



















A model router selects which large language model handles a given request, optimizing for cost, latency, or capability. A model gateway governs how all LLM requests are authenticated, rate-limited, logged, and transformed. You’ll typically need both: routing reduces LLM costs by 40-70%, while the gateway provides the audit trail and access controls compliance requires.
Build Your AI Context Stack
Get the blueprint for implementing context graphs across your enterprise. This guide walks through the four-layer architecture—from metadata foundation to agent orchestration—with practical implementation steps for 2026.
Get the Stack GuideWhat is a model router?
Permalink to “What is a model router?”A model router is infrastructure that evaluates an incoming request and dispatches it to the most appropriate language model. Routing decisions are based on query complexity, task type, latency requirements, or cost budget. According to RouteLLM (Ong et al., LMSYS / UC Berkeley, 2024), trained routing policies can reduce LLM costs by 40-70% while maintaining 95% of GPT-4 quality on quality benchmarks like MT-Bench.
Core routing mechanisms
Permalink to “Core routing mechanisms”Routers use several approaches to make model selection decisions:
- Rule-based routing: Static rules determine which model handles each request type. For example: “if task_type equals ‘code’, use Codestral.” Simple to configure, zero added latency, but requires manual maintenance as your model landscape evolves.
- Classifier-based routing: A lightweight ML model predicts which LLM fits the input before the call is made. RouteLLM’s BERT-based and matrix factorization routers follow this pattern, training on preference data from Chatbot Arena to learn when a weaker model will suffice.
- Semantic routing: Query embeddings are matched to model-mapped topic clusters. A coding query routes to a code-specialized model; a financial analysis query routes to a high-reasoning model.
- Fallback chains: LiteLLM’s approach. Rule-based routing with provider failover — if the primary model is rate-limited or degraded, the request automatically reroutes to a backup. This is not learned routing, but it is the most widely deployed pattern.
What these mechanisms share: the router decides who receives the request. It does not change what flows into that model, or whether what flows in is correct.
What is a model gateway?
Permalink to “What is a model gateway?”A model gateway is a centralized reverse proxy that every LLM request flows through before reaching an AI provider. It handles authentication and authorization, rate limiting, logging and observability, prompt transformation, and semantic caching. Kong, Portkey, and LiteLLM Proxy are common implementations. The gateway is the LLMOps operations layer for LLM infrastructure.
Core gateway functions
Permalink to “Core gateway functions”A gateway wraps every LLM interaction with governance controls:
- Authentication and authorization: Validates credentials before requests reach any LLM provider. Enforces which users and applications can call which models. This is the LLM governance control point for enterprise access.
- Rate limiting and quota enforcement: Caps LLM requests per user, team, or time window. Prevents runaway API spend and enforces per-department budgets.
- Full request/response logging: Captures every prompt and response for audit trail, debugging, and cost attribution across teams. This is the function compliance teams most consistently require.
- Prompt transformation and guardrails: Modifies requests before they reach the model. Injects system context, strips PII, applies content filters. Also handles response transformation post-output.
- Semantic caching: Reuses responses for semantically similar requests, reducing redundant LLM calls. Lowers per-query cost and latency. Note: this caches outputs, not meaning. See the misconception in the FAQ section for why caching is not governance.
- Access controls and cost tracking: Attributes LLM spend by team, project, or user. Centralizes API key management rather than distributing keys to every application.
The gateway governs the flow. It cannot govern the meaning of what flows through it.
Model router vs model gateway: head-to-head comparison
Permalink to “Model router vs model gateway: head-to-head comparison”The sharpest difference between a model router and a model gateway is when each operates and what it controls. The router acts once, before the call, to select a model. The gateway acts on every call to wrap it with governance. They are complementary, not competing.
| Dimension | Model Router | Model Gateway |
|---|---|---|
| Primary function | Select which model handles a request | Govern how every model request is executed |
| Decision timing | Pre-request (dispatch) | Per-request (wraps every call) |
| What it optimizes | Cost, latency, capability match | Security, observability, compliance, cost attribution |
| Who owns it | ML/AI engineering teams | Platform/infra/security engineering teams |
| Failure mode | Wrong model selection leads to quality degradation or excess cost | No gateway means ungoverned access, no audit trail, no rate limiting |
| Key tools | RouteLLM, Martian, LiteLLM Router, Unify AI | Portkey, Kong AI Gateway, LiteLLM Proxy, AWS Bedrock, Azure APIM |
| Can it do the other’s job? | Routing logic can live inside a gateway, but isn’t its primary purpose | Gateway can include fallback chains, but doesn’t optimize for quality or cost per query |
| What neither does | Neither governs the quality or accuracy of context the model receives | Neither governs the quality or accuracy of context the model receives |
Example: financial reporting AI assistant. Your team builds an assistant that answers questions about quarterly financials. The model router dispatches simple summary queries to GPT-4o Mini (fast, cheap) and complex cross-dataset analysis to Claude Opus (high reasoning). The model gateway validates that only Finance team members can call the endpoint, caps requests at 500/day per user, and logs every prompt for audit. Both work correctly. Neither checks whether the revenue definition the model is reasoning over reflects your December 2024 policy change.
This is not a failure of the control plane for LLM infrastructure — it is the boundary of what that layer is designed to do. For enterprise LLM infrastructure to produce reliable outputs, something beneath the router and gateway must govern context quality.
Inside Atlan AI Labs & The 5x Accuracy Factor
Learn how context engineering drove 5x AI accuracy in real customer systems. Explore real experiments, quantifiable results, and a repeatable playbook for closing the gap between AI demos and production-ready systems.
Download E-BookHow model routers and gateways work together
Permalink to “How model routers and gateways work together”Most enterprise teams run a gateway with routing capability built in, or pair a dedicated router with a gateway. The gateway captures the full audit trail; the routing logic inside it dispatches to the optimal model. Together they provide access governance, cost optimization, and operational observability.
The gateway-with-routing pattern
Permalink to “The gateway-with-routing pattern”The convergent enterprise pattern works like this:
- All LLM requests flow through the gateway, providing unified authentication, rate limiting, and logging
- Within the gateway, routing logic dispatches to the optimal model based on request characteristics (complexity, task type, cost budget)
- The gateway logs which model was selected, why, and what the outcome was
- Fallback chains handle provider outages without manual intervention
When to invest in each:
- Start with the gateway when multiple teams share LLM access, compliance requirements are present, or cost attribution is needed. The gateway gives you visibility before you optimize.
- Add routing when cost is a meaningful budget line and you have confirmed your query distribution benefits from model selection. RouteLLM research supports this most strongly when the majority of queries don’t require your highest-capability model.
- Build both simultaneously when deploying a greenfield enterprise AI deployment from scratch.
Based on practitioner signals, large enterprises commonly converge on the gateway-with-routing pattern 6-12 months after initial AI deployment. The sequence: direct API calls, then a gateway for visibility, then routing for cost optimization.
This pattern governs how context is delivered to models at the protocol level, but it does not govern what that context means.
When to use a model router vs a model gateway
Permalink to “When to use a model router vs a model gateway”Use a router when:
- You have a single application calling multiple models and want to reduce cost without sacrificing quality
- If 60% or more of your queries are simple enough for a smaller model, routing can capture that savings without manual per-query decisions
- You have latency-sensitive tiers that need different model response speeds (customer-facing vs. batch processing)
- You are A/B testing model performance across your actual query distribution
Use a gateway when:
- Multiple teams, applications, or agents share LLM API access and you need cost attribution
- Compliance, security, or audit requirements mandate logging every AI interaction
- You want to centralize API key management instead of distributing keys to every application
- You are abstracting away provider lock-in behind a unified API interface
Use both when:
- Any enterprise AI deployment beyond a single-team prototype
The missing layer: what routing and gateways don’t solve
Permalink to “The missing layer: what routing and gateways don’t solve”Model routers and gateways operate on the transport and dispatch layer of LLM infrastructure. They answer: which model runs, and who is allowed to call it. Neither answers: what context is the model actually reasoning over, and is it correct, current, and certified? That is the context layer governance problem neither tool is designed to solve.
The revenue recognition example. Consider an enterprise query: “What is our Q2 revenue recognition threshold for enterprise contracts?” The router selects Claude Opus (complex financial reasoning required). The gateway validates the API key, logs the request, and enforces rate limits. The model runs.
But: was the revenue definition current, post the December 2024 policy change? Was “enterprise contracts” defined consistently with Finance’s interpretation, not Sales’? Was a data freshness certificate attached so the model knew to caveat if the data was 47 days old?
The router and gateway are silent on all of this. They moved the request efficiently and securely. Neither knew whether what they moved was correct.
Three context engineering governance questions neither answers:
-
Meaning governance: Who defines what business context means in this organization, and does the model see that governed context? The router selects a model. The gateway controls access. Neither injects a governed semantic layer.
-
Version governance: Is the context the model reasons over the certified current version, or a stale copy? LLM applications that retrieve from knowledge bases, vector stores, or RAG pipelines can serve outdated context with no flag. This is where enterprise context silos compound the problem — different teams serving different versions of the same definition.
-
Attribution governance: When the model produces an answer, which data assets, definitions, and policies contributed to it? Router logs tell you which model ran. Gateway logs tell you who called it. Neither provides provenance over the reasoning inputs.
One misconception worth dispelling: semantic caching in a gateway is not context governance. Caching a wrong answer faster does not make it accurate — and LLM hallucinations that get cached become systemic errors. Semantic caching is an efficiency mechanism for the transport layer.
Real stories from real customers: context that travels with every model
Permalink to “Real stories from real customers: context that travels with every model”The enterprises that have moved from prototype to production AI share a common pattern: they built the context layer first, then connected delivery mechanisms to it.
Workday. Joe DosSantos, VP Enterprise Data and Analytics: “All of the work that we did to get a shared language at Workday can be leveraged by AI via Atlan’s MCP server.” Workday’s context came first. The protocol and the model selection were the delivery vehicles. When the router picks Claude or GPT-4o, both read from the same context-aware definitions Workday built in Atlan. This is context layer ROI at enterprise scale.
DigiKey. Sridher Arumugham, CDAO: “Atlan enabled us to easily activate metadata activated to AI models for everything from discovery in the marketplace to AI governance to data quality to an MCP server delivering context to AI models. The Snowflake MCP server integration was a key part of our data source strategy.” DigiKey built one context catalog. It feeds every delivery path, including MCP, model calls, and whatever router or gateway sits in front of them.
In both cases, the router and gateway decisions were made after the context layer was in place. The sequencing is not accidental. When the context layer is the foundation, model and protocol choices become reversible. When it isn’t, every routing and gateway decision is a workaround for incomplete semantic infrastructure.
Routing and gateways solve half the problem — the context layer solves the other half
Permalink to “Routing and gateways solve half the problem — the context layer solves the other half”Router solves: cost, latency, capability. Which model.
Gateway solves: access, compliance, observability. Who can call it.
Context layer solves: accuracy, meaning, version control. What the model knows.
The three are not competing layers; they are complementary infrastructure stacked in sequence. The context architecture for AI agents places the context layer beneath the gateway and beneath the router. Whichever model is chosen, whichever access policies are enforced, the model reads the same governed context through the Atlan MCP Server.
The hierarchy looks like this:
Application / Agent
↓
Model Router (selects which model)
↓
Model Gateway (governs access, logs, rate-limits)
↓
Model (Claude / GPT-4o / Gemini / etc.)
↑
Context Layer (certified definitions, versioned metadata)
↑
Atlan MCP Server (governed context as [context infrastructure](https://atlan.com/know/context-infrastructure-for-ai-agents/))
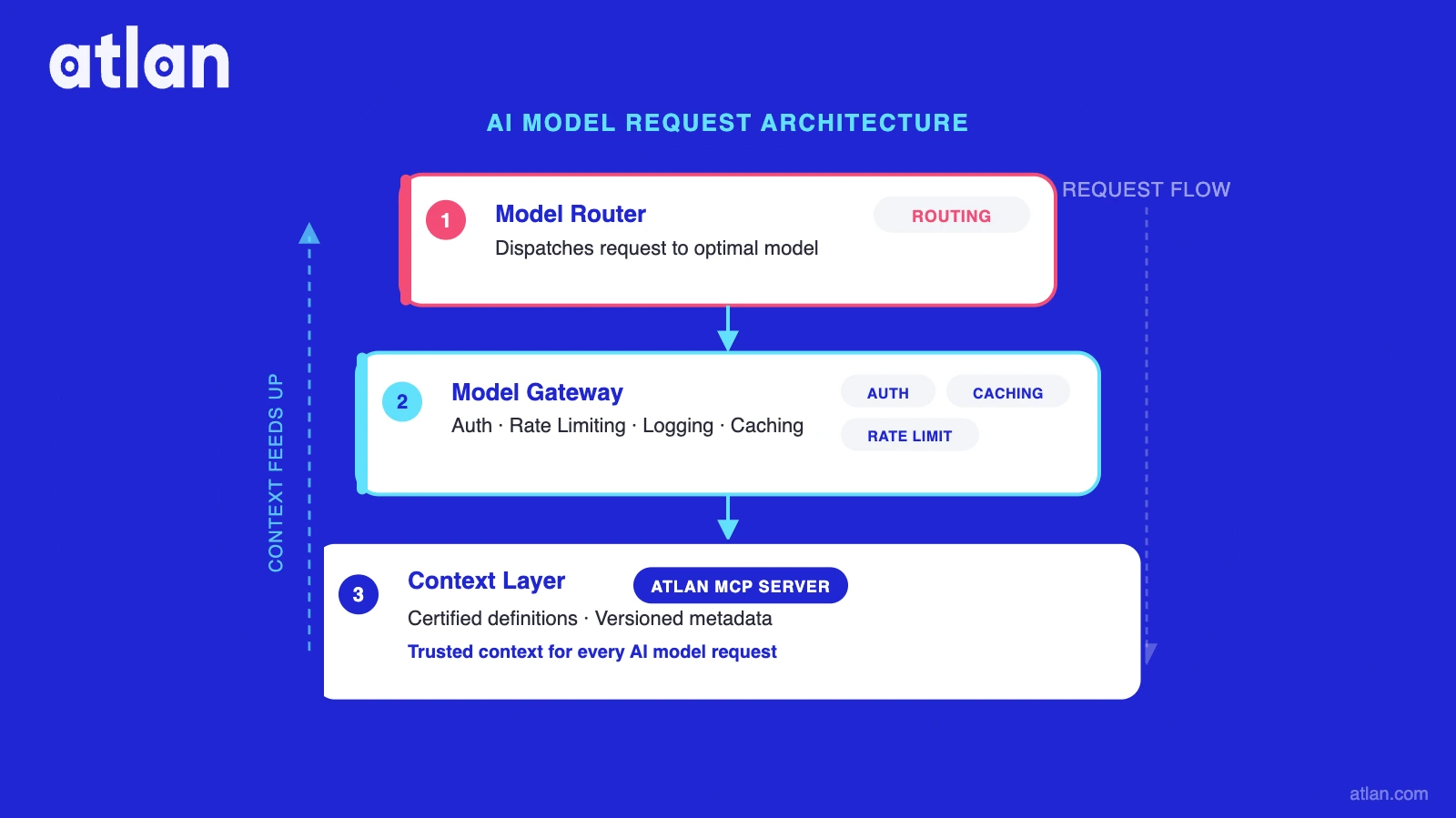
This means: router and gateway decide who and which model. Atlan governs what governed context the model receives at query time. The underlying knowledge graph that powers Atlan’s context layer holds the certified definitions that make that context trustworthy at scale. Understanding why enterprises need a context layer is the key to unlocking contextual intelligence across your AI stack.
The agent context layer and the context API for AI complete the infrastructure stack — giving every agent, regardless of which model the router selected, access to the same governed business definitions.
Explore how Atlan’s context architecture for AI agents completes the infrastructure stack.
FAQs
Permalink to “FAQs”1. What is the difference between a model router and a model gateway?
Permalink to “1. What is the difference between a model router and a model gateway?”A model router selects which language model handles a request, deciding between Claude, GPT-4o, Gemini, or other models based on cost, latency, or capability requirements. A model gateway governs how every LLM request is executed, handling authentication, rate limiting, logging, and prompt transformation. Router = which model; gateway = how it’s accessed and controlled.
2. Can a model router and model gateway be the same tool?
Permalink to “2. Can a model router and model gateway be the same tool?”Yes. Several products bundle both capabilities. LiteLLM, Portkey, and Kong AI Gateway all include routing (model fallback chains, load balancing) and gateway functions (key management, logging, rate limiting). The conceptual distinction remains useful even when one tool handles both: routing optimizes model selection; gateway functions govern access and observability for every call.
3. Do I need both a model router and a model gateway?
Permalink to “3. Do I need both a model router and a model gateway?”Most enterprise AI deployments eventually need both, but in different order. Teams typically add a gateway first for cost attribution, key management, and audit logging across multiple teams, then add routing once cost reduction becomes a meaningful objective. Single-team prototypes often skip both initially. Any multi-team, compliance-sensitive, or production AI deployment benefits from the combination.
4. What is the difference between an AI gateway and an AI proxy?
Permalink to “4. What is the difference between an AI gateway and an AI proxy?”The terms are often used interchangeably. An AI proxy is the underlying network pattern: a service that intercepts and forwards LLM requests. An AI gateway is a proxy with enterprise capabilities added, including authentication, rate limiting, observability, guardrails, and semantic caching. All gateways are proxies; not all proxies are full gateways.
5. Does model routing solve AI hallucinations?
Permalink to “5. Does model routing solve AI hallucinations?”No. Model routing selects a better model for a given task. It does not improve the quality of the context that model receives. If the business definitions, data assets, or knowledge the model reasons over are stale or incorrect, a higher-capability model will produce more confidently wrong answers. LLM hallucinations require context governance, not model selection alone.
6. What is semantic caching in a model gateway and what does it not do?
Permalink to “6. What is semantic caching in a model gateway and what does it not do?”Semantic caching in a model gateway reuses prior LLM responses for semantically similar requests, reducing redundant API calls and lowering latency and cost. What it does not do: verify that the original response was based on correct, current, or governed context. Caching an inaccurate answer faster does not make it accurate. Semantic caching is an efficiency mechanism, not a governance mechanism.
7. How does LiteLLM differ from Portkey?
Permalink to “7. How does LiteLLM differ from Portkey?”LiteLLM is developer-focused and open-source. It provides a unified OpenAI-compatible API across 100+ LLM providers, with routing (fallback chains, load balancing) and gateway functions (key management, logging). Portkey is more enterprise-focused with stronger observability, guardrails, and team-management features, plus tighter integrations into agent frameworks like LangChain and LlamaIndex. Both blend router and gateway capabilities.
Sources
Permalink to “Sources”-
RouteLLM: Learning to Route LLMs with Preference Data - Ong et al., LMSYS / UC Berkeley, 2024. Primary source for the 40–70% cost reduction via trained routing policies.
-
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance - Chen et al., Stanford University, 2023. Foundational framing of the LLM cascade approach to cost optimisation.
-
Large Language Model Routing with Benchmark Datasets - Shnitzer et al., MIT CSAIL, 2023. Frames routing as a model selection problem on benchmark performance.
-
Lost in the Middle: How Language Models Use Long Contexts - Liu et al., Stanford University, 2023. Context position and quality affect model reasoning independently of model choice.
-
Portkey Blog - AI Gateway Architecture and LLM Observability - Category-defining content on AI gateway patterns, observability, and enterprise LLM governance.
-
Kong AI Gateway Documentation - Enterprise gateway plugin reference: AI Proxy, AI Rate Limiting, AI Prompt Guard, AI Semantic Caching.
-
LMSYS Chatbot Arena / RouteLLM Blog - Routing quality benchmarks; preference data methodology for learning routing policies.
