



















Context engineering tools span 7 distinct infrastructure categories — from metadata platforms and knowledge graphs to MCP servers and AI evaluation frameworks — and production teams in 2026 run 3-5 tools across these categories to build a governed context layer for their AI agents. We scored 25+ tools against vendor-neutral criteria (governance depth, MCP support, context versioning, portability, and category coverage) before naming any winners. The 5-tool governance comparison comes first; the full 7-category reference directory follows. This guide gives you the complete picture: what each category does, which tools lead it, and how to compose the right context engineering framework for your organization.
What are context engineering tools for AI agents?
Permalink to “What are context engineering tools for AI agents?”Context engineering tools are the infrastructure systems governing what AI agents see, trust, and reason from before any query runs. They span 7 categories — from metadata platforms and lineage tools to MCP servers and evaluation frameworks. The key distinction from AI coding tools: these govern the data layer, not the prompt window.
This distinction matters more than it sounds. When developers talk about “context engineering” in tools like Cursor, Claude Code, or GitHub Copilot, they mean managing what context engineering means for a coding session — which files are in scope, which memories are loaded, how the context window is used. That is a context engineering vs. prompt engineering problem at the prompt layer.
Enterprise context engineering tools solve a fundamentally different problem: they govern the data layer that AI agents query in production. A Text-to-SQL agent doesn’t just need context in its prompt — it needs certified table definitions, verified business glossary terms, traceable column lineage, and access policies that reflect who owns each asset. That is a context architecture for AI agents problem, not a prompt problem.
Most teams buying “context engineering” point solutions are actually solving a delivery problem while ignoring the governance problem — and that’s why their agents keep hallucinating on the same business terms six months after deployment. Context engineering and AI governance must be co-designed, not bolted on separately.
Quick facts
Permalink to “Quick facts”| Metric | Value | Source |
|---|---|---|
| Categories in a complete context engineering stack | 7 | Atlan research, 2026 |
| Tools reviewed in this guide | 25+ | Atlan |
| MCP SDK monthly downloads (2026) | 97M+ | Anthropic / MCP ecosystem |
| LLM observability market size (2026) | $2.69B | CloudZero / Confident AI research |
| AI agent accuracy with governed context | 94-99% | Atlan benchmark |
| AI agent accuracy without governed context | 10-31% | Atlan benchmark |
How to evaluate context engineering tools: vendor-neutral scoring criteria
Permalink to “How to evaluate context engineering tools: vendor-neutral scoring criteria”Production context engineering deployments fail at the governance layer, not the delivery layer. Before comparing any specific tool, here are the five dimensions that determine whether a platform holds up at enterprise scale:
| Scoring Dimension | What It Measures | Why It Matters |
|---|---|---|
| Governance depth | Certification workflows, access policy enforcement, staleness detection at the data source | Prevents context rot and hallucination at the source — not after the fact |
| MCP support | Native MCP server with runtime access policy enforcement (not static credential scope) | Context delivery must carry governance with it; static scope leaves the enforcement gap open |
| Context versioning | Ability to version context products, run A/B tests on context changes, maintain change history | Context drifts; versioning makes drift visible and recoverable |
| Portability | License freedom (Apache 2.0 > MIT > proprietary SaaS) and self-host capability | Reduces lock-in at the delivery layer where open-source options are strongest |
| Category coverage | Number of the 7 categories natively covered without separate integrations | More native coverage = fewer integration failure points and less governance gap risk |
5-tool focused comparison: context engineering platforms
Permalink to “5-tool focused comparison: context engineering platforms”The table below compares the 5 platforms that claim to solve the “context engineering” problem for AI agents in production — from developer-first memory frameworks to enterprise-grade governed context layers. Data governance vendors (covered in Category 1 of the full 7-category stack) govern the substrate that context engineering platforms serve from, but are not themselves context engineering platforms. For a full vendor landscape including governance tools, see context engineering platforms compared.
| Tool | Governance Score | MCP Delivery | Context Versioning | Portability | Approach | Best For |
|---|---|---|---|---|---|---|
| LlamaIndex | 1/5 | Via integrations | No | High (MIT, self-host) | Data retrieval framework for context assembly | Teams building custom RAG or retrieval pipelines |
| Mem0 | 1/5 | No native MCP | No | High (Apache 2.0, self-host) | Vector + graph memory extraction for agents | Developer-first memory layer; rapid agent prototyping |
| Zep Enterprise | 2/5 | No | Partial (temporal versioning) | Low (SaaS; CE deprecated Apr 2025) | Temporal knowledge graph for long-running sessions | Stateful agents that need persistent session memory |
| Contextual AI | 3/5 | Yes (HTTPS managed) | No | Low (SaaS) | RAG-native context engineering platform for enterprise docs | Enterprises grounding agents in proprietary document corpora |
| Atlan | 5/5 | Yes — runtime access enforcement | Yes (Context Engineering Studio) | Medium (SaaS + export) | Governed enterprise context layer — EDG + Context Agents + CES + Context Lakehouse | Enterprise AI agents needing certified, explainable, governed context at scale |
Governance score key (5-point scale): Each dimension scores 1 point: certification workflows that document who approved a definition (+1), runtime access policy enforcement at MCP query time — not static credential scope (+1), context versioning and A/B testing capability (+1), column-level lineage with physical traceability to source (+1), active business glossary linked to physical lineage — not standalone documentation (+1).
LlamaIndex and Mem0 score 1/5 because they are frameworks, not governance platforms — excellent at context assembly and memory extraction, but governance is out of scope by design. Zep Enterprise scores 2/5 for its temporal versioning model, but lacks certification and MCP governance. Contextual AI scores 3/5: it has document access controls, grounding, and retrieval provenance (+3), but no column-level lineage or enterprise glossary. Atlan scores 5/5 because it is the only platform that provides all five governance dimensions natively — and it delivers context via governed MCP with runtime access enforcement, not static credentials.
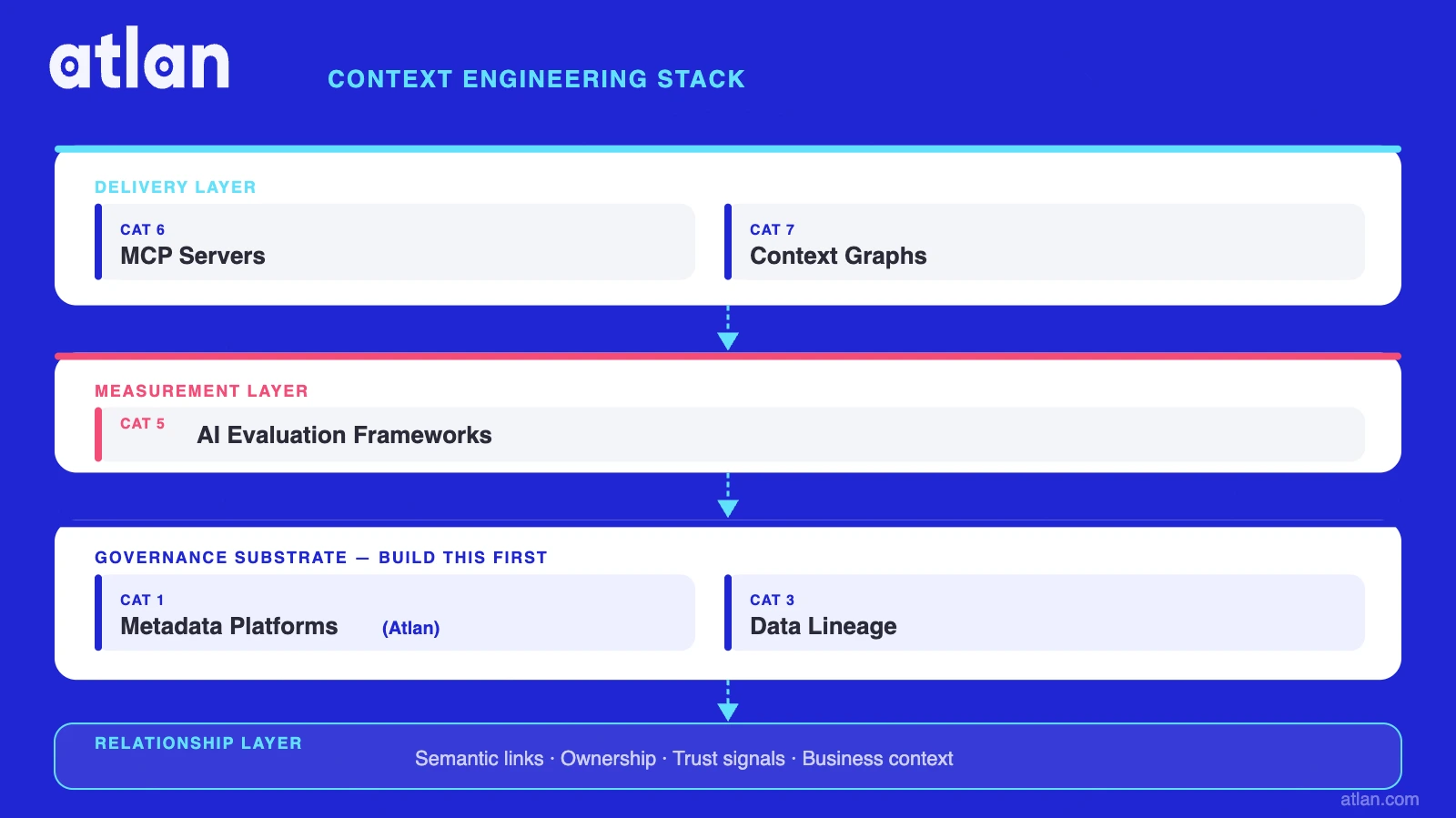
Context engineering tools at a glance: the 7-category reference directory
Permalink to “Context engineering tools at a glance: the 7-category reference directory”| Tool | Category | Best For | Key Differentiator | Open Source | MCP Support | Pricing Model |
|---|---|---|---|---|---|---|
| Atlan | 1, 3, 4, 6 | Enterprise context layer + governed MCP delivery | Four-product platform (EDG + Context Agents + CES + Context Lakehouse); runtime access policy enforcement at MCP query time | No | Yes (native) | Enterprise |
| Neo4j | 2, 7 | Graph database + GraphRAG | Industry-standard graph DB; native GraphRAG library; MCP server | Community edition | Yes (neo4j-mcp-server) | Free / Enterprise |
| Amazon Neptune | 2 | AWS-native graph workloads | Fully managed; property graph + RDF/SPARQL dual model | No | No | AWS pay-as-you-go |
| Stardog | 2 | Ontology-heavy enterprise KG | Built-in reasoning engine; SPARQL; enterprise security | No | No | Enterprise |
| Promethium AI | 2 | Federated zero-copy agent access | 200+ sources; five-level multi-dimensional context | No | No | Enterprise |
| Acceldata ADM | 3 | AI-powered autonomous lineage | AI lineage agent; autonomous hidden dependency detection | No | No | Enterprise |
| Atlan (lineage) | 3 | Column-level lineage + staleness detection | Active metadata flags downstream impact on definition change | No | Yes (native) | Enterprise |
| dbt (Semantic Layer) | 3 | Transformation lineage + certified metrics | Lineage baked into the DAG; semantic layer = certified metric API | Open source core | No | Free / Enterprise |
| OpenLineage / Marquez | 3 | Open lineage standard + interoperability | Apache 2.0 open standard; lingua franca for lineage portability | Yes (Apache 2.0) | No | Free |
| Protégé | 4 | OWL ontology engineering | Stanford-developed; W3C OWL standard; extensible | Yes (free) | No | Free |
| TopBraid EDG | 4 | Enterprise taxonomy governance | Graph-based; SHACL validation; enterprise workflows | No | No | Enterprise |
| PoolParty Semantic Suite | 4 | Multilingual taxonomy management | SKOS/OWL; knowledge graph integration; multilingual | No | No | Enterprise |
| Skan AI (AOW) | 4 | Agentic ontology of work | Purpose-built for human-AI collaboration ontologies (Feb 2026) | No | No | Enterprise |
| Langfuse | 5 | Open-source production tracing | MIT license; self-hostable; native RAGAS integration | Yes (MIT) | No | Free / Cloud |
| LangSmith | 5 | LangChain/LangGraph stacks | Deepest LangGraph integration; prompt hub + versioning | No | No | Free tier / Enterprise |
| RAGAS | 5 | RAG pipeline quality validation | Open standard metrics; framework-agnostic integration | Yes (open source) | No | Free |
| DeepEval (Confident AI) | 5 | CI/CD evaluation as a deployment gate | Pytest-style API; CI/CD integration; agent-specific metrics | Partial | No | Free / Enterprise |
| Arize Phoenix | 5 | OpenTelemetry-native multi-turn eval | OpenTelemetry standard; production monitoring | Yes (open source) | No | Free / Enterprise |
| Maxim AI | 5 | Closed-loop LLM observability | Production to eval to simulation closed loop; RAGAS built-in | No | No | Enterprise |
| Atlan MCP Server | 6 | Governed MCP delivery for enterprise data | Access policy engine enforces permissions at query time | No | Native | Enterprise (incl. with Atlan) |
| GitHub MCP Server | 6 | Repository context for agents | Official; repository metadata + code context | No | Native | Free / Enterprise |
| Notion MCP Server | 6 | Document context for agents | Official; document + database context | No | Native | Free / Enterprise |
| Stripe MCP Server | 6 | Payment data context for agents | Official; payment and customer data | No | Native | Pay-as-you-go |
| TrustGraph | 7 | Sovereign context graph + OntologyRAG | Full-stack: context graphs + memory + retrieval + orchestration | Yes (Apache 2.0) | Yes | Open source |
| Graphiti (by Zep) | 7 | Temporally-aware knowledge graphs | Bi-temporal model; real-time updates; full MCP server | Yes (open source) | Yes (graphiti-mcp-server) | Free / Enterprise |
| Neo4j GraphRAG | 7 | Graph-backed structured retrieval | Industry-standard storage backend; GraphRAG library | Community edition | Yes | Free / Enterprise |
| Cognee | 7 | Memory control plane for AI agents | Apache 2.0; MCP native; 30+ sources; 6-line setup | Yes (Apache 2.0) | Yes | Free / Enterprise |
| Zep Enterprise | 7 | Stateful enterprise agent memory | Temporal KG for long-running sessions; enterprise support | No (CE deprecated Apr 2025) | No | Enterprise |
Why do AI agents need a multi-category tool stack?
Permalink to “Why do AI agents need a multi-category tool stack?”Because no single tool governs the full context lifecycle. A knowledge graph structures relationships but doesn’t certify business definitions. A metadata platform governs provenance but doesn’t handle temporal agent memory. Evaluation frameworks measure quality but don’t fix upstream data problems. Production agents need all 7 layers — composed, not replaced.
The fragmentation failure mode is predictable: teams build context delivery first and governance last, if at all. Agents using ungoverned data produce answers that are internally consistent but semantically wrong — “revenue” calculated differently across two business units, a “customer” definition that varies by region, a churn metric that changed methodology six months ago. The answers are fluent. The business logic is broken.
Counter-argument: “Why not just use RAG?”
RAG (Retrieval-Augmented Generation) is one technique that sits at the boundary of Categories 3 and 5 in this stack. It improves retrieval relevance. What it doesn’t do is certify that the retrieved document is authoritative, enforce access policies on which data the agent can retrieve, define business terms consistently, or detect when an upstream definition changes and the retrieved document becomes stale. RAG is a delivery mechanism, not a three-layer context infrastructure model. See the full context engineering vs. RAG comparison for what each solves. Both are necessary.
Counter-argument: “Why not just use a long context window?”
Context rot research on 18 frontier models (Chroma, 2025) shows quality drops sharply well before advertised window limits — not gradually as most teams assume. Filling a 128K context window with data doesn’t improve reasoning quality; it frequently degrades it. The distinction between in-context vs. external memory matters precisely here — context engineering is about selecting and governing the right context, not stuffing more tokens.
Counter-argument: “Open source is sufficient”
Open-source tools cover delivery and evaluation well. TrustGraph, Graphiti, Cognee, Langfuse, and RAGAS are all mature, usable options in their categories. The gap is governance — building certification workflows, access policies, active staleness detection, and a business glossary backed by physical lineage is genuinely hard to self-build. This is where enterprise metadata platforms earn their license cost.
What production teams actually run: Most enterprise teams in 2026 operate 3-5 tools: a metadata platform for governance (Cat 1), a knowledge or context graph for relationships (Cat 2 or 7), an evaluation framework for quality measurement (Cat 5), and MCP servers for delivery (Cat 6). The 5-phase context engineering framework maps how these layers connect. For teams building a unified context layer, the governance stack (Cat 1-4) is the foundation everything else runs on.
Using governed context, AI agents achieve 94-99% accuracy versus 10-31% without it — a gap that no prompt engineering technique closes. (Source: Atlan)
The 7 categories of context engineering tools at a glance
Permalink to “The 7 categories of context engineering tools at a glance”| Category | Role in the Context Stack | Representative Tools | Governance Depth | MCP Support | Portability | Open Source Option |
|---|---|---|---|---|---|---|
| 1. Metadata platforms | Govern discoverability, certification, access at the source | Atlan | High | Yes (Atlan native MCP with runtime enforcement) | Medium (SaaS + export) | No |
| 2. Knowledge graph tools | Structure entity relationships for traversal | Neo4j, Neptune, Stardog, Promethium | Medium | Yes (Neo4j) | Medium–High (Neo4j community edition; Neptune is managed AWS) | Yes (Neo4j community) |
| 3. Data lineage tools | Trace provenance; answer “can I trust this?” | Atlan, Acceldata, OpenLineage, dbt | High | Indirect | High (OpenLineage Apache 2.0; dbt open source core) | Yes (OpenLineage) |
| 4. Business glossary / ontology | Define terms in human + machine-readable form | Atlan, Protégé, TopBraid, PoolParty | High | Via Cat. 1 | Medium–High (Protégé free; commercial options are SaaS) | Yes (Protégé) |
| 5. AI evaluation frameworks | Measure if agents use context correctly | Langfuse, LangSmith, RAGAS, DeepEval | Low (measures, not governs) | No | High (Langfuse MIT; RAGAS open source; self-hostable) | Yes (Langfuse, RAGAS) |
| 6. MCP servers | Deliver context to agents via standard protocol | Atlan MCP, GitHub MCP, Notion MCP, Stripe MCP | Policy-enforced (Atlan only) | Native | Medium (Atlan is SaaS; GitHub, Notion, Stripe MCP are free tiers) | Yes (many) |
| 7. Context graph tools | Build queryable, relationship-aware knowledge representations | TrustGraph, Graphiti, Cognee, Neo4j GraphRAG, Zep | Medium | Yes (all major) | High (TrustGraph Apache 2.0; Cognee Apache 2.0; Graphiti open source) | Yes (TrustGraph, Cognee, Graphiti) |
The categories are ordered as a stack for a reason. Governance sits at the base (Categories 1-4) because context must be trustworthy before it’s delivered. Delivery mechanisms (Categories 6-7) sit at the top — they are fast and increasingly standardized, but they amplify whatever quality the substrate holds. Evaluation (Category 5) spans all layers: you can measure the quality of retrieved context regardless of which delivery mechanism you’re using.
Teams that skip the governance substrate and build straight to MCP delivery or context graphs are optimizing the last mile while leaving the source ungoverned. For a deeper treatment of Category 7, see our guide to context graph tools for AI agents.
Category 1: Metadata platforms
Permalink to “Category 1: Metadata platforms”Metadata platforms are the governance foundation of a context engineering stack. They determine which data assets are discoverable, certified, and trustworthy before any agent query runs. In 2026, MCP support is the differentiating factor — platforms that expose governed metadata through MCP give agents access to certified context at query time, not at setup time.
Atlan
Permalink to “Atlan”Atlan is a four-product context engineering platform — Enterprise Data Graph, Context Agents, Context Engineering Studio, and Context Lakehouse — with 80+ connectors that governs the full context layer for AI agents: unified semantic layer, column-level lineage, business glossary, certification, and access governance in a single platform. Context Agents had auto-generated 690,000+ descriptions across 50+ enterprise customers by April 2026, compressing 9–12 months of enrichment work into weeks.
The MCP server exposes four tools to AI agents: search_assets, get_assets_by_dsl, traverse_lineage, and update_assets. The access policy engine filters MCP results at query time — the agent sees only what the requesting user is permitted to see, enforced at the moment of query rather than at setup. Among the enterprise data catalog platforms reviewed here, Atlan’s MCP is the only documented Category 1 implementation with runtime access policy enforcement rather than static credential-based scoping.
Pros: MCP with runtime access policy enforcement; active metadata (continuous event-driven, not snapshot); spans Categories 1, 3, and 4 in a single platform; Context Agents at scale across enterprise customers
Cons: Enterprise pricing and implementation timeline; overkill for single-source or small-team deployments; steeper onboarding than point solutions
Pricing: Enterprise (contact for pricing)
URL: atlan.com | Atlan MCP Server documentation
Informatica IDMC
Permalink to “Informatica IDMC”Informatica IDMC is a comprehensive AI-powered data management platform built around the CLAIRE AI engine for metadata discovery, data classification, and relationship mapping. It covers MDM, data quality, cloud data integration, and cataloging — making it the broadest enterprise data management platform in Category 1.
In 2026, Informatica announced native MCP support, positioning IDMC as an enterprise data management platform with headless MCP access to its governed data layer. For hybrid enterprise environments managing data across on-premises and multi-cloud environments, IDMC provides unified governance across that span.
Pros: Broad MDM + data quality + cataloging in one platform; native MCP support (2026); strong hybrid enterprise capability; CLAIRE AI engine for automated metadata enrichment
Cons: Complex licensing with multiple module tiers; heavier implementation than dedicated data catalog platforms; less developer-friendly than newer catalog tools
Pricing: Enterprise
URL: informatica.com
Microsoft Purview
Permalink to “Microsoft Purview”Microsoft Purview provides real-time auto-capture of metadata across Azure and Microsoft 365 assets, with built-in classification for sensitive data and policy enforcement. For organizations that run their data estate on Microsoft infrastructure, Purview offers the tightest integration — metadata governance is native to the stack rather than bolted on.
Pros: Real-time metadata capture; native Azure and M365 integration; automated sensitive data classification; enforces policies across Microsoft workloads
Cons: Limited utility outside the Microsoft ecosystem; data catalog capabilities less mature than dedicated context engineering platforms like Atlan; slower adoption of modern AI agent patterns
Pricing: Included with Microsoft 365 E5 / Azure subscription tiers
URL: microsoft.com/en-us/security/business/microsoft-purview
Category 1 bottom line: For enterprise teams where AI agents must operate on certified, governed data, the metadata platform is the most important investment in the stack. All context delivered to agents downstream is only as trustworthy as the source. Atlan is the only Category 1 platform with documented runtime access policy enforcement at MCP query time — making it the governance foundation for production AI agent deployments in 2026.
Category 2: Knowledge graph tools
Permalink to “Category 2: Knowledge graph tools”Knowledge graph tools structure the relationships between entities — products, people, concepts, events — making context traversable rather than flat. Where a metadata platform certifies individual assets, a knowledge graph maps how those assets relate. For AI agents, this means the difference between retrieving a fact and understanding its context within a network of connected facts.
Neo4j
Permalink to “Neo4j”Neo4j is the industry-standard graph database, with the largest ecosystem of graph tooling in the market. Its native GraphRAG library enables structured knowledge retrieval from graph data, and a published MCP server (neo4j-mcp-server) lets AI agents interact directly with the graph. Most Graphiti and TrustGraph deployments use Neo4j as the storage backend.
Neo4j’s own context engineering tools listicle signals how seriously the company is investing in agentic AI positioning — it’s a sign of category maturity when the storage layer vendor writes the content map.
Pros: Largest graph community; GraphRAG library; MCP server; enterprise clustering and security; broad language support
Cons: Self-managed operational overhead; GraphRAG requires significant implementation work to deliver production-quality results; context graph reasoning layer is still DIY on top of Neo4j storage
Pricing: Community Edition (free) / Enterprise (contact)
URL: neo4j.com
Amazon Neptune
Permalink to “Amazon Neptune”Amazon Neptune is the fully managed graph database service on AWS, supporting both property graphs via Gremlin and RDF graphs via SPARQL. Neptune Analytics (a separate serverless analytics layer) adds vector similarity search for hybrid graph + embedding queries — a pattern relevant for teams building knowledge graph-backed RAG pipelines on AWS.
For AWS-native organizations that need managed graph infrastructure without operational overhead, Neptune is the natural fit. Storage scales automatically and the service handles clustering, patching, and failover.
Pros: Fully managed with no infrastructure to operate; dual-model (property graph + RDF) flexibility; Neptune Analytics adds vector search; native AWS IAM authentication and VPC integration
Cons: Less community tooling than Neo4j for AI agent patterns; no native MCP server; Gremlin/SPARQL skill requirements add ramp-up time for teams coming from SQL; harder to migrate across clouds if requirements change
Pricing: AWS pay-as-you-go (instance + I/O pricing; Neptune Serverless available)
Stardog
Permalink to “Stardog”Stardog is an enterprise knowledge graph platform with built-in reasoning engine, SPARQL, and a virtual graph capability that lets you query relational databases as if they were part of the knowledge graph — without moving data. For organizations with complex regulatory taxonomies or formal ontology requirements, Stardog’s inference engine can derive new facts from existing ones using OWL reasoning rules.
Pros: Built-in OWL reasoning engine; SPARQL for expressive graph queries; virtual graph for federated access to relational sources; enterprise role-based access control
Cons: Niche skill set required (SPARQL, formal ontology, OWL reasoning); smaller community than Neo4j for AI agent tooling; steeper total cost than open-source graph databases; no native MCP server
Pricing: Enterprise (contact for pricing)
URL: stardog.com
Promethium AI
Permalink to “Promethium AI”Promethium AI offers federated, zero-copy data access across 200+ sources with a claimed five-level multi-dimensional context model. Its agent-native architecture is designed for AI systems that need to query across disparate sources — databases, data warehouses, APIs, files — without centralizing data, which is relevant for organizations with data residency requirements or fragmented source landscapes.
Note: Promethium has limited third-party case study documentation publicly available; the five-level context model is the company’s own framing, not an independently validated benchmark.
Pros: Federated architecture with no data movement; broad source coverage (200+ connectors claimed); purpose-built for AI agent query patterns; no central data warehouse required
Cons: Proprietary architecture with limited community transparency; no independent benchmarks available; smaller ecosystem than Neo4j for agent tooling; less community validation overall
Pricing: Enterprise
URL: promethium.ai
Category 2 bottom line: For most teams, Neo4j is the default choice — the community, tooling, and GraphRAG library create the lowest-friction path to graph-backed context. Amazon Neptune wins for AWS-native teams that need fully managed infrastructure. Stardog and Promethium serve more specialized requirements.
Category 3: Data lineage tools
Permalink to “Category 3: Data lineage tools”Data lineage tools answer the question every AI agent implicitly asks before reasoning: “Can I trust this data?” Column-level lineage traces where a value came from, what transformed it, and who owns it. Without lineage, agents can’t distinguish a certified metric from a stale ETL artifact — and neither can your auditors.
Atlan (lineage layer)
Permalink to “Atlan (lineage layer)”Atlan’s lineage layer provides column-level lineage with impact analysis, using event-driven active metadata management to flag downstream context products when upstream definitions change. This prevents silent column-level data lineage drift — the failure mode where a source definition changes and everything downstream silently becomes wrong.
Pros: Active lineage (event-driven, not scheduled snapshot); cross-category integration with Cat 1 metadata and Cat 4 business glossary; downstream impact alerts prevent context rot
Cons: Full value requires the broader Atlan platform investment; not available as a standalone lineage-only tool; implementation effort proportional to estate size
Pricing: Enterprise (included with Atlan platform)
Acceldata ADM
Permalink to “Acceldata ADM”Acceldata ADM includes an AI-powered Data Lineage Agent that continuously maps data flows, autonomously traces upstream sources, identifies downstream impact, and detects hidden dependencies that manual lineage mapping misses. It positions itself as agentic lineage for the agentic AI era.
Pros: AI-driven lineage discovery; autonomous detection of hidden dependencies; continuous monitoring rather than batch crawl
Cons: Less established than Atlan for enterprise data catalog integration; newer in the enterprise governance market; lineage-focused without the broader governance platform depth
Pricing: Enterprise
URL: acceldata.io
OpenLineage / Marquez
Permalink to “OpenLineage / Marquez”OpenLineage is the Apache 2.0 open standard for data lineage, with Marquez as the reference implementation. It has become the lingua franca for lineage interoperability across tools — dbt, Spark, Airflow, Flink, and dozens of other tools emit OpenLineage events natively.
Pros: Open standard with no vendor lock-in; broad tool support across the modern data stack; Marquez reference implementation is free; best choice for teams that need interoperability across multiple lineage-emitting tools
Cons: Marquez reference implementation requires significant operational investment to run at scale; governance layer (certification, access policy) is DIY; not a complete governance solution
Pricing: Free (open source)
URL: openlineage.io
dbt (via Semantic Layer)
Permalink to “dbt (via Semantic Layer)”dbt (data build tool) isn’t a lineage tool in the traditional sense, but its DAG-based transformation model makes lineage intrinsic — every transformation has a documented upstream dependency. The dbt Semantic Layer exposes certified business metrics as an API, giving AI agents access to trustworthy KPIs rather than raw table counts.
Pros: Lineage is inherent to the transformation model, not an add-on; semantic layer provides a certified metrics API for agents; transformation-aware context with natural business term anchoring
Cons: Only covers transformation lineage; doesn’t address ingestion lineage (from source to warehouse) or consumption lineage (from warehouse to downstream agents); best used in combination with a catalog platform
Pricing: Open source core / dbt Cloud Enterprise
URL: getdbt.com
Category 3 bottom line: OpenLineage is the right foundation for teams that want interoperability across their data stack. Atlan’s lineage layer is the right choice for teams that need active governance — where staleness detection and downstream impact alerts matter more than raw portability. dbt’s semantic layer is valuable regardless of which lineage tool you choose.
Category 4: Business glossary and ontology systems
Permalink to “Category 4: Business glossary and ontology systems”Business glossaries define what “revenue” means in your organization. Ontologies make that definition machine-readable so agents can reason about it, not just retrieve it. Without this layer, agents answer with syntactically correct information that violates business semantics — the most common failure mode in enterprise AI deployments and the hardest to detect post-production.
Atlan Business Glossary
Permalink to “Atlan Business Glossary”Atlan’s active business glossary links certified terms directly to physical tables via lineage — a design where glossary definitions are traceable to their source data rather than existing as standalone documentation. Certified terms are consumable via the Atlan MCP server, and Context Agents auto-generate and enrich definitions at scale — having produced 690,000+ descriptions across 50+ enterprise customers.
See the Category 1 profile for the full Atlan platform coverage. The glossary layer operates as a component of the broader platform, not a standalone offering.
Pros: Active glossary linked to physical lineage (not just documentation); certified terms surfaced via MCP; Context Agents for scale; cross-category integration
Cons: Not available as a standalone glossary tool; full value requires the Atlan platform; implementation investment proportional to estate size
Pricing: Enterprise
URL: atlan.com
Protégé
Permalink to “Protégé”Protégé is the Stanford-developed open-source ontology editor and the most widely adopted tool for building W3C OWL ontologies. With decades of academic and enterprise adoption, it is the foundational tool for ontology engineers and researchers who need to build formal machine-readable definitions.
Pros: Free and open source; W3C OWL standard compliance; large academic and enterprise community; extensive plugin ecosystem for ontology reasoning and visualization
Cons: Steep learning curve for non-ontology engineers; no native AI agent integration; UX shows its age; requires significant expertise to build production-quality ontologies
Pricing: Free
URL: protege.stanford.edu
TopBraid EDG (TopQuadrant)
Permalink to “TopBraid EDG (TopQuadrant)”TopBraid EDG is an enterprise data governance platform built around graph-based ontology management, with support for SKOS taxonomies, OWL ontologies, and SHACL constraint validation. For organizations that need governed taxonomies at enterprise scale with formal constraint checking, TopBraid provides the governance workflow layer that Protégé lacks.
Pros: Graph-based enterprise governance workflows; SHACL validation for ontology correctness; SKOS/OWL support; enterprise-grade access controls
Cons: Enterprise pricing; proprietary platform; steeper total cost than open-source alternatives; smaller market footprint than mainstream data catalog tools
Pricing: Enterprise
URL: topquadrant.com
PoolParty Semantic Suite
Permalink to “PoolParty Semantic Suite”PoolParty Semantic Suite handles thesaurus and taxonomy management with SKOS/OWL support and knowledge graph integration, with a particular strength in multilingual taxonomy use cases where organizations need consistent term definitions across languages.
Pros: Multilingual taxonomy management; SKOS/OWL standards; knowledge graph integration; strong for content classification and information architecture
Cons: Limited traction specifically in the AI agent ecosystem; better fit for content management and information architecture teams than ML engineering teams
Pricing: Enterprise
URL: poolparty.biz
Skan AI (Agentic Ontology of Work)
Permalink to “Skan AI (Agentic Ontology of Work)”Skan AI launched its Agentic Ontology of Work (AOW) in February 2026, providing a shared ontology for actions, activities, processes, and agents in enterprise workflows. The concept addresses a real gap: AI agents collaborating on business processes need a common schema for what a “task,” “approval,” or “handoff” means so they can reason consistently across agent boundaries.
This is the only ontology system in Category 4 purpose-designed for agentic workflows rather than data classification. It targets organizations deploying multi-agent systems where shared process semantics matter more than data taxonomy.
Pros: Purpose-built for agentic workflow ontologies; addresses cross-agent semantic consistency; process-native design
Cons: Launched February 2026 — limited independent validation or production case studies available; ontology schema and integration documentation limited publicly; enterprise adoption early stage; no community edition or open-source track
Pricing: Enterprise
URL: skan.ai
Category 4 bottom line: Most enterprise AI teams don’t have ontology engineers on staff, which is why the active business glossary layer in a metadata platform like Atlan is more practical than a dedicated ontology editor. Protégé remains the right tool for teams that need formal OWL ontology work. TopBraid EDG serves the enterprise governance workflow use case. Skan AI AOW is the only option purpose-built for agentic work ontologies.
See How Atlan Governs the Context Layer
Atlan covers Categories 1, 3, and 4 in one governed platform — metadata governance, column-level lineage, and active business glossary. See how it fits your stack.
What should you evaluate when choosing a context engineering tool?
Permalink to “What should you evaluate when choosing a context engineering tool?”Evaluate context engineering tools across 5 dimensions: governance depth (can it certify and enforce access policies?), MCP support (does it deliver to agents via standard protocol?), lineage coverage (does it trace provenance?), staleness detection (does it flag outdated context automatically?), and open-source option (can you reduce vendor lock-in at the delivery layer?).
Governance depth
Permalink to “Governance depth”Governance depth is the dimension that separates tools that prevent hallucination from tools that measure it after the fact. Tools with deep governance certify context at the source, enforce access policies, detect staleness, and integrate business glossary terms with physical lineage.
What to look for: certification workflows that document who approved a definition; access policy enforcement that limits what agents can retrieve; staleness detection that fires when upstream definitions change; business glossary integration that connects terms to physical assets.
MCP support
Permalink to “MCP support”MCP (Model Context Protocol) has become the de facto delivery standard for AI agents in 2026, with 97M+ monthly SDK downloads. Most agent frameworks now speak MCP natively, which means context tools that don’t expose an MCP interface require custom integration work that grows with every new agent.
What to look for: a native MCP server (not just an adapter); granular tool exposure (what tools does the MCP server publish and what can agents invoke?); access policy enforcement at MCP query time rather than at setup time.
Lineage coverage
Permalink to “Lineage coverage”Lineage is provenance made explicit. For AI agents operating in compliance-sensitive environments, lineage is what makes context auditable — the record of where a value came from, what transformed it, and who is accountable for it.
What to look for: column-level lineage (not just table-level); impact analysis that shows which downstream assets are affected when an upstream definition changes; cross-system lineage that traces data across multiple platforms in a multi-cloud estate.
Staleness detection
Permalink to “Staleness detection”Context drift in AI agents is the silent killer of production agent quality. Unlike a broken API that fails loudly, stale context produces plausible-sounding answers built on outdated definitions. Quality degrades before anyone notices — which is why scheduled crawls and monthly refreshes are insufficient for production governance. Context drift detection requires event-driven infrastructure, not batch polling.
What to look for: active metadata management that responds to events rather than schedules; downstream impact alerts that notify when upstream changes invalidate cached context; freshness timestamps surfaced to the agent at query time.
Open-source option
Permalink to “Open-source option”The delivery and evaluation layers (Categories 5, 6, 7) have strong open-source alternatives. Langfuse, RAGAS, TrustGraph, Cognee, and Graphiti are all genuinely production-usable open-source tools. The governance layer (Categories 1-4) is harder to self-build — certification workflows, access policies, and active staleness detection require sustained engineering investment that most teams don’t have.
What to look for: license type (Apache 2.0 and MIT give the most freedom); community health (GitHub stars, contributor count, release cadence); availability of a managed/hosted option if self-hosting proves operationally expensive.
Category 5: AI evaluation frameworks
Permalink to “Category 5: AI evaluation frameworks”Evaluation frameworks measure whether agents are actually using context correctly — not just whether answers are fluent. They track faithfulness (is the answer grounded in the retrieved context?), contextual precision (did the retrieval surface the right chunks?), and relevancy (did the answer match the intent?). The LLM observability market reached $2.69B in 2026 and is projected to grow to $9.26B by 2030 at a 36.2% CAGR. (Source) Gartner projects LLM observability investments will be present in 50% of GenAI deployments by 2028. (Source)
Langfuse
Permalink to “Langfuse”Langfuse is an MIT-licensed, self-hostable LLM observability platform with production tracing, custom scoring, and native RAGAS integration. It is the most widely adopted open-source option in Category 5, with a strong community and a managed cloud tier for teams that want to avoid self-hosting overhead.
Pros: MIT license (true open source); self-hostable; native RAGAS integration; multi-turn agent tracing support; active community development
Cons: Self-hosting at production scale requires operational investment; managed tier is smaller and less feature-complete than LangSmith’s; less opinionated than DeepEval for CI/CD use cases
Pricing: Free (self-hosted) / Langfuse Cloud
URL: langfuse.com
LangSmith
Permalink to “LangSmith”LangSmith is LangChain’s evaluation and observability platform, offering the deepest integration with LangChain and LangGraph workflows. It combines online and offline evaluation, a prompt hub with versioning, and dataset management — making it a complete observability platform for LangChain-native teams.
Pros: Deepest LangGraph integration; prompt hub + versioning for systematic prompt management; dataset management for offline evals; production-ready managed hosting
Cons: Value proposition drops significantly outside the LangChain ecosystem; less useful for teams using other frameworks; commercial product with LangChain dependency
Pricing: Free tier / Enterprise
URL: smith.langchain.com
RAGAS
Permalink to “RAGAS”RAGAS is the open-source RAG evaluation library that established the standard metrics for measuring context quality: answer relevancy, faithfulness, contextual precision, contextual recall, and contextual relevancy. It integrates with every major evaluation platform (Langfuse, LangSmith, Arize Phoenix) and works as a standalone library.
Pros: Free and framework-agnostic; defines the standard evaluation metrics for RAG quality; integrates with every major evaluation platform; fast to add to existing pipelines
Cons: RAG-specific metrics that don’t cover complex multi-turn agent evaluation scenarios; not designed for agentic workflows with tool use and stateful reasoning
Pricing: Free (open source)
URL: docs.ragas.io
DeepEval (Confident AI)
Permalink to “DeepEval (Confident AI)”DeepEval is a Python-first LLM evaluation framework modeled on Pytest, designed to make evaluation a CI/CD deployment gate rather than an afterthought. It covers both RAG metrics and agent-specific evaluation, with component-level debugging that isolates where context failures occur in a pipeline.
Pros: CI/CD integration that treats evaluation as a deployment gate; Pytest-style API for Python-native teams; agent-specific metrics beyond standard RAG scoring; component-level debugging
Cons: Commercial product with less community than Langfuse or RAGAS for self-hosted deployments; fewer integrations with non-Python stacks
Pricing: Free tier / Enterprise
URL: deepeval.com
Arize Phoenix
Permalink to “Arize Phoenix”Arize Phoenix provides multi-turn agent evaluation and production monitoring built on the OpenTelemetry standard, offering span-level visibility into agent execution. For teams already using OpenTelemetry for infrastructure observability, Phoenix extends that investment to the LLM layer with minimal additional instrumentation.
Pros: OpenTelemetry standard makes instrumentation portable; multi-turn agent evaluation with span-level visibility; production monitoring with alert capabilities
Cons: More setup than Langfuse for teams not already on OpenTelemetry; smaller community than Langfuse or LangSmith
Pricing: Open source / Enterprise
URL: phoenix.arize.com
Maxim AI
Permalink to “Maxim AI”Maxim AI offers closed-loop LLM observability — the production traces feed an evaluation layer, which feeds a simulation environment, which validates improvements before they go back to production. RAGAS metrics are built in as first-class features rather than third-party integrations.
Pros: Closed-loop architecture prevents regression by validating improvements before deployment; RAGAS built-in as native metrics; simulation layer for pre-deployment testing
Cons: Proprietary with less community validation than established open-source tools; newer entrant with smaller enterprise reference base
Pricing: Enterprise
URL: getmaxim.ai
Category 5 bottom line: Langfuse + RAGAS is the default starting point for teams that want open-source observability with standard metrics. DeepEval is the right choice for engineering teams that want evaluation baked into their CI/CD pipeline. LangSmith wins for LangChain-native teams. Arize Phoenix serves teams already invested in OpenTelemetry. Don’t skip Category 5 — context quality degrades silently without it.
Category 6: MCP servers and context delivery interfaces
Permalink to “Category 6: MCP servers and context delivery interfaces”MCP servers are the last mile of the context engineering stack — they translate governed context into a protocol AI agents can query in real time. Since Anthropic introduced the Model Context Protocol in November 2024, the ecosystem has grown to 97M+ monthly SDK downloads. Discovery — not protocol support — is now the primary bottleneck for teams building MCP-native agent pipelines.
Atlan MCP Server
Permalink to “Atlan MCP Server”The Atlan MCP Server exposes the full Atlan data catalog to AI agents via the Model Context Protocol. The four published tools — search_assets, get_assets_by_dsl, traverse_lineage, and update_assets — give agents the ability to discover, inspect, trace, and annotate governed data assets in a single protocol call.
The distinguishing feature is runtime access policy enforcement: the Atlan MCP server filters results by the permissions of the requesting user at query time. Most MCP servers return all available data; Atlan’s server enforces governance on every response. Among major enterprise data catalog MCP servers, Atlan’s is the only one with documented runtime access policy enforcement rather than static credential-based scoping — making it the Category 6 implementation most suited to organizations where governance and data access controls must be preserved at query time.
Pros: Runtime access policy enforcement (governance at query time, not setup time); spans catalog + lineage + glossary in one MCP interface; enterprise customer base
Cons: Requires Atlan platform; no value as a standalone MCP server; best for teams already invested in the Atlan platform
Pricing: Included with Atlan Enterprise
URL: atlan.com/know/what-is-atlan-mcp/
Informatica MCP Server
Permalink to “Informatica MCP Server”Informatica announced native MCP support in 2026, making it an enterprise data management platform with headless MCP access. For Informatica IDMC customers, this brings catalog and lineage metadata within reach of any MCP-compatible agent without custom connectors.
Pricing: Enterprise
URL: informatica.com
GitHub MCP Server
Permalink to “GitHub MCP Server”The official GitHub MCP Server gives agents access to repository metadata, code context, pull requests, issues, and commit history. Exposed tools include repository search, file retrieval, issue management, and PR operations — making it the standard context source for engineering agents, code review agents, and developer tooling workflows.
Authentication is via personal access token or GitHub App. The server does not add governance beyond what GitHub’s existing access controls enforce.
Pricing: Free / GitHub Enterprise (depends on repository visibility)
URL: github.com
Notion MCP Server
Permalink to “Notion MCP Server”The official Notion MCP Server exposes document and database content from Notion workspaces to AI agents. Agents can search pages, retrieve database rows, and create or update content — making it the standard context source for agents that need to operate on knowledge base content, meeting notes, project documentation, or internal wikis.
Authentication is via Notion integration token. Access is scoped to pages and databases the integration has been granted access to.
Pricing: Free / Notion Enterprise (depends on workspace tier)
URL: notion.so
Stripe MCP Server
Permalink to “Stripe MCP Server”The official Stripe MCP Server provides AI agents with access to payment data, customer records, invoices, and transaction history via MCP. Exposed capabilities span the core Stripe API surface — suitable for financial analysis agents, billing support agents, and revenue reporting pipelines. Authentication is via Stripe restricted API keys, with access scoped by key permissions.
Pricing: Pay-as-you-go (standard Stripe API pricing; no MCP-specific fee)
URL: stripe.com
Category 6 bottom line: MCP has standardized context delivery. Most major SaaS platforms now ship official MCP servers. The real constraint in 2026 is discovery — finding which MCP servers exist, which tools they expose, and which have governance signals that indicate data quality. For enterprise data catalog access specifically, Atlan’s MCP server has documented runtime governance enforcement — a differentiator for organizations where access controls must travel with the context. For more on how MCP fits the delivery layer, see context infrastructure for AI agents.
Category 7: Context graph tools
Permalink to “Category 7: Context graph tools”Context graph tools build structured, queryable representations of domain knowledge that ground agent queries in verified, explainable facts. Unlike vector databases (which return “similar” results), context graphs return “related and verified” results — preserving relationships, temporal state, and trust provenance. Gartner predicts that more than 50% of AI agent systems will leverage context graphs by 2028, up from a negligible baseline today.
Category 2 vs Category 7 — the distinction: Category 2 (knowledge graph tools) covers general-purpose graph databases: the storage and query infrastructure for entity relationships. Category 7 covers purpose-built context graph tools: systems that add temporal memory layer capabilities, agent-specific extraction pipelines, ontology grounding, and governance provenance on top of a graph storage layer. Neo4j appears in both because it is the storage backend for most Category 7 implementations — but as a standalone database without the context graph layer, it belongs in Category 2. Tools like Graphiti, TrustGraph, and Cognee are Category 7 because they provide the agent-specific semantic and temporal layer that sits above the storage.
For a deeper treatment of this category, see context graph tools for AI agents and context graphs for AI agents.
TrustGraph
Permalink to “TrustGraph”TrustGraph is a self-described “Context Backend” and agent runtime platform powered by context graphs. It provides the full stack for context-powered AI: context graph construction, memory management, retrieval via OntologyRAG, orchestration, and inference — in a single platform designed for sovereign and private deployments.
OntologyRAG is TrustGraph’s proprietary retrieval pattern that grounds retrieval in ontology structure rather than embedding similarity alone — enabling precision-critical workloads where “similar” answers are insufficient and verified, semantically grounded answers are required.
Pros: Full-stack context infrastructure (not just a storage layer); OntologyRAG for precision-critical retrieval; MCP interoperability for standard agent integration; sovereign deployment for data-sensitive organizations
Cons: Early community maturity relative to Neo4j; significant graph engineering resources required; heavier lift for teams without existing context graph expertise
Pricing: Open source (Apache 2.0)
GitHub: github.com/trustgraph-ai/trustgraph
URL: trustgraph.ai
Graphiti (by Zep)
Permalink to “Graphiti (by Zep)”Graphiti is Zep’s open-source temporally-aware knowledge graph library for AI agents. Its bi-temporal data model — tracking both event time and ingestion time — enables precise temporal queries: “what did the agent know at time T?” This is the critical distinction from standard knowledge graphs that store only current state.
Real-time incremental updates without batch recomputation mean agents can be updated with new facts without rebuilding the entire graph — a meaningful operational advantage for long-running agents. The full MCP server implementation (graphiti-mcp-server) makes Graphiti one of the most accessible Category 7 tools for MCP-native deployments.
Pros: Bi-temporal model enables precise temporal reasoning; real-time incremental updates; full MCP server; 26K+ GitHub stars (as of May 2026); supports Neo4j, OpenAI, Azure OpenAI, Google Gemini, and Anthropic out of the box
Cons: Requires Neo4j as the storage backend; LLM dependency for entity extraction adds latency and cost; operational complexity increases at large-scale deployments
Pricing: Open source core / Zep Enterprise
GitHub: github.com/getzep/graphiti
URL: getzep.com/product/open-source/
Neo4j GraphRAG
Permalink to “Neo4j GraphRAG”Neo4j’s GraphRAG library enables structured knowledge retrieval from Neo4j graphs, combining graph traversal with RAG patterns to surface relationship-aware context. In the Category 7 context, Neo4j functions as the storage substrate that most context graph implementations (Graphiti, TrustGraph) are built on top of, plus the GraphRAG retrieval pattern for teams building directly on Neo4j.
Pros: Dominant community and enterprise adoption; GraphRAG library for structured retrieval; MCP server (neo4j-mcp-server); proven at enterprise scale; broad language and framework support
Cons: The context graph reasoning layer — temporal memory, entity extraction, governance — is DIY on top of Neo4j’s storage; not a complete context graph solution out of the box
Pricing: Community Edition (free) / Enterprise
URL: neo4j.com
Cognee
Permalink to “Cognee”Cognee is an Apache 2.0 memory control plane for AI agents that processes raw text and documents into structured knowledge graphs via MCP. Its 30+ source ingestion capability, ontology grounding, local execution option, and 6-line setup make it the most accessible open-source entry point for teams adding context graph capability to an existing agent.
Cognee graduated from the GitHub Secure Open Source program and ships a Claude Code plugin, making it one of the few Category 7 tools with explicit AI agent developer tooling integration.
Pros: Apache 2.0 (maximum open-source flexibility); MCP native; 30+ data source ingestion; runs locally for data-sensitive deployments; ontology grounding; multimodal support; Claude Code plugin
Cons: Younger project with smaller enterprise community than Graphiti; enterprise support less established; fewer case studies at large scale
Pricing: Open source / Enterprise
GitHub: github.com/topoteretes/cognee
URL: cognee.ai
Zep Enterprise
Permalink to “Zep Enterprise”Zep Enterprise is the commercial temporal knowledge graph platform for stateful, long-running AI agents requiring persistent user preference and session memory. The Zep Community Edition was deprecated in April 2025, making the enterprise version the only supported option.
Pros: Strong for stateful multi-turn agents requiring long-term memory; temporal memory preserves session state across interactions; enterprise support and SLAs
Cons: Community Edition deprecated (April 2025) — teams on CE must migrate or pay enterprise; pricing opacity; lock-in risk for teams that adopted when CE was free
Pricing: Enterprise
URL: getzep.com
Category 7 bottom line: Graphiti is the community-first choice for teams that need temporal knowledge graphs with MCP support. TrustGraph is the sovereign/precision choice for organizations where data residency and ontology-grounded retrieval are non-negotiable. Cognee is the quickest open-source entry point for teams adding context graph capability to an existing agent pipeline. Neo4j GraphRAG underpins most production deployments. For a comparison of these tools side by side, see context graph tools compared.
How do you build a context engineering tool stack?
Permalink to “How do you build a context engineering tool stack?”Start with the governance layer (Categories 1-4), not the delivery layer (Categories 6-7). Most teams buy the tools that are easiest to demo — MCP servers and evaluation frameworks — and discover 6 months later that the context being delivered is ungoverned and drifting. Build from the substrate up, not from the interface down. The how to build a context engineering framework guide covers this sequence in detail.
Three orientation questions before choosing tools:
-
What’s your existing data stack? Your current data warehouse, catalog, and orchestration tools determine which metadata platform integrations are available to you — and whether you’re extending an existing governance investment or starting from scratch.
-
What’s your current failure mode? Hallucination on business terms points to a Category 4 gap (no shared glossary). Stale data answers point to a Category 3 gap (no active lineage). Inability to explain agent reasoning points to a Category 2 or 7 gap (no relationship graph). No visibility into output quality points to a Category 5 gap (no evaluation framework).
-
Do you have a team that can operate graph infrastructure? The answer determines whether Category 7 tools should be managed services or open-source self-hosted deployments. Graphiti and TrustGraph are genuinely approachable for teams with Python and graph fundamentals; Neo4j at enterprise scale is a specialist skill.
Decision framework: matching your need to the right category
Permalink to “Decision framework: matching your need to the right category”| If You Need… | Start with Category | Recommended Tool(s) | Why |
|---|---|---|---|
| Governed, certified context at the source | Category 1 | Atlan | Data must be trustworthy before delivery |
| Relationship-aware entity retrieval | Category 2 or 7 | Neo4j, Graphiti, TrustGraph | Flat retrieval misses connected facts |
| Auditable context for compliance | Category 3 | Atlan (lineage), OpenLineage | Regulators care about provenance |
| Consistent business term definitions | Category 4 | Atlan Glossary, Protégé, TopBraid | Semantic drift is the #1 hidden context failure |
| Quality measurement for RAG pipelines | Category 5 | Langfuse + RAGAS, DeepEval | Can’t improve what you don’t measure |
| MCP delivery to agents | Category 6 | Atlan MCP, GitHub MCP | Protocol is the interface; governance is upstream |
| Temporal agent memory at scale | Category 7 | Graphiti, TrustGraph, Zep Enterprise | Stateful agents need bi-temporal knowledge graphs |
By company stage
Permalink to “By company stage”Startups (under 50 people): Start with open-source tools in Categories 5 and 7 — Langfuse and RAGAS for evaluation, Cognee or Graphiti for context graph capability. Skip Category 1 enterprise metadata platforms until data volume and team size justify the governance investment.
Mid-market (50-500 people): Introduce a metadata platform in Category 1 alongside Neo4j for knowledge graph. Build toward governed MCP delivery in Category 6 once the governance layer is in place.
Enterprise (500+ people): A full 7-category stack is justified at this scale. A Category 1 governance platform is non-negotiable when multiple teams are producing context products that feed enterprise agents. One caveat: not every enterprise needs sovereign context graph infrastructure (TrustGraph) on day one — start with the governance substrate and add Category 7 capability when stateful, multi-agent use cases demand it.
By use case
Permalink to “By use case”Text-to-SQL agents: Require Category 1 (certified table and column definitions), Category 3 (lineage for trust verification), and Category 4 (business glossary defining what metrics mean). See context engineering for data engineering teams for a deeper treatment of this use case.
Customer support agents: Require Category 7 (temporal knowledge graph for session memory and user preference persistence) and Category 5 (faithfulness evaluation to catch hallucinated policy answers).
RAG over enterprise documents: Require Category 5 (evaluation), Category 6 (MCP delivery), and Category 2 or 7 (entity relationship traversal for related document retrieval). See context engineering vs. RAG for the full architectural distinction.
Compliance and audit workloads: Require Category 3 (lineage for provenance audit), Category 1 (certified access policies), and Category 4 (governance taxonomy for regulatory term definitions). See context engineering and AI governance for the compliance treatment.
Which context engineering categories does Atlan cover?
Permalink to “Which context engineering categories does Atlan cover?”Atlan is a four-product context engineering platform — the model is not the moat; context is. The four products map directly to the context engineering lifecycle: Enterprise Data Graph unifies context from 80+ sources into a living graph; Context Agents create and enrich it automatically; Context Engineering Studio tests and ships it; and Context Lakehouse stores, versions, and serves it at scale as the world’s first context store engineered natively for AI.
| Category | Atlan Coverage | What Atlan Provides | What Atlan Doesn’t Replace |
|---|---|---|---|
| 1. Metadata platforms | Full | 80+ connectors, certification, active metadata, Context Engineering Studio | — |
| 2. Knowledge graph tools | Partial | Internal metadata relationship graph via Enterprise Data Graph | Neo4j, Neptune, Stardog as standalone graph databases |
| 3. Data lineage tools | Full | Column-level lineage, impact analysis, event-driven staleness detection | — |
| 4. Business glossary / ontology | Full | Active glossary, certified terms via MCP, Context Agents at 690K+ descriptions across 50+ customers | Protégé for OWL ontology engineering |
| 5. AI evaluation frameworks | None | — | Langfuse, RAGAS, DeepEval, LangSmith |
| 6. MCP delivery | Full (governed) | Atlan MCP Server with runtime access policy enforcement — agents see only what they’re permitted to see | GitHub MCP, Notion MCP, Stripe MCP for their domains |
| 7. Context graph tools | None (adjacent) | Metadata graph is catalog-scoped; Context Lakehouse stores versioned context products | TrustGraph, Graphiti, Cognee, Zep |
Atlan’s differentiation is in the governance substrate — the layer that makes context trustworthy before it reaches any delivery mechanism. The 94-99% accuracy benchmark applies specifically to this governed-source advantage: agents querying Atlan’s certified, lineage-traced context achieve that accuracy; agents querying the same organization’s ungoverned data achieve 10-31%. Atlan AI Labs measured a 5x improvement in AI response accuracy for Workday’s deployment via Atlan’s MCP server, and a 3x improvement in SQL generation accuracy for complex conversational queries with Atlan-enriched metadata. Context Agents compress 9–12 months of enrichment work into minutes. Mastercard runs 100M+ assets on Atlan’s context architecture; CME Group manages 18M+ assets and 1,300+ glossary terms.
Named a Leader in the 2026 Gartner® Magic Quadrant™ for Data & Analytics Governance Platforms, Atlan sits at the intersection of the three categories that matter most when AI agents need context they can trust: knowing what data exists, knowing where it came from, and knowing what it means. For a direct comparison of Atlan against other context engineering platforms, see context engineering platforms compared.
Key takeaways on choosing context engineering tools
Permalink to “Key takeaways on choosing context engineering tools”Context engineering tools span 7 distinct infrastructure categories — and the most important insight from this guide is the order: governance (Categories 1-4) enables delivery (Categories 6-7), not the reverse. Teams that build a great MCP delivery layer on ungoverned data are optimizing the wrong end of the stack. The what is context engineering guide covers the full discipline, and context management strategies for enterprise AI maps how CDOs and data leaders are building the governance foundation first.
No single tool covers the full 7-category stack. Composition is the skill — matching each category to the right tool for your organization’s failure mode, data estate, and team capabilities. For a side-by-side comparison of the leading context engineering platforms, including how Atlan stacks up against other enterprise options, see the full comparison guide.
Open source is genuinely strong in delivery and evaluation. The commercial gap is governance: certification workflows, access policies, active staleness detection, and business glossaries backed by physical lineage are hard to self-build and sustain. That gap is where enterprise metadata platforms earn their cost.
One “don’t overbuy” note: teams with a single data source and a small agent footprint do not need an enterprise metadata platform on day one. Start with evaluation (Category 5) to understand your failure modes, add context management software for your highest-value context source, and scale governance investment (Categories 1-4) as your agent footprint and data complexity grow.
See how Atlan governs the context layer — Watch the Context Studio demo
FAQs about context engineering tools for AI agents
Permalink to “FAQs about context engineering tools for AI agents”1. What is the difference between context engineering tools and AI coding tools like Cursor or Claude Code?
Permalink to “1. What is the difference between context engineering tools and AI coding tools like Cursor or Claude Code?”AI coding tools (Cursor, Copilot, Claude Code) help developers manage the context window of an LLM during coding sessions — which files are in scope, which recent changes are included, how memories are maintained within a session. Context engineering tools for AI agents govern the enterprise data layer that agents query in production: metadata certification, lineage provenance, business glossaries, and MCP delivery. Different problem, different stack, different buyer.
2. Do I need all 7 categories of context engineering tools?
Permalink to “2. Do I need all 7 categories of context engineering tools?”No — stack coverage depends on your failure mode. Teams with clean, certified data and simple retrieval may only need Categories 5 (evaluation) and 6 (MCP delivery). Organizations where agents must reason about business definitions, trace data provenance, or enforce access policies need Categories 1-4 as the governance foundation. Start with your worst failure mode and add layers as your agent footprint grows.
3. What is MCP and why does it matter for context engineering?
Permalink to “3. What is MCP and why does it matter for context engineering?”MCP (Model Context Protocol), introduced by Anthropic in November 2024, is the de facto protocol for connecting AI agents to data sources. It standardizes how agents request context, what tools they can invoke, and how responses are formatted. By 2026, MCP had 97M+ monthly SDK downloads, and most major SaaS platforms have shipped official MCP servers. For context engineering, MCP is Category 6 — the delivery layer. Governance still happens upstream.
4. What is the difference between a context graph tool and a vector database?
Permalink to “4. What is the difference between a context graph tool and a vector database?”A vector database returns contextually similar results based on embedding proximity — useful for “what’s relevant?” A context graph tool returns relationship-aware, verified results — useful for “what’s connected and trusted?” Vector databases are stateless retrieval engines; context graphs preserve temporal state, entity relationships, and governance provenance. Most production stacks use both, not one. See the context graphs for AI agents guide for a detailed comparison.
5. Which context engineering tools are open source?
Permalink to “5. Which context engineering tools are open source?”Strong open-source options exist across categories: Langfuse (MIT, Category 5), RAGAS (open source, Category 5), TrustGraph (Apache 2.0, Category 7), Graphiti by Zep (open source core, Category 7), Cognee (Apache 2.0, Category 7), OpenLineage/Marquez (Apache 2.0, Category 3), Protégé (free, Category 4), Neo4j Community Edition (Category 2). Governance platforms in Category 1 have limited open-source equivalents — enterprise metadata management remains largely commercial.
6. How long does it take to implement a context engineering tool stack?
Permalink to “6. How long does it take to implement a context engineering tool stack?”Point-solution implementations — a single evaluation framework or MCP server — take days to weeks. A governed context engineering stack including a metadata platform, lineage layer, business glossary, and MCP delivery takes 3-6 months for initial deployment and 6-12 months to reach production quality across a large data estate. The governance layer setup time dominates the timeline; delivery tools are comparatively fast to configure.
7. Is RAG the same as context engineering?
Permalink to “7. Is RAG the same as context engineering?”No. RAG (Retrieval-Augmented Generation) is one technique that spans Categories 3 and 5 of a context engineering stack. It improves retrieval relevance by fetching relevant documents at query time. Context engineering is the infrastructure discipline governing what those documents contain, whether they’re certified, who can access them, and whether the business terms they use mean the same thing across your organization. RAG is a delivery pattern. Context engineering is the governance system RAG retrieves from.
8. How much do context engineering tools cost?
Permalink to “8. How much do context engineering tools cost?”Costs vary by category and tier. Open-source tools (Langfuse, RAGAS, Cognee, TrustGraph, OpenLineage) have no license cost but require engineering investment to operate. Enterprise metadata platforms like Atlan are priced on data asset volume, connector count, or user seats — typically six-figure annual contracts for mid-to-large enterprises. Knowledge graph databases (Neo4j Community, Protégé) have free tiers. AI evaluation platforms (Langfuse, RAGAS) are free to start with paid tiers for managed hosting. Total stack cost for a full 7-category enterprise deployment typically ranges from $200K to $500K+ annually, with the governance platform representing the majority of that cost.
9. What is context rot and how do context engineering tools prevent it?
Permalink to “9. What is context rot and how do context engineering tools prevent it?”Context rot is the silent degradation of context quality that happens when source data definitions change and downstream context products are not updated. A business glossary term defined one way last quarter, an ETL transformation updated two weeks ago, a column renamed in the source system — all of these create situations where agents confidently reason from stale information. Context engineering tools prevent context rot through active metadata management (event-driven updates rather than scheduled crawls), downstream impact analysis, and staleness timestamps surfaced at query time. Evaluation frameworks (Category 5) detect context rot after the fact; governance tools (Categories 1-4) prevent it.
Sources
Permalink to “Sources”- Anthropic: Effective context engineering for AI agents — practitioner post on context engineering principles
- Neo4j: Context engineering tools — competitor treatment of context engineering tooling
- Atlan: Context engineering vs RAG — source for 94-99% vs 10-31% accuracy benchmark
- Atlan: What is the Atlan MCP Server — Atlan MCP server documentation
- Atlan: Context infrastructure for AI agents — three-layer context infrastructure model
- Atlan: Data lineage — Atlan lineage capability overview
- RAGAS documentation — RAG evaluation metrics
- Langfuse — MIT-licensed LLM observability
- TrustGraph GitHub — TrustGraph open source (Apache 2.0)
- Graphiti GitHub (Zep) — Graphiti open source
- Cognee GitHub — Cognee open source (Apache 2.0)
- Acceldata: Data Lineage Agent — Acceldata lineage agent
- Promethium AI: Enterprise Knowledge Graph Buyer’s Guide 2026 — knowledge graph market context
- Confident AI: LLM observability tools comparison 2026 — LLM observability market data
- ContextGraph.tech: Open source context graph tools — context graph market overview
- Confident AI: Top LLM observability tools — $2.69B (2026) → $9.26B (2030) market size projection; underlying data from The Business Research Company
- Demand Gen Report: Gartner LLM observability — Gartner 50% GenAI deployments by 2028
- Contextual AI — RAG-native enterprise context engineering platform
- Mem0: State of AI Agent Memory 2026 — AI agent memory benchmarks and architectures
- Elastic + Contextual AI partnership — enterprise context engineering platform partnership
