



















In May 2026, VentureBeat reported that buyer intent for hybrid retrieval tripled from 10.3% to 33.3% in a single quarter as enterprises discovered RAG architecture alone cannot carry production-grade agentic AI. LangChain’s survey of 1,300+ practitioners found 32% cite output quality as their top production barrier. Both signals point to the same gap: agents can retrieve answers, but cannot yet retrieve trustworthy ones. This page draws what VentureBeat named in prose: the architectural difference between RAG and an agent context layer, shown in code, diagrams, and a 4-stage adoption timeline.
What is the difference between an agent context layer and RAG?
Permalink to “What is the difference between an agent context layer and RAG?”RAG and a context layer are not alternatives. They occupy different positions in the AI agent stack and break in different ways when absent.
RAG (Retrieval-Augmented Generation) is a retrieval mechanism. It converts queries into embeddings, searches a vector store for semantically similar chunks, and injects those chunks into an LLM prompt. RAG answers: what text is most relevant to this query?
An agent context layer is governed data infrastructure. It resolves business entity definitions, enforces access policies at runtime, tracks column-level lineage, and attaches certified provenance to every answer. The context layer answers: what does this entity mean, who owns it, and is this agent allowed to see it?
The production-grade answer is both, in sequence. The context layer executes first, enriching the query with governed semantic anchors. RAG executes second, retrieving from a knowledge base whose embeddings include business metadata. The LLM generates last, with certified definitions and lineage in the prompt.
| Dimension | RAG alone | Context layer alone | RAG + Context layer |
|---|---|---|---|
| What it stores | Document chunks as float vectors | Business definitions, lineage, policies, ownership | Governed chunks enriched with business metadata |
| How it updates | Re-embed on document change | Event-driven sync with source systems | Both update independently |
| Governance support | None; retrieves all similar chunks regardless of policy | Full: role-based access, certified definitions, version history | Full: policy enforced before retrieval |
| Explainability | “I found these chunks” | “This entity is owned by Y, last certified Z” | “I used certified definition v3, owner: Finance” |
| Multi-agent support | Each agent retrieves independently; no shared semantic anchor | Shared governed substrate all agents query | Consistent answers across agents |
| Provenance tracking | None; retrieval is stateless | Full: column-level lineage from source to report | Answer includes lineage path and context version |
| Freshness model | Static at last embedding update | Active: event-driven metadata sync prevents staleness | Freshness metadata available at retrieval time |
| Query interface | Embedding similarity search | SDK or MCP tool calls | Enriched embedding search using certified definitions as anchors |
| Failure mode when absent | Ungoverned retrieval; definition conflicts surface silently | Governed metadata agents cannot query at runtime | N/A |
| Ideal for | Unstructured document retrieval at scale | Resolving entity semantics, enforcing policies, tracking decisions | Production-grade enterprise agents with compliance requirements |
The architecture: RAG-only vs RAG with a context layer
Permalink to “The architecture: RAG-only vs RAG with a context layer”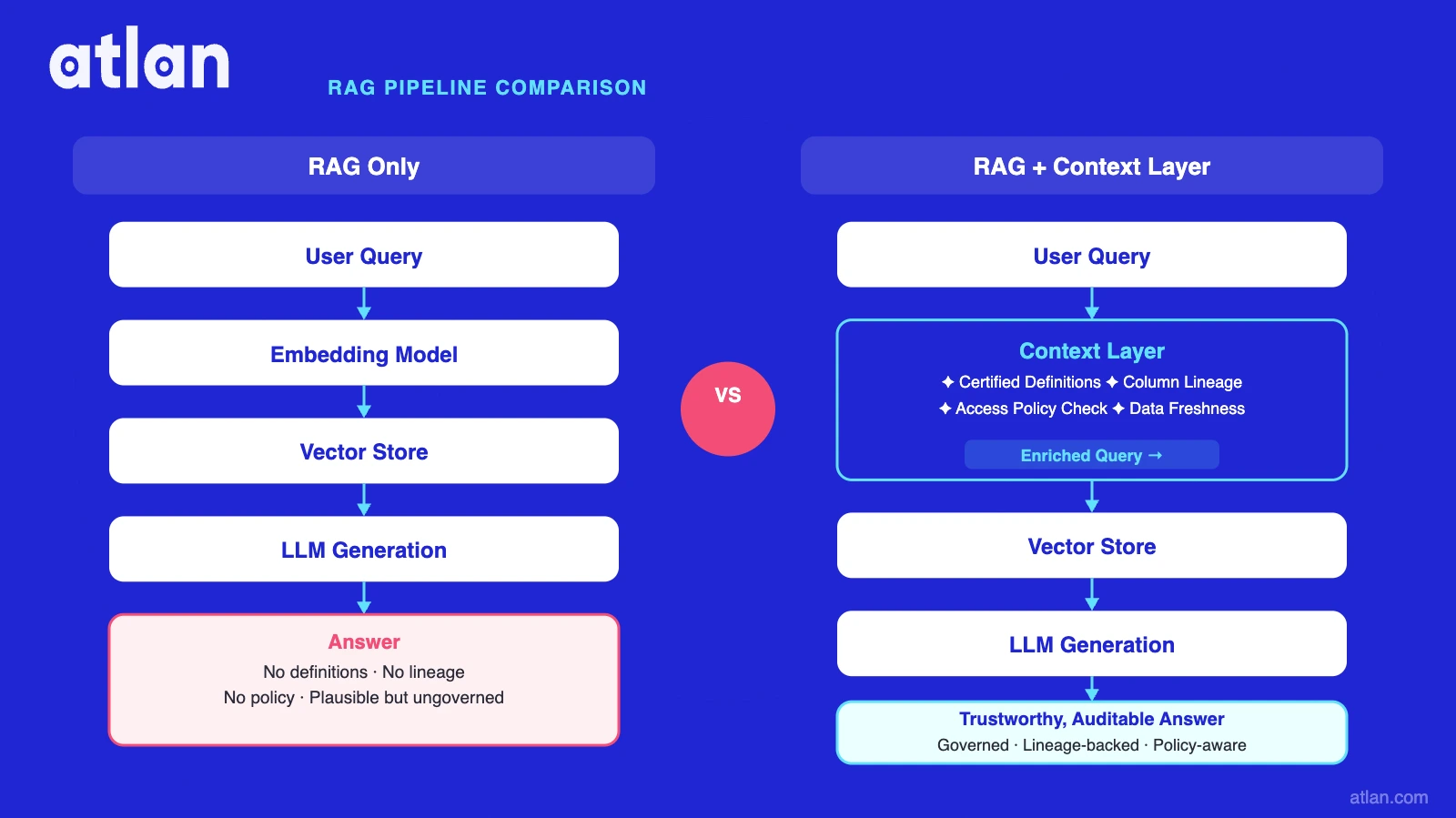
RAG-only pipeline
Permalink to “RAG-only pipeline”User Query
|
v
Embedding Model (query -> float vector)
|
v
Vector Store (cosine similarity search -> top-k chunks)
|
v
LLM Generation (chunks injected into prompt -> answer)
|
v
Answer [no definitions | no lineage | no policy check | no audit trail]
The RAG-only pipeline is effective for bounded, single-domain knowledge bases. What it structurally cannot provide:
- Business definitions. “Revenue” in your vector store may mean GAAP net revenue in Finance, bookings in Sales, and contract value in Legal. The embedding model cannot mark one authoritative.
- Lineage. When an agent says “Q1 ARR was $42M,” there is no record of which table that number came from or whether the source was certified.
- Policy enforcement. A vector search returns all semantically similar chunks regardless of whether the requesting agent is authorized. Permission leakage is not a model failure; it is a structural gap in pure RAG.
- Audit trail. The chunks used to generate an answer are not logged with metadata, version, or owner. Compliance teams cannot reconstruct what context the agent used.
This is why RAG accuracy problems tend to manifest at retrieval time, not generation time. Research shows 73% of RAG failures originate in the retrieval stage.
RAG + Context Layer pipeline
Permalink to “RAG + Context Layer pipeline”User Query
|
v
Context Layer Resolution
[ Business definitions (certified, versioned) ]
[ Column-level lineage (source -> report) ]
[ Access policy check (role-based, runtime) ]
[ Freshness metadata (last sync, lag) ]
|
v
Enriched Query (original query + certified definitions + scope)
|
v
RAG Retrieval (embedding search filtered to certified assets)
|
v
LLM Generation (governed chunks + definitions + lineage in prompt)
|
v
Cited Answer [provenance: context version | owner | policy used]
The context layer does not replace vector search; it precedes it. By the time RAG runs, the query carries certified semantic anchors and the retrieval is filtered to governed, policy-compliant assets. The LLM generates with definitions and lineage already in context.
This is the context infrastructure for AI agents that transforms a plausible answer into a trustworthy one.
What a context layer adds to RAG: the structural difference in code
Permalink to “What a context layer adds to RAG: the structural difference in code”The architectural difference is concrete in code. Two functions answer the same business question, with and without a context layer.
# ============================================================
# PATH A: Raw RAG query - no context layer
# ============================================================
def agent_answer_raw(user_question: str) -> str:
"""
Query goes directly to the vector store.
No definition, no ownership, no lineage, no policy check.
'Revenue' could mean anything. No way to know.
"""
query_embedding = embed(user_question)
chunks = vector_store.similarity_search(
embedding=query_embedding,
top_k=5
# No filter: retrieves certified and uncertified assets equally
# No policy check: returns data regardless of user authorization
)
return llm.generate(prompt=user_question, context=chunks)
# Answer has no provenance, no version, no owner - not auditable
# ============================================================
# PATH B: Context-layer-enriched RAG query
# ============================================================
def agent_answer_governed(user_question: str, agent_id: str) -> str:
"""
Context layer resolves entities, enforces policy, enriches query.
RAG retrieves only from governed, certified assets.
Answer carries provenance for full auditability.
"""
# Step 1: Extract entities and resolve via context layer
entities = entity_extractor.extract(user_question) # ["revenue", "ARR", "Q1"]
context_metadata = {}
for entity in entities:
resolved = context_layer.resolve(entity)
# Returns: canonical_name, certified_definition, owner, certified_at,
# authoritative_source, lineage[], policy{read_roles, deny_roles}, freshness{}
context_metadata[entity] = resolved
# Step 2: Policy enforcement before any retrieval occurs
for entity, meta in context_metadata.items():
if not context_layer.check_policy(agent_id, meta["policy"]):
raise PermissionError(f"Agent {agent_id} not authorized for {entity}")
# Step 3: Build enriched query using certified definitions as semantic anchors
enriched_query = query_builder.build(
question=user_question,
definitions=context_metadata
)
# Step 4: RAG retrieval - filtered to certified assets only
chunks = vector_store.similarity_search(
embedding=embed(enriched_query),
top_k=5,
filters={"certification_status": "certified"}
)
# Step 5: Generate with governed context and lineage in the prompt
answer = llm.generate(
prompt=enriched_query,
context=chunks,
metadata=context_metadata
)
# Step 6: Log decision trace - context IDs, versions, policy constraints used
context_layer.log_decision_trace(
agent_id=agent_id,
question=user_question,
context_used=context_metadata,
answer_hash=hash(answer)
)
return answer
# Answer is now auditable: which definition version, lineage path, who authorized it
The key function signatures reveal the structural difference:
context_layer.resolve(entity): unlocks certification, lineage, ownership, policy, and freshness for any entity.context_layer.check_policy(agent_id, policy): enforces access before a single vector search runs.query_builder.build(question, definitions): certified definitions become semantic anchors for the embedding search.context_layer.log_decision_trace(...): the audit record RAG alone cannot produce.
Path A is faster. Path B is trustworthy. For a customer support bot over a bounded FAQ corpus, Path A may suffice. For a financial analyst agent querying earnings data across Salesforce, Snowflake, and Looker, Path B is not optional.
For more on context engineering strategies or how context engineering differs from prompt engineering, those pages go deeper.
When organizations outgrow RAG alone: a 4-stage timeline
Permalink to “When organizations outgrow RAG alone: a 4-stage timeline”The decision to add a context layer is rarely philosophical. It is triggered by specific, observable failures.
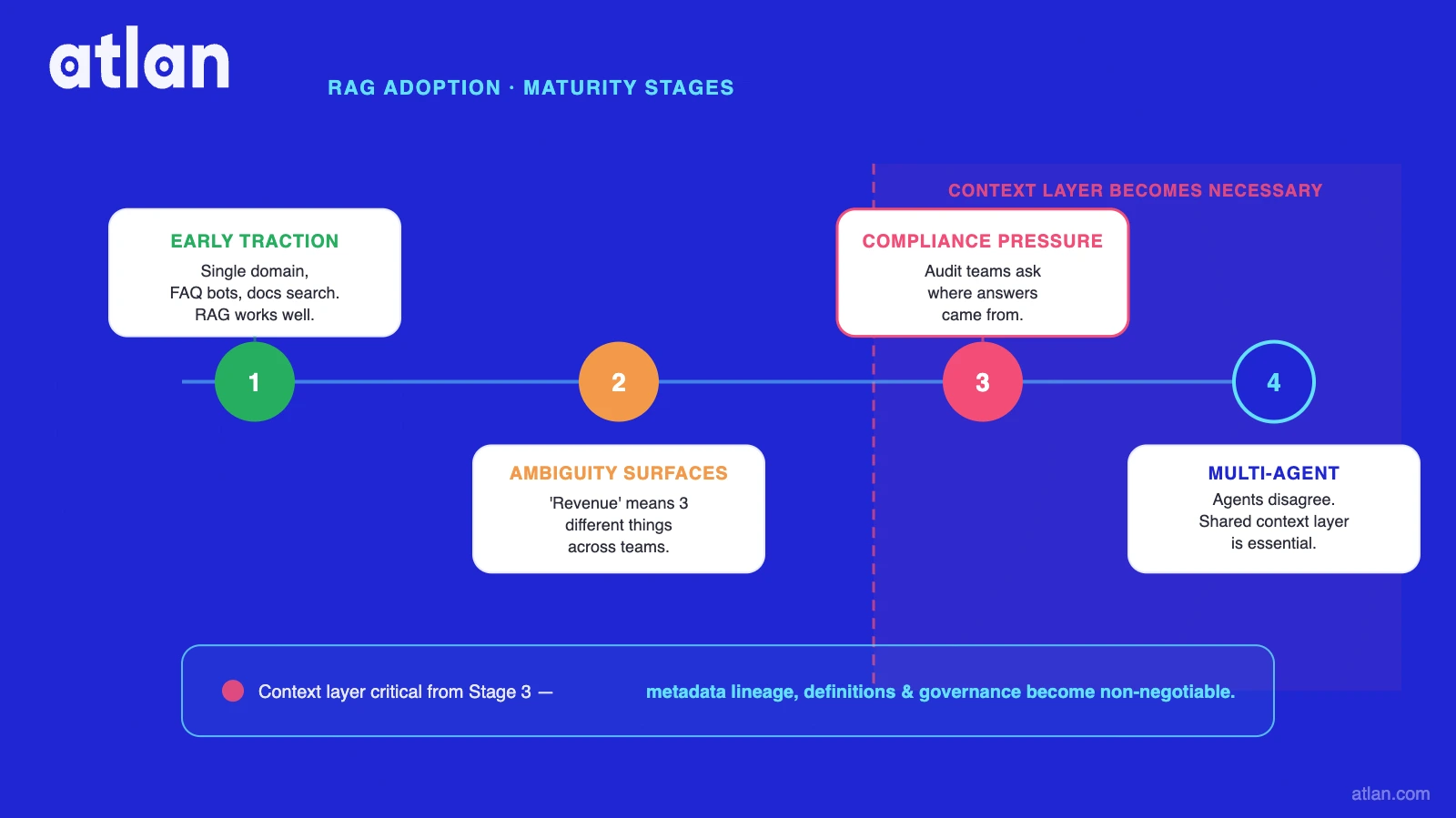
Stage 1: Single-domain RAG delivers value
Permalink to “Stage 1: Single-domain RAG delivers value”One team, one knowledge base, one application: a customer support FAQ bot, an internal HR policy assistant, or a product documentation search. RAG is more than sufficient. The corpus is bounded, definitions are implicit and consistent, and conflicts are rare. Advanced RAG techniques can extend this stage further. A context layer is not yet needed.
Stage 2: Cross-system queries surface ambiguity
Permalink to “Stage 2: Cross-system queries surface ambiguity”Two or more teams share an agent, or one agent begins querying multiple source systems. “Revenue” becomes a problem: CRM shows pipeline value, the warehouse shows GAAP net revenue, billing shows contracted ARR. The agent retrieves all three vectors and confidently returns the wrong number.
The agent is not hallucinating. It is retrieving correctly from ungoverned data. Stakeholders report “the agent gives different answers to the same question.” This is the Stage 2 signal. The fix is a business glossary with certified definitions: the first component of a context layer’s core components.
Stage 3: Compliance requires provenance
Permalink to “Stage 3: Compliance requires provenance”A regulated industry, an audit request, or an AI governance mandate arrives. The question shifts from “is the answer right?” to “where did this answer come from?” RAG cannot answer. Retrieval is stateless: the chunks that produced an answer carry no metadata, version, or owner. Legal asks for evidence of AI reasoning. None exists.
Deloitte’s 2026 State of AI report found that only 21% of organizations have mature governance for agentic AI, despite 74% expecting to use agents moderately or more by 2027. The gap between adoption and governance is where Stage 3 failures live. The fix is decision traces, column-level lineage, and policy enforcement: all responsibilities of an enterprise context layer. These are also core AI agent risks and guardrails concerns.
Stage 4: Multi-agent systems require a shared context substrate
Permalink to “Stage 4: Multi-agent systems require a shared context substrate”Multiple agents work in sequence or parallel. Agent A defines “ARR” using one retrieved chunk. Agent B defines it differently. The pipeline produces contradictory outputs. Debugging is intractable because each agent ran its own independent retrieval. Memory layers are session-scoped and cannot share certified enterprise definitions across agent boundaries.
This is the multi-agent system orchestration problem that no prompt engineering solves. The fix is a shared context substrate: one governed layer all agents query via MCP or SDK, returning the same certified definitions regardless of which agent asks. Without it, context drift detection is a reactive process rather than a structural guarantee.
As Stephanie Walter, analyst at HyperFRAME Research, observed in VentureBeat: “Agents don’t just need more tokens or better models. They need governed, current, low-latency context.”
Why both are necessary in production
Permalink to “Why both are necessary in production”The narrative that “context architecture is replacing RAG” is technically incorrect. RAG remains the retrieval mechanism. What changes is the substrate RAG retrieves from: it needs to be governed.
RAG without a context layer is retrieval from ungoverned data. The agent finds semantically similar text, but that text may carry conflicting definitions, stale numbers, or data the requesting user is not authorized to see. Atlan’s research on RAG accuracy problems found 80% of enterprise RAG deployments critically fail in production, not because retrieval is broken, but because the substrate is ungoverned.
A context layer without RAG is governed metadata agents cannot query at runtime. A business glossary is not a retrieval system. The metadata layer for AI needs a runtime query interface, and that interface is RAG.
The compound is the answer. Context engineering assembles and maintains it. A context graph maps entity relationships within it. A knowledge graph may underpin parts of it. The memory layer stores session-scoped state on top of it. Each layer has its role; none replaces the others.
For how business context for AI is structured architecturally, or how context-aware AI agents consume it at runtime, those pages extend the architecture. For hybrid RAG and how to evaluate RAG systems, the tooling guides go deeper.
How Atlan acts as the context layer beneath RAG
Permalink to “How Atlan acts as the context layer beneath RAG”Atlan is not a RAG replacement. It is the governed substrate that RAG retrieves from.
When Workday’s Joe DosSantos described building a revenue analysis agent, he identified the missing piece: “We had no way to interpret human language against the structure of the data.” Building the semantic translation layer with Atlan’s MCP server produced a 5x improvement in AI analyst accuracy.
The structural components Atlan provides map directly to the compound architecture:
- Governed business glossary. Certified definitions with ownership, version history, and certification date: the inputs to
context_layer.resolve(). - Column-level lineage. Full traceability from source through transformation to reporting surface: the inputs to decision trace logging.
- Active metadata. Event-driven sync with source systems rather than snapshot re-embedding; freshness signals at query time.
- Agent access control. Runtime policy enforcement identical to human data access: the
context_layer.check_policy()call. - MCP server. Open standard delivery to any compatible agent framework: the API surface any RAG pipeline can call.
- 400+ data sources. Cross-platform coverage across Snowflake, Databricks, Salesforce, BigQuery, dbt, and Looker.
The accuracy impact is measurable. Atlan’s research across 522 queries found a 38% relative improvement in AI SQL accuracy when governed context was added (p<0.0001), with 2.15x on medium-complexity queries. Snowflake research found a 20% answer accuracy gain and 39% tool call reduction when an ontology layer was added. These are substrate improvements, not model improvements.
Context Engineering Studio bootstraps 90% of enrichment automatically. The enterprise context layer does not require a multi-year governance program. Connect Atlan to your existing data infrastructure and let the MCP server surface governed context to your agent frameworks.
For how Atlan acts as enterprise AI memory, or the design choices in an agent context layer, those pages continue the architecture. If you are evaluating tools, agent context layer tools compared maps the landscape. And if the distinction between a context layer and a knowledge base is still open, agent context layer vs knowledge base addresses it directly.
Frequently asked questions
Permalink to “Frequently asked questions”1. Does a context layer replace RAG?
Permalink to “1. Does a context layer replace RAG?”No. A context layer is the governed data substrate that sits beneath RAG. RAG remains the retrieval mechanism: it finds semantically relevant chunks and injects them into an LLM prompt. The context layer governs what RAG retrieves from. Both are load-bearing in production: RAG alone retrieves from ungoverned data; a context layer alone is governed metadata agents cannot query at runtime.
2. When should I add a context layer to my RAG system?
Permalink to “2. When should I add a context layer to my RAG system?”The RAG-outgrown timeline maps four stages. Stage 1 (single-domain RAG) typically does not need a context layer. Trigger points: Stage 2, when cross-system queries surface conflicting definitions; Stage 3, when compliance requires provenance; Stage 4, when multi-agent systems need a shared semantic substrate. If stakeholders say “the agent gives different answers to the same question,” you have reached Stage 2.
3. What does a context layer add to RAG architecturally?
Permalink to “3. What does a context layer add to RAG architecturally?”Five structural capabilities RAG alone cannot provide: (1) certified business definitions as semantic anchors; (2) runtime policy enforcement before any vector search; (3) column-level lineage from source to answer; (4) freshness metadata so agents know when context is stale; and (5) a decision trace log for auditability. The Python code block above shows how context_layer.resolve() and context_layer.check_policy() slot in.
4. Can RAG provide provenance and lineage?
Permalink to “4. Can RAG provide provenance and lineage?”Structurally, no. RAG retrieval is stateless: the chunks used to generate an answer are not logged with metadata, version, or owner. Some implementations add source attribution (the URL of the retrieved document), but this is not column-level lineage and does not track transformations. Provenance at the level compliance teams require is a context layer responsibility. AI agent observability tools can surface gaps but cannot close them structurally.
5. What is the difference between a context layer and a semantic layer?
Permalink to “5. What is the difference between a context layer and a semantic layer?”A semantic layer (dbt metrics layer, LookML, AtScale) exposes pre-defined business metrics to BI tools via SQL. A context layer is broader: it governs entity definitions, lineage, access policies, freshness, and inter-entity relationships across all data systems, exposed to AI agents via MCP or SDK at runtime. The semantic layer is one component that may feed into a context layer.
6. How do multiple agents share context in a production system?
Permalink to “6. How do multiple agents share context in a production system?”Through a shared context layer: one governed substrate all agents query via the same MCP server or SDK. Without it, each agent retrieves independently and may resolve the same entity to different definitions. Stage 4 of the timeline above describes this failure mode. Only a shared context substrate solves it structurally.
Sources
Permalink to “Sources”- VentureBeat: “Context architecture is replacing RAG as agentic AI pushes enterprise retrieval to its limits” (May 2026). https://venturebeat.com/data/context-architecture-is-replacing-rag-as-agentic-ai-pushes-enterprise-retrieval-to-its-limits
- VentureBeat: “The RAG era is ending for agentic AI: a new compilation-stage knowledge layer is what comes next.” https://venturebeat.com/data/the-rag-era-is-ending-for-agentic-ai-a-new-compilation-stage-knowledge-layer-is-what-comes-next
- LangChain: State of Agent Engineering 2025. 1,300+ respondents. https://www.langchain.com/state-of-agent-engineering
- Deloitte: State of AI in the Enterprise 2026. 3,235 IT/business leaders, 24 countries, Aug-Sept 2025. https://www.deloitte.com/us/en/about/press-room/state-of-ai-report-2026.html
- Capgemini Research Institute: “Rise of Agentic AI: How trust is the key to human-AI collaboration.” April 2025, 1,500 executives. https://www.capgemini.com/insights/research-library/ai-agents/
- Gartner: “Organizations with successful AI initiatives invest up to 4x more in data and analytics foundations.” April 2026. https://www.gartner.com/en/newsroom/press-releases/2026-04-16-gartner-says-organizations-with-successful-ai-initiatives-invest-up-to-four-times-more-in-data-and-analytics-foundations
- Atlan: “Research Shows How Enhanced Metadata Delivers 38% Better AI Accuracy.” 522 queries, p<0.0001. https://atlan.com/know/enhanced-metadata-improves-query-accuracy/
- DataHub: “RAG vs. Context Management.” https://datahub.com/blog/rag-vs-context-management/
- Unblocked: “Context Engine vs RAG: Retrieval Isn’t Enough.” https://getunblocked.com/blog/context-engine-vs-rag/
- InformationWeek: “RAG compliance risks: Why CIOs must audit AI data pipelines.” https://www.informationweek.com/data-management/nobody-told-legal-about-your-rag-pipeline-why-that-s-a-problem
- ElixirData: “Context Layer for AI: The Missing Enterprise Architecture Layer.” Dr. Jagreet Kaur Gill. https://www.elixirdata.co/blog/context-layer-for-ai
- InfoQ: “Beyond RAG: Architecting Context-Aware AI Systems with Spring Boot.” https://www.infoq.com/articles/beyond-rag-context-aware/
