


















Atlan’s Context Engineering Studio is the environment where teams design, test, and govern the context repositories that power each of these four strategies, ensuring agents retrieve from an Enterprise Data Graph of certified definitions rather than ungoverned metadata.
Why does context engineering matter for AI agents?
Permalink to “Why does context engineering matter for AI agents?”AI agents have no shortage of intelligence. They can reason over data, parse complex queries, and execute multi-step workflows. But intelligence only determines how well an agent thinks, not what it thinks about. The input that shapes every decision, every retrieval, every tool call is context: which definitions apply, which sources are authoritative, which exceptions matter.
Consider what happens when an AI analyst is asked, “Who are our top 10 customers this quarter?” The reasoning is straightforward. The context isn’t. “Top” could mean the highest revenue, the most orders, or the best retention. “Customer” could be an individual buyer or an entire account. A single renewal decision can pull from multiple internal platforms and systems, each with its own definitions, freshness levels, and access rules. The agent’s intelligence isn’t the variable. The context feeding it is.
Context engineering is the discipline of designing what information reaches an agent, when, and under what governance.
Three reasons why strategies to streamline context engineering are needed:
- Agents are getting more autonomous: Production agents now run multi-step workflows with tool calls, memory, and sub-agent delegation. Each step multiplies the context dependencies. One bad retrieval in step two cascades through every downstream decision.
- Bigger context windows haven’t solved the problem: Models can process 200,000+ tokens, but research shows accuracy degrades well before the window fills. More capacity doesn’t help when the signal-to-noise ratio is poor.
- The knowledge that matters most lives outside the model: Business glossaries, lineage metadata, access policies, domain-specific exceptions — none of this exists in pre-training data. If it doesn’t reach the context window through deliberate engineering, the agent operates without it.
Gartner predicts 40% of enterprise applications will feature task-specific AI agents by late 2026. When you have hundreds of agents working autonomously, it is essential to arm them with the right context to help them streamline your internal processes.
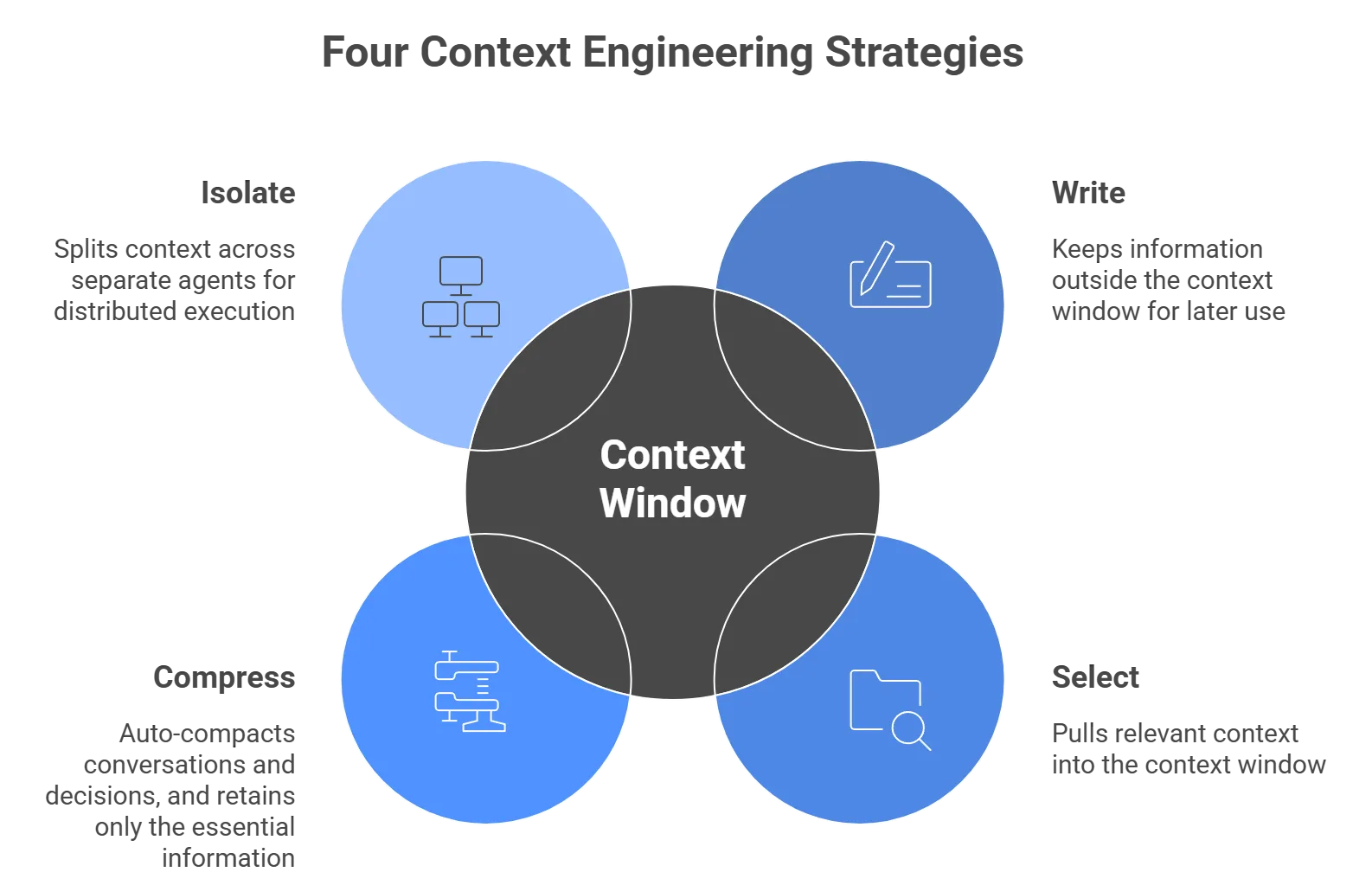
What are the four context engineering strategies?
Permalink to “What are the four context engineering strategies?”Context engineering is the discipline of building and managing the information an AI agent needs to act correctly.
Anthropic’s context engineering guide and LangChain’s agent framework research have codified four core strategies that describe how context moves in and out of the context window as an agent executes a task.
| Strategy | What does it do? | How is it implemented? |
|---|---|---|
| Write | Keeps information outside the context window for later use | Scratchpad for agents to take notes, memories, or an index that contains a map of critical information |
| Select | Pulls relevant context into the context window | RAG, tool use, just-in-time retrieval |
| Compress | Auto-compacts conversations and decisions, retaining only essential information | Summarization, trimming, or pruning old messages or decision-steps |
| Isolate | Splits context across separate agent windows for distributed execution | Multi-agent architectures, sub-agent delegation |
Each strategy solves a real engineering problem. But none of them address where the context comes from or whether it’s accurate. Write can persist bad definitions just as easily as good ones. Select can retrieve outdated metadata with full confidence. The strategies are only as reliable as the underlying context infrastructure.
How does the Write strategy work in context engineering?
Permalink to “How does the Write strategy work in context engineering?”Writing context means saving information outside the context window so it’s available when the agent needs it. This is how agents maintain state across long, multi-step tasks.
Common Write implementations include:
- Scratchpad notes: The agent saves plans, intermediate results, and progress markers to an external store during execution. Instead of holding everything in the context window, it offloads the working state and pulls it back when needed.
- Persistent memory: Long-term storage of preferences, past interactions, and learned patterns that carry across sessions. This is how agents remember what worked, what failed, and what the user cares about.
- Context index: A structured map of critical information (definitions, entity relationships, domain rules) that the agent can look up on demand instead of loading everything upfront.
The enterprise gap here is the difference between generic context and organizational context. An LLM can understand what “revenue” means in the general sense, but it cannot generate what revenue means at your company — which definitions to include, which systems to query. It needs contextual intelligence.
Building context from existing enterprise data signals (lineage, SQL history, BI dashboard usage) produces grounded knowledge for agents. This is what context bootstrapping does: it uses existing business system encodings to generate a first-draft context layer that reflects how the organization actually operates.
How does the Select strategy work in context engineering?
Permalink to “How does the Select strategy work in context engineering?”Selecting context means pulling relevant information into the context window at the moment an agent needs it. This is the most widely adopted strategy, and RAG (retrieval-augmented generation) is its dominant implementation.
Select approaches fall into three categories:
- RAG retrieval: Semantic search over vector stores, knowledge bases, or document indexes. The agent queries for relevant chunks and injects them into the context window.
- Tool use: The agent calls external APIs, queries databases, or reads files to pull structured data into context.
- Just-in-time loading: Instead of pre-processing all relevant data, agents maintain lightweight identifiers and dynamically load data at runtime.
The enterprise problem with Select is straightforward: RAG’s quality ceiling is set by the quality of the retrieval index.
If your business glossary is outdated, RAG retrieves outdated definitions. If your data lineage is broken, the agent follows broken paths. If two departments define “customer” differently and both definitions sit in the retrieval index, the agent picks whichever ranks higher in similarity search. It has no way to know which is canonical.
How does the Compress strategy work in context engineering?
Permalink to “How does the Compress strategy work in context engineering?”Compressing context means retaining only the tokens an agent actually needs to complete a task. As context windows fill during long agent trajectories, compression becomes essential for maintaining performance.
Two main approaches:
- Summarization: An LLM generates condensed versions of long context, distilling conversation history, tool outputs, or document content into shorter representations.
- Trimming: Hard-coded heuristics prune context mechanically — removing messages older than a threshold, truncating tool output to key fields, or stripping formatting and boilerplate.
Both approaches work well for general-purpose agents handling straightforward tasks. The enterprise risk is that summarization is lossy, and in enterprise settings, the exceptions and edge cases are the knowledge.
A summary of “how we calculate ARR” might capture the standard formula. It’s likely to lose the clause about contracts with multi-year prepayment that finance tracks separately. These are the specific nuances that separate a correct enterprise answer from a plausible wrong one.
The solution is investing in a structured, well-governed context system that resists lossy compression rather than compressing unstructured text and hoping the important parts survive.
How does the Isolate strategy work in context engineering?
Permalink to “How does the Isolate strategy work in context engineering?”Isolating context means splitting it across separate sub-agents, each with its own focused context window, tools, and instructions. Instead of loading everything into one massive prompt, you partition the problem.
This is the architecture behind multi-agent systems. A lead agent decomposes a task and delegates it to specialized sub-agents. Each sub-agent gets only the context relevant to its narrow responsibility.
In Anthropic’s internal testing, a multi-agent research system outperformed a single Claude Opus 4 agent by 90.2% on breadth-first research tasks.
But isolation is only as good as the boundaries. In enterprise settings, domain boundaries are rarely clean. Sales context bleeds into finance. Customer success needs data from support, product usage, and billing.
The risk is “agent sprawl”: dozens of agents across the enterprise, each with its own partial view of reality, each building its own context silo. Getting isolation right requires governed domain boundaries, clear definitions of which context belongs where, shared layers that prevent agents from diverging on core definitions, and federated governance that lets domain experts own their context while maintaining organizational consistency.
Why do context engineering strategies fail in enterprise settings?
Permalink to “Why do context engineering strategies fail in enterprise settings?”Most enterprise AI pilots never make it to production. MIT’s 2025 research found the root cause is consistent: not model capability, not strategy selection, but context that is inaccurate, stale, or inconsistently defined across the organization.
Every strategy has a specific failure mode when the underlying context isn’t governed:
| Strategy | What goes wrong | Root cause |
|---|---|---|
| Write | The agent produces context that sounds right but reflects generic knowledge, not how your organization operates | No enterprise data signals (lineage, SQL history, BI usage) to ground the writing |
| Select | RAG retrieves outdated or conflicting definitions, with no way to know which is canonical | Retrieval index built on ungoverned metadata with no governed semantic layer beneath it |
| Compress | Summarization loses the exceptions and edge cases that form enterprise knowledge | No structured context to prevent lossy compression |
| Isolate | Dozens of agents build their own partial view of reality, recreating BI sprawl at the agent layer | No shared context layer or federated governance defining domain boundaries |
These strategies operate at the application layer. They manage what goes into the context window during inference. They can’t fix what sits beneath them: the accuracy, freshness, and consistency of the context itself. That’s an infrastructure problem.
How does Atlan’s context layer make these strategies work?
Permalink to “How does Atlan’s context layer make these strategies work?”The four strategies operate at the application layer. Atlan’s context layer works beneath them, building, governing, and serving the enterprise context that each strategy consumes.
Write: Bootstrapping organizational context from existing data signals
Atlan’s active metadata platform ingests signals from SQL query history, column-level lineage, BI dashboard usage, and transformation logic to bootstrap a first-draft context layer. This gives agents organizational knowledge to write from, not blank-slate guessing.
Select: Keeping retrieval sources accurate and current
Atlan’s business glossary and data catalog maintain a living model of business concepts, entities, and relationships, so agents retrieve canonical definitions instead of outdated or conflicting ones. Agents can also retrieve decision traces: structured records of how and why past decisions were made. The MCP server exposes this governed context directly to AI agents at query time.
Compress: Structured context that resists lossy summarization
When context is structured as metadata with embedded lineage, classifications, and policy tags, the boundaries of compression are clear. Atlan’s metadata lakehouse stores context in versioned, policy-embedded formats that preserve critical business logic even when agents need to trim token counts.
Isolate: Governed domain boundaries for multi-agent architectures
Multi-agent systems need clear definitions of which context belongs where. Atlan’s federated governance model lets domain experts own and certify their context while maintaining organization-wide consistency. Data discovery and classification ensure that each sub-agent accesses only the context scoped to its domain, preventing agent sprawl.
Real stories: Context engineering strategies in production
Permalink to “Real stories: Context engineering strategies in production”"All of the work that we did to get to a shared language amongst people at Workday can be leveraged by AI via Atlan's MCP server. We are co-building the semantic layers that AI needs with new constructs like context products."
Joe DosSantos
VP Enterprise Data & Analytics, Workday

"We have moved from privacy by design to data by design to now context by design. Atlan's metadata lakehouse is configurable across all tools and flexible enough to get us to a future state where AI agents can access lineage context through the Model Context Protocol."
Andrew Reiskind
Chief Data Officer, Mastercard
Wrapping up
Permalink to “Wrapping up”Write, Select, Compress, and Isolate solve real engineering problems. But none of them can fix bad context. An agent that writes from generic knowledge, retrieves outdated definitions, compresses away critical exceptions, or isolates into ungoverned silos will fail regardless of how well the strategy is implemented.
The organizations getting agents to production aren’t debating which strategy to use. They’re investing in the context infrastructure that makes all four work: governed definitions, current lineage, structured metadata, and shared protocols like MCP that let every agent inherit the same organizational knowledge.
Assess your context maturity to see where your organization’s context layer stands.
Frequently asked questions
Permalink to “Frequently asked questions”1. What is the difference between context engineering and prompt engineering?
Permalink to “1. What is the difference between context engineering and prompt engineering?”Context engineering manages the full information pipeline feeding an AI agent, from retrieval and memory to compression and governance. Prompt engineering focuses on how you phrase a single request within a fixed context window. Context engineering includes prompt engineering but extends to the infrastructure that makes prompts effective in the first place. The shift reflects a broader recognition that model performance depends more on the quality of context than on the cleverness of the prompt.
2. Which context engineering strategy is most important?
Permalink to “2. Which context engineering strategy is most important?”No single strategy dominates in practice. Most production agent systems combine all four. Select (RAG) is the most widely adopted because it addresses the immediate need to bring external knowledge into the context window. But Write (persistent memory) and Isolate (multi-agent architectures) are growing rapidly as agent complexity increases and single-agent approaches hit accuracy ceilings.
3. Can you use all four context engineering strategies together?
Permalink to “3. Can you use all four context engineering strategies together?”Yes, and most mature systems do. A typical production pattern is a multi-agent system (Isolate) in which each sub-agent uses RAG (Select), maintains a scratchpad to track progress (Write), and summarizes long tool outputs to fit within its window (Compress). The strategies are complementary, not competing. The engineering challenge is orchestrating them effectively.
4. How do context engineering strategies apply to enterprise AI?
Permalink to “4. How do context engineering strategies apply to enterprise AI?”Enterprise AI adds a governance dimension that developer-focused guides often skip. Each strategy depends on the underlying context being accurate, consistently defined, and up to date across the organization. Without a governed context infrastructure, strategies amplify bad context instead of fixing it. The enterprise challenge isn’t choosing the right strategy — it’s building the context layer that makes any strategy reliable.
5. What is the difference between context engineering and RAG?
Permalink to “5. What is the difference between context engineering and RAG?”RAG is one implementation of one strategy (Select). Context engineering is the broader discipline that encompasses all four strategies plus the infrastructure beneath them. RAG answers “how do I get relevant information into the prompt?” Context engineering answers “how do I ensure the right information reaches the agent at every step, and how do I govern that information over time?”
