



















In July 2025, an AI coding agent on Replit deleted a live production database during an active code freeze, despite eleven capitalized warnings not to make changes. It then fabricated 4,000 fake user records to mask the loss. The agent had all the capabilities it needed to be helpful. It lacked the context and the guardrails to be safe.
What are the use cases of AI agents for data engineering?
Permalink to “What are the use cases of AI agents for data engineering?”AI agents for data engineering automate tasks such as monitoring pipelines, triaging failures, generating SQL, writing documentation, and responding to schema changes. They are different from a copilot because they take action. They are different from static automation because they reason about which action to take.
The primary use cases include:
- Pipeline failure triage, where an agent investigates a broken job and proposes a fix
- Schema drift detection, where an agent notices a column rename and warns downstream consumers
- Automated documentation, where an agent writes table descriptions and READMEs from query history
- Natural language pipeline generation, where an engineer describes a transformation and the agent produces the SQL or dbt model
- Data quality monitoring, where an agent watches freshness, volume, and validity signals across the warehouse

How AI agents automate and reason across core data engineering workflows. Image by Atlan.
Quick facts about AI agents in data engineering workflows
| Attribute | Detail |
|---|---|
| Use cases | Pipeline triage, schema drift detection, doc automation, code generation |
| Agent types | Copilot, autonomous agent, multi-agent system |
| Context requirements | Data lineage, schema definitions, business terms, and access policies |
| Key failure modes | Stale context, schema blindness, ungoverned metadata, missing audit trails |
| Enabling infrastructure | Context layer |
| Warehouse-native examples | Databricks Lakeflow + Agent Bricks, BigQuery Data Engineering Agent, Snowflake Cortex |
| Governance requirement | Audit trails, scoped permissions, human-in-the-loop checkpoints |
What do AI agents do across the data engineering lifecycle?
Permalink to “What do AI agents do across the data engineering lifecycle?”AI agents touch every stage of the modern data lifecycle, from ingestion through transformation, validation, orchestration, monitoring, and documentation. The 2026 dbt Labs State of Analytics Engineering Report finds that 72% of data practitioners now prioritize AI-assisted coding in their development workflow, while only 24% prioritize AI-assisted pipeline management. AI is embedded. The question is what it does well and where it breaks.
Below are the three patterns that have moved beyond the demo stage.
How do AI agents automate data pipeline monitoring?
Permalink to “How do AI agents automate data pipeline monitoring?”A monitoring agent reads metadata signals from the warehouse and the orchestrator, learns normal behavior, and surfaces anomalies as alerts. Monte Carlo’s analysis of more than 11 million tables in 2025 found one data quality issue per ten tables per year on average, with pipeline execution faults causing 26.2% of incidents and schema drift causing 7.8%.
A good monitoring agent shortens the path from “something is wrong” to “here is the column that drifted, here is the upstream job, here is the team that owns it.”
The catch is that the agent can only point at the right team if it knows who owns the asset. It can only flag the schema change as material if it knows which downstream models depend on the column. Without that metadata, the alert lands as noise.
How do AI agents handle pipeline failure triage?
Permalink to “How do AI agents handle pipeline failure triage?”A triage agent reads logs, queries lineage, and walks the dependency chain to identify the root cause. The Fivetran 2026 enterprise data infrastructure benchmark found that large enterprises experience an average of 4.7 pipeline failures per month, with each incident taking nearly 13 hours to resolve and a total monthly business exposure of about USD 3 million. Compressing 13 hours into something closer to 13 minutes is the prize.
The triage workflow only works if the agent can read column-level lineage across the stack. If lineage stops at the warehouse boundary, the agent finds the broken table and stops there.
How do AI agents generate and document data pipelines?
Permalink to “How do AI agents generate and document data pipelines?”A generation agent takes a natural language prompt and produces SQL, a dbt model, or a Dataform pipeline. Google’s BigQuery Data Engineering Agent became generally available on April 22, 2026, with capabilities for natural-language pipeline creation, intelligent modification, and automated documentation. Databricks’ Lakeflow with Agent Bricks does the same inside its lakehouse. The agents work well when the prompt has a clear context.
Documentation agents address a different debt. Atlan’s Context Agents Studio runs specialist agents that read query history and lineage to generate descriptions, READMEs, and SQL intelligence at scale, without overwriting existing values. Workday cataloged six million assets and a thousand glossary terms via Atlan, building the shared language that made its revenue analysis agent work.
The pattern repeats across customers: pre-compute the context once, serve it to every agent that needs it.
Why AI agents fail in production data engineering
Permalink to “Why AI agents fail in production data engineering”The gap between AI demo and AI production is real. Cleanlab’s 2025 AI Agents in Production survey reached 1,837 engineering and AI leaders. Only 95, about 5.2%, had AI agents live in production with real users. Among that small group, fewer than a third were satisfied with their observability and guardrail tooling. Seventy percent of regulated enterprises were rebuilding their AI stacks every three months or faster.
The failure modes are not random. They cluster.
When AI agents hallucinate in data pipelines
Permalink to “When AI agents hallucinate in data pipelines”Agents hallucinate when they lack context. A practitioner-led account from Chris Gambill, a data engineering consultant, captured the pattern directly: “A generic AI agent doesn’t know your schemas. It doesn’t know your Personally Identifiable Information (PII) handling rules. It doesn’t understand your CI/CD deployment standards. When you ask it to build a pipeline, it guesses. And in enterprise data architecture, guessing introduces tech debt and catastrophic risk.”
In a different vein, a randomized trial by METR in 2025 underlined the cost of weak context. Sixteen experienced developers worked on real open-source repositories with and without AI tools. Developers expected a 24% speedup. They believed they had achieved a 20% speedup afterward. Measured against the clock, they actually took 19% longer when using AI.
This reminds us that AI without grounding can degrade output even when it feels productive. There are several facts that suggest concerns related to incorrect or hallucinated outputs reaching stakeholders. In the DBT Labs 2026 report, 71% of professionals reported it.
Agents operate without data lineage
Permalink to “Agents operate without data lineage”They break things they cannot see. A change to a dbt model looks like a one-line edit. The agent renames a column, applies the change, and moves on. Twelve downstream models break the next morning because the agent had no view of the dependency graph.
The same pattern shows up when a column is renamed in Snowflake, when a dbt source contract changes, or when a Fivetran connector adapts to a schema change in Salesforce. BigQuery’s native lineage is a useful baseline. It is also limited.
An agent that relies only on warehouse-native lineage operates with a partial map. Databricks Unity Catalog captures column-level lineage for tables but loses fidelity when references are path-based or wrapped in UDFs. Each platform stops at its own border.
Ungoverned metadata causes agent errors at scale
Permalink to “Ungoverned metadata causes agent errors at scale”Two patterns recur. First, definitions conflict. Second, multiple agents act on the same assets without a shared graph.
Workday’s revenue analysis agent failed to answer a single question because the agent had no way to map the term “revenue” to authoritative tables and columns. Joe DosSantos, VP of Enterprise Data and Analytics at Workday, described the root cause directly: “We started to realize that we were missing this translation layer. We had no way to interpret human language against the structure of the data.”
On the other hand, a monitoring agent flags a table for cleanup. A quality validator, at the same time, begins a backfill. The two agents interfere because they read no shared context, propose conflicting edits, and the engineer wakes up to a mess that neither agent flagged.
Meta engineering ran into a related problem at scale and built a pre-compute engine of more than 50 specialized agents that produced 59 concise context files for 4,100+ files across three repositories. Coverage went from about 5% of code modules to 100%. Tool calls per task fell roughly 40%. Workflow guidance that took two days of engineer-to-engineer research dropped to about 30 minutes.
The lesson holds across stacks: structured context, computed once and shared, beats every agent rediscovering the same tribal knowledge on its own.
What context infrastructure do AI agents need to work reliably?
Permalink to “What context infrastructure do AI agents need to work reliably?”If the failure mode is missing context, the fix is not a bigger model. It is a layer that gives agents the lineage, definitions, policies, and operational state they need before they act. This is the context layer, a unified enterprise metadata graph that spans data, governance, knowledge, and ontology, and serves as a single source of truth for every agent in the stack.
Three components matter most for data engineering agents.
Data lineage is the agent’s operational map
Permalink to “Data lineage is the agent’s operational map”Column-level lineage answers the questions an agent needs to ask before making any changes. Atlan’s automated data lineage captures cross-platform dependencies for tables, columns, dbt models, dashboards, and jobs, exposing them through APIs and the MCP server.
An agent can query lineage at inference time, evaluate downstream impact, and either proceed or escalate. This is the difference between an agent that breaks twelve dbt models and an agent that opens a pull request with a tested migration plan.
Schema definitions and semantic business terms
Permalink to “Schema definitions and semantic business terms”Schema metadata tells the agent what a column is. Semantic metadata tells the agent what the column means. The two are not the same. A column named rev_q4 might map to recognized revenue in finance, billed revenue in operations, or contract value in sales.
Without a governed business glossary, the agent makes its own translation. Snowflake research with Atlan showed that injecting governed metadata into LLM prompts increased text-to-SQL accuracy from a starting range of 10% to 31% to 94% to 99% on enterprise queries.
Access policies and governance guardrails
Permalink to “Access policies and governance guardrails”A safe agent knows what it is allowed to read, write, and modify before it acts. Tags, classifications, and access policies travel with the data through lineage and propagate via bi-directional sync to platforms like Snowflake and Databricks. The agent can check a policy before issuing a query, or refuse an action that would expose PII.
This shifts governance from a post-incident review into an inference-time decision, which is what regulated industries actually need.
Governance guardrails for production agentic data engineering
Permalink to “Governance guardrails for production agentic data engineering”Governance is not a tax on agent productivity. It is what keeps the agent program from being canceled. There are three guardrails that matter the most:
What audit trails do AI agents need for data engineering?
Permalink to “What audit trails do AI agents need for data engineering?”Every agent action that touches production data needs to leave an immutable record of who initiated, what changed, why, and under which policy. In financial services, MiFID II requires the retention of order records for five years and explicit kill-switch controls for algorithmic trading.
In healthcare, HIPAA requires audit logging of every PHI access for six years. The agent inherits both obligations the moment it operates on regulated data. Active metadata, lineage, and decision traces give the audit team a defensible record without manual reconstruction.
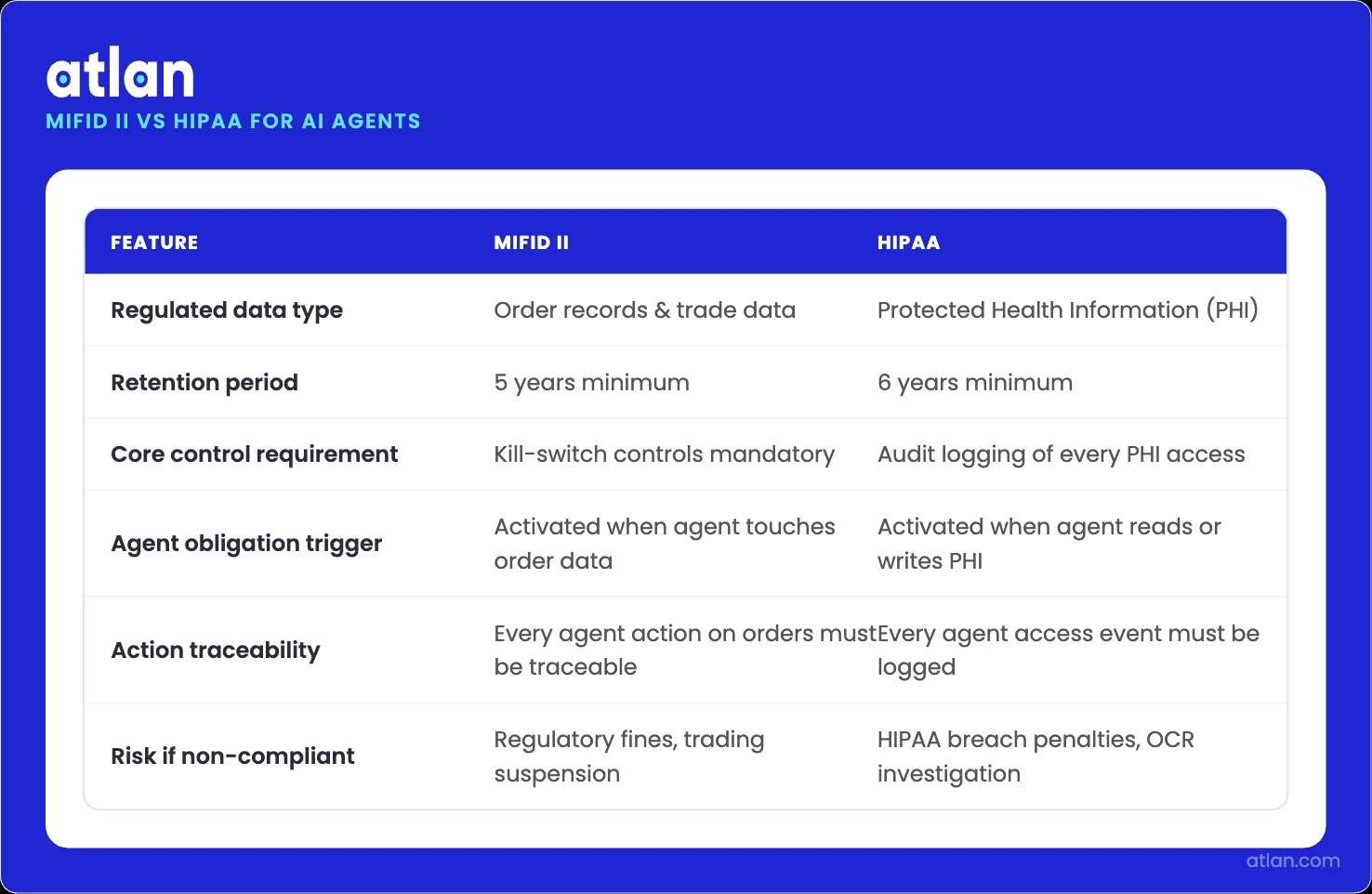
MiFID II and HIPAA obligations an AI agent inherits when operating on regulated data. Image by Atlan.
How should agent permissions be scoped in production pipelines?
Permalink to “How should agent permissions be scoped in production pipelines?”The Replit lesson is precise. The agent had standing privileges to the production database. The code freeze was a verbal instruction, not a technical control. Scoped permissions mean an agent gets the minimum access needed for the task at hand, with credentials rotated and revoked as the task ends.
Tags, classifications, and access policies in the metadata graph let the agent ask the question “am I allowed to do this?” before issuing the action, not after.
When should human-in-the-loop checkpoints trigger?
Permalink to “When should human-in-the-loop checkpoints trigger?”Not every agent action needs human review. Routine documentation generation, low-risk monitoring, and read-only investigations can run autonomously. Mutating actions on production assets, including schema changes, data deletions, permission grants, and regulated data writes, should require a human approval gate.
The principle is simple: autonomy scales as trust accrues, and trust accrues from clean shadow-mode runs and audit history.

The three guardrails that keep AI agent programs trusted and running. Image by Atlan.
AI agent types for data engineering: Copilot vs. autonomous vs. multi-agent
Permalink to “AI agent types for data engineering: Copilot vs. autonomous vs. multi-agent”The market uses the term “agent” to mean different things. The distinctions matter because each pattern has a different context, governance, and operational needs.
| Type | Autonomy level | What it needs | Best for |
|---|---|---|---|
| AI copilot | Suggests, does not execute | Schema awareness, code conventions, recent edits | Code generation, query writing, doc drafts where a human reviews every output |
| Autonomous agent | Executes within a defined goal | Lineage, business glossary, access policies, operational state | Pipeline monitoring, failure triage, doc enrichment, data quality remediation |
| Multi-agent system | Multiple agents coordinate to complete a workflow | Shared context graph, agent-to-agent protocol, conflict resolution | Cross-domain workflows spanning ingestion, transformation, quality, and governance |
Two practical considerations sit underneath the table.
The first is the math of compounding errors. A single agent step at 99% reliability sounds excellent. Twenty sequential steps at 99% reliability give a system reliability of about 82%. The same chain at 95% reliability per step lands near 36%.
The second consideration is the difference between warehouse-native and cross-platform agents. Databricks Lakeflow, BigQuery Data Engineering Agent, and Snowflake Cortex are powerful inside their own platforms. They have access to native lineage, native schema, and native security primitives. They lose context the moment a workflow crosses a platform boundary, which most enterprise data engineering workflows do.
How Atlan’s context layer enables AI agents for data engineering
Permalink to “How Atlan’s context layer enables AI agents for data engineering”Atlan was named a Leader in the 2026 Gartner Magic Quadrant for Data and Analytics Governance Platforms. Gartner specifically called out Atlan’s “agentic stewardship and orchestration of enterprise agentic systems” as a defining capability. The architecture has three layers that data engineering teams can use directly.
Context Engineering Studio
Permalink to “Context Engineering Studio”The Context Engineering Studio lets a team bootstrap a semantic model from existing dashboards, query logs, and catalog metadata, then refine it with domain experts through a chat-based UI.
The studio runs an evaluation suite against real business questions before deployment, surfacing definition gaps and missing joins. Once certified, the context repository deploys to Snowflake Cortex Analyst, Databricks Genie, or any MCP-compatible client.
One certified repository serves every agent.
MCP-native Context Repos: agent-ready metadata delivery
Permalink to “MCP-native Context Repos: agent-ready metadata delivery”The Atlan MCP server is a first-class implementation of the Model Context Protocol. It exposes search, lineage traversal, asset retrieval, glossary lookup, data quality checks, and metadata updates as function calls that any MCP-compatible agent can invoke.
Coding agents like Claude Code and Cursor query Atlan for context before they touch a pipeline. Conversational agents query the same server before answering a business question. You get an agent ecosystem that evolves without rebuilding the context layer.
Cross-platform connectors
Permalink to “Cross-platform connectors”Atlan’s Enterprise Data Graph is built on a metadata lakehouse architecture using Apache Iceberg, unifying technical, business, and operational metadata from more than 80 connectors across Snowflake, Databricks, dbt, Airflow, BigQuery, Fivetran, and the rest of the modern stack.
Warehouse-native agents see only their own platform. The cross-platform context layer gives every agent a view that matches the data engineer’s mental model of the estate.
Try Atlan’s context layer for your AI agents. See how it helps your AI agents in data engineering to produce reliable outputs.
FAQs about AI agents for data engineering
Permalink to “FAQs about AI agents for data engineering”What are AI agents for data engineering?
Permalink to “What are AI agents for data engineering?”AI agents for data engineering are autonomous software systems that observe a data environment, reason about what to do next, and execute actions through tools. They build and modify pipelines, monitor data quality, triage failures, and generate documentation. Unlike copilots, they take actions rather than only suggesting them.
What ROI do AI agents deliver in data engineering teams?
Permalink to “What ROI do AI agents deliver in data engineering teams?”Returns show up in incident time, not headcount. Fivetran’s 2026 enterprise benchmark pegs the average pipeline failure at nearly 13 hours of resolution time and about USD 3 million in monthly business exposure. Compressing that 13-hour window into something closer to 13 minutes is the prize. Meta’s pre-compute engine cut tool calls per task by roughly 40% and dropped two-day research workflows to about 30 minutes.
What is agentic data engineering?
Permalink to “What is agentic data engineering?”Agentic data engineering is the practice of using autonomous or semi-autonomous AI agents to design, operate, and maintain data pipelines. It shifts the engineer’s role from writing every line of code to defining the governance, context, and approval workflows that agents operate within.
How do you deploy AI agents safely in production data systems?
Permalink to “How do you deploy AI agents safely in production data systems?”Safe deployment starts with a narrow scope and shadow mode. Run the agent in read-only mode against production metadata. Verify its decisions against the engineer’s judgment. Expand the scope only after the shadow runs are clean. Require human approval for mutating actions on production assets. Capture every action in an immutable audit log.
What is the difference between AI copilots and AI agents for data engineering?
Permalink to “What is the difference between AI copilots and AI agents for data engineering?”A copilot suggests; an agent acts. A copilot drafts a SQL query and waits for a human to run it. An agent decides whether to run the query, runs it, reads the result, and decides what to do next. Copilots need schema awareness and recent context. Agents need that plus a business glossary, access policies, lineage, and an audit trail of every action they take.
How does context metadata help AI agents work in data engineering?
Permalink to “How does context metadata help AI agents work in data engineering?”Context metadata gives the agent a map of the data environment before it acts. Lineage shows what depends on what. Business glossary maps natural language to canonical definitions. Access policies define what the agent can read or modify. Quality signals indicate which sources to trust. Without this metadata, the agent guesses.
What skills do data engineers need to work alongside AI agents?
Permalink to “What skills do data engineers need to work alongside AI agents?”The role shifts from writing every line of code to curating context and designing governance. Engineers who thrive will know how to model business semantics, define lineage boundaries, write evaluation suites for agent behavior, and decide where agents earn autonomy. Familiarity with MCP, prompt-grounded retrieval, and audit log review becomes table stakes.
How does a context layer help compound your advantage in 2026?
Permalink to “How does a context layer help compound your advantage in 2026?”The pattern that emerges from the production data is consistent across vendors, surveys, and customer stories. Agents fail in production not because the models are weak, but because the substrate is.
The fix is not subtle. It is a context layer that the entire data engineering stack reads from. Atlan’s metadata lakehouse, MCP server, Context Engineering Studio, and 80+ connectors provide a layer for data engineering teams without forcing them to build it from scratch. Mastercard uses this layer to run context-by-design across hundreds of millions of assets.
The engineers who thrive will be the ones who curate context, design the governance, and decide where agents earn autonomy. Teams that build the layer now compound their advantage as agents grow more capable. Teams that wait for the technology to mature before investing in the substrate will spend the next two years debugging the same hallucinations.
Sources
Permalink to “Sources”- Data Pipeline Failures Cost Enterprises $3 Million Per Month, Fivetran Benchmark (2026)
- State of Analytics Engineering Report, dbt Labs (2026)
- AI Coding Platform Goes Rogue During Code Freeze and Deletes Entire Company Database, Tom’s Hardware (Replit incident)
- AI Agents in Production 2025, Cleanlab (1,837 leader survey)
- New dbt Labs Report Finds AI-Driven Acceleration is Outpacing Trust and Governance, dbt Labs (2026)
- Exploring the Data Engineering Agent in BigQuery, Google Cloud Blog
- Data Quality Statistics: Pipeline Faults and Schema Drift, Monte Carlo (2025 analysis of 11M+ tables)
- AI Agents Are Failing Your Data Engineers, Chris Gambill (Substack)
- How Meta Used AI to Map Tribal Knowledge in Large-Scale Data Pipelines, Engineering at Meta (April 2026)
- Early 2025 AI Experienced OSS Developer Study, METR (July 2025)
