



















GCP data catalog at a glance
Permalink to “GCP data catalog at a glance”| Aspect | Details |
|---|---|
| What is GCP data catalog? | Google Cloud’s native metadata catalog and governance service, now branded as Dataplex Universal Catalog. The original standalone Data Catalog was deprecated in January 2026. |
| What does it do? | Automatically catalogs metadata across GCP services. Tracks data lineage. Enables data quality monitoring and profiling. Provides a business glossary. Governs access via IAM and BigQuery policy tags. Surfaces AI and ML assets alongside data assets. |
| What’s missing? | Column-level lineage limited to BigQuery only. No automatic propagation of metadata or governance context to tools outside GCP. Cross-system lineage from tools like dbt, Tableau, or Fivetran requires custom API instrumentation. |
| Pricing | Basic discovery is included in the free standard tier (first 100 DCU-hours/month free) at $0.060 per DCU-hour beyond that. Data lineage, quality, profiling, and the data exploration workbench fall under the premium tier, starting at $0.089 per DCU-hour. |
| Best for | Organizations running predominantly on GCP, particularly BigQuery-centric data stacks, which need automated metadata discovery and governance within the Google Cloud ecosystem. |
What does the GCP data catalog do? An overview of Dataplex Universal Catalog
Permalink to “What does the GCP data catalog do? An overview of Dataplex Universal Catalog”"Think of Dataplex Universal Catalog as an automated smart library for your enterprise. Instead of manually entering, the system automatically ingests technical metadata from your storage systems (like BigQuery). - GCP on how Dataplex Universal Catalog works.
At its core, Dataplex Universal Catalog is a fully managed, serverless governance layer that sits across your GCP data estate. It discovers, catalogs, and manages metadata from the services where your data already lives, such as BigQuery, Cloud Storage, Cloud SQL, Spanner, Vertex AI, Pub/Sub, Dataform, Dataproc Metastore.
Dataplex Universal Catalog provides the governance infrastructure to make that metadata useful and trustworthy across GCP. It is deeply integrated with BigLake, Google Cloud’s native Apache Iceberg storage engine. BigLake Metastore is natively supported in Dataplex Universal Catalog, enforcing governance policies consistently across multiple query engines.
How is it different from the original Data Catalog for GCP?
Permalink to “How is it different from the original Data Catalog for GCP?”If you’ve been hearing “Dataplex” and “Universal Catalog” used interchangeably, there’s a reason. Google Cloud has been progressively unifying what were once separate services — the original Data Catalog, Dataplex, and their overlapping governance capabilities — into a single product: Dataplex Universal Catalog.
The original Data Catalog was deprecated on January 30, 2026, and all its functionality has been absorbed into Dataplex Universal Catalog.
Top use cases of GCP data catalog
Permalink to “Top use cases of GCP data catalog”-
Democratize data insights: Run global, natural language searches to find tables, inspect schemas, check quality scan results, and read business glossary definitions without engineering support.
-
Streamline compliance: Understand where sensitive data lives, how it flows, and who accesses it with data classification, BigQuery policy tags, lineage tracking, and audit logs for access events.
-
Govern AI and ML assets: Dataplex catalogs Vertex AI models, datasets, feature store views, and feature groups alongside traditional data assets and visualizes lineage between them.
-
Monitor data quality: Define code-free data quality rules for BigQuery tables covering completeness, uniqueness, regex matching, and referential integrity, with results published as catalog metadata.
-
Enable data mesh: Dataplex’s domain model lets organizations distribute data ownership across teams while enforcing consistent policies centrally, with domain owners managing their own data products and metadata.
-
Build data products: Data products (Preview) are curated, ready-to-use packages of data assets, documentation, quality contracts, and governance controls that solve specific business problems. Designed to reduce time to insight and improve trust.
Assess Your Data Catalog Maturity
Take the AssessmentWhat are the native capabilities of Dataplex Universal Catalog for GCP?
Permalink to “What are the native capabilities of Dataplex Universal Catalog for GCP?”Metadata cataloging and discovery
Permalink to “Metadata cataloging and discovery”Dataplex Universal Catalog automatically retrieves metadata from BigQuery, Cloud SQL, Spanner, Vertex AI, Pub/Sub, Dataform, and Dataproc Metastore.
Technical metadata is enriched using Aspects: structured, schema-driven metadata fields that replace the legacy tag templates from the original Data Catalog. Each Aspect is an instance of an Aspect Type, a reusable template that defines fields, data types, and constraints.
You can use system-defined Aspect Types (covering schema, quality scan results, and profiling data) or create custom Aspect Types to capture domain-specific metadata such as data classification, business ownership, or SLA commitments.
Entry Types extend this further by defining required Aspects for any given asset category, letting governance teams enforce minimum metadata standards across the catalog. A BigQuery table, for example, can be configured to require owner and data classification aspects before it is considered complete.

Aspect Type and Entry Type in GCP's Dataplex Universal Data Catalog. Source: Google Cloud documentation
Search spans projects and regions, respects IAM permissions, and as of late 2025 supports natural language queries in GA, allowing users to find assets in everyday language rather than technical syntax.
Data lineage
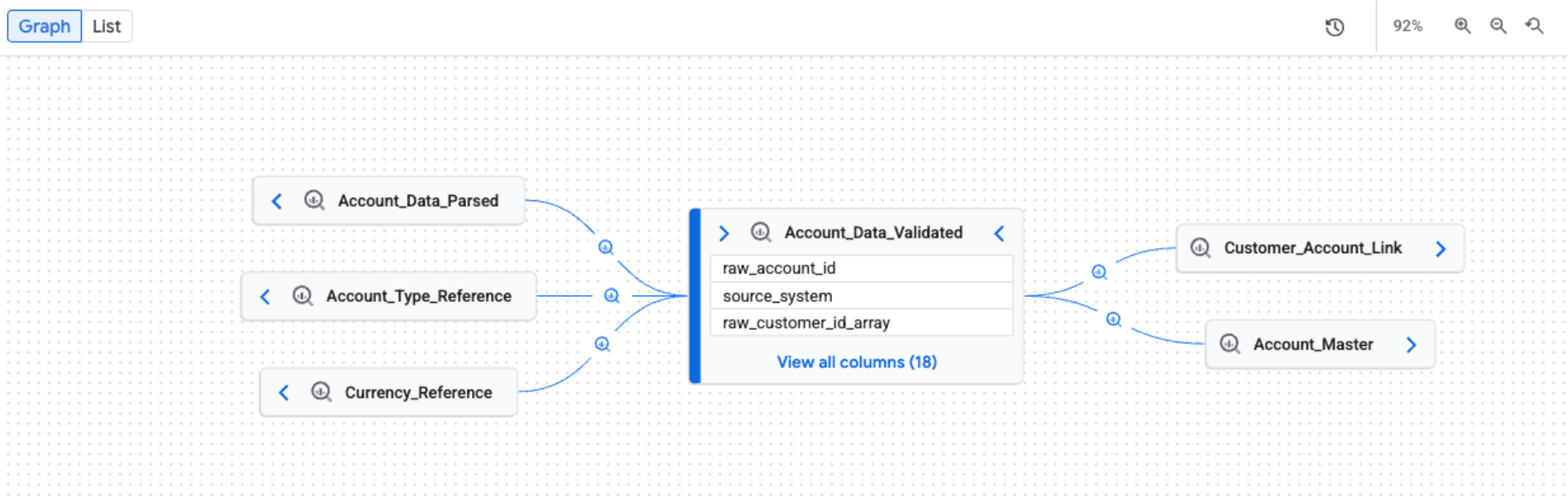
Permalink to “Data lineage”Dataplex Universal Catalog automatically records lineage for BigQuery jobs: CREATE TABLE AS SELECT, CREATE VIEW, INSERT, MERGE, UPDATE, DELETE, and SELECT operations with destination tables. Lineage is enabled per project by enabling the Data Lineage API, after which it is ingested automatically from all supported services in that project.
Beyond BigQuery, native lineage integrations cover Cloud Data Fusion, Cloud Composer (using the apache-airflow-providers-openlineage package), Dataproc Spark jobs, and Vertex AI Pipelines. Lineage is viewable as an interactive graph in the Google Cloud console or queried via the Data Lineage API. For custom sources not covered by native integrations, OpenLineage is supported for manual ingestion.
Column-level lineage for BigQuery is generally available, tracking how individual columns flow between tables for root cause and impact analysis. It is currently limited to BigQuery jobs only.

Data lineage visualization using Dataplex. Source: Google Cloud documentation
Two important limitations to plan around:
- All lineage data is retained for 30 days only.
- BigQuery lineage appears within 24 hours after job completion.
Data quality and profiling
Permalink to “Data quality and profiling”Dataplex provides two complementary quality capabilities for BigQuery:
- Data profiling: Automatically generates statistical profiles covering column distributions, null counts, unique values, and outliers, published as catalog metadata on the entry.
- Auto data quality: Define and automate data quality rules against BigQuery tables without writing custom validation code
Predefined rule types cover null checks, range checks, set checks, regex checks, uniqueness, and statistical range checks. For more complex logic, custom SQL rules support row conditions, table conditions, and SQL assertions including cross-table referential integrity checks.
Business glossary: what it means in practice
Permalink to “Business glossary: what it means in practice”Dataplex Universal Catalog provides a centralized business glossary, generally available as of June 2025. The glossary is structured in three layers:
- A glossary at the top level
- Categories nested up to three levels deep (up to 200 per glossary)
- Terms within those categories (up to 5,000 per glossary)
Each term can carry a short description (up to 1 KB), a long-form overview (up to 120 KB), and contacts identifying the responsible data steward or owner. Terms support two types of relationships: synonyms and related terms.
The glossary follows a role-governed access model:
- Dataplex Catalog Admin for full management
- Dataplex Catalog Editor for stewards
- Dataplex Catalog Viewer for read-only access by data consumers
Starting July 2026, glossary content will be billed under Dataplex Universal Catalog metadata storage pricing.
Data products
Permalink to “Data products”Data products (Preview) are curated packages of data assets, documentation, quality contracts, and governance controls assembled to solve a specific business problem. Rather than hunting through raw tables, data consumers can browse and request access to data products relevant to their use case.
Data products are foundational for data mesh architectures and for AI use cases where agents need structured, governed, business-ready data context.

Enable data mesh architecture with GCP's Dataplex Universal Data Catalog. Source: GCP
Access control
Permalink to “Access control”Dataplex Universal Catalog integrates with Google Cloud IAM for fine-grained access control at the project, entry group, or individual entry level.
Predefined roles cover the full spectrum:
- Dataplex Administrator, Editor, and Viewer for catalog management.
- Dataplex Catalog Admin, Editor, and Viewer for metadata operations.
- Data Lineage Viewer, Editor, and Events Producer for lineage access.
For column-level security on BigQuery data, Dataplex integrates with BigQuery policy tags, which restrict access to sensitive columns based on IAM bindings and are not deprecated as part of the Dataplex migration. VPC Service Controls are also supported, allowing organizations to restrict Dataplex API calls to specific network perimeters.
Data Insights and MCP integration
Permalink to “Data Insights and MCP integration”Dataplex Universal Catalog includes Data Insights, which uses Gemini large language models to generate natural language questions based on a table’s metadata. So, data teams can uncover patterns, assess data quality, and perform statistical analyses without writing queries manually.
For developer and agent workflows, Dataplex Universal Catalog connects to tools including the Gemini CLI via a dedicated extension that bundles an MCP server, removing the need for a separate server setup. Other MCP-compatible IDEs can connect using the general-purpose MCP Toolbox for Databases, which acts as an open-source MCP server between the IDE and Dataplex Universal Catalog. Both paths enable AI-driven data discovery and asset management directly within a development environment using natural language prompts.
How does a metadata context plane extend the metadata management capabilities of Dataplex Universal Catalog?
Permalink to “How does a metadata context plane extend the metadata management capabilities of Dataplex Universal Catalog?”Dataplex Universal Catalog is purpose-built for GCP, and within that boundary it delivers robust, automatic governance. But most modern data stacks don’t live entirely inside GCP. They span dbt transformations, Fivetran or Airbyte ingestion, Tableau or Looker BI layers, Snowflake data warehouses, and Databricks lakehouses.
Even within GCP, the absence of active metadata propagation, constrained column-level lineage, and no automatic coverage of external lineage creates operational gaps that matter when governance needs to scale.
This is where a metadata control plane fills the gap. A metadata control plane is a system-agnostic layer that sits above individual platforms, stitching together their metadata into unified lineage graphs, and actively propagating governance context across the entire estate.
Key capabilities include:
-
Metadata Lakehouse: Store all metadata (technical, business, operational, and social) as a structured, queryable asset in its own right, enabling teams to automate context-driven operations at scale.
-
Active metadata propagation: Tags, classifications, and governance context applied to a source asset automatically travel downstream along lineage paths and sync bidirectionally with each platform’s native tagging system.
-
Cross-system, column-level lineage beyond BigQuery: Assemble automated and actionable column-level lineage across every system in the stack, from ingestion tools through transformation layers to BI dashboards.
-
Cross-system data quality signals: Quality scan results from Dataplex, dbt tests, and other tools are surfaced in a single view alongside lineage, so teams can trace a quality failure back to its root cause across system boundaries, not just within GCP.
-
AI-ready semantic layer: Enrich raw technical metadata with business glossary terms, ownership, classifications, and quality signals, creating a governed semantic layer that’s queryable by AI agents and analytics tools.
-
Context graph: Beyond lineage, a metadata control plane builds a connected graph of relationships across assets, people, processes, and policies, giving both human users and AI agents the full context of how a data asset fits into the organization.
-
App Framework: A metadata control plane’s app framework lets partners and customers build custom governance workflows, automations, and integrations directly on top of the metadata layer.
-
Agentic data stewards: Deploy a suite of AI agents that continuously generate, enrich, and maintain context, keeping descriptions, classifications, and relationships current as data assets and pipelines evolve.
-
AI-ready governance via MCP: Expose lineage, quality, and governance context from the entire data estate to AI agents and developer tools.
-
A unified governance layer for the full stack: For organizations running GCP alongside Snowflake, Databricks, dbt, Tableau, or Fivetran, a metadata control plane stitches together metadata from every system into a single, coherent governance layer, so policies defined once flow out to each platform’s native enforcement mechanisms.
Real stories from real customers
Permalink to “Real stories from real customers”
Nasdaq powers AI governance with unified metadata context
"Nasdaq adopted Atlan as their 'window to their modernizing data stack' and a vessel for maturing data governance. The implementation of Atlan has also led to a common understanding of data across Nasdaq, improved stakeholder sentiment, and boosted executive confidence in the data strategy. This is like having Google for our data."
Michael Weiss, Product Manager
Nasdaq
🎧 Listen to AI-generated podcast: How Nasdaq Uses Active Metadata
53% less engineering workload and 20% higher data-user satisfaction
"Kiwi.com has transformed its data governance by consolidating thousands of data assets into 58 discoverable data products using Atlan. 'Atlan reduced our central engineering workload by 53% and improved data user satisfaction by 20%,' Kiwi.com shared. Atlan's intuitive interface streamlines access to essential information like ownership, contracts, and data quality issues, driving efficient governance across teams."
Data Team
Kiwi.com
🎧 Listen to AI-generated podcast: How Kiwi.com Unified Its Stack with Atlan
Moving forward with Dataplex Universal Catalog for your GCP data and AI estate
Permalink to “Moving forward with Dataplex Universal Catalog for your GCP data and AI estate”Dataplex Universal Catalog is a powerful starting point for GCP-native organizations to set up metadata management and governance. Automatic lineage for BigQuery jobs, built-in data quality scans, a centralized business glossary, AI and Vertex AI asset cataloging, and deep BigQuery integration make it the right foundation for GCP-centric governance.
But for organizations whose data estate extends beyond GCP, Dataplex alone may leave meaningful gaps. A metadata context plane like Atlan works with Dataplex Universal Catalog to stitch together the metadata from every other system in the stack into a single, coherent governance layer.
For data teams that need cross-system column-level lineage, near-real-time impact analysis, active metadata propagation, extended lineage retention, and AI-ready governance across their full GCP and non-GCP estate, Atlan and Dataplex together provide complete coverage.
See how Atlan extends Dataplex for cross-system governance
Book a DemoFAQs about GCP data catalog
Permalink to “FAQs about GCP data catalog”What is Dataplex Universal Catalog?
Permalink to “What is Dataplex Universal Catalog?”Dataplex Universal Catalog is Google Cloud’s unified metadata management and data governance solution for the GCP ecosystem. It provides automatic metadata cataloging for BigQuery and other GCP services, end-to-end data lineage, built-in data quality and profiling, a centralized business glossary, data product management, and access control via Google Cloud IAM.
What is the difference between GCP data catalog and Dataplex Universal Catalog?
Permalink to “What is the difference between GCP data catalog and Dataplex Universal Catalog?”GCP Data Catalog was Google Cloud’s original standalone metadata management service, focused primarily on metadata discovery, tagging, and search for GCP assets. Dataplex was a separate service focused on data lake organization, quality, and governance across distributed domains.
In 2025, Google unified these two services into Dataplex Universal Catalog — a single product that covers all of the capabilities of both predecessors, along with significant additions: a built-in business glossary (GA as of June 2025), column-level lineage for BigQuery (GA), data products (Preview), AI and ML asset cataloging for Vertex AI, natural language search (Preview), and MCP integration for AI-driven data discovery.
The original standalone Data Catalog was deprecated on January 30, 2026. All Data Catalog content and usage should be migrated to Dataplex Universal Catalog.
What are the key capabilities of Dataplex Universal Catalog?
Permalink to “What are the key capabilities of Dataplex Universal Catalog?”Dataplex Universal Catalog provides six core capabilities. Metadata cataloging and discovery, data lineage (with column-level lineage for BigQuery jobs), auto data quality and built-in profiling, business glossary, data products, and access control integrated with Google Cloud IAM and BigQuery policy tags.
What are the top use cases of Dataplex Universal Catalog?
Permalink to “What are the top use cases of Dataplex Universal Catalog?”The three primary use cases from Google Cloud’s own documentation are accelerating self-service analytics, governing AI and data products, and streamlining compliance. Beyond these three, data mesh enablement and data quality monitoring are common secondary use cases for organizations adopting distributed data ownership or building quality-aware pipelines on GCP.
Is Dataplex Universal Catalog free to use?
Permalink to “Is Dataplex Universal Catalog free to use?”Partially. Dataplex Universal Catalog uses a tiered pricing model based on pay-as-you-go Data Compute Unit (DCU) consumption.
The standard processing tier, which covers Cloud Storage metadata discovery, is $0.06 per DCU-hour, with the first 100 DCU-hours per month free. The free tier does not apply to the premium processing tier. Data lineage, auto data quality, and data profiling fall under the premium processing tier at $0.089 per DCU-hour, with no free allowance.
Metadata storage for automatically ingested Google Cloud technical metadata is free; custom metadata storage beyond that is billed at $0.002739726 per GiB-hour.
Business glossary content will be billed under metadata storage pricing starting July 2026. Gemini-powered features including Data Insights are billed separately under Gemini in BigQuery pricing.
What are some best practices for Dataplex Universal Catalog?
Permalink to “What are some best practices for Dataplex Universal Catalog?”Enable the Data Lineage API on production projects from the start as lineage is only tracked from the point of enablement. Design your Aspect Types before populating the catalog. Build your business glossary before linking terms to columns. Use Entry Types to enforce minimum metadata standards. Integrate quality scan results with lineage from the start. Grant the Data Lineage Viewer role at the folder or organization level for cross-project lineage.
When do I need a metadata control plane to extend the capabilities of Dataplex Universal Catalog?
Permalink to “When do I need a metadata control plane to extend the capabilities of Dataplex Universal Catalog?”You need a metadata control plane when your data stack extends beyond GCP, you need column-level lineage beyond BigQuery, as well as active metadata propagation and unified governance across the full data and AI stack.
Share this article

{kind=link}
{kind=link}