



















Why does context engineering matter more in multi-agent systems?
Permalink to “Why does context engineering matter more in multi-agent systems?”Multi-agent systems multiply context risk.
A single agent can misunderstand a metric and return a bad answer. A multi-agent system, on the other hand, can pass that misunderstanding through a planner agent, a data agent, a policy agent, a finance agent, and a customer-facing agent before anyone sees the output.
That is why context engineering changes shape when teams move from one agent to many.
A single-agent setup asks, “What context does this agent need to answer well?” A multi-agent setup asks, “How do several agents share the same business understanding while each agent sees only the context its role requires?”
The industry also understands the importance of context engineering in a multi-agent system. Gartner predicts that 40% of enterprise applications will include task-specific AI agents by 2026, up from less than 5% in 2025. Gartner also predicts that one-third of agentic AI implementations will combine agents with different skills by 2027.
As more enterprise applications start using teams of task-specific agents, the risk is no longer limited to one agent getting context wrong. A small mismatch in one agent’s context can now move through the entire workflow.
Think about a revenue workflow that involves multiple agents:
- A planner agent breaks the request into data retrieval, policy review, account analysis, and response synthesis.
- A data agent pulls ARR from warehouse tables and semantic models.
- A governance agent checks whether the user can view customer-level revenue.
- A CRM agent adds the renewal stage, opportunity health, and account exceptions.
- A narrative agent turns all of that into a recommendation for the account team.
If each agent is working from the same trusted context, the system can coordinate well. But if the data agent uses one ARR definition, the CRM agent uses another, and the governance agent applies an outdated policy, the final answer can sound precise and still be wrong.
The agents completed their tasks. The context failed.
Build Your AI Context Stack
Get the blueprint for implementing context graphs across your enterprise. This guide walks through the four-layer architecture — from metadata foundation to agent orchestration — with practical implementation steps for 2026.
Get the Stack GuideWhat changes when context moves from one agent to many?
Permalink to “What changes when context moves from one agent to many?”Single-agent context engineering is already hard. Multi-agent context engineering adds handoffs, role boundaries, shared state, durable memory, and cross-agent accountability.
Here’s a quick summary of the differences between single-agent and multi-agent context engineering:
| Dimension | Single-agent context engineering | Multi-agent context engineering |
|---|---|---|
| Goal | Give one agent enough context to complete a task | Give each agent enough context while preserving shared meaning across agents |
| Main failure mode | Incomplete or outdated context | Conflicting context, handoff loss, drift, duplicated reasoning, inconsistent policy enforcement |
| Memory | Session memory or tool-specific memory | Shared runtime state plus governed enterprise memory |
| Retrieval | One retrieval policy | Role-specific retrieval from a common context repository |
| Business meaning | Often embedded in prompt instructions | Served from a governed context layer |
| Handoffs | Usually irrelevant or simple | Must preserve evidence, constraints, assumptions, and policy checks |
| Governance | Per-agent guardrails | Common policy layer, provenance, access checks, and decision traces |
| Testing | Prompt tests and task evals | Cross-agent simulations, golden questions, trace review, and context drift checks |
One distinction we should keep in mind while working with multi-agent systems is the difference between shared state and shared context.
Shared state tells agents what has happened so far: the user asked about ARR, the data agent ran a query, the policy agent approved access, and the narrative agent needs to write the final response.
Shared context tells agents what those updates mean. It defines which ARR calculation is approved, which table to use, who owns the metric, which policy applies, and which exceptions matter.
Multi-agent systems need both. State helps agents pass work from one step to the next. Context helps them stay aligned on the business meaning behind that work.
A multi-agent system needs different kinds of context for different jobs.
Some context tells agents how to behave. Some tracks what is happening right now. Some stores what the organization already knows. Some controls what agents are allowed to access or do.
In a demo, teams can often squeeze all of this into one prompt, one memory store, or one shared document. In an enterprise workflow, that creates risk. A policy can change
A metric definition can be updated. A user may have access to one dataset but not another. One agent may need raw evidence, while another only needs the approved summary.
That is why a multi-agent context architecture needs clear layers for them to perform efficiently. These layers include:
-
Instructions: Each agent contains a dedicated system instruction that contains all the essential information about its role including its task boundaries, output format, tools, and escalation rules. These should be versioned so teams know which behavior was active in each run.
-
Runtime state: The short-lived record of the current task, such as intermediate outputs, routing choices, and temporary variables. This helps agents pass work from one step to the next.
-
Working memory: The notes an agent keeps during a longer workflow, including assumptions, unresolved questions, and progress markers. This memory should expire or be compacted when the task ends.
-
Durable memory: Approved learning that should survive across sessions, such as user preferences, domain decisions, or recurring corrections. In enterprises, this needs review, privacy controls, and provenance.
-
Knowledge: The business context agents rely on, including documents, semantic models, glossary terms, lineage, policies, and quality signals. This layer needs certified sources, freshness checks, ownership, and access control.
-
Tools: The operational systems agents can call, such as APIs, databases, dashboards, ticketing systems, and policy engines. Tool context should define permissions, schemas, instructions, and failure handling.
-
Protocols: The delivery layer for agent collaboration and context access, such as MCP, A2A, or framework-native handoffs. This layer helps agents exchange tasks and securely retrieve context.
-
Governance: The control layer around policy checks, evals, guardrails, human approval, and trace review. It makes the system explainable instead of just automated.
With these layers in place, teams can choose the right multi-agent pattern without letting every workflow create its own version of business truth.
Which multi-agent pattern should teams use?
Permalink to “Which multi-agent pattern should teams use?”There is no single best multi-agent pattern. The right pattern depends on where context should live and how much control the system needs.
LangChain’s multi-agent documentation describes common patterns such as subagents, handoffs, skills, routers, and custom workflows. Amazon Bedrock’s multi-agent guidance emphasizes supervisor agents, specialist collaborators, clear responsibilities, and minimizing overlap.
In enterprise context engineering, the choice of pattern matters because each pattern moves the context differently.
| Pattern | How it works | Best fit | Context engineering implication |
|---|---|---|---|
| Supervisor or manager | A lead agent plans, delegates, and synthesizes outputs from specialist agents | Workflows that need centralized control and one final answer | Supervisor needs agent capability context, task state, and enough evidence to detect contradictions |
| Handoff | One agent transfers control to another agent that continues the workflow | User-facing journeys such as support, onboarding, triage, and approvals | Handoff must include constraints, assumptions, prior tool results, and policy checks, along with conversational context |
| Router | A classifier or planner sends the request to one or more specialist agents | Clear domain routing, such as finance, HR, legal, security, or data access | Router needs reliable intent context and capability metadata for each agent |
| Skills or context-on-demand | A single agent loads specialist instructions, tools, or knowledge only when needed | Tasks where one agent can remain in control but needs a specialized context to complete the task | Context packages must be modular, discoverable, and scoped tightly |
| Graph workflow | A fixed workflow controls the order of steps, with agents used only where reasoning is needed | Regulated, repeatable, or high-risk enterprise processes | State transitions, context retrieval, policy checks, and human approvals can be explicit |
| Parallel specialists | Multiple agents investigate different parts of the problem at the same time | Research, incident analysis, complex diagnostics, or comparison tasks | Each branch needs an isolated working context and a structured synthesis step |
The common mistake is adding agents before defining context ownership.
If five agents each retrieve from separate document stores, use different metric definitions, and write unreviewed memories, the architecture does not become smarter. It becomes harder to debug.
The better pattern is to let orchestration vary by workflow while keeping the shared context foundation.
For Data Leaders Evaluating Where to Start
Atlan's CIO guide to context graphs walks through a practical four-layer architecture from metadata foundation to agent orchestration.
Get the CIO GuideWhat should a multi-agent context architecture include?
Permalink to “What should a multi-agent context architecture include?”Once teams choose a multi-agent pattern, they need a shared architecture that keeps the agents aligned.
The goal is simple: agents can have different jobs, but they should not use different versions of business meaning. A data agent, policy agent, operations agent, and narrative agent may each need a different context, but that context should come from the same trusted foundation.
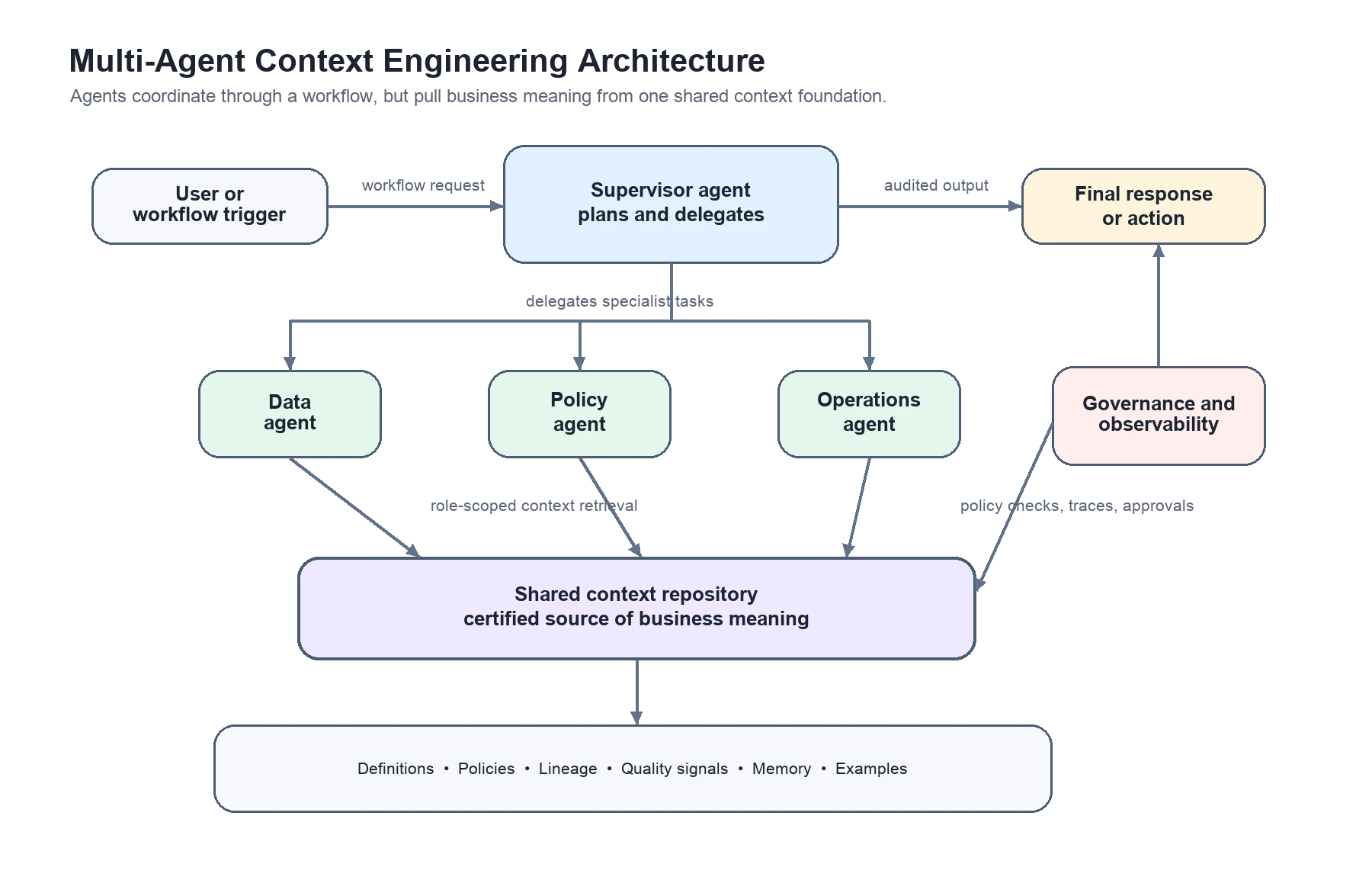
A strong multi-agent context architecture includes six core parts:
-
Agent coordination: A planner, supervisor, router, handoff, or graph workflow decides which agent should do what, and in what order.
-
Context assembly: A dedicated service retrieves, filters, ranks, compacts, and formats the right context for each agent before the model receives it.
-
Access control: Each agent receives only the context allowed by the user, task, role, and policy boundary.
-
Shared business meaning: Certified definitions, semantic models, policies, lineage, quality signals, and ownership details come from one governed source.
-
Provenance and traces: The system records which context, source, policy, tool call, and context version shaped each agent’s output.
-
Feedback and improvement: Corrections, eval failures, user feedback, and production traces are reviewed before they become reusable context.
This is where the context graph becomes important. It connects tables, dashboards, metrics, glossary terms, policies, owners, and past decisions so agents can retrieve relationships, not just isolated text chunks.
How should context be assembled for each agent?
Permalink to “How should context be assembled for each agent?”A strong context assembly pipeline usually moves through nine steps:
-
Understand the task: Identify what the user is asking for, which domain it belongs to, how risky the request is, and what kind of output is expected.
-
Resolve identity and permissions: Map the human user, the agent role, and the service account so access rules are applied before context reaches the model.
-
Choose the context scope: Select the relevant domain, workflow, data products, policies, business terms, and tools. This prevents every agent from receiving the entire knowledge base.
-
Retrieve trusted context: Pull definitions, lineage, policies, examples, memory, tool schemas, and source evidence from approved systems.
-
Rank and filter: Prioritize context that is certified, fresh, owned, and relevant. Remove context that is outdated, duplicate, low-quality, or outside the agent’s role.
-
Apply policy before injection: Mask, deny, redact, or transform sensitive context before it is added to the agent prompt or tool call.
-
Compact and format: Structure the context in the format the agent needs. A data agent may need raw evidence and SQL constraints. A narrative agent may need approved summaries, policy decisions, and source references.
-
Inject and trace: Pass the context into the agent call and record what was used, including source IDs, policy checks, tool calls, and context version.
-
Capture feedback: Record corrections, eval failures, user feedback, and human approvals so the shared context layer can improve after review.
The order matters. Identity and policy checks need to happen before context is injected into the model. Context should be scoped before retrieval gets too broad. Feedback should be reviewed before it becomes durable memory.
This is what makes context assembly different from simply passing information between agents. The assembly layer decides what each agent should receive, what should stay hidden, what must be carried forward, and what needs to be recorded for review.
This matters even more during handoffs. A policy agent does not need every SQL result the data agent saw. It needs the metric requested, the user identity, the data classification, the proposed action, and the relevant policy IDs.
That is how teams keep agents specialized without letting context become fragmented.
How does a shared context repository work?
Permalink to “How does a shared context repository work?”A shared context repository gives each agent a governed slice of the same truth.
Let’s look at this through a simple example written for LangGraph. The goal is not to show a complete production system. The goal is to show the architecture pattern: the graph manages the workflow, while the shared context repository manages business meaning, access, and traceability.
In this example, the data agent and the policy agent both work on the same revenue question. They do not carry their own private definition of ARR. They do not rely on static prompt text. Instead, each agent asks the shared context repository for the context it needs for its role.
The data agent receives the metric definition and lineage context. The policy agent receives the access policy context. Both agents receive the same context version, so the final answer can show which source, policy, and version shaped the response.
from typing import TypedDict
from langgraph.graph import END, START, StateGraph
class AgentState(TypedDict):
user_id: str
question: str
metric: str
context_version: str
evidence: list[dict]
policy_result: dict
answer: str
class SharedContextRepo:
def fetch(self, \*, user_id: str, agent_role: str, intent: str, terms: list[str]) -> dict:
return {
"version": "rev-2026-06-07",
"agent_role": agent_role,
"terms": {
"ARR": {
"definition": "Annual recurring revenue recognized under the finance-approved metric policy.",
"owner": "Finance Analytics",
"source_id": "business\_glossary.term.arr",
"last_reviewed": "2026-05-18",
"certification": "approved",
}
},
"lineage": \[
{
"asset": "mart_finance.arr_by_account",
"source_id": "lineage.asset.mart_finance.arr_by_account",
"quality": "certified",
}
],
"policies": \[
{
"id": "policy.customer_revenue_visibility",
"decision": "allow_with_masking",
"reason": "User can view aggregated ARR, not raw account-level revenue.",
}
],
"handoff_contract": {
"must_preserve": \["metric source", "policy decision", "context version"],
"do_not_share": \["raw restricted rows"],
},
}
repo = SharedContextRepo()
def data_agent(state: AgentState) -> AgentState:
context = repo.fetch(
user_id=state["user_id"],
agent_role="data_agent",
intent="answer revenue question",
terms=[state["metric"\]],
)
state["context_version"] = context["version"\]
state["evidence"\].append(
{
"agent": "data_agent",
"source_id": context["lineage"[0]["source_id"],
"source_type": "lineage",
"context_version": context["version"],
"policy_ids": \[p\["id"\] for p in context["policies"\]],
}
)
return state
def policy_agent(state: AgentState) -> AgentState:
context = repo.fetch(
user_id=state["user_id"],
agent_role="policy_agent",
intent="check revenue access",
terms=[state["metric"\]],
)
state["policy_result"] = {
"allowed": context["policies"[0]["decision"] == "allow_with_masking",
"policy\_id": context["policies"[0]["id"],
"reason": context["policies"[0]["reason"],
"context_version": context["version"],
}
state["evidence"\].append(
{
"agent": "policy_agent",
"source_id": context["policies"[0]["id"],
"source_type": "policy",
"context_version": context["version"],
"policy_ids": \[context["policies"[0]["id"\]],
}
)
return state
def supervisor(state: AgentState) -> AgentState:
if not state["policy_result"\]\["allowed"\]:
state["answer"] = "I cannot answer this request with the user's current access."
return state
state["answer"] = (
f"Use {state['metric'\]} from certified finance context. "
f"Policy applied: {state['policy_result'\]\['policy\_id'\]}. "
f"Context version: {state['context_version'\]}."
)
return state
graph \= StateGraph(AgentState)
graph.add\_node("data_agent", data_agent)
graph.add\_node("policy_agent", policy_agent)
graph.add\_node("supervisor", supervisor)
graph.add\_edge(START, "data_agent")
graph.add\_edge("data_agent", "policy_agent")
graph.add\_edge("policy_agent", "supervisor")
graph.add\_edge("supervisor", END)
app = graph.compile()
This pattern separates four things that often get blurred:
-
Workflow state: The graph state tracks the task, evidence, policy result, and final answer.
-
Governed context: The shared repository returns definitions, lineage, policies, freshness signals, and handoff rules.
-
Agent behavior: Each agent receives instructions and context tailored to its role, but the source of truth remains shared.
-
Decision trace: Each agent adds evidence explaining which context version, source, and policy shaped the output.
The same design can be implemented in CrewAI, Amazon Bedrock Agents, OpenAI Agents SDK, Google ADK, or a custom orchestration layer. What should stay consistent is the contract between agents and context: where trusted context comes from, which slice each agent can use, what policy applies, and how the decision is traced.
In practice, that contract starts with subtraction. Each agent should receive the smallest context slice that enables it to fulfill its role without losing the shared meaning needed for coordination.
Teams should define this at the agent-contract level: role, inputs, outputs, tools, allowed actions, context sources, handoff requirements, and trace requirements. That keeps agents specialized without turning every agent into a copy of the whole enterprise knowledge base.
What failure modes should the architecture prevent?
Permalink to “What failure modes should the architecture prevent?”Multi-agent systems fail in ways that single-agent systems do not.
A good multi-agent context architecture is designed to catch these issues before they spread across the workflow:
| Failure mode | What it looks like | How to prevent it |
|---|---|---|
| Context collision | Two agents use different definitions for the same metric | Certified definitions, context versions, and shared glossary retrieval |
| Handoff dilution | A downstream agent receives the answer but not the assumptions behind it | Handoff contracts, evidence bundles, and trace IDs |
| Stale memory | A prior correction or old user preference overrides the current policy | Memory expiry, consolidation, review status, and freshness checks |
| Over-broad retrieval | Agents receive too much context and choose irrelevant details | Role-scoped retrieval, ranking, filtering, and compaction |
| Tool ambiguity | Agents call the wrong API or misread tool outputs | Tool instructions, schemas, allowed action lists, and evals |
| Policy bypass | One agent applies the policy, but another takes action without it | Central policy checks before retrieval, tool calls, and final actions |
| Unreviewed learning | Agent feedback becomes a durable business truth without approval | Proposed context updates, domain review, and committed enterprise memory |
| Trace gaps | The final answer cannot be explained across agents | End-to-end observability and decision traces |
This is the enterprise version of context engineering. It is less about adding more context to the prompt and more about controlling how context is selected, trusted, changed, and carried across the system.
Where do MCP and A2A fit?
Permalink to “Where do MCP and A2A fit?”MCP and A2A are useful, but they solve different parts of the system.
Anthropic introduced MCP as an open standard for connecting AI assistants to systems where data lives, including business tools, content repositories, and development environments. In a multi-agent system, MCP is a clean way to expose governed tools, metadata, policies, and context sources to agents.
Google’s A2A announcement frames A2A as an open protocol for agent collaboration across frameworks and vendors. It supports capability discovery, task management, collaboration, and secure information exchange between the client and remote agents.
The boundary is important:
| Layer | What it solves | What it does not solve |
|---|---|---|
| MCP | Agent access to tools, data, and context servers | Which business definition is certified |
| A2A | Agent-to-agent collaboration, task state, and handoffs | Whether the agents share the same business meaning |
| Context layer | Governed meaning, lineage, policies, ownership, memory, and trust signals | The full orchestration runtime |
In practice, production systems need all three. A planner agent may use A2A-style handoffs to coordinate with specialist agents. Each specialist may use an MCP server to retrieve context or execute a tool. The shared semantic layer and context layer make sure those calls return consistent business meaning.
Protocols move work and context. The context layer makes that context trustworthy.
How does Atlan support multi-agent context engineering?
Permalink to “How does Atlan support multi-agent context engineering?”Atlan’s role is to serve as the shared enterprise context layer beneath agent frameworks.
Instead of treating context as static prompt text, Atlan turns existing metadata, definitions, lineage, policies, quality signals, and usage patterns into machine-readable context that agents can retrieve and trust. That matters in multi-agent systems because every specialist agent needs a role-specific view of the same enterprise truth.
Core capabilities map naturally to the architecture:
-
Enterprise Data Graph: Connects assets, glossary terms, lineage, policies, owners, and usage signals into a living graph of enterprise context.
-
Context Engineering Studio: Helps teams bootstrap, test, simulate, refine, and deploy context for AI use cases.
-
Context Repos: Package semantic models, skill files, evals, policies, and examples into reusable context units for agents.
-
Atlan MCP: Exposes governed context to agent stacks through Atlan MCP and related interfaces.
-
Context Lakehouse: Stores and serves context from a Context Lakehouse designed for scale and interoperability.
-
AI Governance: Adds AI governance, access controls, observability, and decision traces around agent behavior.
The practical outcome is straightforward: agents can be built in LangGraph, CrewAI, Claude, ChatGPT, Snowflake Cortex, Genie, or custom stacks while subscribing to the same governed context foundation.
That prevents the next version of the old BI problem, where every team builds its own logic, and every tool gives a different answer.
How should teams get started?
Permalink to “How should teams get started?”Start with one high-value workflow and one shared context repository.
Do not begin by building ten agents. Begin by choosing a workflow in which incorrect context poses real business risk, such as revenue analysis, customer renewal recommendations, policy review, data access triage, or incident response.
Then build the minimum viable context:
-
Certified terms: The handful of definitions the workflow cannot get wrong.
-
Trusted assets: The tables, dashboards, APIs, and documents agents can use.
-
Policies: The access, privacy, retention, and approval rules that apply.
-
Agent contracts: The role, tools, inputs, outputs, and handoff rules for each agent.
-
Golden questions: The test questions that prove the context works.
-
Trace requirements: The evidence each agent must preserve for review.
-
Feedback path: The process for turning agent corrections into proposed context updates.
Once that repository works for one workflow, add agents around it. The context foundation should scale before the agent roster does.
Start the conversation to see how Atlan helps teams build governed context for enterprise AI agents.
FAQs about multi-agent context engineering
Permalink to “FAQs about multi-agent context engineering”Is multi-agent context engineering the same as shared memory?
Permalink to “Is multi-agent context engineering the same as shared memory?”No. Shared memory records what agents or users have done across sessions. Multi-agent context engineering includes memory, but it also includes certified definitions, lineage, policies, examples, quality signals, ownership, and decision traces. Memory helps agents remember. A context layer helps agents reason from governed business meaning.
Do MCP and A2A replace a context layer?
Permalink to “Do MCP and A2A replace a context layer?”No. MCP helps agents connect to external tools and data sources. A2A helps agents communicate and coordinate across systems. A context layer supplies the governed business meaning those protocols carry, including definitions, policies, provenance, and trust signals.
When should a team use multiple agents instead of one agent?
Permalink to “When should a team use multiple agents instead of one agent?”Use multiple agents when the workflow has clearly separable responsibilities, different tool permissions, different risk boundaries, or specialized review steps. A revenue workflow may need separate data, policy, account, and narrative agents. If the task is narrow and low-risk, one well-scoped agent with strong context is usually simpler.
What is the first context repository a team should build?
Permalink to “What is the first context repository a team should build?”Start with the repository behind one important workflow, not the whole enterprise. Include the terms, data assets, policies, examples, evals, agent contracts, and trace requirements the workflow needs. The first repository should prove that shared context improves accuracy, auditability, and reuse before the pattern expands.
Sources
Permalink to “Sources”Sources and reference materials used for the article:
Gartner: 40% of enterprise applications will feature task-specific AI agents by 2026
LangChain documentation: Multi-agent systems
Amazon Bedrock documentation: Multi-agent collaboration
Anthropic: Introducing the Model Context Protocol
Google Developers Blog: A2A, a new era of agent interoperability
NIST: AI Risk Management Framework
Context engineering in Multi-agent systems
