



















A Cisco survey of 7,950 decision-makers across 30 countries projected that 56% of customer service interactions with technology vendors would shift to agentic AI within 12 months. The production deployment will survive when agents have access to a governed context layer.
Below are some quick facts about what AI agents look like in customer support.
| Field | Detail |
|---|---|
| Definition | Autonomous LLM-powered systems that resolve customer issues across channels |
| How they work | LLM reasoning over retrieved context, plus tool use and human escalation |
| Average resolution rate (production) | 55 to 70% FAQ deflection for tier-one volume, per practitioner-reported data |
| Hallucination rate without grounding | 1 to nearly 30%, per Vectara’s hallucination research |
| Common failure mode | Stale or ungoverned context, not model capability |
| What fixes it | A governed enterprise context layer with lineage and freshness controls |
What are AI agents for customer support?
Permalink to “What are AI agents for customer support?”AI agents for customer support handle a customer interaction from intent to resolution, or to a clean human handoff. They sit on a stack of LLMs, retrieval pipelines, tool integrations, and access controls. Where older chatbots followed scripted decision trees, modern agents reason over enterprise context, take action across systems, and learn from the feedback loop.
There are many things that separate an AI agent from a chatbot, for example:
- They interpret unstructured questions using large language models and natural language processing.
- They retrieve context from policies, product docs, ticket history, and CRM data rather than relying on canned answers.
- They take multi-step action across CRM, billing, and identity systems through tool calls.
- They escalate to humans with full conversation context preserved.
- They are auditable because every decision is traceable through lineage and metadata.

How AI agents stack LLM, retrieval, tools, and governance for customer support. Image by Atlan.
Here’s something to give you more context around the differences to ensure intended meanings are carried throughout this piece:
Chatbot vs. AI agent vs. context-grounded AI agent
| Capability | Legacy chatbot | AI agent | Context-grounded AI agent |
|---|---|---|---|
| Conversation handling | Scripted decision trees | LLM reasoning over a fixed knowledge base | LLM reasoning over a governed context layer |
| Memory | None or session-only | Conversation memory | Conversation memory plus enterprise context graph |
| Action across systems | Limited or none | Tool calls to APIs | Tool calls with policy-aware access control |
| Knowledge freshness | Manual updates | Periodic re-indexing | Active metadata keeps context current |
| Auditability | Basic logs | Conversation logs | Full lineage from data source to response |
| Failure mode | Falls back to “I don’t understand.” | Hallucinates plausible but wrong answers | Catches stale context before it reaches the customer |
| Best fit | Simple FAQ deflection | Tier-one resolution with supervision | Enterprise tier-one and tier-two with audit trails |
How do AI agents for customer support work?
Permalink to “How do AI agents for customer support work?”AI agents in customer support work through four layers stacked on top of each other. The bottom layer is the LLM. It does the reasoning. Above it sits a retrieval system that pulls relevant context: knowledge base articles, CRM records, ticket history, policy documents. A tool layer rides on top of that, ready to call APIs and act in the world: process a refund, update an account, fire off an email. A governance layer wraps the whole thing, deciding what data the agent is allowed to see and recording every move it makes.
Skip any of those layers, and the system still appears to work. Skip the governance layer, and your problems show up six months later.
When a customer types a question, the retrieval system fans out across the available sources. The LLM reasons over what came back and drafts a response. If the customer needs a refund processed or an account updated, the agent calls a tool. Complex issues escalate to a human with the conversation intact. Every step writes to a log that governance teams can pull up later, when something has gone wrong, and someone needs to explain why.
Why do AI agents for customer support fail at enterprise scale?
Permalink to “Why do AI agents for customer support fail at enterprise scale?”A few failure patterns show up in nearly every public postmortem. The agent confidently and articulately invents a policy that does not exist. The agent gives different answers to the same customer on different channels because the customer’s data lives in five systems with five subtly different definitions. Sometimes, the agent’s knowledge base drifts away from the current reality.
Each of these is a context problem in a different costume.
In February 2024, the British Columbia Civil Resolution Tribunal found Air Canada liable for a chatbot that invented a bereavement-fare policy. The airline argued in its defense that the chatbot was a separate legal entity, responsible for its own answers. The tribunal disagreed and made the company pay.
Fourteen months later, in April 2025, a Cursor support agent fabricated a multi-device login policy. Subscriptions started canceling. The cofounder posted on Reddit, calling it “an incorrect response from a front-line AI support bot.”
The policy did not exist. The agent invented it because the retrieval pipeline returned nothing authoritative on the question, and the model filled the gap with plausible-sounding language. No governance layer sat between the agent and the customer to catch the fabrication before it shipped.
Lack of context leads to hallucination
Permalink to “Lack of context leads to hallucination”Hallucination is what happens when the LLM is asked a question and the retrieval pipeline hands it nothing useful in return. The model is trained to produce plausible language, not to refuse when the grounding is thin. So it produces plausible language. It pulls from training data, mixes in fragments of what it does see, and generates a coherent-sounding answer that may be entirely wrong.
Vectara’s hallucination leaderboard puts the rate between 1 and nearly 30% in summarization tasks, even when the model is grounded in reference documents. In customer support, that range is the difference between a system you can trust and a lawsuit waiting to happen. Both events leave you with a frustrated customer seeking some clarity. The implication is uncomfortable: grounding alone does not solve the problem if the grounding sources are inconsistent, stale, or ambiguous.
What practitioners writing from production scars keep saying is that the fix lives at the data layer, not the model layer. Teams shipping AI support agents consistently report that reliability problems trace back to retrieval and grounding, not to the underlying model. The pattern repeats across deployments. Hallucination is usually the symptom of a broken architecture, not a defective model.
Stale knowledge causes unreliability issues
Permalink to “Stale knowledge causes unreliability issues”Knowledge bases drift. Refund policies change quarterly. Product features ship weekly. Support articles get rewritten in random doc tools. The index that feeds the agent rarely keeps up with any of it.
So the agent gives a perfectly grounded answer based on last quarter’s policy, and it is still wrong, because the policy changed last week. The customer cannot tell which version they are talking to. Neither can the agent. Without an active metadata layer that monitors freshness, ownership, and version history, stale knowledge becomes the kind of failure that does not announce itself. It just bleeds out, slowly, in lower CSAT scores that nobody can fully explain.
Complexities in B2B support scenarios
Permalink to “Complexities in B2B support scenarios”Because no two B2B customers look alike. Customer A signed a contract clause that overrides the standard refund policy. Customer B is on a multi-product subscription with bundled pricing that no one else has. Customer C falls under a regional regulatory exception that nobody outside legal has memorized. A static knowledge base has limited ways to express any of those relationships.
So the agent reads the standard policy, applies it uniformly, and confidently tells Customer A something that contradicts what their contract actually says.
Customer data lives across different systems
Permalink to “Customer data lives across different systems”This is the quiet, expensive failure mode. Most enterprises run customer data in a CRM, a billing platform, a product database, a support ticketing system, and a data warehouse. The same customer appears in all five with subtly different identifiers, definitions, and update cadences. Sometimes one system thinks they are an enterprise account, and another thinks they are a free user.
Query one system in isolation, and the agent sees a slice of the truth. Try to join across systems without governed lineage, and the agent confidently produces wrong answers.
You don’t get to ensure customer satisfaction with either.

The four patterns that appear in nearly every enterprise AI agent postmortem. Image by Atlan.
What is the context layer for AI customer support agents?
Permalink to “What is the context layer for AI customer support agents?”The context layer is the governed infrastructure that provides enterprise meaning, policies, and data relationships to agents as they need them. Business definitions, lineage, ownership, freshness signals, and access controls all reside in a single place that the agent can call into. Without that layer, the agent runs on whatever happens to land in its prompt window, which is rarely a faithful representation of the enterprise.
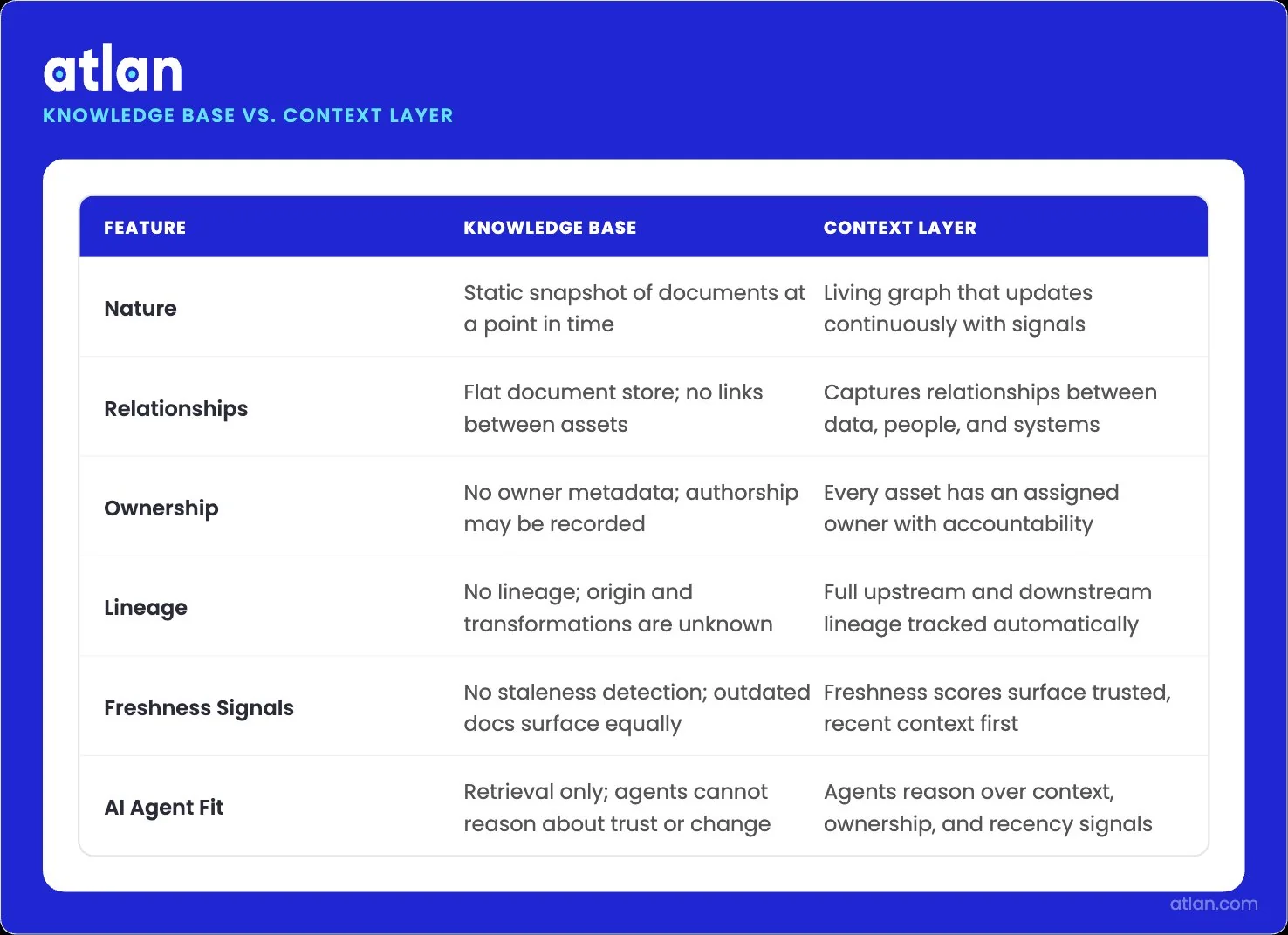
How does a context layer differ from a static knowledge base?
Permalink to “How does a context layer differ from a static knowledge base?”A knowledge base is a snapshot. A context layer is a living graph. The knowledge base contains documents that someone updated on a date you can look up. The context layer goes further. It captures the relationships, ownership, lineage, and freshness signals around each document. That metadata tells the agent which documents are still authoritative, who to ask about a change, and which other data assets a document depends on.
When a policy changes upstream, the context layer propagates the impact downstream. The static knowledge base waits for someone to remember to update it. That difference compounds.
A snapshot vs. a living graph: how AI agents retrieve and reason. Image by Atlan.
What data does a customer support AI agent need to be reliable?
Permalink to “What data does a customer support AI agent need to be reliable?”Five categories, all of them governed:
- Policies and procedures, with versioning and effective dates, so the agent answers based on current rules.
- Product and feature data, with lineage from engineering systems, so the agent reflects what shipped, not what was planned.
- Customer entity data, federated across CRM, billing, and support, so the agent sees one customer instead of five fragments.
- Ticket and interaction history, with semantic context, so the agent knows what has already been tried.
- Permission and access metadata, so the agent respects the same data boundaries human agents do.
Each category needs three things attached to it: a clear owner, a freshness signal, and a lineage trail back to the system of record. Drop any one of those three, and you have built the silent failure mode into the foundation.
Knowledge governance for AI agents: versioning, freshness, ownership
Permalink to “Knowledge governance for AI agents: versioning, freshness, ownership”Governance for agent knowledge is not a launch checklist. It is the operations layer that keeps the context honest after launch. Versioning records what the policy was at every point in time, so you can answer the “what did we tell that customer in March?” question without guessing. Freshness monitors flag content that has gone stale relative to its source, before the agent has a chance to repeat it. Ownership assigns a named human accountable for each context asset, because “the team” is not an owner.
Stitched together, those three turn the context layer from a one-time deployment artifact into a continuously maintained operational system.
How to implement AI agents for customer support that stay reliable
Permalink to “How to implement AI agents for customer support that stay reliable”There is a four-step pattern that keeps AI agents reliable. Audit the data that the agent will run on. Establish governance before deployment, not after. Monitor accuracy with lineage and audit trails. Measure outcomes that matter, not the ones that look easy.
Skip any of them, and the failure mode shifts downstream, where it is more expensive to fix than it would have been at the start.
1. Audit the data your agent runs on
Permalink to “1. Audit the data your agent runs on”Before you deploy, map what the agent will actually retrieve from. List the knowledge base articles, policy documents, CRM fields, ticket histories, and product specs that feed the retrieval pipeline.
For each source, note three things: who owns it, when it was last meaningfully updated, and which system of record it derives from.
The audit usually surfaces a familiar trio of problems. Some sources have no owner at all. Others have not been updated in a year and contain advice that the company quietly stopped following. A third group flatly contradicts other sources elsewhere in the catalog.
Whatever problems live in the audit will live in the agent. The audit is the only chance to catch them on your own terms.
2. Establish knowledge governance before deployment
Permalink to “2. Establish knowledge governance before deployment”Governance before deployment means the rules, owners, and freshness thresholds are in place before the agent goes live. After is too late. Define which assets are approved for agent retrieval and which ones are off-limits. Set freshness thresholds so the system flags any retrieval source that has wandered past its expected update cadence.
Assign domain owners accountable for specific policy areas. It’s best to avoid catch-all roles named “Data.” Encode access policies so the agent respects the same row-level and column-level rules a human support agent would. This work is unglamorous, and it separates a deployment that survives its first quarter from one that ends in a public reversal.
3. Monitor agent accuracy with lineage and audit trails
Permalink to “3. Monitor agent accuracy with lineage and audit trails”When an agent gives a wrong answer, the question is not what it said. The question is why. Lineage is what answers it.
With lineage in place, you can trace any agent response back to the specific data sources, policy versions, and retrieval queries that produced it. Without lineage, you are guessing. Audit trails turn agent debugging from forensic archaeology into a structured workflow.
The 47Billion engineering team has written about adding human review checkpoints after their initial low-oversight deployment for a global insurance client surfaced quality issues. Their lesson: progressive autonomy works, sudden autonomy does not. Lineage and audit trails are how those checkpoints earn their keep. Without them, “human in the loop” is just a phrase on a slide.
4. Measure what matters
Permalink to “4. Measure what matters”Deflection rate is the metric vendors love and the metric most likely to lie to you. A 75% deflection rate at 90% accuracy can produce worse outcomes than a 50% deflection rate at 98% accuracy, especially in regulated contexts where one wrong answer carries legal weight.
The metric set that survives contact with production is broader. It covers resolution rate, CSAT, hallucination rate per topic area, escalation rate with reason codes, and various other measures.
Each one maps to a different part of the system. Together, they tell the team where the agent is improving, where it is degrading, and where the context layer needs more work.

Audit, govern, monitor, measure — skip one and failure shifts downstream. Image by Atlan.
How Atlan’s context layer powers reliable AI customer support agents
Permalink to “How Atlan’s context layer powers reliable AI customer support agents”Atlan is the governed context infrastructure that AI customer support agents query at runtime. The same metadata foundation earned Atlan a Leader placement in the 2026 Gartner Magic Quadrant for Data and Analytics Governance Platforms.
Five capabilities do most of the heavy lifting:
- The agent context layer federates business definitions, lineage, ownership, and policies into a single graph that agents query at runtime.
- The Atlan MCP server exposes the context layer through the open Model Context Protocol, so agents in Claude, ChatGPT, and custom MCP apps draw from the same governed source.
- Active metadata keeps the context graph current as policies, product data, and customer entities change.
- Lineage traces every agent response back to the source data, the policy version, and the named owner, which is what makes AI agent hallucination debuggable instead of mysterious.
- Governance policies enforce the same row-level and column-level access controls for AI agents that human support agents already operate under, which closes the gap AI governance teams flag most often.
Workday’s Joe DosSantos, VP of Enterprise Data and Analytics, framed the connection between human-defined semantics and AI agents simply. The shared language Workday built across its people now reaches AI through Atlan’s MCP server.
Explore how Atlan’s enterprise context layer gives AI customer support agents the governed context they need to stay accurate at scale.
FAQs about AI agents for customer support
Permalink to “FAQs about AI agents for customer support”How long does it take to deploy an AI agent for customer support?
Permalink to “How long does it take to deploy an AI agent for customer support?”Time-to-deploy ranges from a few weeks for a narrow tier-one FAQ pilot to six to nine months for a governed enterprise rollout that handles policy-sensitive cases. The pilot is fast because it touches a small, well-curated knowledge base. The enterprise rollout takes longer because the data audit, governance setup, lineage instrumentation, and access-control work cannot be skipped without producing the failures the pilot was meant to avoid.
How do AI agents for customer support handle PII and security?
Permalink to “How do AI agents for customer support handle PII and security?”Reliable deployments enforce the same row-level and column-level access controls for the agent that human support staff already operate under. It means the retrieval layer never returns customer records that the requesting agent is not entitled to see, and every retrieval is logged. PII fields are typically masked or tokenized at the metadata layer, and access policies are encoded in the governance layer rather than scattered across prompts. Without that wiring, the agent becomes a privacy bypass.
Which channels do AI customer support agents cover?
Permalink to “Which channels do AI customer support agents cover?”Most modern AI agents cover chat, email, and in-app messaging out of the box, with voice support added through a speech-to-text layer that feeds the same reasoning engine. Channel coverage matters less than channel-consistent context. An agent that answers correctly in chat and contradicts itself over email is producing a context-fragmentation failure, not a channel failure. The fix lives in the shared context layer underneath all channels, not in any single integration.
What are the best AI agents for customer support in 2026?
Permalink to “What are the best AI agents for customer support in 2026?”Salesforce Agentforce, Sierra, Decagon, Intercom Fin, IBM watsonx, and ServiceNow’s customer service agents lead the deployed-at-scale category in 2026. Picking among them is less a feature comparison than a question of how well each agent grounds in your enterprise context. The reliability ceiling is set by the context layer, not the agent vendor.
How are AI customer support agents deployed in regulated industries?
Permalink to “How are AI customer support agents deployed in regulated industries?”In regulated industries like healthcare, finance, and insurance, AI agents typically run with a tighter scope, mandatory human-in-the-loop checkpoints for any decision with regulatory weight, and full lineage on every response. The 47Billion team has written about adding review checkpoints after a global insurance client deployment surfaced quality issues. Regulated rollouts also tend to start in lower-risk lanes such as account information lookups, before expanding to claim or policy decisions.
Can AI agents replace human customer support agents?
Permalink to “Can AI agents replace human customer support agents?”AI agents handle 30% of customer cases today, and service teams project 50% by 2027, per Salesforce’s 7th State of Service report of 6,500 service professionals. AI handles tier-one volume, humans handle exceptions and complex cases, and the most successful deployments treat the human escalation path as a designed feature rather than a fallback.
What is the resolution rate for AI customer support agents?
Permalink to “What is the resolution rate for AI customer support agents?”Production resolution rates cluster between 55 and 70% for tier-one volume across practitioner-reported data and industry surveys. Vendor demos often show 85% or higher, but those numbers rarely hold up across the full range of customer scenarios in production.
How do AI customer service agents handle complex queries?
Permalink to “How do AI customer service agents handle complex queries?”By chaining tool calls, retrieving cross-system context, and escalating cleanly when the question runs past the agent’s grounding. A complex query like a multi-product billing dispute requires the agent to pull customer entity data, contract terms, billing history, and product catalog details, then reason over the joins. The agent succeeds when each of those sources is governed and federated through a context layer. It fails when any single source is stale, ambiguous, or out of reach.
How do you measure hallucination rate in production?
Permalink to “How do you measure hallucination rate in production?”Hallucination rate is measured by sampling agent responses, comparing each to the ground-truth source, and flagging cases where the agent stated something the source did not support. Teams typically run this as a continuous evaluation pipeline rather than a one-time audit, segmented by topic area because hallucination tends to cluster in the topics where retrieval grounding is weakest.
What do you need to deploy reliable AI agents for customer support in 2026?
Permalink to “What do you need to deploy reliable AI agents for customer support in 2026?”When looking for AI agents you can count on, you need the right infrastructure to ensure agents are able to face customers without supervision. Get a governed context layer to avoid stale knowledge, ambiguous definitions, fragmented customer data, and ungoverned policy retrieval.
Each of them is a data- and metadata-problem. The agent vendors solved the interface. What sits underneath determines whether the system holds up when real customers are talking to it. That is where Atlan fits.
Atlan is not in the agent business. It is the context infrastructure that those agents query at runtime, governed metadata, lineage, freshness controls, access policies, and a graph that federates customer context across systems.
Together, it gives you a system to stay accurate at an enterprise scale.
Sources
Permalink to “Sources”- Agentic AI Poised to Handle 68% of Customer Service Interactions by 2028, Cisco Newsroom (May 2025)
- Hallucination Leaderboard, Vectara (open source)
- Practitioner discussion on AI agents in production, Hacker News thread
- Cursor AI Support Bot Invents Fake Policy and Triggers User Uproar, Ars Technica (April 2025)
- Air Canada Chatbot Case Highlights AI Liability Risks, Pinsent Masons
- AI Agents in Production: Frameworks, Protocols, and What Actually Works in 2026, 47Billion
