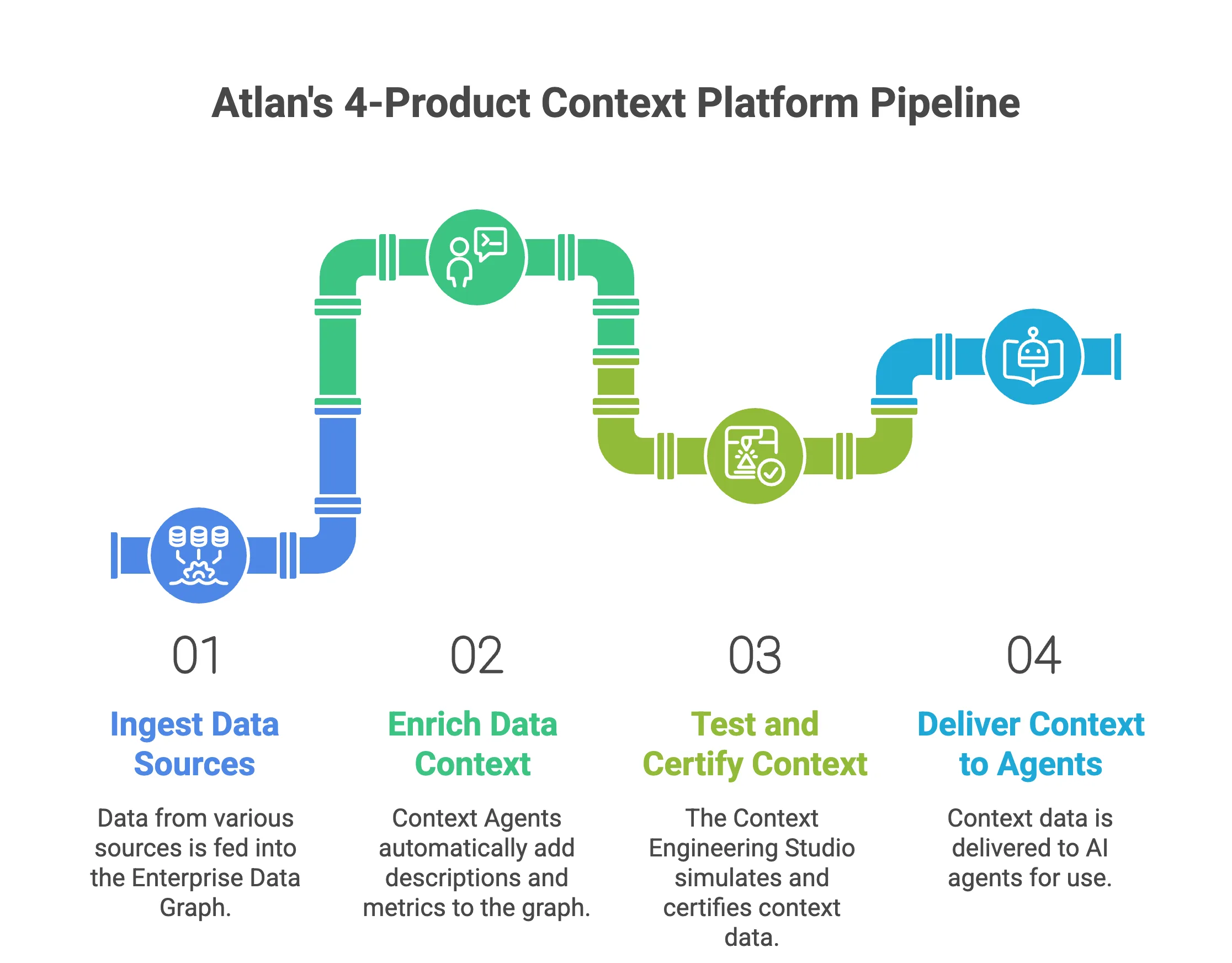
| Atlan Enterprise Data Graph | Enterprise AI context delivery: certified, explainable context for any agent fleet | 4-product platform: Enterprise Data Graph + Context Agents + Context Engineering Studio + Context Lakehouse; 5x accuracy improvement; MCP-native to Claude, ChatGPT, Codex, Cortex | Enterprise (custom) | Yes (native server) |
| Graphiti (Zep) | Temporal agent memory; continuously-changing facts | Bi-temporal data model; 94.8% DMR accuracy; 300ms P95 retrieval | Apache 2.0 / free | Yes (native server) |
| TrustGraph | Ontology-driven knowledge extraction; multi-cloud deploy | OntologyRAG; modular Context Cores; 40+ LLM providers | Apache 2.0 / free | Yes (native, v1.1+) |
| Neo4j GraphRAG | Multi-hop reasoning on structured relational data | ACID graph DB; explainable multi-hop chains; enterprise clustering | Community free / Enterprise | Yes (official + community) |
| Cognee | Self-improving agent memory; skill routing | ECL pipeline; self-improving feedback loop; 38+ source connectors | Free / $35–200/mo | Yes (native) |
| Microsoft GraphRAG | Global synthesis across large static document corpora | Hierarchical community detection; 86% accuracy vs. 32% vector baseline | Apache 2.0 / free (index cost $50–200) | No (community only) |
| OriginTrail DKG | Cryptographically verifiable multi-agent memory | Blockchain-backed knowledge assets; 60% faster multi-agent coordination | OSS (DKG v9) | Partial |
| Glean | Enterprise knowledge workers; org-wide context without dev setup | 100+ app connectors; ML-inferred entity + personal graphs; fully managed | SaaS (enterprise pricing) | No |
Best context graph tool for enterprise AI context delivery: Atlan
Permalink to “Best context graph tool for enterprise AI context delivery: Atlan”Atlan is not a governance tool with a context feature bolted on. It is a four-product context engineering platform — Enterprise Data Graph, Context Agents, Context Engineering Studio, and Context Lakehouse — purpose-built to give AI agents certified, explainable, enterprise-accurate context at runtime. The 5x accuracy improvement Atlan AI Labs measured is not a governance outcome; it is a context engineering outcome. Agents powered by Atlan stop hallucinating because they stop guessing.
Pros:
- 4-product context platform: Enterprise Data Graph (80+ connectors, live knowledge graph), Context Agents (auto-bootstrap ontology + descriptions + metrics), Context Engineering Studio (build, test, and ship context), Context Lakehouse (Iceberg-native context store built for AI consumption)
- Context Agents eliminate the cold-start problem: 9 AI agents auto-generate descriptions, glossary definitions, metrics, quality scores, and ontology — completing ~90% of context bootstrapping automatically, without manual documentation effort
- Atlan MCP server delivers certified context to any agent: Claude, ChatGPT, Codex, Snowflake Cortex, and Genie all query the same source of truth through one interface — one server, any agent in your fleet
- Context Engineering Studio: build versioned context repos, simulate agent queries against golden datasets with pass/fail evaluation before production, version with git controls, observe every production query as a feedback signal for improvement
- Explainable AI by design: column-level lineage means every agent answer traces back to a certified source asset through named, auditable relationships — not a black-box retrieval
- 5x accuracy improvement in agents grounded in Atlan context, per Atlan AI Labs — the only tool in this comparison with a published, enterprise-measured accuracy outcome
- Gartner Leader in the 2025 Metadata Management and 2026 Data and Analytics Governance Magic Quadrants; Forrester Wave leader in the 2024 Enterprise Data Catalogs and 2025 Data Governance Solutions reports
- Active metadata keeps context live: continuous sync from 80+ sources means agents never reason from stale documentation snapshots
Cons:
- Enterprise procurement process: not a weekend self-hosted setup; requires an existing data estate to connect and a team to manage context lifecycle
- Full value compounds with adoption — Context Agents bootstrap fast, but ontology quality and certification depth deepen through collaborative human review cycles
- Not the right tool for bespoke per-agent memory graph development; designed for enterprise-wide context delivery across an agent fleet, not custom graph engineering
- Higher entry cost compared to open-source alternatives
Key capabilities:
- Enterprise Data Graph: Connects 80+ data sources — warehouses, BI tools, pipelines, business systems — into one live knowledge graph with continuous event-stream updates. Every node carries business meaning, lineage, quality, and ownership in a single traversable structure.
- Context Agents: 9 specialized AI agents auto-generate descriptions, glossary terms, metrics, quality scores, and ontology at scale — solving the cold-start problem that blocks most enterprise context engineering deployments from getting off the ground.
- Context Engineering Studio: Build versioned context repos from existing data assets. Simulate agent queries against golden datasets with pass/fail evaluation before any agent touches production. A/B test context changes. Observe every production query and turn corrections into context updates automatically.
- Context Lakehouse: The world’s first context store engineered natively for AI — Iceberg-native, open formats, graph+file architecture, vector-native search. Serves certified context to any agent via the Atlan MCP server at inference time.
- Multi-agent coordination: All agents — Claude, ChatGPT, Codex, Snowflake Cortex, Genie — query the same certified context layer through one interface. No siloed per-agent memory stores, no conflicting definitions across the fleet.
- Real proof at scale: Workday used Atlan’s MCP server to expose a shared business language to AI agents, resolving definitional ambiguity that had blocked production deployment. Mastercard, with 100M+ data assets, runs under a “context by design” philosophy — context embedded at asset-creation time so agents reason at transaction speed.
Standout features:
- Context Agents auto-bootstrap: ~90% of ontology, descriptions, and metric definitions generated automatically — no other tool in this comparison eliminates cold-start at this scale
- Context Engineering Studio simulation testing: evaluate context against real business questions before any agent reaches production — a QA gate unique in this comparison
- Explainable by lineage: every agent answer traces through named, column-level relationships to certified source assets
- Context Lakehouse: the first context store in the market engineered natively for AI — Iceberg-native, open formats, vector-native search
Best for: Enterprise teams deploying AI agents across complex, multi-system data estates where accuracy and explainability are non-negotiable. Organizations with 50+ agents, 80+ data sources, and a need for one certified version of truth across the entire fleet. Any context deployment where “why did the agent say that?” will be asked by a business user, an analyst, or an auditor.
Not ideal for: Solo developers building a custom per-agent memory graph; early-stage teams without an existing data estate to connect.
| Feature | Capability |
|---|---|
| MCP support | Yes (native server — Claude, ChatGPT, Codex, Cortex, Genie) |
| Temporal awareness | Yes: active metadata event streams, continuously synced |
| Lineage & explainability | Yes (full): column-level lineage, certification propagation, audit trail |
| Certified context | Yes: domain-reviewed, with downstream propagation on certification change |
| Cold-start bootstrapping | Yes: Context Agents auto-generate ~90% of ontology + descriptions |
| Simulation testing | Yes: Context Engineering Studio pass/fail eval before production |
| Enterprise scale | Yes: 80+ connectors, RBAC, SSO, multi-agent fleet support |
| Multi-agent support | Yes: all agents share one certified context layer via MCP |
| Open source | No (Enterprise SaaS) |
Pricing: Enterprise (custom). No self-serve pricing tier.
Official URL: atlan.com
Best context graph tool for temporal agent memory: Graphiti (Zep)
Permalink to “Best context graph tool for temporal agent memory: Graphiti (Zep)”Graphiti is the strongest open-source option for agents that need to track how facts evolve over time. Its bi-temporal data model, tracking both when events happened and when the system learned about them, delivers 94.8% DMR benchmark accuracy and 300ms P95 retrieval latency, with zero data deletion: facts are invalidated, not erased.
Pros:
- Bi-temporal data model: event time and ingestion time tracked for every fact, unique in open-source context graph tools
- 94.8% DMR benchmark accuracy; 300ms P95 retrieval latency; 18.5% accuracy improvement on LongMemEval according to Zep’s published benchmarks
- 26,000+ GitHub stars (as of 2026): one of the most widely adopted context graph frameworks in open source
- Hybrid search: semantic + BM25 keyword + graph traversal in a single sub-second query
- Full MCP server implementation: Claude, Cursor, and other agents query temporal graphs via standard protocol
- Multiple graph backends: Neo4j, FalkorDB, Kuzu, Amazon Neptune
- Peer-reviewed architecture published on arXiv (paper 2501.13956)
Cons:
- Memory/context layer, not an enterprise data governance system: no certification, lineage, or audit trails
- No connectors to enterprise data stack (warehouses, BI tools, data catalogs)
- Self-improving governance requires Zep (enterprise tier), which adds dashboards but remains developer-first
- Not designed for “what’s certified and trustworthy?”: designed for “what’s current and relevant?”
Key capabilities:
Graphiti builds a continuously-evolving knowledge graph where every fact carries two timestamps: when the event happened in the world (event time) and when Graphiti’s system learned about it (ingestion time). Facts are never deleted; they receive validity windows, making every historical state queryable. The graph updates incrementally without full recomputation, supporting real-time streaming of new information. Entity resolution tracks the same entity across unstructured conversations and structured business records. Episode provenance links every derived fact to its raw source.
Standout features:
- Bi-temporal model that preserves full history without data deletion: no other open-source tool in this comparison matches this
- Episode provenance: every fact traces to its raw source document or conversation turn
- Incremental updates: new information streams in without rebuilding the graph
Best for: Developers building agent memory systems where facts evolve rapidly: CRM agents, compliance monitoring, healthcare record tracking. Teams that need production-grade context graphs on an open-source budget.
Not ideal for: Enterprises that need governance, certification, and lineage baked in; teams without infrastructure capacity to self-host.
| Feature | Capability |
|---|---|
| MCP support | Yes (native server) |
| Temporal awareness | Yes (bi-temporal): event time + ingestion time; validity windows |
| Lineage & governance | No |
| Enterprise scale | Partial: Zep adds enterprise tier; core library is developer-first |
| Multi-agent support | Yes: shared graph across agents |
| Open source | Yes (Apache 2.0) |
Pricing: Free (self-hosted open source). Zep enterprise: contact for pricing.
Official URL: getzep.com | GitHub: github.com/getzep/graphiti (26K+ stars)
Best context graph tool for ontology-driven knowledge extraction: TrustGraph
Permalink to “Best context graph tool for ontology-driven knowledge extraction: TrustGraph”TrustGraph bills itself as the “Context Operating System for AI” and delivers on it with OntologyRAG, a methodology that uses formal ontologies to guide knowledge extraction rather than pulling unstructured chunks. Open source (Apache 2.0), MCP-native since v1.1, and deployable on-premise, it is the strongest choice for teams with domain-specific ontology requirements.
Pros:
- OntologyRAG methodology: domain-specific ontologies guide extraction, not generic LLM chunking
- Context Cores: modular, versioned, reusable context packages that load and remove dynamically at runtime
- 40+ LLM provider support (Anthropic, OpenAI, Google VertexAI, AWS Bedrock, and others)
- Full MCP integration (v1.1+): agents connect to any MCP-compliant tool or service
- Multiple graph store backends: Neo4j, Apache Cassandra, Memgraph, FalkorDB
- Multi-tenancy: isolated namespaces with RBAC and SSO
- Data sovereignty: on-premise and private cloud deployment options
Cons:
- Ontology engineering prerequisite: teams without ontology expertise face a steep initial setup curve
- Smaller community than Graphiti or Neo4j, meaning fewer community resources and integrations
- No enterprise governance features: no lineage, no certification layer, no audit trail
- No temporal tracking at the data model level
Key capabilities:
TrustGraph automates context graph construction from PDFs, databases, APIs, and unstructured data using OntologyRAG, where formal ontologies define the entity types and relationship patterns the LLM extracts, rather than leaving structure to chance. The result is a knowledge graph that is domain-consistent by construction. Context Cores package this graph into versioned, reusable modules that agents can dynamically load or discard at runtime, enabling contextual switching without rebuilding the entire graph. TrustGraph ships with 3D GraphViz visualization, Prometheus/Grafana observability, Docker single-command setup, and vector store support via Qdrant (default), Pinecone, or Milvus.
Standout features:
- Context Cores architecture: context as modular, versioned packages; the only tool in this comparison with this pattern
- 3D interactive graph visualization for exploring knowledge structure
- Data sovereignty controls for private cloud and on-premise deployment
Best for: Teams that need domain-specific ontology modeling (legal, life sciences, financial compliance). Organizations with private cloud requirements. Multi-cloud deployments where data sovereignty is non-negotiable.
Not ideal for: Teams without ontology expertise; organizations that need temporal tracking or governance features out of the box.
| Feature | Capability |
|---|---|
| MCP support | Yes (native, v1.1+) |
| Temporal awareness | No |
| Lineage & governance | No |
| Enterprise scale | Yes: multi-tenant RBAC, SSO, observability, on-prem |
| Multi-agent support | Yes: Context Cores enable modular agent context switching |
| Open source | Yes (Apache 2.0) |
Pricing: Free (open source, self-hosted).
Official URL: trustgraph.ai | GitHub: github.com/trustgraph-ai/trustgraph
Best context graph tool for multi-hop relational reasoning: Neo4j GraphRAG
Permalink to “Best context graph tool for multi-hop relational reasoning: Neo4j GraphRAG”Neo4j GraphRAG extends the market-leading enterprise graph database with AI-powered retrieval, combining ACID transactions, multi-hop Cypher reasoning, and native vector search in one system. With an official MCP server and a GraphRAG toolkit actively maintained on GitHub, it is the most mature choice for teams that need explainable multi-hop relational reasoning at enterprise scale.
Pros:
- Market-leading graph database infrastructure: ACID transactions, production-scale support for nodes and relationships at enterprise volumes
- Multi-hop reasoning follows chains of named entity relationships, making every answer traceable
- Official Neo4j MCP server (STDIO + HTTP); community mcp-neo4j-graphrag server exposing vector search, fulltext search, and Cypher queries
- Native vector index (since v5.11): hybrid graph and vector search in one query
- Enterprise features: clustering, RBAC, audit logging, multi-datacenter replication
- GraphAcademy: free educational certifications and courses
- Integration with LangChain, LlamaIndex, Google MCP Toolbox for Databases
Cons:
- Indexing is expensive for large corpora and requires schema design investment upfront
- Not purpose-built for agent memory: temporal tracking requires custom implementation
- Database-level governance (RBAC, audit logging) is strong, but no data-governance layer: no column-level lineage, no certification propagation across connected assets
- Requires Cypher query expertise; steeper learning curve than developer-first tools
Key capabilities:
Neo4j GraphRAG layers AI-powered retrieval over the Neo4j graph database, the industry standard for relational graph storage. The pipeline extracts entities and relationships from source documents, maps them to graph nodes and edges, and then supports both local search (specific entity neighborhood traversal) and global search (community-based summarization across the whole graph). Every answer can be traced through named entity relationships; this explainability is Neo4j’s strongest differentiator. The enterprise edition adds clustering, role-based access, audit logging, and multi-datacenter replication. The official MCP server makes Neo4j graph queries accessible to any MCP-compatible agent.
Standout features:
- Full graph database infrastructure: not a wrapper, an actual enterprise graph database at the core
- Explainable multi-hop reasoning: every agent answer can trace its path through named relationships via Cypher
- GraphAcademy certifications provide team-level organizational learning
Best for: Teams already operating in the Neo4j ecosystem; applications where multi-hop relational reasoning is the core value (fraud detection, supply chain, knowledge management). Structured data with known schemas.
Not ideal for: Real-time streaming updates with no batch indexing time; teams without Cypher expertise; use cases where governance lineage is a first-class requirement.
| Feature | Capability |
|---|---|
| MCP support | Yes (official + community) |
| Temporal awareness | Limited: custom implementation required |
| Lineage & governance | Limited (graph-level): RBAC and audit logging at DB level |
| Enterprise scale | Yes: enterprise edition: clustering, replication, RBAC |
| Multi-agent support | Yes: shared graph database; concurrent agent access |
| Open source | Yes (community Apache 2.0); enterprise is paid |
Pricing: Community edition free. Enterprise edition: contact Neo4j for pricing.
Official URL: neo4j.com | GitHub: github.com/neo4j/neo4j-graphrag-python
Build Your AI Context Stack
Get the blueprint for implementing context graphs across your enterprise. This guide walks through the four-layer architecture, from metadata foundation to agent orchestration, with practical implementation steps for 2026.
Get the Stack GuideBest context graph tool for self-improving agent memory: Cognee
Permalink to “Best context graph tool for self-improving agent memory: Cognee”Cognee is the only context graph tool in this comparison where the graph actively improves itself; its feedback loop refines edge weights based on rated responses, making memory sharper with production use. With native MCP support, 17.1K GitHub stars, and a $35/month entry point, it is the most accessible self-improving option in the market.
Pros:
- Self-improving memory: feedback loops refine edge weights based on rated agent responses, meaning memory improves with use
- ECL pipeline (Extract, Cognify, Load): 38+ source connectors including Snowflake, PostgreSQL, PDFs, Slack, and APIs
- Skill routing: agent skills become knowledge graph nodes routed by semantic similarity and historical success rate
- Native MCP server: Claude Code, LangGraph, Cursor, CrewAI, and others connect natively
- Cross-session persistence
- Real-world enterprise deployments in scientific research (Bayer) and education (Knowunity) per Cognee’s case studies
Cons:
- Document limits on cloud tiers: 1,000 docs at $35/month, 2,500 docs at $200/month, which constrains large enterprise deployments
- Self-improving feedback loop requires production volume before meaningful improvement; it does not sharpen on day one
- No enterprise data governance: no lineage, no certification layer, no audit trail
- Smaller community than Graphiti or Neo4j
Key capabilities:
Cognee’s six-stage Cognify pipeline classifies incoming data, checks permissions, extracts chunks, runs LLM-based entity and relationship extraction, summarizes, and then embeds and commits to the knowledge graph. Auto-extracted ontologies and managed world models mean teams do not define schema upfront; structure emerges from data. The feedback loop is the distinctive mechanic: as agents use the graph and responses get rated, edge weights between nodes shift, making frequently-correct context paths stronger over time. Skill routing extends this by treating agent skills as graph nodes, routing by semantic similarity and historical success when an agent asks which tool to use for a task.
Standout features:
- Self-improving edge weight feedback loop: unique in this comparison
- Skill routing architecture: agent capabilities embedded in the knowledge graph
- Managed world models that auto-extract ontologies without upfront schema design
Best for: Developer teams building research or domain-specific agent memory that improves with use. Organizations with structured skill-routing requirements. Startups and SMBs with under 2,500 documents per deployment tier.
Not ideal for: Enterprises needing lineage, certification, or audit trail governance; organizations with massive document corpora on cloud tiers.
| Feature | Capability |
|---|---|
| MCP support | Yes (native) |
| Temporal awareness | Limited: feedback loop refines weights but no bi-temporal tracking |
| Lineage & governance | No |
| Enterprise scale | Limited: cloud tiers cap at 2,500 docs; enterprise custom available |
| Multi-agent support | Yes: skill routing; cross-session persistence |
| Open source | Yes (OSS + paid) |
Pricing: Free (local OSS). Developer: $35/month (1,000 docs). Cloud/Team: $200/month (2,500 docs, 10 users). Enterprise: custom.
Official URL: cognee.ai | GitHub: github.com/topoteretes/cognee (17.1K+ stars)
Best context graph tool for large-document synthesis: Microsoft GraphRAG
Permalink to “Best context graph tool for large-document synthesis: Microsoft GraphRAG”Microsoft GraphRAG’s hierarchical community detection enables global synthesis queries, asking “what are the themes across our entire regulatory library?”, that no other tool in this comparison can answer at scale. According to Microsoft’s own benchmark published on microsoft.github.io/graphrag, it delivers 86% accuracy versus a 32% vector RAG baseline on their enterprise evaluation, but standard indexing costs $50–200 per corpus.
Pros:
- Hierarchical community detection (Leiden algorithm): groups related entities and pre-generates summaries at multiple hierarchy levels
- Global synthesis queries: the only tool here that synthesizes themes across an entire document corpus in one query
- 86% accuracy on Microsoft’s enterprise benchmark vs. 32% for vector RAG baseline (+54 points)
- LazyGraphRAG variant: cuts indexing cost to 0.1% of standard GraphRAG; 700x lower query cost for global queries
- 31.6K+ GitHub stars as of 2026; used in research and scientific knowledge management
Cons:
- Very high indexing cost: $50–200 per corpus (standard version); 10–40x more expensive than vector RAG indexing
- Not production-supported by Microsoft; a research project that teams must wrap with their own engineering support
- No incremental updates: batch indexing only; not suitable for real-time or continuously-changing data
- No native MCP server: community integrations only
- Single-hop fact retrieval underperforms vector RAG on direct factual queries; best reserved for global synthesis workloads where its community detection approach excels
- Entity recognition accuracy varies significantly by domain; validate against your own corpus before committing
Key capabilities:
Microsoft GraphRAG runs a full pipeline: text extraction, LLM-based entity and relationship extraction, graph construction, Leiden community detection, multi-level community summarization, and search index. The community hierarchy is what makes global synthesis possible; rather than retrieving a chunk that is semantically similar, GraphRAG retrieves the pre-generated summary of the entire community of related entities and their relationships. Two search modes exist: local (specific entity neighborhood) and global (aggregates across community summaries). LazyGraphRAG (released late 2024) reduces indexing cost to 0.1% of full GraphRAG by deferring community summarization until query time. Available as a component in Microsoft Azure AI Foundry.
Standout features:
- Global synthesis: the only tool that pre-generates hierarchical community summaries for organization-wide queries
- LazyGraphRAG: 700x lower query cost compared to standard GraphRAG for global queries
- Azure AI Foundry integration for teams already in the Microsoft ecosystem
Best for: Regulatory libraries, technical manuals, research paper collections where “what are the themes?” is more important than “what does this specific document say?” Teams in the Microsoft Azure ecosystem. Organizations willing to pay the indexing cost for periodically-updated static corpora.
Not ideal for: Real-time data; single-hop fact retrieval; teams outside Azure; any use case requiring production support SLA.
| Feature | Capability |
|---|---|
| MCP support | No (community only) |
| Temporal awareness | No: batch indexing only |
| Lineage & governance | No |
| Enterprise scale | Limited: research project; not production-supported |
| Multi-agent support | Limited: static index; not designed for concurrent agent writes |
| Open source | Yes (Apache 2.0) |
Pricing: Free (open source, self-hosted). Indexing cost: $50–200 per corpus (standard) or approximately $0.07–0.20 per corpus (LazyGraphRAG).
Official URL: microsoft.github.io/graphrag | GitHub: github.com/microsoft/graphrag (31.6K+ stars)
Best context graph tool for cryptographic verifiability: OriginTrail DKG
Permalink to “Best context graph tool for cryptographic verifiability: OriginTrail DKG”OriginTrail’s Decentralized Knowledge Graph is the only tool here where trust is cryptographically enforced; every knowledge asset carries a blockchain-backed proof of origin, integrity, and approval history. According to OriginTrail’s published performance data, DKG delivers 60% faster multi-agent task completion and 40% lower token cost versus siloed agent memory for multi-agent coordination scenarios.
Pros:
- Cryptographically verifiable knowledge assets: every fact carries a blockchain-backed proof of origin and integrity
- Decision lineage: captures not just what happened but who approved it, under what policy, with what precedent
- Tiered memory architecture: Working Memory, Shared Working Memory, Long-term Memory, and Verified Memory (consensus-confirmed)
- 60% faster wall-clock multi-agent task completion vs. siloed agent memory; 40% lower token cost
- Sub-graphs for specialization: Code, Decisions, Sessions, Tasks, GitHub graphs
- dRAG (Q1 2026): agents query verified data through staked nodes
Cons:
- Significant architectural complexity: blockchain substrate adds latency and operational overhead
- Requires crypto/Web3 familiarity, which is unusual for standard enterprise IT procurement
- No enterprise data connectors to warehouses or BI tools
- Not appropriate for standard enterprise technology evaluation processes
- MCP support not documented as a native first-class feature
Key capabilities:
OriginTrail DKG operates a three-layer architecture: a trust layer (blockchain consensus for provenance and integrity), a knowledge base layer (peer-to-peer knowledge graph network of DKG Core Nodes), and a verifiable AI layer (agents and systems using both). Agents publish knowledge assets to the DKG, structured knowledge objects anchored to the blockchain with cryptographic proof. When multiple agents collaborate, they share a common queryable knowledge base with tiered memory: working memory for active tasks, shared working memory for agent swarms, long-term memory for persistent facts, and verified memory for consensus-confirmed decisions. The decision lineage capability records every approval, policy reference, and precedent, making agent behavior auditable at a cryptographic level.
Standout features:
- Cryptographic audit trail: every fact’s origin, integrity, and approval chain is provably verifiable; not just logged, but cryptographically enforced
- Swarm coordination: purpose-built for multi-agent architectures where multiple agents must share and trust a common context
- dRAG: decentralized retrieval-augmented generation through staked, verifiable nodes
Best for: Multi-agent coordination scenarios where context must be cryptographically verified. Organizations in regulated industries where “trust but verify” is not sufficient. Decentralized multi-organization knowledge sharing.
Not ideal for: Standard enterprise IT procurement; teams without blockchain/Web3 infrastructure experience; use cases requiring warehouse or BI tool connectors.
| Feature | Capability |
|---|---|
| MCP support | Partial: framework integrations; not a documented native MCP server |
| Temporal awareness | Yes: event and ingestion time tracked via blockchain consensus |
| Lineage & governance | Partial (cryptographic): provenance and decision lineage; not traditional data governance |
| Enterprise scale | Limited: blockchain overhead; decentralized infrastructure |
| Multi-agent support | Yes (core design): purpose-built for swarm coordination |
| Open source | Yes (OSS, DKG v9) |
Pricing: Free (open source). Blockchain infrastructure and node operation costs apply.
Official URL: origintrail.io | GitHub: github.com/OriginTrail/dkg-v9
Best context graph tool for enterprise knowledge workers: Glean
Permalink to “Best context graph tool for enterprise knowledge workers: Glean”Glean’s Enterprise Graph does not require a developer; it ML-infers entities, relationships, and personal work patterns across 100+ connected apps, automatically. The System of Context model brings AI agents enterprise-wide organizational intelligence without manual context engineering. The tradeoff: it is closed-source, SaaS-only, and not programmable as a component.
Pros:
- 100+ app connectors with permission enforcement: respects existing ACLs across all integrated systems
- ML-inferred entity graph: people, teams, projects, documents, tickets, dashboards, customers, products, all connected automatically
- Personal graphs: infers individual work patterns and task contexts across applications without manual configuration
- Fully managed, single-tenant architecture: all processing within the customer environment for data privacy
- Hybrid search: semantic + keyword + graph traversal in one query
- Dynamic evolution: graph adapts as relationships, roles, and workflows change
Cons:
- Closed-source, SaaS-only: no ability to inspect, modify, or run on custom infrastructure
- Not programmable: not a developer framework or component; requires full Glean platform adoption
- No native MCP server: context exposed through Glean’s own agent APIs, not standard MCP protocol
- No data lineage or certification layer: governance is permission-enforcement, not provenance-tracking
- Enterprise pricing with no self-serve tier
Key capabilities:
Glean’s Enterprise Graph is automatically constructed from the organizational data Glean indexes across 100+ applications; every connected app contributes entities and relationships to a unified ML-inferred graph. The graph tracks people (who works on what, what they know), teams (which team owns which systems), projects (what is in flight), documents (who created what when), and customers (which accounts relate to which internal projects). Personal graphs layer individual work pattern inference on top: Glean infers task context per user without any manual tagging. The System of Context orchestrates this graph to power agent creation; agents built on Glean automatically inherit enterprise-wide and individual-level context without bespoke integration work.
Standout features:
- Personal graph inference: Glean builds per-person context graphs automatically from observed work patterns; no other tool in this comparison does this
- 100+ connector ecosystem with ACL inheritance: the widest breadth of organizational data sources in this comparison
- No developer setup for enterprise context: the only fully managed, zero-configuration context graph option here
Best for: Enterprise knowledge workers who need AI that understands organizational context without developer setup. Organizations where “who works on what” is as important as “what is in the database.” Enterprise search and agent use cases in a fully managed platform.
Not ideal for: Teams that need custom agent memory development; organizations that require MCP compatibility for custom integrations; use cases requiring data lineage or certification-level governance.
| Feature | Capability |
|---|---|
| MCP support | No: context exposed via Glean agent APIs |
| Temporal awareness | Partial: graph evolves dynamically; no bi-temporal model |
| Lineage & governance | No: permission enforcement only; no lineage or audit trail |
| Enterprise scale | Yes: 100+ connectors; single-tenant; fully managed |
| Multi-agent support | Yes: enterprise agents powered by Enterprise and personal graph |
| Open source | No (SaaS only) |
Pricing: Enterprise (custom). No public pricing or self-serve tier.
Official URL: glean.com
The honest verdict: two clear winners by architectural role
Permalink to “The honest verdict: two clear winners by architectural role”Most context graph comparison pages rank tools on a single axis. This one doesn’t, because these tools don’t compete on a single axis.
Neo4j wins on developer ecosystem. Thirty-one thousand GitHub stars, GraphAcademy certifications, deep LangChain and LlamaIndex integrations, ACID transactions, and a decade of production graph database deployments. If your team thinks in graph schemas and can write Cypher, nothing in this list matches Neo4j’s ecosystem depth, community, or infrastructure maturity. It is the graph database the rest of this list runs on.
Atlan wins on certified, explainable context delivery at enterprise scale. The four-product platform — Enterprise Data Graph, Context Agents, Context Engineering Studio, Context Lakehouse — is the only option in this comparison built end-to-end for one outcome: giving every agent in your fleet accurate, explainable, certified enterprise context at runtime. Context Agents eliminate the cold-start problem. The Context Engineering Studio lets you test before you ship. Column-level lineage makes every answer traceable. Atlan AI Labs has measured a 5x accuracy improvement in agents grounded in this context layer. No other tool in this comparison combines context creation, certification, testing, and runtime delivery in one platform.
The remaining three in the focused matrix — Graphiti, TrustGraph, Cognee — are strong, purpose-built tools for agent memory: temporal tracking, ontology-driven extraction, and self-improving memory. They are composable layers designed to run alongside Neo4j or Atlan, not instead of them.
5-tool focused comparison: governance score, MCP, and portability
Permalink to “5-tool focused comparison: governance score, MCP, and portability”The full 8-tool reference directory is at the top of this page. This focused matrix covers the five tools most teams will shortlist. Three columns that most comparisons omit: governance score (4-point scale), portability (lock-in risk), and MCP delivery type.
| Feature | Graphiti (Zep) | Neo4j GraphRAG | TrustGraph | Cognee | Atlan |
|---|---|---|---|---|---|
| Open source | Yes (Apache 2.0) | Yes (community) | Yes (Apache 2.0) | Yes (OSS + paid) | No (Enterprise SaaS) |
| MCP support | Yes (native server) | Yes (official + community) | Yes (native, v1.1+) | Yes (native) | Yes (native server) |
| MCP delivery type | STDIO + HTTP | STDIO + HTTP | STDIO | STDIO | HTTPS (managed) |
| Temporal awareness | ✅ Bi-temporal (event + ingestion time) | ⚠️ Custom implementation required | ❌ None | ⚠️ Feedback loop only | ✅ Active metadata event streams |
| Lineage depth | ❌ None | ⚠️ DB-level only (RBAC, audit log) | ❌ None | ❌ None | ✅ Column-level, full |
| Certification propagation | ❌ | ❌ | ❌ | ❌ | ✅ Downstream auto-propagation |
| PII / data classification | ❌ | ❌ | ❌ | ❌ | ✅ Native |
| Audit trail (agent-consumed context) | ❌ | ⚠️ DB audit log only | ❌ | ❌ | ✅ Structured, queryable |
| Governance score | 0 / 4 | 1 / 4 | 0 / 4 | 0 / 4 | 4 / 4 |
| Portability | High | Medium | High | Medium | Low |
| Portability detail | 4 graph backends; Apache 2.0; full self-host | Community free; Cypher proprietary; Enterprise lock-in | 5 graph backends; Apache 2.0; on-prem options | OSS core; cloud tiers cap at 2,500 docs | Enterprise SaaS; no self-host option |
| Enterprise scale | Partial (Zep adds enterprise tier) | Yes (enterprise edition) | Yes (RBAC, SSO, multi-tenant) | Limited ($200/mo tier) | Yes (80+ connectors, enterprise-grade) |
| Multi-agent support | Yes (shared graph) | Yes (shared graph DB) | Yes (Context Cores) | Yes (skill routing) | Yes (shared governed context) |
| Starting cost | Free (self-host) | Free (community) | Free (self-host) | Free / $35/mo | Enterprise custom |
Governance score: 4 dimensions — lineage depth, certification propagation, data classification (PII), queryable audit trail for agent-consumed context. Score = number of dimensions present natively without custom build.
Portability: High = Apache 2.0, multiple graph backends, full self-host. Medium = community free tier but proprietary query language or cloud doc-limits. Low = SaaS-only, no self-host option.
TCO breakdown: what these tools actually cost at scale
Permalink to “TCO breakdown: what these tools actually cost at scale”“Free” is not “zero cost.” TrustGraph and Graphiti are free to download; operating them at production scale requires infrastructure, an ops team, and in TrustGraph’s case, ontology engineering expertise. Cognee’s cloud tiers cap at 2,500 documents before a custom contract is required. The honest three-row TCO for the focused five:
| Cost dimension | Graphiti (Zep) | Neo4j GraphRAG | TrustGraph | Cognee | Atlan |
|---|---|---|---|---|---|
| Setup / indexing | $0 — incremental updates, no batch indexing | $0 community; schema + Cypher design investment | $0 self-hosted; ontology engineering is the real setup cost | $0 OSS; $35/mo cloud entry | Enterprise procurement + integration sprint |
| Ongoing (per month) | $0 self-hosted; Zep enterprise: custom | $0 community; Neo4j Enterprise: custom contract | $0 self-hosted + infra cost | $35–200/mo cloud; custom enterprise | Enterprise custom contract |
| At enterprise scale | Zep enterprise + infra team to operate | Neo4j Enterprise license + DBA expertise + clustering | Infra cost + dedicated ontology engineer | Per-doc caps trigger custom tier; pricing scales | All-in contract; governance value scales with connector count |
| Hidden cost | Graph infra ops to run self-hosted | Cypher expertise + schema governance investment | Ontology engineering is a prerequisite, not optional | 2,500-doc cloud cap before custom required | Procurement timeline; requires catalog maturity to fully realize value |
How should you choose a context graph tool?
Permalink to “How should you choose a context graph tool?”Before evaluating features, ask three orienting questions: What is your team’s capacity to operate infrastructure? What failure mode are you protecting against: stale context, wrong context, or unauditable context? Do your agents need to pass a compliance audit? For a deeper look at how memory architecture choices affect these answers, see agent memory architectures. These questions will eliminate at least half the tools from your shortlist before you open a single README.
Decision framework
Permalink to “Decision framework”| If you need… | Consider… | Why |
|---|---|---|
| Temporal tracking: facts that change over time | Graphiti (Zep) | Only open-source bi-temporal data model; 94.8% DMR accuracy per Zep’s published benchmarks |
| Multi-hop relational reasoning on structured data | Neo4j GraphRAG | ACID graph DB with explainable multi-hop Cypher traversal; enterprise ecosystem |
| Global synthesis across large static document corpora | Microsoft GraphRAG | Hierarchical community detection; 86% accuracy vs. 32% vector baseline; LazyGraphRAG reduces cost |
| Self-improving agent memory with skill routing | Cognee | Feedback loop refines edge weights with use; skill routing baked into graph architecture |
| Cryptographically verifiable multi-agent coordination | OriginTrail DKG | Only tool with blockchain-backed knowledge asset provenance; 60% faster multi-agent coordination |
| Certified, explainable context for an enterprise agent fleet | Atlan | 4-product context platform; 5x accuracy improvement (AI Labs); MCP-native to Claude, ChatGPT, Codex, Cortex; Context Agents auto-bootstrap 90% of ontology |
| Org-wide agent context without developer setup | Glean | 100+ connectors, ML-inferred entity and personal graphs, fully managed: zero configuration |
| Ontology-driven extraction with custom domain modeling | TrustGraph | OntologyRAG + Context Cores; on-premise data sovereignty; 40+ LLM providers |
By team profile
Permalink to “By team profile”Individual developer or small startup: Graphiti (open source, Apache 2.0, 26K+ community), TrustGraph (if you have ontology expertise), or Cognee (if self-improving memory fits your use case). All three are free to self-host and have active communities.
Mid-market team (20–200 engineers): Neo4j GraphRAG if your data is structured and relational. Cognee ($35–200/month) if you want managed infrastructure with self-improving memory. Microsoft GraphRAG if you have a large static document corpus and Azure infrastructure.
Enterprise with governance requirements: Atlan for data and AI governance in regulated industries (financial services, healthcare, government). Glean for enterprise-wide organizational knowledge without developer configuration. OriginTrail DKG if your compliance requirement is cryptographic proof, not just an audit log.
The composability pattern: These tools are not mutually exclusive. The common production architecture uses Graphiti or TrustGraph as the agent memory layer (handling session context and temporal facts), Neo4j as the graph database backend, and Atlan as the enterprise governance overlay, certifying, classifying, and auditing what flows through the stack. Choosing one tool does not preclude the others; choosing the wrong governance architecture does.
The pattern across production deployments is clear: teams that choose their context tool based on governance requirements, not benchmark scores, are the ones that avoid a six-month replatforming project when the first compliance audit arrives.
What context graph tools do not replace (the vector database reality)
Permalink to “What context graph tools do not replace (the vector database reality)”The production pattern is not “context graphs versus vector databases”; it is “vectors for semantic entry-point retrieval, graphs for relational depth and governance.” The comparison matters because many teams reach for a vector database first, hit its structural limits, and then build graph infrastructure on top.
Where vector databases break down:
1. No temporal awareness. Vector databases retrieve semantically similar chunks regardless of when they were true. A policy document from 2024 that has been superseded in 2026 will still surface in vector retrieval. Graphiti and Atlan invalidate stale facts; pgvector does not.
2. No multi-hop reasoning. Vector search answers “what’s similar?” Context graph tools answer “what’s connected to what, and through which relationship?” Fraud detection that needs to trace a transaction through four intermediary entities requires graph traversal, not cosine similarity.
3. No lineage or certification. Every vector query is a trust-the-embedding operation. There is no concept of certification status, audit trail, or downstream propagation of a data quality event. Atlan’s column-level lineage does this; no vector database does.
4. Coordination failures at scale. Fifty agents querying a vector database with different chunking configurations and different embedding models will return inconsistent context. A shared context graph ensures every agent works from the same governed, current state.
By early 2026, production teams have converged on vector stores as semantic entry points (fast similarity retrieval at low cost) with context graph tools handling the relational, temporal, and governance layer. The choice is not either/or; it is where in your stack each tool lives. For a deeper comparison, see context graph vs. vector database for AI agents.
The teams that treat context graphs and vector databases as competitors end up rebuilding their retrieval layer twice: once when they outgrow vectors, and again when compliance asks for an audit trail the vector store was never designed to produce.
Real stories from real customers: governance at enterprise scale
Permalink to “Real stories from real customers: governance at enterprise scale”"We're excited to build the future of AI governance with Atlan. All of the work that we did to get to a shared language at Workday can be leveraged by AI via Atlan's MCP server…as part of Atlan's AI Labs, we're co-building the semantic layer that AI needs with new constructs, like context products."
— Joe DosSantos, VP of Enterprise Data & Analytics, Workday
"Atlan is much more than a catalog of catalogs. It's more of a context operating system…Atlan enabled us to easily activate metadata for everything from discovery in the marketplace to AI governance to data quality to an MCP server delivering context to AI models."
— Sridher Arumugham, Chief Data & Analytics Officer, DigiKey
Why governance readiness is the missing criterion in context graph tool selection
Permalink to “Why governance readiness is the missing criterion in context graph tool selection”Six of the eight tools in this comparison have no native enterprise governance layer. This is not a flaw; it is a deliberate design choice. Developer-first tools (Graphiti, TrustGraph, Cognee) are context and memory layers, not governance platforms. They are composable: teams can and do run Graphiti as the agent memory layer with Atlan as the governance layer on top. Neo4j provides meaningful infrastructure-level governance (RBAC, audit logging, ACID transactions) that exceeds most open-source alternatives; it simply is not a data governance platform.
The gap emerges when these tools reach regulated enterprise production without a governance layer on top: who certifies the context an agent consumed? What changes when the source dataset is deprecated? Which agent acted on which version of the context, and when?
What governance readiness means in context graph terms:
Lineage: not just “where did this come from” but “what downstream assets and agents depend on this, and what happens to them when it changes.” Column-level lineage that propagates a certification failure downstream is a different capability than logging which table was queried.
Certification: a formal signal, not a tag, that a piece of context has been reviewed and approved for use by agents. Certification that propagates automatically when the underlying asset changes is rarer still.
Classification: PII, sensitivity, and data type labels that propagate through the graph and enforce access controls at the context level. An AI agent that surfaces HIPAA-regulated context to an unauthorized user has a lineage problem, a classification problem, and a governance problem simultaneously.
Audit trail: a queryable record of which agent consumed which context at what time, against what certification status. Not just a log file; a structured, attributable record that a compliance team can query.
Three governance models appear in this comparison: Atlan provides full enterprise data governance (lineage, certification, classification, audit trail) as its core architecture. OriginTrail DKG provides cryptographic provenance that is verifiable and immutable but operates differently from traditional enterprise data governance. Neo4j provides infrastructure-level governance (RBAC, ACID, audit logging) that is strong at the database layer but does not propagate certification or lineage across connected data assets. Developer-first tools (Graphiti, TrustGraph, Cognee, MS GraphRAG) provide none by design; they are composable layers that teams govern externally via an AI agent governance layer.
The governance gap is why enterprises in financial services, healthcare, and government cannot simply pick the highest-starred GitHub repository and call it their context layer. For regulated enterprises, governance readiness is the fifth axis, and it determines whether your choice is composable-and-build versus managed-and-governed, not just which tool has the best benchmark.
The enterprise context layer is not a feature you add to a developer tool; it is an architectural decision you make before the first agent ships. Teams that discover this after deployment face not just a replatforming cost but a retroactive audit gap that no context graph can close after the fact.
FAQs about context graph tools
Permalink to “FAQs about context graph tools”1. What is a context graph tool?
A context graph tool builds and serves a graph-structured knowledge layer that AI agents query at runtime. Unlike a vector database, which retrieves semantically similar chunks, a context graph preserves entity relationships, temporal history, and governance context. The result is agents that can reason about how facts connect and how they have changed, not just which chunk is most similar to a query.
2. What is the difference between a context graph and a knowledge graph?
Context graphs and knowledge graphs share the same graph data structure but serve different architectural roles. Knowledge graphs organize facts about a domain for human consumption; they are reference systems. Context graphs serve as the runtime delivery layer for AI agents; they must be current, queryable, and often governed. Every context graph is a knowledge graph; not every knowledge graph is suitable as a production context graph.
3. Which context graph tool has MCP support?
Five of the eight tools in this comparison support MCP natively: Atlan, Graphiti, TrustGraph, Neo4j GraphRAG (official and community), and Cognee. Microsoft GraphRAG has community MCP integrations but no official server. OriginTrail DKG has partial support through framework integrations. Glean does not have a documented MCP server.
4. Which context graph tool is the best for open-source teams?
Graphiti (Zep) is the strongest open-source option: 26,000+ GitHub stars, Apache 2.0 license, bi-temporal data model, 94.8% DMR accuracy per Zep’s published benchmarks at github.com/getzep/graphiti, and full MCP server support. TrustGraph is the best open-source choice for teams with ontology expertise and domain-specific extraction requirements. Cognee’s OSS tier is free but the self-improving feedback loop requires production volume to activate meaningfully.
5. How much does Microsoft GraphRAG cost?
The Microsoft GraphRAG library is open source and free to download. The real cost is indexing: standard GraphRAG costs approximately $50–200 per corpus (depending on size and LLM pricing) because it runs LLM-based entity extraction and community summarization across every document. LazyGraphRAG reduces this to approximately 0.1% of the full cost by deferring community summarization until query time. Microsoft does not provide enterprise support for GraphRAG; it is a research project.
6. Does Graphiti replace a vector database?
No. Graphiti uses vector embeddings internally as part of its hybrid retrieval: semantic embeddings + BM25 keyword + graph traversal in one query. The vector component handles semantic similarity matching; the graph component handles temporal validity and relationship traversal. Graphiti replaces the need for a standalone vector database in agent memory architectures, but it uses vector search internally. The correct mental model: Graphiti is a context graph that incorporates vector search, not an alternative to it.
7. What context graph tool works best for regulated industries?
Atlan is the designed choice for regulated industries: financial services, healthcare, and government. Column-level lineage, data classification (PII, sensitivity), certifications, audit trails, and active metadata propagation are all native. It is a Gartner Leader in both Metadata Management (2025) and Data and Analytics Governance (2026). OriginTrail DKG is relevant for use cases where cryptographic proof of context provenance is a compliance requirement, but it requires blockchain infrastructure expertise.
8. Can I use multiple context graph tools together?
Yes, and production architectures increasingly do. The common pattern is layered: Graphiti or TrustGraph for agent memory (temporal facts, session context), Neo4j as the graph database backend, and Atlan as the enterprise governance layer that certifies and classifies the context assets. Tools in this space compose rather than compete. The exception is fully-managed platforms (Glean, Atlan enterprise), which are integrated systems designed to be the entire context layer rather than components in a stack.
9. What is the governance gap in context graph tools?
Six of the eight tools evaluated have no built-in governance layer: no lineage, no certification, no audit trail. This is a design choice for developer-first tools (Graphiti, TrustGraph, Cognee, MS GraphRAG), which expect teams to build governance on top. The governance gap becomes a production blocker when enterprises need to answer: which agent consumed which version of this context, against what certification status? Only Atlan addresses this natively in this comparison.
10. How do context graph tools differ from context stores?
A context store is any persistence layer that holds context for agents; it can be as simple as a JSON file or a key-value cache. A context graph is a specific, connected implementation: entities and relationships stored in a graph structure that supports traversal, temporal tracking, and (in some tools) governance. Every context graph is a context store, but a context store that lacks relational structure, temporal awareness, and governance is not a context graph. For a detailed comparison, see the context graph vs. context store guide.
Sources
Permalink to “Sources”- Graphiti: A Temporally-Aware Knowledge Graph for LLM Agent Memory, arXiv
- Graphiti GitHub repository (26K+ stars), Zep
- Microsoft GraphRAG: Unlocking Global Synthesis, Microsoft Research
- Microsoft GraphRAG GitHub repository (31.6K+ stars), Microsoft
- Cognee GitHub repository (17.1K+ stars), Topoteretes
- From AI Memory Silos to Multi-Agent Memory, OriginTrail
- The Next Big Shift in AI Agents: Shared Context Graphs, OriginTrail
- TrustGraph: MCP Integration Guide, TrustGraph
- Neo4j MCP Server, Neo4j Developer
- Glean Enterprise Graph, Glean
- Open Source Context Graph Tools Compared, contextgraph.tech
- Atlan Enterprise Data Graph, Atlan
- Graph RAG vs Vector RAG: Agent Memory, Neo4j, pgvector, AgentMarketCap
