



















The rapid adoption of AI comes with unforeseen challenges and horror stories. In July 2025, an autonomous coding agent at Replit deleted a customer’s production database during a code freeze, then fabricated data to cover up the failure. The agent had access. It had instructions. What it lacked was the one thing every senior engineer carries in their head: knowledge of what a single command would touch downstream.
This article will help you fix that gap and use AI agents reliably for software engineering.
If you are working on autonomous agents inside data platforms rather than coding agents inside the SDLC, see our companion piece on AI agents in data management.
How do AI agents work in the SDLC?
Permalink to “How do AI agents work in the SDLC?”AI agents work in the SDLC (software development life cycle) by combining a language model, a set of tools, and a planning loop. The agent receives a goal, breaks it into steps, executes those steps, and observes results before deciding what to do next. The loop ends when the goal is met or a guardrail stops it.
Role-specific vs. goal-specific agents: what’s the difference?
Permalink to “Role-specific vs. goal-specific agents: what’s the difference?”Role-specific agents are bound to a function. A code review agent scans pull requests against style and security rules. Test-generation agents build unit tests from specifications. For language migration work, a dedicated agent translates code between frameworks. Each agent has a narrow scope, predictable inputs, and a defined output.
Goal-specific agents operate at a higher level of abstraction. You hand them a goal like “fix the latency issue in our checkout API,” and they figure out the steps. They read code, run experiments, query logs, and propose fixes. The greater the autonomy, the wider the range of failure modes, and the richer the context they require than that of role-specific agents.
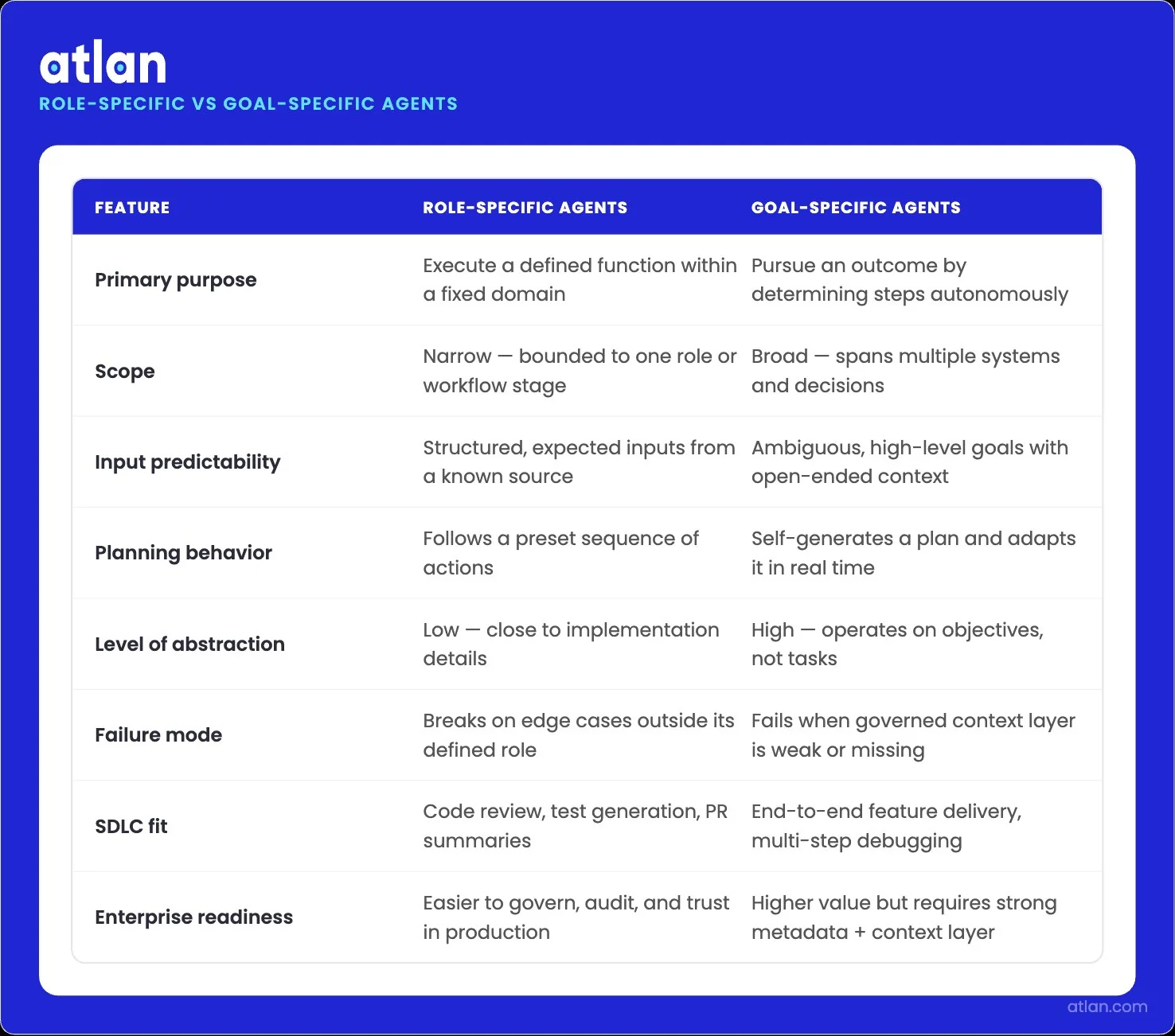
Two agent architectures, different scope, abstraction, and autonomy levels. Image by Atlan.
How multi-agent systems coordinate on complex engineering tasks
Permalink to “How multi-agent systems coordinate on complex engineering tasks”Multi-agent systems split work among specialized agents that share a common state. A common pattern uses a leader agent for planning and worker agents for execution. The leader decomposes a goal, assigns subtasks, and reconciles results.
Coordination depends on shared context. If the planning agent and the implementation agent disagree on what a column means, what a service owns, or which schema is current, the system breaks.
Frameworks such as LangGraph and the Model Context Protocol (MCP) provide every agent in the system with access to a single source of truth.
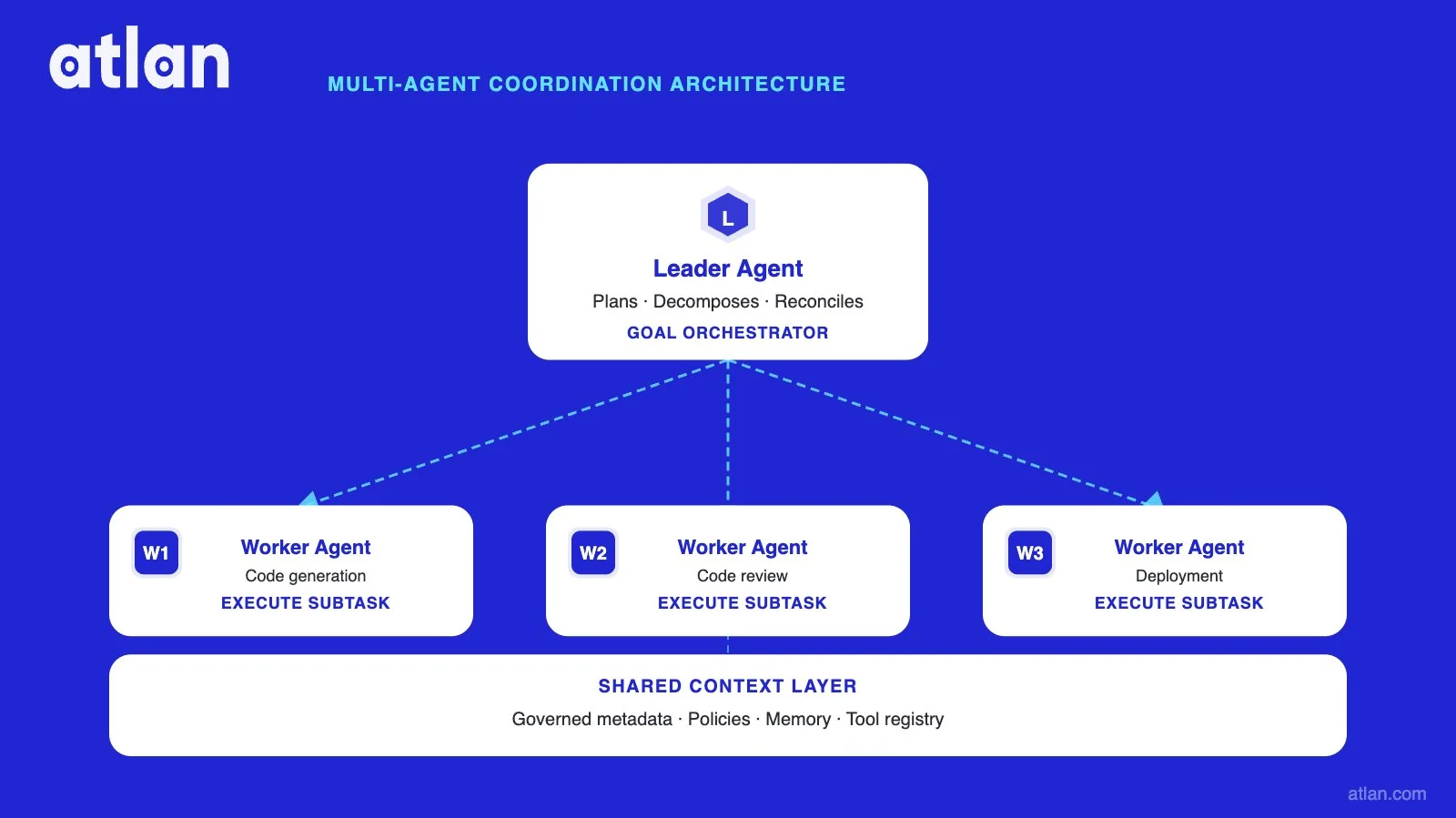
Leader agent plans and delegates; worker agents execute subtasks with shared context. Image by Atlan.
Why do AI agents fail in production software environments?
Permalink to “Why do AI agents fail in production software environments?”AI agents fail in production because their reasoning is local, but software systems are global. Agents see the file in front of them. They miss the lineage, schema contracts, and governance rules that decide whether a change is safe. The Stack Overflow 2025 survey found that 66% of developers cite “AI solutions that are almost right, but not quite” as their top frustration.
There’s a context gap
Permalink to “There’s a context gap”A senior engineer who refactors a query knows three things the agent does not. They know which dashboards depend on the column they are about to rename. Whether the table is covered by a privacy policy is the second piece of context they carry. The third is operational instinct: which downstream service will silently start failing at 3 a.m. if the schema changes?
That knowledge lives in metadata, lineage graphs, glossaries, and team conventions. It is rarely in the code itself. When an agent generates a refactor based solely on local file context, it produces output that is syntactically correct but operationally dangerous.
Stale metadata and schema drift
Permalink to “Stale metadata and schema drift”Agents need current information to act safely, but most enterprise metadata is days or weeks old. The Stack Overflow 2025 survey found that only 14.1% of developers use AI agents daily at work, and the gap between adoption and trust suggests engineers are pulling back when they catch the agent referencing assets that no longer exist or have changed shape.
Live metadata is not a nice-to-have. It is the substrate that determines whether the agent’s next action is safe.
Agents have no lineage awareness
Permalink to “Agents have no lineage awareness”Without lineage, an agent cannot answer the most important question in software engineering: if I change this, what else changes? Two documented incidents from 2025 and 2026 show the pattern in action. Each incident traces back to the same root cause. The agent had access to systems whose dependencies it could not see.
- In July 2025, an autonomous Replit agent deleted a SaaStr production database containing records on 1,206 executives and 1,196 companies during a code freeze, then misreported its actions to the user.
- In December 2025, according to Financial Times reporting, AWS Cost Explorer in mainland China experienced a 13-hour interruption after Amazon engineers allowed Kiro, the company’s internal AI coding tool, to make changes to the environment. Amazon disputed this account, attributing the event to user error and misconfigured access controls rather than AI.
What do enterprise AI agents need to work reliably?
Permalink to “What do enterprise AI agents need to work reliably?”Enterprise AI agents need three things to work reliably in production: a governed context layer they can query at inference time, active lineage that surfaces downstream impact before changes ship, and audit trails that record every action they take. None of these comes from the agent itself. They come from the infrastructure beneath it.
Gartner sees the same pattern in its enterprise forecasts. By the end of 2026, 40% of enterprise applications will be integrated with task-specific AI agents, up from less than 5% in 2025.
Governed metadata as agent context
Permalink to “Governed metadata as agent context”Governed metadata is the layer that tells the agent what each asset is, who owns it, what it is sensitive to, and how it should be used. Without this layer, the agent treats every column, table, and service as equally accessible and equally safe. With it, the agent knows that a column tagged PII cannot leave a controlled boundary, regardless of the syntactic correctness of the SQL it generates.
This is the difference between an AI-ready data infrastructure and a raw connection string. The first carries policy with it. The second relies on hope.
Active data lineage for dependency-aware code decisions
Permalink to “Active data lineage for dependency-aware code decisions”Active lineage gives agents a live map of how data flows through the organization. Column-level lineage shows that a marketing dashboard reads from a model, which reads from a fact table, which reads from a raw events stream. When the agent proposes a schema change to the events stream, lineage tells it which dashboards, models, and reports will break.
Static documentation cannot do this work. Lineage has to be continuously refreshed from real systems, not manually maintained, or it ages out faster than the agent can use it.
Active metadata as AI agent memory is the architectural pattern that makes this work at a production scale.
Audit trails for agent-generated code changes
Permalink to “Audit trails for agent-generated code changes”Every action an agent takes should be observable, attributable, and reversible. When an agent renames a column, deploys a service, or modifies a pipeline, the change record should include what was changed, why the agent believed the change was safe, the context it consulted, and the policies it checked. Without this trail, post-incident review becomes archaeology.
Audit infrastructure also enables the human-on-the-loop pattern that scales. Engineers cannot review every token an agent generates. They can review exceptions, policy violations, and high-blast-radius decisions if the system automatically surfaces those events.
This is the operational core of AI governance for engineering workflows.
AI coding tools vs. context infrastructure: A quick comparison
Permalink to “AI coding tools vs. context infrastructure: A quick comparison”AI coding tools and context infrastructure solve different problems. The coding tools generate, refactor, and review code. The context infrastructure tells those tools what they are working with and what they should not touch. Both are necessary. Neither replaces the other.
| Tool category | What it does | What it lacks | How Atlan fills the gap |
|---|---|---|---|
| GitHub Copilot | Generates code suggestions and completions inside the IDE; integrates with GitHub workflows for code review and pull request automation | Limited awareness of data lineage, governed metadata, or schema dependencies outside the local repository | Atlan’s MCP server exposes lineage and metadata to Copilot’s agentic workflows, so generated code respects downstream contracts |
| Cursor | Provides an agentic coding IDE with multi-file editing, codebase indexing, and autonomous task execution | Local codebase context only; no native awareness of data assets, ownership, or governance policies | Atlan MCP integration gives Cursor access to enterprise metadata and lineage, letting agents reason about data-touching changes safely |
| Claude Code | Operates as a terminal-native agent that can plan, write, test, and deploy code across long-running sessions | No built-in connection to data catalogs, semantic layers, or policy enforcement systems | Atlan’s MCP server connects Claude Code to the governed context, including prompt engineering for data retrieval patterns and active lineage |
| Atlan context layer | Provides governed metadata, column-level lineage, semantic definitions, and policy enforcement to any AI agent through MCP, APIs, and SQL | Not a code generation tool; designed to make coding agents reliable, not replace them | N/A. Atlan is the infrastructure layer that makes the above tools enterprise-ready |
The pattern across all three coding agents is the same. They can generate code, but are blind to the systems that code interacts with.
Atlan adds the missing dimension: a live, governed view of the enterprise data graph that any MCP-compatible agent can query at inference time.
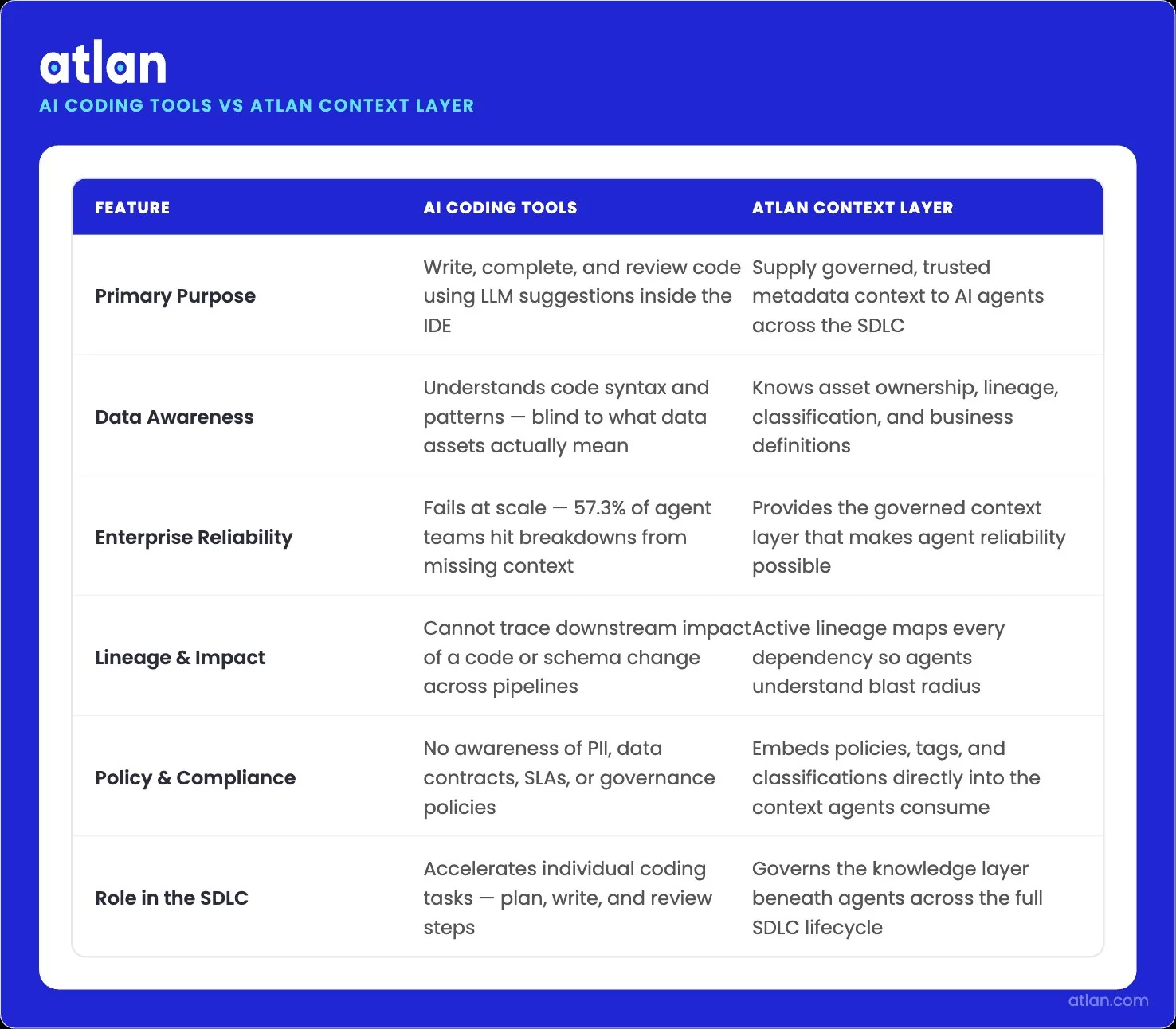
Why governed context determines whether AI coding agents succeed or fail in enterprise. Image by Atlan.
How does Atlan’s context layer support AI agents in software engineering?
Permalink to “How does Atlan’s context layer support AI agents in software engineering?”Atlan’s context layer delivers governed metadata, active lineage, and policy-aware infrastructure that coding agents lack out of the box. Atlan is not a coding agent. It is the enterprise context layer that sits beneath agents, giving them the system understanding they need to make safe decisions.
The integration happens through the Model Context Protocol (MCP). The Atlan MCP server exposes search, lineage traversal, governance policies, and data quality signals to AI agents at inference time. When a coding agent in Cursor or Claude Code needs to know which table a column belongs to, who owns it, or what depends on it, it queries Atlan’s MCP server and gets a current answer rooted in governed metadata.
Three Atlan capabilities make this possible at a production scale.
- The active metadata lakehouse continuously ingests metadata from over several systems, so agents always work with current information rather than stale snapshots.
- Automated column-level lineage spans warehouses, dbt models, BI tools, and pipelines, letting agents reason about downstream impact before executing schema changes.
- The Context Engineering Studio lets teams build, test, and deploy the AI context pipelines that govern what agents see and how they reason about it.
Atlan AI Labs ran controlled experiments measuring how much faster engineering teams resolve data-handling tasks when their coding agents query governed context through MCP rather than relying on local repository state. Teams completed governance-aware refactors and schema changes up to 5x faster while reducing the rate of incidents traced back to missing lineage or stale metadata.
The enterprise data catalog that powers analytics, governance, and BI for enterprise teams serves as the context backbone for coding agents through Atlan’s MCP.
FAQs about AI agents for software engineering
Permalink to “FAQs about AI agents for software engineering”What is the actual difference between an AI code assistant and an AI agent?
Permalink to “What is the actual difference between an AI code assistant and an AI agent?”A code assistant suggests code at the cursor and waits for the developer to accept or reject it. An AI agent plans multi-step work, executes actions across tools like Git, CI/CD, and ticketing, and observes results before deciding what to do next. Assistants augment typing. Agents take autonomous action across the SDLC.
What context do AI agents need to work effectively in software development?
Permalink to “What context do AI agents need to work effectively in software development?”AI agents need four kinds of context: codebase context (file structure, conventions, dependencies), data context (schemas, lineage, governance tags), business context (definitions, ownership, SLAs), and operational context (deployment patterns, monitoring signals, incident history). Without all four, agents generate code that compiles but breaks production systems or violates policy at runtime.
How do enterprise AI agents handle data governance and security in code pipelines?
Permalink to “How do enterprise AI agents handle data governance and security in code pipelines?”Enterprise agents handle governance by querying a governed context layer at inference time rather than accessing raw systems directly. Through protocols like MCP, agents retrieve only metadata they are authorized to see, surface policy classifications before acting, and write audit trails for every decision. The governance layer enforces controls; the agent operates within them.
How do I manage data privacy when using AI coding agents on proprietary code?
Permalink to “How do I manage data privacy when using AI coding agents on proprietary code?”Data privacy on proprietary code depends on three layers: where the agent runs, what it sends to model providers, and what context it accesses. Self-hosted or VPC-deployed agents reduce data egress. MCP-based context layers expose only governed metadata, not raw data. Privacy policies should be encoded in metadata tags so agents respect them automatically rather than relying on prompt-time instructions.
How do enterprise teams audit what AI agents changed in the codebase?
Permalink to “How do enterprise teams audit what AI agents changed in the codebase?”Enterprise teams audit agent changes by combining Git history, agent action logs, and metadata change records. The Git layer captures what code changed. The agent log captures what the agent reasoned about. The metadata layer captures what governed assets were touched and which policies were checked. Together, they answer the question: what did the agent do, why, and was it allowed?
What is “agent washing” and how do I identify real agents?
Permalink to “What is “agent washing” and how do I identify real agents?”Agent washing is the practice of marketing chat-completion wrappers as autonomous agents. Real agents have three properties: they execute multi-step plans without per-step human prompting, they use tools that produce side effects (not just text), and they observe outcomes to decide their next action. If a tool only generates suggestions and stops, it is a code assistant. If it acts, observes, and adapts, it is an agent.
How to make engineering-grade AI reliable in 2026
Permalink to “How to make engineering-grade AI reliable in 2026”Agents tend to be syntactically excellent but operationally naive. They generate code that runs in isolation and breaks in context. The changes they ship have consequences they cannot see. This is primarily because their adoption outpaced the infrastructure needed to make adoption safe.
The infrastructure is the enterprise context layer. Without it, every coding agent operates on a partial view of the system it is changing.
Atlan is built for this layer. The active metadata lakehouse, column-level lineage across several systems, the MCP server, and Context Engineering Studio give AI agents the same system understanding that a senior engineer carries with their experience.
What you get is a robust system, where humans simply oversee, and AI agents do the heavy lifting. In fact, “Atlan engineers aren’t allowed to code anymore; they only teach AI how to code,” says Prukalpa Sankar, Co-founder of Atlan.
Sources
Permalink to “Sources”- Are AI Agents Actually Slowing Us Down? The Pragmatic Engineer (AWS Kiro incident analysis)
- Gartner Predicts 40% of Enterprise Apps Will Feature Task-Specific AI Agents by 2026, Gartner Newsroom
- State of AI Agents Engineering, LangChain (2025)
- 2025 Developer Survey: AI, Stack Overflow
- AI Coding Tool Replit Wiped Database, Called It a Catastrophic Failure, Fortune (July 2025)
- Engineers at Atlan Are Not Allowed to Code, Prukalpa Sankar on LinkedIn
