



















Before MCP, every AI model that needed to access a new data source required a custom integration: built once, for one model, and maintained forever. Multiply that across 10 models and 20 data sources and you have 200 custom connectors, each with its own auth logic, error handling, and drift risk. Atlan’s MCP server exposes the Enterprise Data Graph, verified ownership, lineage, business definitions, and access policy, to any MCP-compatible AI runtime, so the same governed context layer serves Claude, Cursor, Databricks, and Snowflake Cortex through a single interface without custom integration per tool.
MCP (Model Context Protocol) collapses that N×M matrix to N + M: each AI client implements MCP once, each data source implements MCP once, and any client can reach any server.
Here is what makes MCP worth understanding in 2026:
- Rapid adoption across major AI tools: Claude (native), OpenAI (March 2025), Google (March 2026), VS Code, Cursor, JetBrains, Windsurf, Vercel AI SDK. The major AI development platforms all support MCP natively.
- 970x SDK growth: Monthly SDK downloads went from ~100,000 in November 2024 to 97 million in March 2026 according to the official MCP anniversary report, reflecting developer adoption of the standard.
- Open governance: In December 2025, Anthropic donated MCP to the Agentic AI Foundation (AAIF) under the Linux Foundation, giving it the same neutral governance model as Kubernetes and Linux.
- 17,000+ servers indexed: An independent registry census counted 17,468 MCP servers across public registries as of Q1 2026, covering databases, file systems, CRMs, catalogs, and developer environments.
- The real bottleneck: MCP is protocol-neutral about what a server exposes. Most MCP servers expose raw data, not governed context. The protocol enables quality; it does not enforce it. That gap between connectivity and context governance is why AI agents need an enterprise context layer — and where enterprise hallucinations occur at scale.
Build Your AI Context Stack
Get the blueprint for implementing context graphs across your enterprise. This guide walks through the four-layer architecture, from metadata foundation to agent orchestration, with practical implementation steps for 2026.
Get the Stack GuideWhat is MCP?
Permalink to “What is MCP?”MCP, which stands for Model Context Protocol, is an open standard for connecting AI applications to external data sources, tools, and workflows. The official analogy is apt: MCP is to AI agents what USB-C is to devices. Before USB-C, connecting a device to a laptop required different cables for different ports. Before MCP, connecting an AI agent to a new data source required a different custom integration every time.
The protocol was created at Anthropic by David Soria Parra and Justin Spahr-Summers and announced on November 25, 2024. The motivation was explicit: AI models were “trapped behind information silos and legacy systems.” The N×M integration problem, where N AI models each requiring custom code to reach M data sources creates N×M unique connectors, was making AI development brittle and expensive to scale.
MCP collapses that to N + M. Each side implements the protocol once. Any MCP-compatible AI client can reach any MCP-compatible server, without additional integration work. This matters especially for autonomous agents that need to reach many systems independently.
The speed of industry adoption reflects how badly that problem needed solving. OpenAI adopted MCP in March 2025. Google Gemini and Vertex AI Agent Builder followed in March 2026 alongside the Google A2A protocol for agent interoperability. VS Code, Cursor, JetBrains AI Assistant, Windsurf, and Hugging Face all support it natively. From 100,000 monthly SDK downloads at launch to 97 million in March 2026, the protocol’s adoption curve is one of the fastest in developer infrastructure history.
In December 2025, Anthropic took the step that transformed MCP from a vendor project into genuine open infrastructure: it was donated to the Agentic AI Foundation (AAIF), a directed fund under the Linux Foundation, co-founded by Anthropic, Block, and OpenAI. MCP now has the same governance model as Kubernetes and Linux: neutral, community-driven, and not controlled by any single vendor.
For teams building on the enterprise context layer, MCP represents the connectivity tier: the standardized channel through which AI agents reach the governed data context that makes their answers reliable. Understanding the protocol is the first step to understanding what MCP cannot do alone.
Quick facts
Permalink to “Quick facts”| What it is | Open standard for connecting AI agents to external systems |
|---|---|
| Created by | Anthropic (Nov 25, 2024), donated to Linux Foundation (Dec 2025) |
| Core architecture | Host, Client, and Server layers communicating via JSON-RPC 2.0 |
| Three primitives | Tools (actions), Resources (data), Prompts (templates) |
| Adoption | 17,000+ servers, 97M monthly SDK downloads, OpenAI + Google + Microsoft support |
| Transport options | stdio (local), Streamable HTTP (remote, OAuth 2.0) |
| Enterprise reach | 78% of enterprise AI teams report at least one MCP-backed agent in production, per an April 2026 survey |
How MCP works: architecture and primitives
Permalink to “How MCP works: architecture and primitives”MCP uses a three-layer architecture built on JSON-RPC 2.0. Understanding the three layers (Host, Client, Server) and the three primitives those servers expose is the foundation for understanding both what MCP enables and where its limits are.
The client-host-server model
Permalink to “The client-host-server model”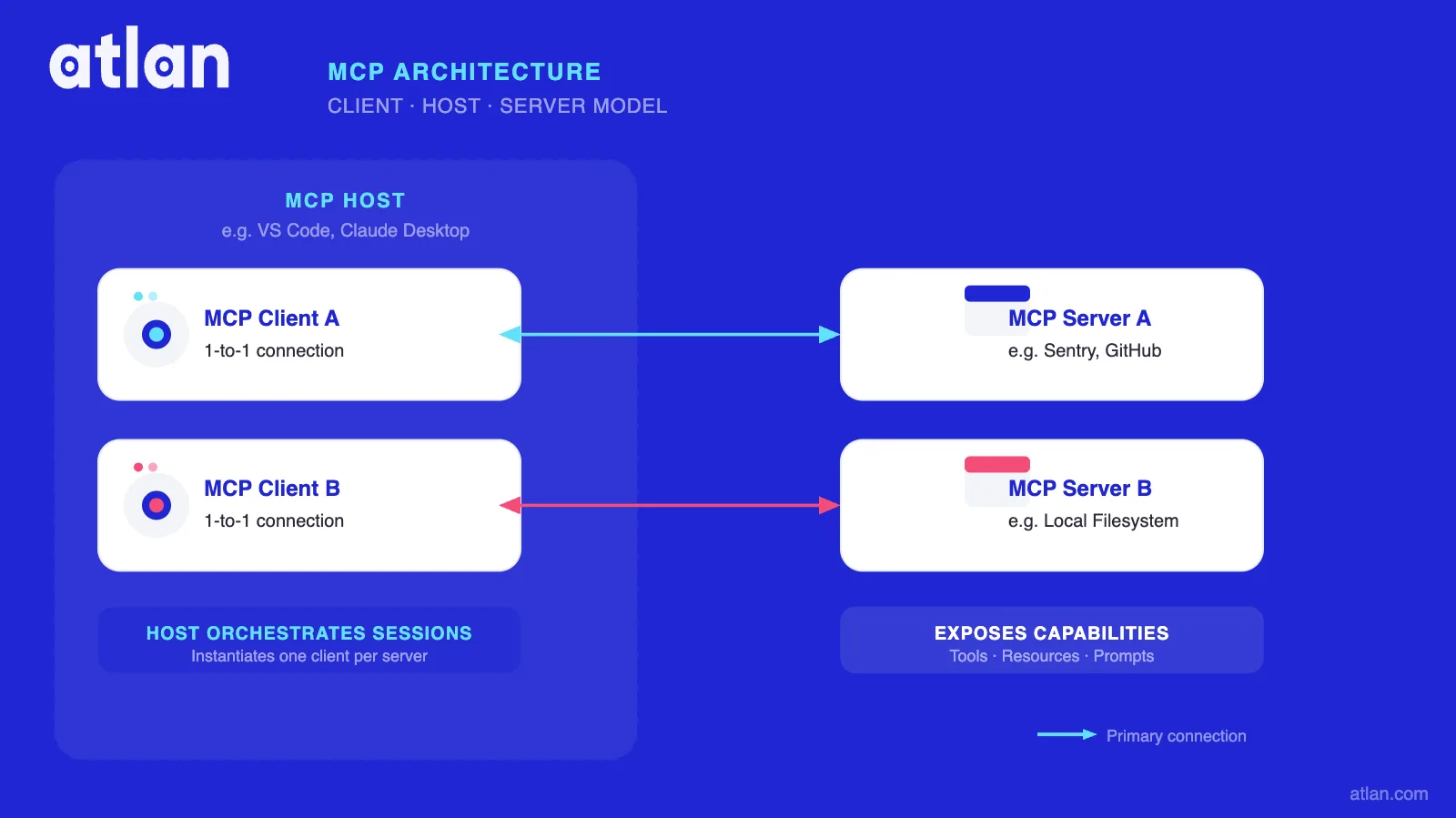
The MCP Host is the AI application the user interacts with: Claude Desktop, Claude Code, VS Code with GitHub Copilot, or Cursor. The host orchestrates sessions, manages connections, and is where the user works.
The MCP Client is a component inside the host. It maintains a dedicated one-to-one connection with a single MCP server. A host instantiates one client per server it connects to, so if VS Code connects to both a Sentry MCP server and a local filesystem server, it creates two separate client objects.
The MCP Server is a lightweight program that exposes specific capabilities to clients. Servers can run locally (same machine, via stdio) or remotely (cloud-hosted, via Streamable HTTP). The server does not need to know anything about the AI model it’s serving; it exposes its capabilities via the protocol, and the host decides how to use them.
This separation is what gives MCP its portability. The same MCP server for PostgreSQL works identically whether the client is Claude, ChatGPT, or Cursor. For MCP server implementation patterns, the host-client-server separation also means teams can build and deploy servers independently from AI client upgrades. Popular enterprise integrations include the MCP server for Snowflake, MCP server for Databricks, and MCP server for dbt.
The three MCP primitives
Permalink to “The three MCP primitives”MCP servers expose three types of capabilities to clients:
Tools are executable functions the AI can invoke: API calls, database queries, file operations, or any action the server supports. They are invoked via tools/call. The LLM selects which tool to use based on each tool’s description — this is a direct expression of LLM reasoning applied to tool selection — which means tool descriptions are effectively part of the prompt and must be written carefully.
Resources are read-only context data passed to the model as grounding information: file contents, database records, catalog entries, schema definitions. Fetched via resources/read. This is the mechanism that connects MCP to RAG-style retrieval workflows: the resource is the retrieved context passed to the model before generation. Effective context management determines what Resources carry — raw file contents and ungoverned schema dumps, or, when the server is backed by a governed catalog, verified, lineage-linked, ownership-tagged metadata.
Prompts are reusable templates for structuring model interactions: system prompts, few-shot examples, domain-specific interaction patterns. Server authors encode knowledge about how to interact with their system; AI hosts can discover and apply these templates without human configuration. This mechanism supports context bootstrapping — pre-loading agents with the structured context they need before a session begins.
Servers can also request capabilities from clients: Sampling (ask the host LLM to complete a generation), Elicitation (request user input mid-session), and Logging (structured debug messages from server to client).
Transport layer (stdio vs Streamable HTTP)
Permalink to “Transport layer (stdio vs Streamable HTTP)”MCP uses JSON-RPC 2.0 as its underlying message format. Two transport options exist for different deployment contexts:
| Transport | Best for | How it works |
|---|---|---|
| stdio | Local servers, development | Standard I/O streams; client spawns server as subprocess; no network overhead; no auth required |
| Streamable HTTP | Remote or cloud servers, production | HTTP POST with optional Server-Sent Events for streaming; supports OAuth 2.0, bearer tokens, API keys |
The connection lifecycle across both transports follows the same three phases: Initialization (version negotiation and capability exchange), Message exchange (requests, responses, notifications), and Termination.
For development, stdio is the right starting point: no auth setup, zero network overhead, easy to debug. For production deployments where the MCP server runs on cloud infrastructure and serves multiple clients, Streamable HTTP with OAuth 2.0 is the correct choice.
MCP vs function calling vs REST API
Permalink to “MCP vs function calling vs REST API”| Aspect | MCP | Function calling | REST API |
|---|---|---|---|
| Open standard | Yes | No (vendor-specific) | No standard |
| Tool discovery | Dynamic at runtime (tools/list) |
Static (baked into prompt) | None |
| Stateful sessions | Yes | No | No |
| Bidirectional | Yes (notifications) | No | No |
| Token consumption | Low (tools discovered separately) | High (all definitions in prompt) | Not applicable |
| Auth standardization | OAuth 2.0 via transport | Per-provider | Manual |
| Works across AI clients | Yes | No | Not applicable |
The key insight from the table: MCP does not replace REST APIs. MCP servers typically call REST APIs internally. MCP adds the AI-friendly discovery, session, and governance layer on top of them. For more detail on where each approach fits, see MCP vs API: when to use each.
What you can do with MCP: use cases and ecosystem
Permalink to “What you can do with MCP: use cases and ecosystem”The MCP ecosystem has grown from a handful of official reference servers at launch to 17,468 servers indexed across public registries as of Q1 2026, up from 1,200 servers a year earlier. According to the same census, the registry grew to 9,400+ active servers by April 2026 at +18% month-over-month growth through Q1 2026. A survey of enterprise AI teams found that 78% report at least one MCP-backed agent in production as of April 2026, though adoption maturity varies significantly by industry and organization size.
Official MCP servers from the reference repository cover the most common developer needs:
- Development tools: GitHub, Git, local filesystem, Sentry
- Communication: Slack, Google Drive
- Data and databases: PostgreSQL, Redis
- Browser automation: Puppeteer
- Web tools: Fetch (web-to-text conversion), Brave Search
- AI tooling: Memory (knowledge graph), Sequential Thinking
Beyond the official servers, the community has built MCP servers for virtually every enterprise system an AI agent might need: Salesforce, HubSpot, Confluence, Notion, SharePoint, Jira, ServiceNow, and hundreds of internal data systems.
Key enterprise use cases include:
- Connecting AI agents to internal databases without writing custom integrations for each model
- Surfacing governed metadata from a data catalog at inference time, so the agent knows not just the schema but who owns it and whether it’s trusted
- Knowledge base retrieval across Confluence, Notion, and SharePoint via standardized MCP servers
- CRM access: Salesforce and HubSpot data accessible to AI agents through a single protocol
- Code and DevOps context: GitHub issues, Sentry errors, and CI pipeline status surfaced to AI coding tools
The distinction between an MCP server for a flat filesystem and one for a governed data catalog matters significantly at enterprise scale. A flat filesystem server returns raw data. An MCP-connected data catalog returns data with embedded context: ownership, lineage, quality scores, and access policies. The data catalog as an MCP server is what makes the difference between AI agents that find data and AI agents that find trustworthy data.
For teams evaluating the right tool for knowledge retrieval in AI agents, the data catalog for AI framing explains why catalog-backed MCP servers are architecturally different from general-purpose ones.
MCP vs alternatives: when to use what
Permalink to “MCP vs alternatives: when to use what”MCP is not the right choice for every integration scenario. Understanding when to use MCP versus function calling versus REST APIs versus RAG changes the architecture decisions significantly.
MCP vs function calling
Permalink to “MCP vs function calling”Function calling is the mechanism OpenAI, Anthropic, and other providers offer for letting LLMs invoke code during inference. It works, but it has three structural limitations:
- Vendor lock-in: OpenAI function calling only works with OpenAI models. Anthropic tool use only works with Claude. An investment in function calling infrastructure is tied to a single provider.
- Static definitions: Tool schemas are baked into the system prompt at the start of every conversation. Every tool definition consumes tokens, whether or not the agent uses it.
- No cross-client portability: A function calling setup built for ChatGPT does not work in Cursor, VS Code, or Claude Desktop.
MCP eliminates all three: tools are discovered dynamically at runtime via tools/list, are not in the context window until called, and the same MCP server works identically across every MCP-compatible AI client. See MCP vs API for a detailed decision framework.
Function calling still makes sense for simple, tightly scoped, single-model workflows where cross-client portability is not a requirement.
MCP vs REST API
Permalink to “MCP vs REST API”REST APIs are not replaced by MCP; they are what MCP servers call internally. The distinction is the consumer: if the consumer is a human developer or a traditional software application, REST is the right interface. If the consumer is an AI agent that needs to discover capabilities dynamically and maintain session state, MCP is the right interface.
MCP adds over REST: standardized tool discovery, session management, bidirectionality through notifications, and OAuth 2.0 auth built into the transport layer. Use REST directly for non-AI integrations, simple CRUD operations, or when you control both ends of the integration. Use MCP when the client is an AI agent.
MCP vs RAG
Permalink to “MCP vs RAG”RAG (retrieval-augmented generation) and MCP solve different problems and work together rather than against each other. RAG handles what to retrieve and how: embedding search, chunking strategy, relevance ranking, reranking. MCP handles how to connect: the transport protocol between an AI agent and the data system that holds the retrieval index.
In practice, an MCP server can expose the output of a RAG pipeline as a Resource. The AI agent calls the MCP server, the server runs the RAG retrieval, and the relevant context is returned as a grounded input. Context engineering vs RAG explores this layering in more depth.
The full stack: MCP + RAG + governed context
Permalink to “The full stack: MCP + RAG + governed context”For enterprise AI agents to be production-reliable, three layers need to work together:
- MCP = the connectivity layer (how agents reach data systems) — see the AI agent stack for a view of all layers
- RAG = the retrieval layer (how relevant context is found within those systems)
- Governed context = the quality layer (what the agent actually gets: verified ownership, lineage, freshness, and access policy from a platform like Atlan)
Each layer is necessary; none is sufficient alone. For a comprehensive view of how these fit together, the context layer for AI agents guide covers the full enterprise architecture.
When to use what: decision table
Permalink to “When to use what: decision table”| Criteria | Use MCP | Use function calling | Use REST API |
|---|---|---|---|
| Multiple AI clients | Yes | No | Not applicable |
| Dynamic tool discovery | Yes | No | No |
| Stateful session needed | Yes | No | No |
| Single-model, simple task | No | Yes | - |
| Non-AI integration | No | No | Yes |
| Pair with RAG pipeline | Yes | Limited | Manual wiring |
How to get started with MCP
Permalink to “How to get started with MCP”Getting started with MCP requires three things: an MCP-compatible AI host, an MCP server for the target data source, and a transport configuration. For local development, the setup takes under 30 minutes. For production, the security and auth requirements demand more planning.
Prerequisites
Permalink to “Prerequisites”AI host options: Claude Desktop (quickest local start), Claude Code, Cursor, VS Code with GitHub Copilot, or JetBrains AI Assistant.
MCP servers: Find official servers at github.com/modelcontextprotocol/servers. Community servers are indexed at mcphub.com and in the awesome-mcp-servers GitHub lists. For production enterprise use, build your own using the official SDKs: Python, TypeScript, C#, Java, Kotlin, or Go.
For production: OAuth 2.0 credentials, a server hosting environment, and a security audit of any community servers in use.
Getting started: step by step
Permalink to “Getting started: step by step”- Choose an MCP-compatible AI host. Claude Desktop is the fastest path for local exploration.
- Find or build an MCP server for your data source. Start with the official reference servers for common systems (PostgreSQL, filesystem, GitHub).
- Configure transport. For local development, use stdio: no auth required, the server runs as a subprocess of the client.
- Test with sample queries using the MCP Inspector (official debugging tool).
- Move to Streamable HTTP transport for production: add OAuth 2.0, configure server hosting, enable SSE for streaming responses.
For implementation patterns beyond the basics, the MCP server implementation guide covers architecture, setup, and common deployment decisions. For deeper context on the discipline behind building reliable AI systems with MCP, see the agent engineering guide.
Common pitfalls to avoid
Permalink to “Common pitfalls to avoid”Authentication gaps. Auth was optional until March 2025. Many community MCP servers deployed before that date still run without authentication. Audit every server before connecting it to a production AI agent.
Supply chain risk. Trojanized MCP packages have been discovered in npm (including a malicious version of postmark-mcp). Vet every server against trusted sources before deployment. The rapid growth of the ecosystem has made it a high-value supply chain target.
Security at scale. Deploying 10 or more MCP plugins creates a 92% probability of exploitation. Enterprise adoption has outpaced security tooling. The rapid growth that produced 17,000+ servers also produced an ecosystem where vetting and audit infrastructure are still maturing. Enterprise MCP deployments need centralized visibility into which servers are connected, what capabilities they expose, and who has access — essentially an AI control plane — before these risks can be managed at scale.
Discoverability. There is no authoritative universal MCP server registry. The official registry launched in preview in September 2025 and has had data resets. Rely on vetted sources and maintain your own inventory of approved servers.
Version drift. The spec updates frequently. Review the 2026 MCP roadmap for what is stable versus in flux. Pin SDK versions and test on upgrade.
How Atlan’s MCP server connects AI agents to governed data context
Permalink to “How Atlan’s MCP server connects AI agents to governed data context”MCP is protocol-neutral about what a server exposes. The protocol handles the channel: the serialization, discovery, sessions, and transport. It does not constrain what flows through that channel. An MCP server for a flat filesystem returns whatever files exist, with no annotation about trust, ownership, or freshness. An MCP server backed by a governed data catalog can return the same data with full provenance: who owns it, where it came from, what its quality score is, and whether the requesting agent has access.
At enterprise scale, the bottleneck shifts from “can we connect?” to “can we trust what we are connected to?” Atlan’s research across customer deployments found that governed retrieval achieves 94-99% AI accuracy, compared to 10-31% accuracy for ungoverned retrieval. That difference is driven by whether the context an AI agent receives is verified and attributed, or raw and uncontrolled.
Atlan’s MCP server exposes a governed metadata platform to AI tools like Claude, Cursor, and Claude Desktop. It provides tools for:
- Asset discovery: Search for data assets across the governed catalog by name, owner, tag, or classification
- Lineage exploration: Understand upstream sources and downstream dependencies, not just the table but the full provenance chain
- Custom metadata management: Surface business context, quality scores, and stewardship information at inference time
- Business glossary operations: Retrieve standardized definitions and policies that give AI agents the organizational vocabulary to reason correctly
- Real-time governed context: Every asset returned carries ownership, freshness signals, and access policy status
Unlike an MCP server for a flat filesystem, Atlan encodes trust alongside data. When an AI agent queries via Atlan’s MCP server, asset results are filtered through Atlan’s access policy engine at query time, so what the agent receives is already scoped to what the requesting user or service principal is permitted to see. Ownership, upstream lineage, quality scores, and access classifications travel with every asset returned, not as separate calls. For teams working on agent context layer architecture, Atlan’s MCP server is the governed implementation that closes the gap between raw connectivity and reliable AI.
The result: enterprise AI agents get the context they need to cite sources instead of hallucinating them. To understand how this fits into the broader context layer vs semantic layer architecture, Atlan’s MCP server operates at the context layer: governed metadata that flows to AI through the MCP channel. For implementation patterns around context APIs for AI, Atlan’s MCP server is the production-grade reference.
MCP is the channel. Atlan’s context layer governs what flows through it. Enterprise AI agents need both.
Inside Atlan AI Labs and the 5x accuracy factor
Learn how context engineering drove 5x AI accuracy in real customer systems. Explore real experiments, quantifiable results, and a repeatable playbook for closing the gap between AI demos and production-ready systems.
Download E-BookReal stories from real customers: MCP-powered agents in production
Permalink to “Real stories from real customers: MCP-powered agents in production”"We're excited to build the future of AI governance with Atlan. All of the work that we did to get to a shared language at Workday can be leveraged by AI via Atlan's MCP server...as part of Atlan's AI Labs, we're co-building the semantic layer that AI needs with new constructs, like context products."
— Joe DosSantos, VP of Enterprise Data & Analytics, Workday
"Atlan is much more than a catalog of catalogs. It's more of a context operating system...Atlan enabled us to easily activate metadata for everything from discovery in the marketplace to AI governance to data quality to an MCP server delivering context to AI models."
— Sridher Arumugham, Chief Data & Analytics Officer, DigiKey
MCP is the pipe. Context quality is what flows through it.
Permalink to “MCP is the pipe. Context quality is what flows through it.”MCP achieved something rare in developer infrastructure: broad adoption across competing platforms in under 18 months. The protocol solved a genuinely painful problem, the N×M integration fragmentation that made every AI-to-data connection a custom engineering project, and it solved it cleanly enough that the major AI providers, IDE vendors, and enterprise tooling platforms all converged on it.
But adoption also revealed a challenge the protocol was never designed to solve. MCP is neutral about what a server exposes. The same protocol that can deliver a governed, lineage-traced, access-controlled data asset can equally deliver a stale, unverified, unattributed one. The protocol does not know the difference. Most MCP servers, built quickly by developers who needed connectivity, expose raw data. When AI agents reach that raw data and reason confidently from it, the result is not a protocol failure; it is a context quality failure.
The enterprise context layer addresses this gap by sitting between the raw data and the MCP server: enriching assets with ownership, lineage, quality scores, and access policies before they leave the server. The teams getting the most from MCP in production treat it as one layer in a three-layer stack, connectivity through MCP, retrieval logic through RAG, and governed context through a context layer for AI agents that controls what flows through the channel. When all three work together, AI agents can cite sources instead of inventing them.
FAQs about MCP (Model Context Protocol)
Permalink to “FAQs about MCP (Model Context Protocol)”What is the Model Context Protocol used for?
Permalink to “What is the Model Context Protocol used for?”MCP is used to connect AI agents and applications to external data sources, tools, and workflows through a standardized protocol. Common uses include connecting AI assistants to databases, file systems, APIs, data catalogs, and communication tools, allowing the agent to read context, execute actions, and chain tools across systems without requiring a custom integration for each connection.
Who created the Model Context Protocol?
Permalink to “Who created the Model Context Protocol?”Anthropic created MCP, authored by David Soria Parra and Justin Spahr-Summers. It was announced on November 25, 2024. In December 2025, Anthropic donated MCP to the Agentic AI Foundation (AAIF), a directed fund under the Linux Foundation, co-founded with Block and OpenAI, making MCP vendor-neutral, open-standard infrastructure governed by an independent body.
What is the difference between MCP and an API?
Permalink to “What is the difference between MCP and an API?”REST APIs are the integration standard; MCP servers typically call REST APIs internally. MCP adds a layer on top: standardized tool discovery at runtime, stateful sessions, bidirectional communication, and OAuth 2.0 auth, designed specifically for AI agents. Think of MCP as an AI-friendly orchestration layer above your existing APIs, not a replacement for them.
What is the difference between MCP and function calling?
Permalink to “What is the difference between MCP and function calling?”Function calling is vendor-specific - OpenAI’s implementation only works with OpenAI models; Anthropic’s only with Claude. Tool definitions are static, baked into the prompt, consuming tokens. MCP is an open standard: tools are discovered dynamically at runtime via tools/list, sessions are stateful, and the same MCP server works across Claude, ChatGPT, Cursor, and VS Code.
What are MCP servers?
Permalink to “What are MCP servers?”MCP servers are lightweight programs that expose capabilities - tools, resources, and prompts - to AI clients. A server might wrap a database, a file system, a data catalog, or a third-party API. Servers can run locally (same machine, stdio transport) or remotely (cloud-hosted, HTTP transport). As of Q1 2026, over 17,000 MCP servers have been indexed across public registries.
What are the three primitives of MCP (Tools, Resources, Prompts)?
Permalink to “What are the three primitives of MCP (Tools, Resources, Prompts)?”MCP servers expose three types of capabilities. Tools are executable actions the AI can invoke: API calls, database queries, file operations. Resources are read-only context data passed to the model: catalog entries, document contents, schema records. Prompts are reusable templates that encode domain-specific interaction patterns - system prompts and few-shot examples that AI hosts can discover and apply.
Is MCP an open standard?
Permalink to “Is MCP an open standard?”Yes. MCP’s specification is published at modelcontextprotocol.io and licensed as open source. In December 2025, Anthropic donated MCP to the Agentic AI Foundation (AAIF) under the Linux Foundation, the same governance model as Linux, Kubernetes, and other critical open infrastructure. SDKs are available in Python, TypeScript, C#, Java, Kotlin, and Go, maintained by the community and corporate contributors.
What are the security risks of MCP for enterprise?
Permalink to “What are the security risks of MCP for enterprise?”Key risks include authentication gaps (auth was optional until March 2025; many deployed servers remain unauthenticated), tool poisoning via malicious server descriptions, prompt injection, and supply chain attacks (trojanized MCP packages discovered in npm). Deploying 10 or more MCP plugins creates a 92% probability of exploitation. Enterprise deployments require server vetting, OAuth 2.0 enforcement, and audit logging before production use.
Sources
Permalink to “Sources”- Introducing the Model Context Protocol, Anthropic
- MCP Architecture Overview, modelcontextprotocol.io
- Model Context Protocol, Wikipedia
- MCP joins the Linux Foundation, GitHub Blog
- One Year of MCP: November 2025 Spec Release, MCP Blog
- MCP Adoption Statistics 2026, Digital Applied
- MCP vs Function Calling, Plugins, APIs, ikangai
- The 2026 MCP Roadmap, MCP Blog
- MCP Security Risks, Data Stealth
- What Is RAG Architecture, Atlan
